
環境 操作系統:Ubuntu 18.04 MongoDB: 4.0.3 伺服器 首先部署3台伺服器,1台主節點 + 2台從節點 3台伺服器的內容ip分別是: 10.140.0.5 (主節點) 10.140.0.6 (從節點01) 10.140.0.7 (從節點02) 安裝MongoDB 接下來,需要 ...
環境 操作系統:Ubuntu 18.04 MongoDB: 4.0.3
伺服器 首先部署3台伺服器,1台主節點 + 2台從節點
 3台伺服器的內容ip分別是:
10.140.0.5 (主節點)
10.140.0.6 (從節點01)
10.140.0.7 (從節點02)
3台伺服器的內容ip分別是:
10.140.0.5 (主節點)
10.140.0.6 (從節點01)
10.140.0.7 (從節點02)
安裝MongoDB 接下來,需要在每一臺伺服器上安裝MongoDB。 完整安裝過程可參考官方文檔。 為了方便,本文提供MongoDB的一鍵安裝腳本。
切換成root用戶
sudo su -
運行安裝腳本
wget https://gitlab.com/caizhifei2003/scripts/raw/master/install/mongodb/ubuntu-1804.sh
chmod u+x ubuntu-1804.sh
./ubuntu-1804.sh
此時,可以通過mongo命令進入資料庫
配置複製集 設置複製集名稱 有兩種方式來設置複製集的名稱。一種是通過mongod命令,另一種是通過修改配置文件。 本文使用通過修改配置文件的方式來設置複製集名稱,確保每次節點重新啟動後能夠使用相同的配置啟動資料庫。
打開MongoDB在Ubuntu上的配置文件
vim /etc/mongod.conf
找到replication配置節
replication: replSetName: "rs0"
綁定MongoDB的IP地址 找到net配置節
net: port: 27017 bindIp: localhost,10.140.0.5這裡是主節點的地址,相應的從節點要綁定 10.140.0.6 10.140.0.7
保存文件,重新啟動mongod服務
service mongod restart
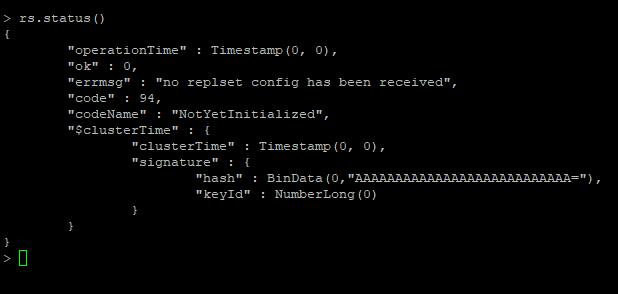
此時,進入到任何一個節點。查看複製集狀態。
初始化複製集 通過mongo shell進入主節點的資料庫 執行複製集初始化命令
rs.initiate( { _id : "rs0", members: [ { _id: 0, host: "10.140.0.5:27017" }, { _id: 1, host: "10.140.0.6:27017" }, { _id: 2, host: "10.140.0.7:27017" } ] })
查看複製集狀態
rs.status()
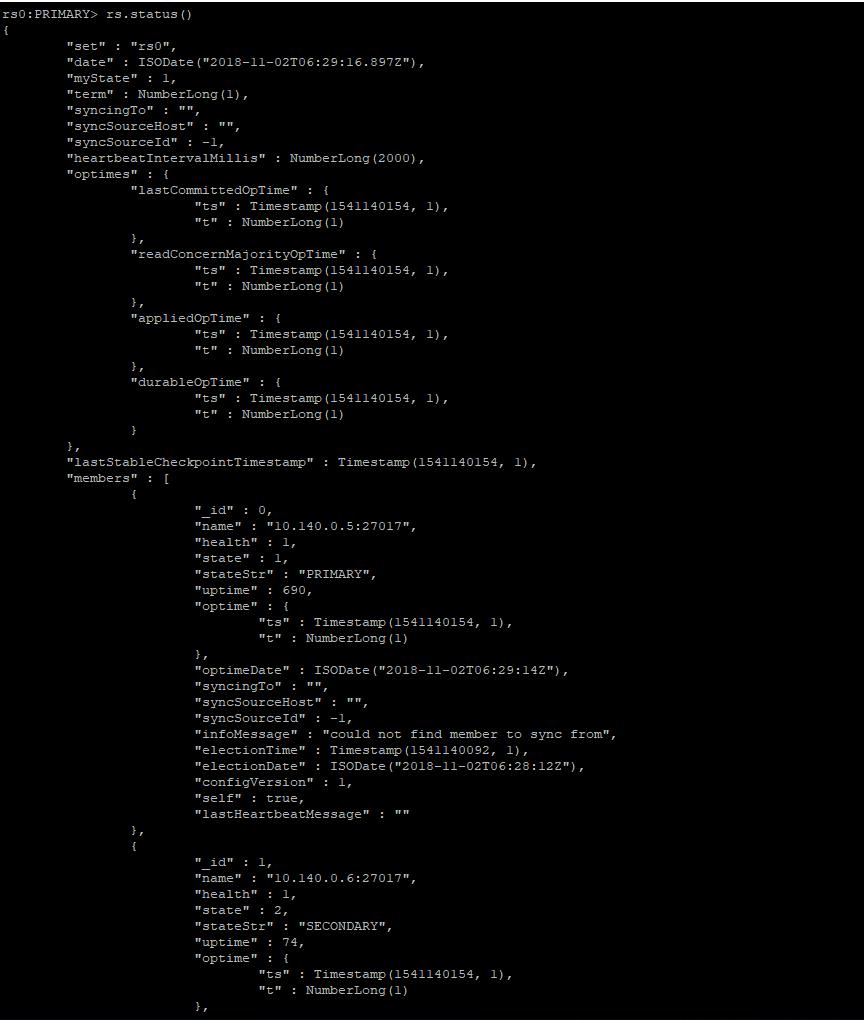
到此,複製集已經創建成功。
測試數據同步 執行如下命令,在主節點上插入一條數據
use test db.test.insertOne({"name": "kenny"})
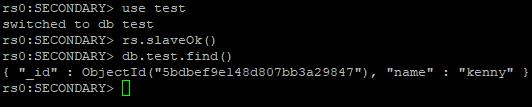
進入任何一個從節點,查看數據是否被同步。
use test rs.slaveOk() db.test.find()預設情況下,MongoDB只允許在主節點上寫入和讀取數據。這裡的rs.slaveOk()是為了在從節點上也讀取數據而需要執行的session(如果退出mongo shell,需要重新執行該命令)級別的命令。 顯示的內容如下:
測試重新選舉主節點 在3個節點上分別使用rs.isMaster()命令 10.140.0.5:
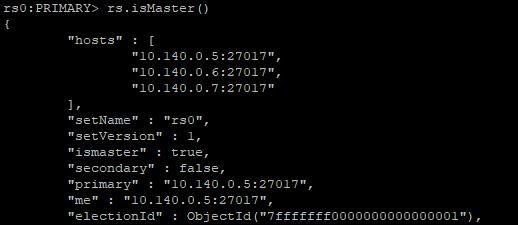
10.140.0.6:
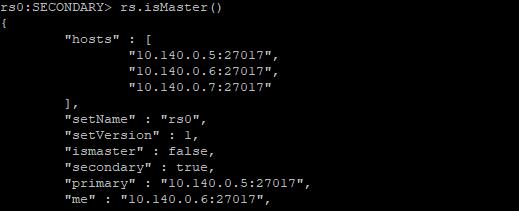
10.140.0.7
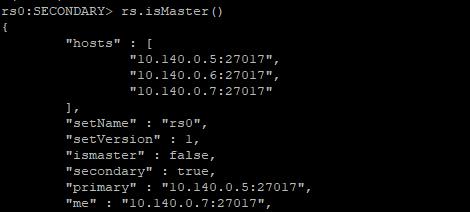
強制關閉主節點上的MongoDB服務
use admin
db.shutdownServer()
在兩個從節點上,通過rs.isMaster()命令查看狀態
10.140.0.6:
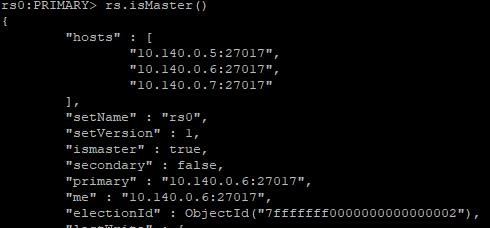
10.140.0.7:
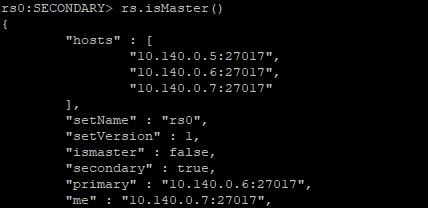
從上面的運行結果可以看出,10.140.0.6已經被推選成新的主節點。此時所有服務一切正常。 至此,部署MongoDB複製集的基本操作已經完成。
總結 MongoDB複製集的部署還是比較簡單的,官方文檔也給出了較為詳細的說明。 同任何其它資料庫一樣,MongoDB的副本集也是為了增強數據的安全性,避免因為伺服器出現異常時,而導致數據服務不可用的情況出現。同時,數據被完整的保存在多個節點中,任何一臺伺服器的硬碟出現問題,都不會丟失數據。但是這裡也存在風險,那就是數據同步存在時間差,如果還沒有等到數據被同步到從節點,主節點就當機的話,那麼這部分數據是無法找回的。 官方建議的副本集節點數量是3個,1個主節點+2個從節點。或者是1個主節點+1個從節點+1個仲裁節點。仲裁節點的作用是在主節點不可用時,通過演算法找到最適合的從節點成為新的主節點。不建議將仲裁節點和數據節點放在同一個伺服器上。


