hive中的轉義符 Hadoop和Hive都是用UTF-8編碼的,所以, 所有中文必須是UTF-8編碼, 才能正常使用 備註:中文數據load到表裡面, 如果字元集不同,很有可能全是亂碼需要做轉碼的, 但是hive本身沒有函數來做這個 一、轉義字元的特殊情況: 自身的轉義,比如java有時候需要兩個 ...
hive中的轉義符
Hadoop和Hive都是用UTF-8編碼的,所以, 所有中文必須是UTF-8編碼, 才能正常使用
備註:中文數據load到表裡面, 如果字元集不同,很有可能全是亂碼需要做轉碼的, 但是hive本身沒有函數來做這個
一、轉義字元的特殊情況:
自身的轉義,比如java有時候需要兩個轉義字元"\\",或者四個轉義字元“\\\\”。
1)java的倆種情況:
a.正則表達式匹配和string的split函數,這兩種情況中字元串包含轉義字元“\”時,需要先對轉義字元自身轉義,就是說需要兩個轉義字元“\\”。比如\n,\t等(java解析後,再有正則和split自身特定進行解析)
b.而當匹配字元正斜線“\”,則需要四個轉義字元“\\\\”,因為,首先java(編譯器?)自身先解析,轉義成兩個“\\”,再由正則或split的解析功能轉義成一個“\”,才是最終要處理的字元。
這是因為解析過程需要兩次,才能在字元串中出現正斜線“\”,出現後才能轉義後面的字元。
2)hive中的split和正則表達式
hive用java寫的,所以同Java一樣,兩種情況也需要兩個“\\”,
split處理代碼為例:
a.split(dealid,'\\\\')[0] as dealids,1: 代碼中,如果以“\”作為分隔符的話,那麼就需要4個轉義字元“\\\\”,即
b.split(all,'~') :這裡切分符號是正則表達式,按一個字元分隔沒問題
c. split(all,'[|~]+'): 在[]內部拼接成字元串
3)hive語句在shell腳本中執行
shell語言也有轉義字元,自身直接處理。
而hive語句在shell腳本中執行時,就需要先由shell轉義後,再由hive處理。這個過程又造成二次轉義。
如上面的hive語句寫入shell腳本中,執行是錯誤的,shell先解析,轉義成”|“後傳給hive,hive解析這個轉義字元後,split就無法正確的解析了。
所以,註意hive語句在shell腳本執行時,轉義字元需要翻倍。hive處理的是shell轉義後的語句,必須轉以後正確,才能執行。
註意:是否使用轉義字元是看這個字元在這個語言中有沒有特殊意義,有的話,就需要加上\來進行轉義、
|
轉義字元的使用: |
||||
|
轉義字元 |
無轉義符 |
轉義符\ |
轉義符\\ |
轉義符\\\ |
|
" |
" |
\" |
\\” |
|
|
\ |
不可識別 |
不可識別 |
不可識別 |
\\\\ |
|
/ |
/ |
\/ |
\\/ |
\\\/ |
|
' |
不可識別 |
\' |
不可識別 |
\\\' |
|
~ |
~ |
\~ |
\\~ |
|
|
| |
| |
\| |
\\| |
\\\| |
|
; |
; |
\; |
\\; |
|
|
: |
: |
\: |
\\: |
|
|
, |
, |
\, |
\\, |
|
|
. |
. |
\. |
\\. |
|
|
! |
! |
\! |
\\! |
|
|
( |
( |
\( |
\\( |
|
|
) |
) |
\) |
\\) |
|
|
[ |
不可識別 |
不可識別 |
\\[ |
|
|
] |
] |
\] |
\\] |
|
|
{ |
{ |
\{' |
\\{ |
|
|
} |
} |
\} |
\\} |
|
|
? |
? |
\? |
\\? |
|
|
_ |
_ |
\_ |
\\_ |
|
|
- |
- |
\- |
\\- |
|
|
# |
# |
\# |
\\# |
|
|
## |
## |
\## |
\\## |
\\\## |
|
& |
& |
\& |
\\& |
|
|
^ |
^ |
\^ |
\\^ |
|
|
|
|
|
|
|
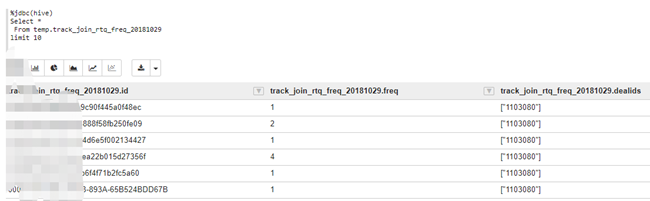
二、案例:原數據表
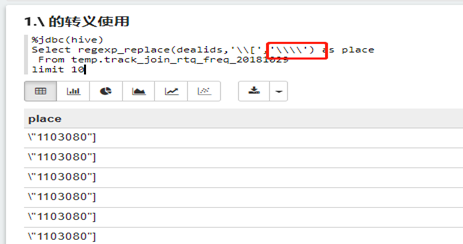
1.\符號
(1)regexp_replace(dealids,'\\[','\\\\')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\\\') as place
From temp.track_join_rtq_freq_20181029
limit 10
註意:


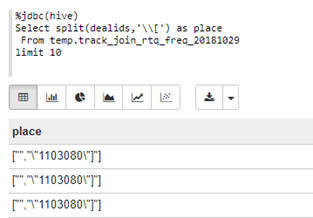
2.[與]符號
(1)\\[:split(dealids,'\\[')
%jdbc(hive)
Select split(dealids,'\\[') as place
From temp.track_join_rtq_freq_20181029
limit 10
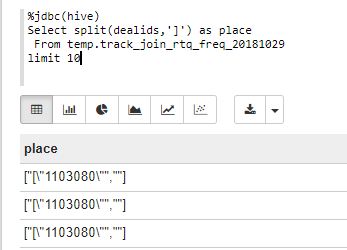
(2)]:split(dealids,']')
%jdbc(hive)
Select split(dealids,']') as place
From temp.track_join_rtq_freq_20181029
limit 10
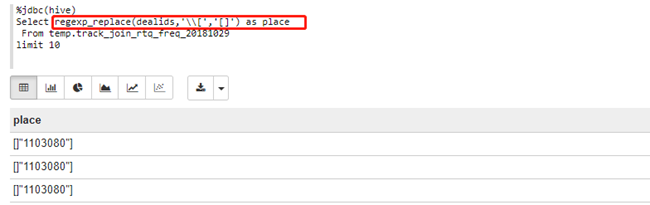
(3)\\[和[]:regexp_replace(dealids,'\\[','[]')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','[]') as place
From temp.track_join_rtq_freq_20181029
limit 10
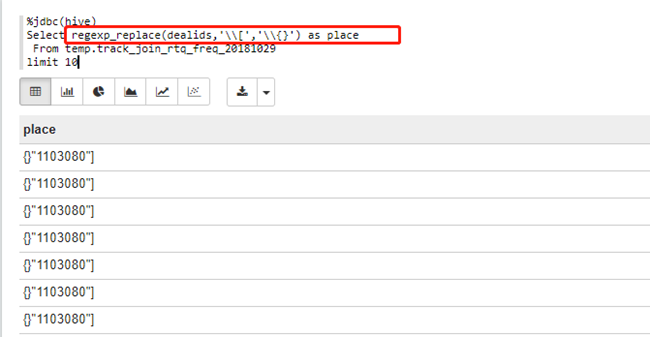
(4)\\[和\\{}:regexp_replace(dealids,'\\[','\\{}')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\{}') as place
From temp.track_join_rtq_freq_20181029
limit 10
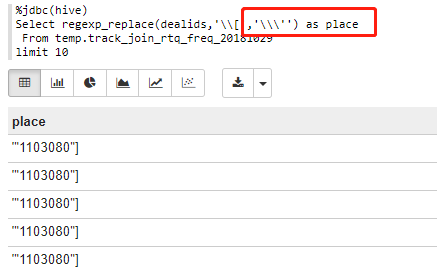
3.’符號
(1)\\\':regexp_replace(dealids,'\\[','\\\'')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\\'') as place
From temp.track_join_rtq_freq_20181029
limit 10