
明天老王要給我們講JVM的知識,提前發了一個小Demo給我們看,代碼如下: 運行上述代碼,結果毫無疑問,電腦瞬間開始狂躁起來,過了十幾秒,然後G了 基於JDK1.8運行的,估計老版本會崩的更快。。。 如果不計算記憶體,這個HashMap一共要插入4000*4000*4個對象,但是其實只有4個是不重覆的 ...
明天老王要給我們講JVM的知識,提前發了一個小Demo給我們看,代碼如下:
package demo; import java.util.*; public class Demo { public static class SkuKey { private String category; private String skuProperties; public SkuKey(String category, String skuProperties) { this.category = category; this.skuProperties = skuProperties; } } public static class Sku{ String category; String skuProperties; String name; public Sku(String category, String skuProperties, String name) { this.category = category; this.skuProperties = skuProperties; this.name = name; } } public static void main(String[] args) { List<Sku> skus = new ArrayList(); skus.add(new Sku("0001", "1:1;2:2;3:3", "sku-1")); skus.add(new Sku("0002", "1:1;2:2;3:3", "sku-2")); skus.add(new Sku("0003", "1:1;2:2;3:3", "sku-3")); skus.add(new Sku("0004", "1:1;2:2;3:3", "sku-4")); Map<SkuKey, Sku> skuByKey = new HashMap<>(); for(int i = 0; i< 4000*4000; i++) { skus.forEach( sku -> skuByKey.put(new SkuKey(sku.category, sku.skuProperties), sku ) ); } System.out.println("build map complete"); } }
運行上述代碼,結果毫無疑問,電腦瞬間開始狂躁起來,過了十幾秒,然後G了
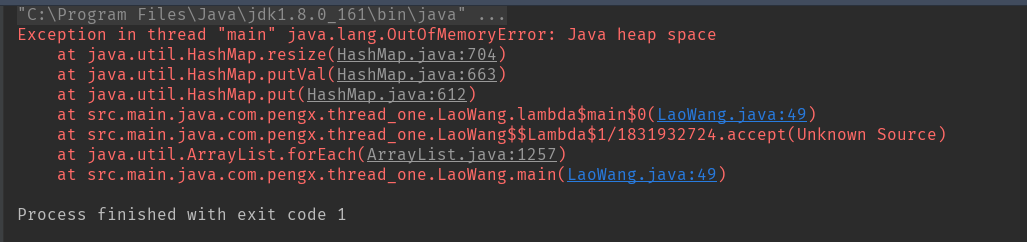
基於JDK1.8運行的,估計老版本會崩的更快。。。
如果不計算記憶體,這個HashMap一共要插入4000*4000*4個對象,但是其實只有4個是不重覆的,所以其實我們只要重寫hashCode和equals方法就可以解決這個問題了;
public static class SkuKey { private String category; private String skuProperties; public SkuKey(String category, String skuProperties) { this.category = category; this.skuProperties = skuProperties; } public int hashCode(){ return category.hashCode() + skuProperties.hashCode(); } public boolean equals(Object obj) { SkuKey skuKey = (SkuKey)obj; return this.category.equals(skuKey.category) && this.skuProperties.equals(skuKey.skuProperties); } }
等明天培訓之後再總結為何以這個為例子來引入JVM的深入研究!


