
聚簇索引是對磁碟上實際數據重新組織以按指定的一個或多個列的值排序的演算法。特點是存儲數據的順序和索引順序一致。一般情況下主鍵會預設創建聚簇索引,且一張表只允許存在一個聚簇索引。 在《資料庫原理》一書中是這麼解釋聚簇索引和非聚簇索引的區別的:聚簇索引的葉子節點就是數據節點,而非聚簇索引的葉子節點仍然是索 ...
聚簇索引是對磁碟上實際數據重新組織以按指定的一個或多個列的值排序的演算法。特點是存儲數據的順序和索引順序一致。一般情況下主鍵會預設創建聚簇索引,且一張表只允許存在一個聚簇索引。
在《資料庫原理》一書中是這麼解釋聚簇索引和非聚簇索引的區別的:聚簇索引的葉子節點就是數據節點,而非聚簇索引的葉子節點仍然是索引節點,只不過有指向對應數據塊的指針。
因此,MYSQL中不同的數據存儲引擎對聚簇索引的支持不同就很好解釋了。下麵,我們可以看一下MYSQL中MYISAM和INNODB兩種引擎的索引結構
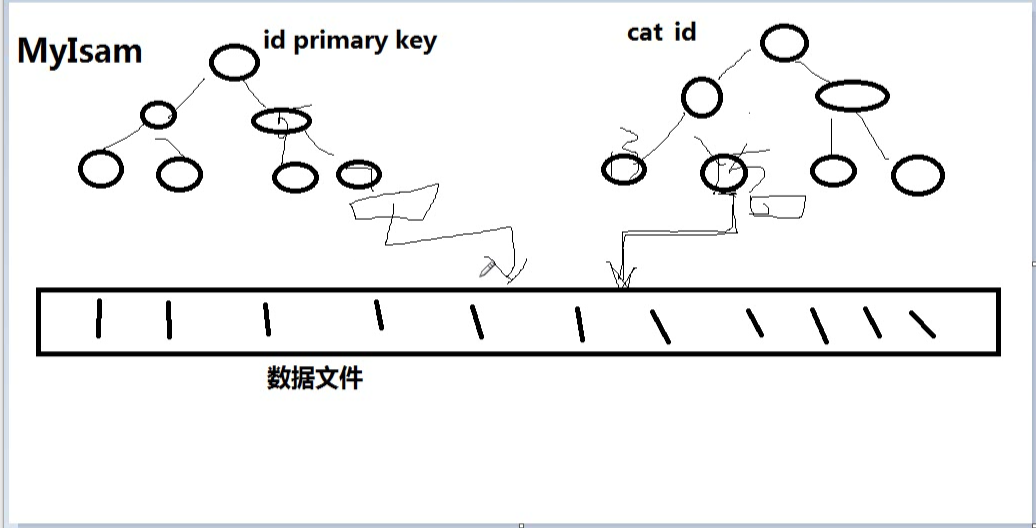
myisam的索引存儲圖如下,可以看出,無論是id還是cat_id,下麵都存儲有執行物理地址的值。通過主鍵索引或者次索引來查詢數據的時候,都是先查找到物理位置,然後再到物理位置上去尋找數據。
innodb的索引存儲圖如下,我們會發現,主鍵索引下麵直接存儲有數據,而次索引下,存儲的是主鍵的id。通過主鍵查找數據的時候,就會很快查找到數據,但是通過次索引查找數據的時候,需要先查找到對應的主鍵id,然後才能查找到對應的數據。
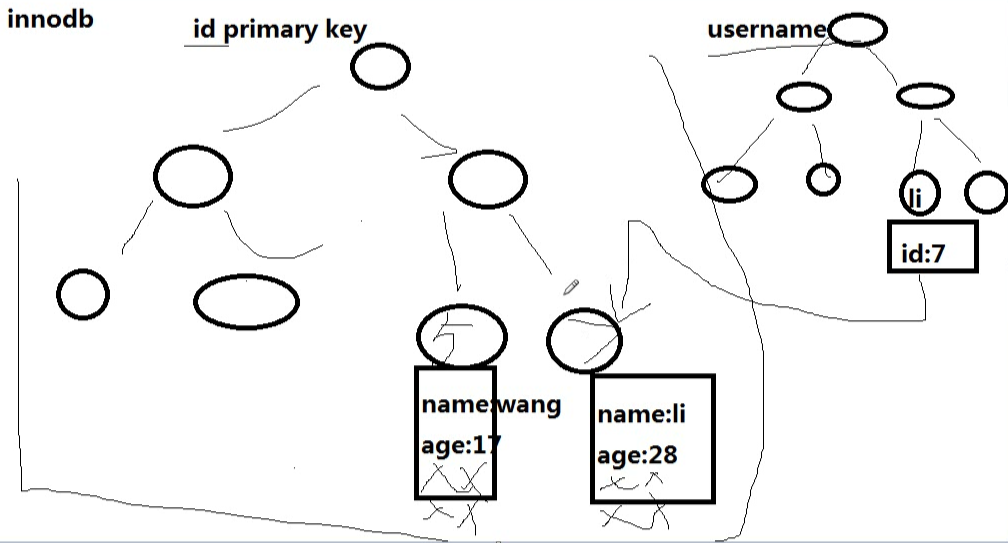
nnodb的主索引文件上 直接存放該行數據,稱為聚簇索引,次索引指向對主鍵的引用
myisam中, 主索引和次索引,都指向物理行(磁碟位置).
註意: innodb來說,
1: 主鍵索引 既存儲索引值,又在葉子中存儲行的數據
2: 如果沒有主鍵, 則會Unique key做主鍵
3: 如果沒有unique,則系統生成一個內部的rowid做主鍵.
4: 像innodb中,主鍵的索引結構中,既存儲了主鍵值,又存儲了行數據,這種結構稱為”聚簇索引”

