
在安裝和測試HBase之前,我們有必要先瞭解一下HBase是什麼 我們可以通過下麵的資料對其有一定的瞭解: HBase 官方文檔中文版 HBase 深入淺出 我想把我知道的分享給大家,方便大家交流。 ...
在安裝和測試HBase之前,我們有必要先瞭解一下HBase是什麼
我們可以通過下麵的資料對其有一定的瞭解:
我想把我知道的分享給大家,方便大家交流。
以下是本文的大綱:
1.Hadoop集群環境搭建
2.Hbase的介紹
3.單機模式解壓和安裝HBase
3.1.創建t_student表
3.2.查看表t_student
3.3.查看表結構
3.4.插入數據
3.5.查詢table
4.完全分散式模式解壓和安裝HBase
4.1.創建t_student表
4.2.插入數據
4.3.數據從記憶體寫入到磁碟
4.4.再次插入數據
4.5.再次把數據寫入到磁碟
4.6.手動合併文件
4.7.查看文件內容
若有不正之處,還請多多諒解,並希望批評指正。
請尊重作者勞動成果,轉發請標明blog地址
https://www.cnblogs.com/hongten/p/hongten_hadoop_hbase.html
正所謂磨刀不費砍材功,下麵的工具大家可以先下載備用。
環境及工具:
Windows 7 (64位)下麵的虛擬機(64位):VMware-workstation-full-14.0.0-6661328.exe
Linux操作系統:CentOS-6.5-x86_64-bin-DVD1.iso
Xshell:Xshell-6.0.0101p.exe
WinSCP:從windows上面上傳文件到Linux
zookeeper:zookeeper-3.4.6.tar.gz
hadoop:hadoop-2.5.1_x64.tar.gz
鏈接:https://pan.baidu.com/s/1hvdbGUh488Gl1EF2v44BIw
提取碼:ncdd
Hbase: hbase-0.98.9-hadoop2-bin.tar.gz
1.Hadoop集群環境搭建
在做Hbase安裝和測試之前,我們有必要把 Hadoop2集群環境搭建 好。
2.Hbase的介紹
Hadoop Database, 是一個高可靠性,高性能,面向列,可伸縮,實時讀寫的分散式資料庫。 利用Hadoop HDFS作為其文件存儲系統,利用Hadoop MapReduce來處理HBase中的海量數據,利用Zookeeper作為其分散式協同服務 主要用來存儲非結構化和半結構化的鬆散數據(列存NoSQL資料庫) Column Family 列族 HBase表中的每個列都歸屬某個列族,列族必須作為表模式(schema)定義的一部分預先給出,如: create 'test', 'course'; 列名以列族作為首碼,每個'列族'都可以有多個列成員(column);如course:math, course:english,新的列族成語(列)可以隨時按需,動態加入 許可權控制,存儲以及調優都在列族層面進行的; HBase把同一列族裡面的數據存儲在同一目錄下,由幾個文件保存。 HBase體系架構 Client: 包含訪問HBase的介面並維護cache來加快對HBase的訪問 Zookeeper: 1. 保證任何時候,集群中只有一個master 2. 存儲所有Region的定址入口 3. 實時監控Region Server的上線和下線信息,並實時通知master 4. 存儲Hbase的schema和table元數據 Master: 1. 為Region Server分配region 2. 負責Region Server的負載均衡 3. 發現失效的Region Server並重新分配其上的region 4. 管理用戶對table的增刪改操作 Region Server: 1. 維護region,處理對這些region的IO請求 2. 負責切分在運行過程中變的過大的region Rgion: 1. HBase自動把表水平分成多個區域(region),每個region會報錯一個表裡面某段連續的數據;每個表一開始只有一個region,隨著數據不斷插入表,region不斷增大,當增大到一個閾值的時候,region就會等分兩個新的region(裂變) 2. 當table中的行不斷增多,就會有越來越多的region,這樣一張完整的表被保存在多個Region Server上。 Memstore於storefile: 1. 一個region由多個store組成,一個sote對應一個CF(列族) 2. sotre包含位於記憶體中的memstore和位於磁碟的storefile寫操作先寫入memstore,當memstore中的數據達到某個閾值,region server會啟動flashcache進程寫入storefile,每次寫入形成單獨的一個storefile。(這樣在一個region裡面就會產生很多個storefile) 3. 當storefile文件的數量增長到一定閾值後,系統會進行合併(Minor, Major Compaction),在合併過程中貴進行版本合併和刪除工作(Major),形成更大的storefile。 4. 當一個region所有storefile的大小和超過一定閾值後,會把當前的region分割為兩個,並由hmaster分配到相應的region server伺服器,實現負載均衡。 5. 客戶端檢索數據,現在memstore找,找不到再找storefile。
3.單機模式解壓和安裝HBase
--單機模式解壓和安裝HBase tar -zxvf hbase-0.98.9-hadoop2-bin.tar.gz --創建軟鏈 ln -sf /root/hbase-0.98.9-hadoop2 /home/hbase --配置java環境變數 cd /home/hbase/conf/ vi hbase-env.sh --jdk必須在1.6以上 export JAVA_HOME=/usr/java/jdk1.7.0_67 :wq --修改hbase-site.xml文件,數據保存到本地 vi hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>file:///opt/hbase</value> </property> </configuration> :wq --關閉防火牆 service iptables stop --啟動HBase cd /home/hbase/bin/ ./start-hbase.sh --檢查是否已經啟動 jps --查看是否有HMaster進程 --查看監聽的埠 netstat -naptl | grep java --啟動瀏覽器訪問 http://node4:60010
3.1.創建t_student表
--進入hbase cd /home/hbase/bin/ ./hbase shell --創建t_student表 create 't_student' , 'cf1' hbase(main):003:0> create 't_student' , 'cf1' 0 row(s) in 0.4000 seconds
3.2.查看表t_student
--查看表 list hbase(main):004:0> list TABLE t_student 1 row(s) in 0.0510 seconds
3.3.查看表結構
--查看表結構 desc 't_student' hbase(main):005:0> desc 't_student' Table t_student is ENABLED COLUMN FAMILIES DESCRIPTION {NAME => 'cf1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => ' 0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DEL ETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} 1 row(s) in 0.1310 seconds
3.4.插入數據
--插入數據 put 't_student' , '007', 'cf1:name', 'hongten' hbase(main):006:0> put 't_student' , '007', 'cf1:name', 'hongten' 0 row(s) in 0.1750 seconds
3.5.查詢table
--查詢table hbase(main):007:0> scan 't_student' ROW COLUMN+CELL 007 column=cf1:name, timestamp=1541162668222, value=hongten 1 row(s) in 0.0670 seconds
4.完全分散式模式解壓和安裝HBase
--完全分散式模式解壓和安裝HBase --拷貝hbase-0.98.9-hadoop2-bin.tar.gz從節點node1到node2, node3, node4節點上 scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node2:~/ scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node3:~/ scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node4:~/ --解壓縮文件 tar zxvf hbase-0.98.9-hadoop2-bin.tar.gz --創建軟鏈 ln -sf /root/hbase-0.98.9-hadoop2 /home/hbase cd /home/hbase/conf/ vi hbase-site.xml --mycluster為集群名稱 <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> <description>The directory shared by RegionServers.</description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>The mode the cluster will be in. Possible values are false: standalone and pseudo-distributed setups with managed Zookeeper true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)</description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> <description>Comma separated list of servers in the ZooKeeper Quorum. For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com". By default this is set to localhost for local and pseudo-distributed modes of operation. For a fully-distributed setup, this should be set to a full list of ZooKeeper quorum servers. If HBASE_MANAGES_ZK is set in hbase-env.sh this is the list of servers which we will start/stop ZooKeeper on. </description> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/zookeeper</value> <description>Property from ZooKeeper's config zoo.cfg. The directory where the snapshot is stored. </description> </property> :wq --修改regionservers文件,該文件列出所有region server主機的hostname vi regionservers node1 node2 node3 node4 :wq --修改hbase-env.sh文件 vi hbase-env.sh --修改java環境變數 export JAVA_HOME=/usr/java/jdk1.7.0_67 --預設為true,使用hbase自帶的zookeeper --修改為false,使用我們自定義的zookeeper export HBASE_MANAGES_ZK=false :wq --使得Hadoop和HBase關聯起來 --把hadoop的配置文件hdfs-site.xml拷貝到/home/hbase/conf/目錄 cd /home/hbase/conf/ cp -a /home/hadoop-2.5/etc/hadoop/hdfs-site.xml . --把同樣的配置從node1拷貝到node2,node3,node4上面去scp /home/hbase/conf/* root@node2:/home/hbase/conf/scp /home/hbase/conf/* root@node3:/home/hbase/conf/scp /home/hbase/conf/* root@node4:/home/hbase/conf/ --關閉所有節點上的防火牆(node1, node2, node3, node4) service iptables stop --在啟動HBase之前,我們需要確保zookeeper和hadoop都已經啟動 --我們這裡在node1,node2,node3,node4上面都有配置hbase, --啟動的時候,隨便選擇一個節點啟動hbase,由於我們之前有配置免密碼登錄 --所以我們在node1上面啟動hbase cd /home/hbase/bin/ ./start-hbase.sh 輸出結果: [root@node1 bin]# ./start-hbase.sh starting master, logging to /home/hbase/bin/../logs/hbase-root-master-node1.out node3: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node3.out node1: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node1.out node4: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node4.out node2: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node2.out --可以在node4上面啟動master cd /home/hbase/bin/ ./hbase-daemon.sh start master 輸出結果: [root@node4 bin]# ./hbase-daemon.sh start master starting master, logging to /home/hbase/bin/../logs/hbase-root-master-node4.out [root@node4 bin]# jps 28630 HRegionServer 28014 NodeManager 29096 Jps 29004 HMaster 27923 JournalNode 27835 DataNode --瀏覽器輸入 http://node1:60010
我們在瀏覽器裡面輸入http://node1:60010
可以進入Hbase的管理界面,我們可以看到我們在4個節點(node1,node2, node3,node4)上都部署了Region Server。

4.1.創建t_student表
--創建t_student表 create 't_student' , 'cf1'
4.2.插入數據
此時的數據還在memstore裡面(即HBase的管理的記憶體裡面)
--插入數據 put 't_student' , '007', 'cf1:name', 'hongten'
4.3.數據從記憶體寫入到磁碟
把memstore的數據寫入到storefile裡面
--把數據從記憶體寫入到磁碟 flush 't_student'
4.4.再次插入數據
put 't_student' , '001', 'cf1:name', 'Tom' put 't_student' , '002', 'cf1:name', 'Dive'
4.5.再次把數據寫入到磁碟
--把數據從記憶體寫入到磁碟 flush 't_student'
此時我們可以看到,在HDFS上面有兩個文件
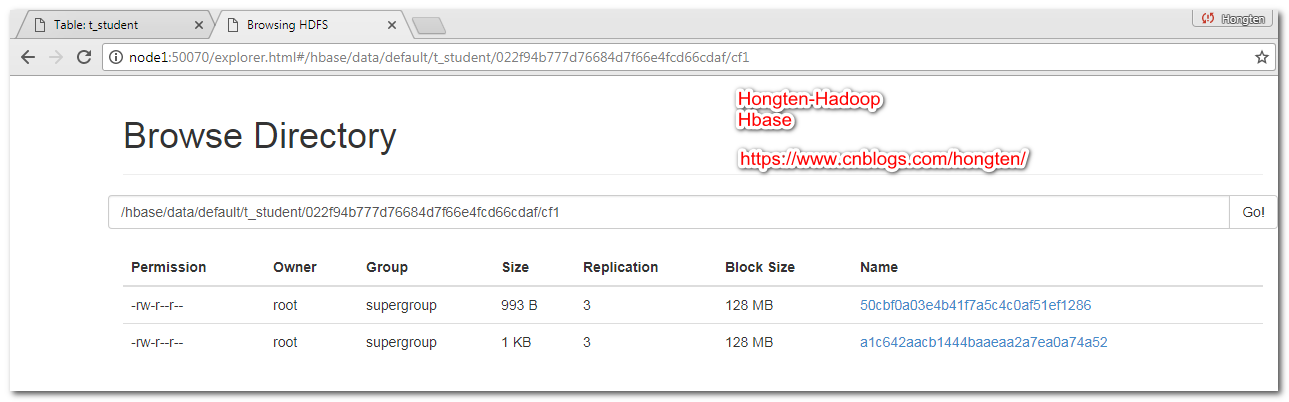
4.6.手動合併文件
--手動合併文件 major_compact 't_student'
合併之後,兩個文件變成了一個文件

4.7.查看文件內容
上面文件的全路徑
--查看文件內容 [root@node1 bin]# ./hbase hfile -p -f /hbase/data/default/t_student/022f94b777d76684d7f66e4fcd66cdaf/cf1/8efb9596ac774e839f0775efc55a8ab7 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hbase-0.98.9-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 2018-11-02 08:55:29,281 INFO [main] Configuration.deprecation: fs.default.name is deprecated. Instead, use fs.defaultFS 2018-11-02 08:55:29,429 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available 2018-11-02 08:55:29,732 INFO [main] util.ChecksumType: Checksum using org.apache.hadoop.util.PureJavaCrc32 2018-11-02 08:55:29,734 INFO [main] util.ChecksumType: Checksum can use org.apache.hadoop.util.PureJavaCrc32C K: 001/cf1:name/1541173663169/Put/vlen=3/mvcc=0 V: Tom K: 002/cf1:name/1541173670882/Put/vlen=4/mvcc=0 V: Dive K: 007/cf1:name/1541173242683/Put/vlen=7/mvcc=0 V: hongten Scanned kv count -> 3
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,覺得有用打賞點哦!你的支持是我最大的動力。謝謝。
Hongten博客排名在100名以內。粉絲過千。
Hongten出品,必是精品。
E | [email protected] B | http://www.cnblogs.com/hongten
========================================================


