
一、前言 在之前的系列文章中介紹了redis的入門、持久化以及複製功能,如果不瞭解請移步至redis系列進行閱讀,當然我也是抱著學習的知識分享,如果有什麼問題歡迎指正,也歡迎大家轉載。而本次將介紹哨兵集群相關知識,包括哨兵集群部署、哨兵原理、相關配置、故障轉移等內容,正因為redis有了哨兵機制,而 ...
一、前言
在之前的系列文章中介紹了redis的入門、持久化以及複製功能,如果不瞭解請移步至redis系列進行閱讀,當然我也是抱著學習的知識分享,如果有什麼問題歡迎指正,也歡迎大家轉載。而本次將介紹哨兵集群相關知識,包括哨兵集群部署、哨兵原理、相關配置、故障轉移等內容,正因為redis有了哨兵機制,而在很多企業(包括筆者自身的公司)採用的是哨兵模式下的redis主從。
二、哨兵(Sentinel)簡介
哨兵(後文統稱sentinel)是官方推薦的的高可用(HA)解決方案。在之前的文章中介紹過redis的主從高可用解決方案,這種方案的缺點在於當master故障時候,需要手動進行故障恢復,而sentinel是一個獨立運行的進程,它能監控一個或多個主從集群,並能在master故障時候自動進行故障轉移,更為理想的是sentinel本身是一個分散式系統,其分散式設計思想有點類似於zookeeper,當某個時候Master故障後,sentinel集群採用Raft演算法來選取Leader,故障轉移由Leader完成。而對於客戶端來說,操作redis的主節點,我們只需要詢問sentinel,sentinel返回當前可用的master,這樣一來客戶端不需要關註的切換而引發的客戶端配置變更。一個典型的sentinel架構如下圖:
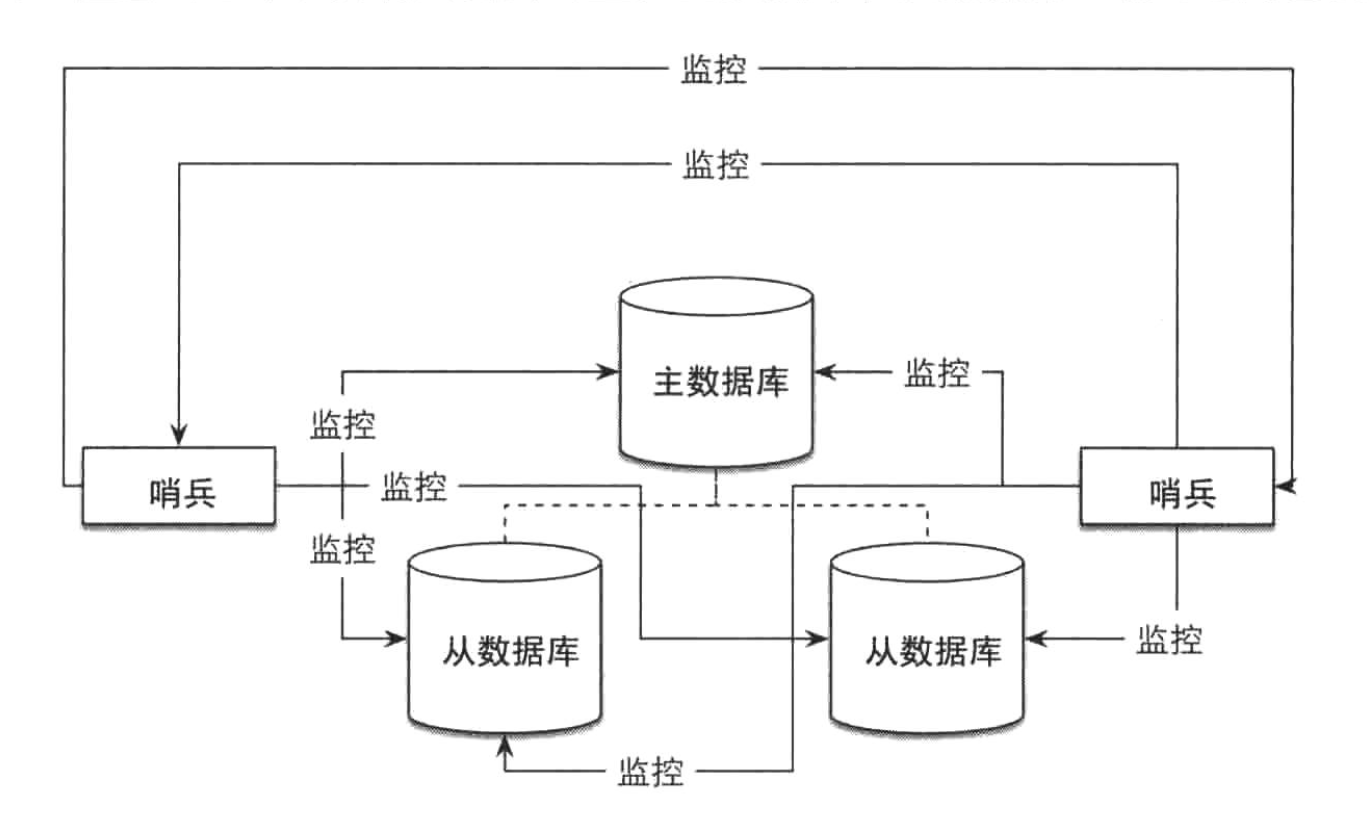
sentinel的主要功能:
- 監控(Monitoring): sentinel 會不斷地檢查Master和Slave是否運作正常。
- 通知(Notification):當被監控的某個Redis實例出現問題時, 哨兵(sentinel) 可以通過 API 向管理員或者其他應用程式發送通知。
- 自動故障遷移(Automatic failover):當一個Master不能正常工作時,sentinel)會開始一次自動故障遷移操作,它會將失效Master的其中一個Slave升級為新的Master, 並讓失效Master的其他Slave改為複製新的Master; 當客戶端試圖連接失效的Master時,集群也會向客戶端返回新Master的地址,使得集群可以使用Master代替失效Master。
-
配置中心(Configuration provider):如果故障轉移發生了,sentinel會返回新的master地址。
三、Sentinel集群部署
環境規劃
本次部署過程中將分別部署三個哨兵節點來監控一主二從的redis集群,主從的搭建過程可以參考筆者博文《redis系列--主從複製以及redis複製演進》,以下是環境規則:
- 哨兵節點:10.1.210.32:26379、10.1.210.33:26379、10.1.210.34:26379
- redis實例:10.1.210.69:6379(主)、10.1.210.69:6380(從)、10.1.210.69:6381(從)
安裝配置
sentinel安裝與redis安裝過程一致,請參考redis系列文章,而在源碼中,redis提供了參考配置示例sentinel.conf(可以使用命令grep -E -v ^# sentinel.conf 查看),如下:
port 26379 dir /tmp sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000
配置說明:
sentinel monitor mymaster 127.0.0.1 6379 2
這行配置代表sentinel監控的master名字叫做mymaster(可以自己取),地址是127.0.0.1,埠是6379。最後一個2代表當sentinel集群中有2個sentinel認為master故障時候才判定master真正不可用。官方把該參數稱為quorum,在後續選舉領頭哨兵時候會用到,在下文將進行介紹。
sentinel down-after-milliseconds mymaster 30000
sentinel會向master發送心跳PING來確認master是否存活,如果master在“一定時間範圍”內不回應PONG 或者是回覆了一個錯誤消息,那麼這個sentinel會主觀地(單方面地)認為這個master已經不可用了(subjectively down, 也簡稱為SDOWN)。而這個down-after-milliseconds就是用來指定這個“一定時間範圍”的,單位是毫秒,在這裡表示30秒時間內master不回應PONG則主觀不可用。
sentinel parallel-syncs mymaster 1
該配置表明在發生failover主備切換時候,最多允許多少個slave同時同步新的master。這個數字越小,完成failover所需的時間就越長,但是如果這個數字越大,就意味著越多的slave因為replication而不可用。可以通過將這個值設為 1 來保證每次只有一個slave處於不能處理命令請求的狀態。
sentinel failover-timeout mymaster 180000
failover-time超時時間,當failover開始後,在此時間內仍然沒有觸發任何failover操作,當前sentinel將會認為此次failover失敗,單位毫秒。
不難發現關於sentinel的配置都是固定格式如下:
sentinel <option_name> <master_name> <option_value>
運行Sentinel
啟動sentinel的方式有兩種,兩種方式都必須指定配置文件:
#第一種(推薦) redis-sentinel /path/to/sentinel.conf #第二種 redis-server /path/to/sentinel.conf --sentinel
以下是筆者三個節點的配置文件,並同時拷貝到三個節點進行啟動:


bind 10.1.210.32 #IP地址 port 26379 #埠 dir /opt/db/redis # 數據存儲目錄 daemonize yes #後臺運行 logfile /opt/db/redis/sentinel.log #日誌 sentinel monitor mymaster 10.1.210.69 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 18000010.1.210.32
bind 10.1.210.33 #IP地址 port 26379 #埠 dir /opt/db/redis # 數據存儲目錄 daemonize yes #後臺運行 logfile /opt/db/redis/sentinel.log #日誌 sentinel monitor mymaster 10.1.210.69 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 18000010.1.210.33
bind 10.1.210.34 #IP地址 port 26379 #埠 dir /opt/db/redis # 數據存儲目錄 daemonize yes #後臺運行 logfile /opt/db/redis/sentinel.log #日誌 sentinel monitor mymaster 10.1.210.69 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 18000010.1.210.34
通過redis-sentinel /opt/db/redis/sentinel.conf啟動每個sentinel,以下是啟動日誌(可以發現sentinel自動通過master發現slave和其他sentinel):

此時,一個sentinel集群就搭建完成。
sentinel相關命令
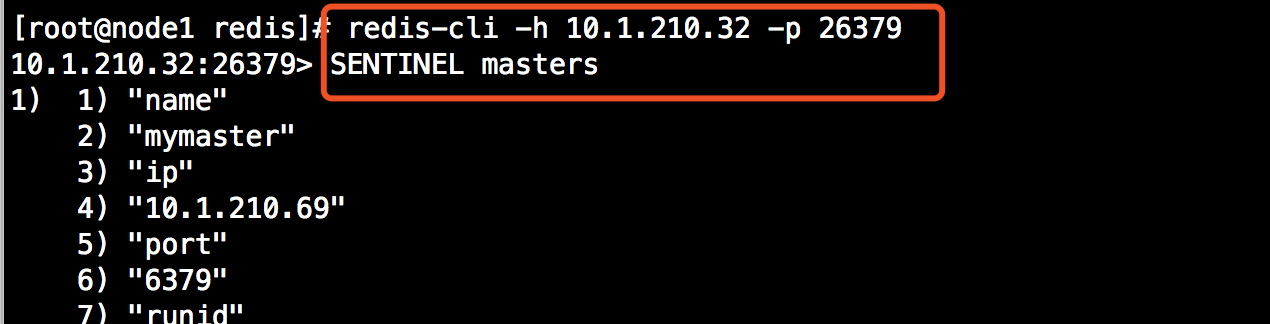
和redis一樣,sentinel可以通過客戶端使用命令操作,例如查看master狀態SENTINEL masters,示例:
以下是所有命令以及解釋:
SENTINEL masters #列出所有被監視的master,以及當前master狀態 SENTINEL master <master name> #列出指定的master SENTINEL slaves <master name> #列出給定master的所有slave以及slave狀態 SENTINEL sentinels <master name> #列出監控指定的master的所有sentinel SENTINEL get-master-addr-by-name <master name> #返回給定master名字的伺服器的IP地址和埠號 SENTINEL reset <pattern> #重置所有匹配pattern表達式的master狀態 SENTINEL failover <master name> #當msater失效時, 在不詢問其他 Sentinel 意見的情況下, 強制開始一次自動故障遷移,但是它會給其他sentinel發送一個最新的配置,其他sentinel會根據這個配置進行更新 SENTINEL ckquorum <master name> #檢查當前sentinel的配置能否達到故障切換master所需的數量,此命令可用於檢測sentinel部署是否正常,正常返回ok SENTINEL flushconfig #強制sentinel將運行時配置寫入磁碟,包括當前sentinel狀態
四、Sentinel原理
SDOWN和ODOWN
在介紹sentinel原理之前,需要瞭解的兩個概念SDOWN和ODOWN:
- SDOWN:全拼Subjectively Down,稱為主觀下線,指的是單個sentinel對redis實例作出的下線狀態判斷。
- ODOWN:全拼Objectively Down,稱為客戶端下線,指多個 Sentinel 實例在對同一個redis做出 SDOWN 判斷,並且通過 SENTINEL is-master-down-by-addr 命令互相交流之後,得出的redis實例下線判斷。(一個 Sentinel 可以通過向另一個 Sentinel 發送 SENTINEL is-master-down-by-addr 命令來詢問對方是否認為給定的redis實例已下線。)
從sentinel的角度來看,如果發送了PING心跳後,在一定時間內沒有收到合法的回覆,就達到了SDOWN的條件。這個時間在配置中通過master-down-after-milliseconds參數配置。
當sentinel發送PING後,以下回覆之一都被認為是合法的:
PING replied with +PONG. PING replied with -LOADING error. PING replied with -MASTERDOWN error.
其它任何回覆(或者根本沒有回覆)都是不合法的。
從SDOWN切換到ODOWN不需要任何一致性演算法,只需要一個gossip協議:如果一個sentinel收到了足夠多的sentinel發來消息告訴它某個master已經down掉了,SDOWN狀態就會變成ODOWN狀態。如果之後master可用了,這個狀態就會相應地被清理掉。
真正進行failover需要一個授權的過程,這個授權的過程即是leader選取過程,但是所有的failover都開始於一個ODOWN狀態。ODOWN狀態只適用於master,對於不是master的redis節點sentinel之間不需要任何協商,slaves和sentinel不會有ODOWN狀態。
實現原理
一個sentinel啟動時會讀取配置文件,並通過sentinel monitor <master-name> <ip> <port> <quorum>配置尋找要監控的主資料庫,這個配置在之前已經進行詳細說明,其中master-name是由一個大小寫字母、數字、和“._-”組成的資料庫主庫名字,為了考慮到主庫的IP地址和埠可能在故障切換後發生變化,所以還需要ip和port來標示這個主庫。一個哨兵可監控多個主從系統從而形成網狀結構,正如在前面簡介的圖示一樣。
sentinel啟動後,會與監控的資料庫建立兩條連接,如下圖(主庫10.1.210.69:6379與10.1.210.32的sentinel節點兩條鏈接):

這兩個連接與普通客戶端一樣,其中一條連接用來訂閱master的__sentinel__:hello頻道用於獲取其他監控該資料庫的sentinel節點信息,另外一條用於哨兵定期向主資料庫發送INFO等命令獲取主庫本身信息,原因在於當客戶端進入訂閱模式以後只能接受消息,不能發送命令,所以還需要建立一條連接。
與監控的主庫建立連接完成後,sentinel定時執行以下操作:
- 每10s會向主資料庫和從資料庫發送INFO命令;
- 每1s向master、slave以及其他哨兵節點發送PING命令;
- 每2s向master和slave的__sentiel__:hello頻道發送自己的信息來宣佈自己的存在,同時該過程也是實現哨兵之間自動發現的基礎;
這三個操作貫穿了哨兵整個生命周期,非常重要,也是其原理的核心,所以以下將詳細介紹該操作過程。
首先,sentinel啟動後,向主庫發送INFO命令使得sentinel可以獲取當前主庫的相關信息(包括運行的ID,複製信息、以及屬於該主庫的從庫節點信息),這也是為什麼在配置監控時候只需要配置監控的主庫信息sentinel就自動找到其對應的從庫,進而實現從庫的監控。而後和每個從庫同樣建立兩個連接,這兩個連接和上文介紹的與主庫的連個連接完全一致,在此之後,哨兵會每10s定時向已知所有主從發送INFO命令獲取信息更新併進行相應操作,比如對新增的從庫建立連接並加入監控隊列、又或者是主庫信息發生變化(由failover引起的)進行信息更新等。
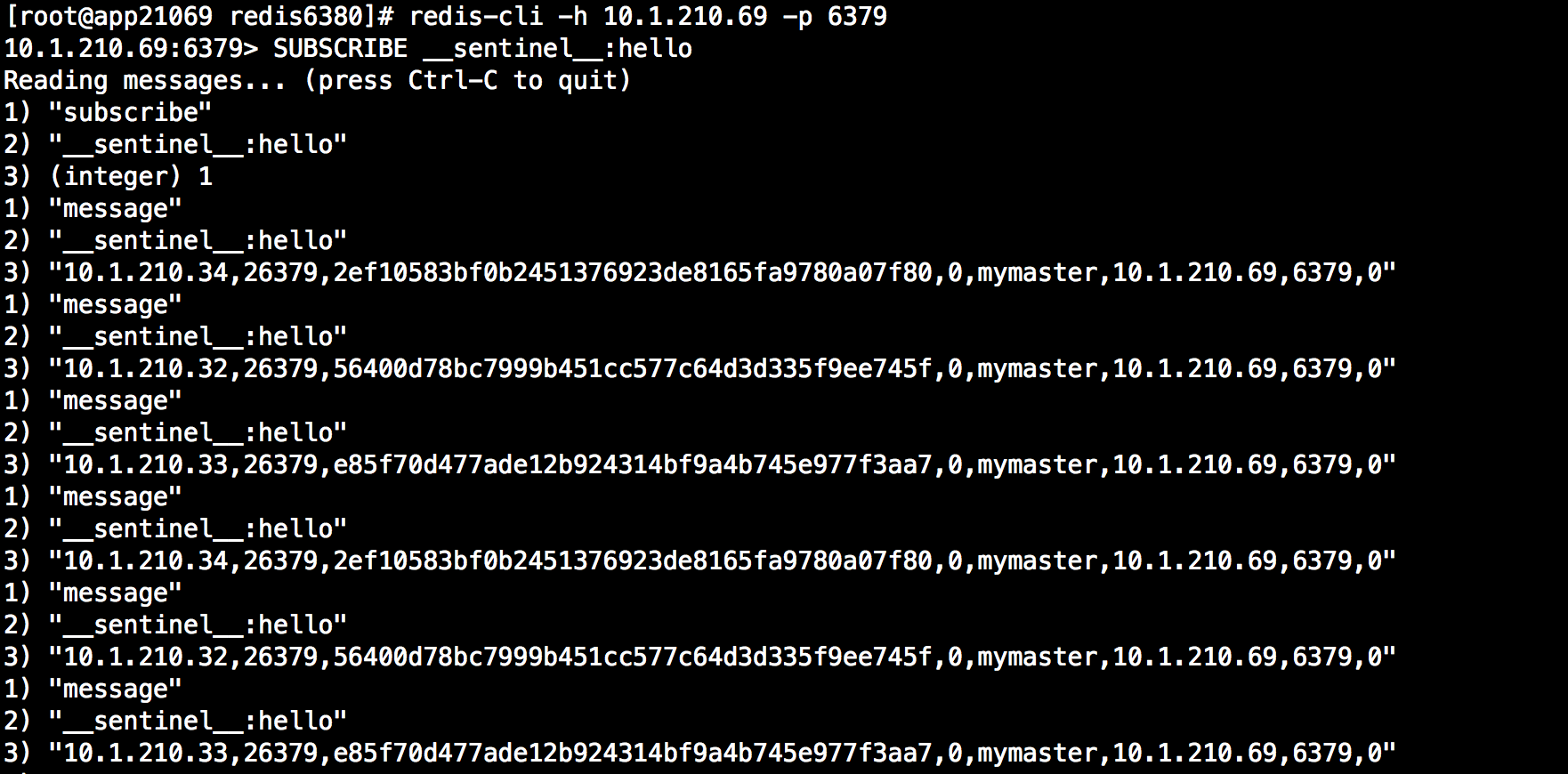
接下來哨兵向master和slave的__sentinel__:hello頻道發送信息與同樣監控該redis示例的其他哨兵分享自己的信息。發送的消息內容為:
<哨兵地址> ,<哨兵埠>,<哨兵運行的ID>,<哨兵配置的版本>,<主庫名稱>,<主庫地址>,<主庫埠>,<主庫配置版本>,該消息包含了哨兵基本信息以及監控的主庫信息,當其他sentinel收到消息後會判斷發消息的哨兵是不是新的哨兵,如果是則將其加入已發現的哨兵列表,並創建一個到其的連接(與資料庫不同)哨兵與哨兵之間只會創建一條連接用於發送PING命令,同時sentinel會判斷主資料庫的配置版本,如果該版本比記錄資料庫版本高,則更新主資料庫的數據,其作用在後續介紹。
實現了自動發現從資料庫和其他sentinel節點後,sentinel後續要做的任務是定時監控這些已經發現的主從節點和sentinel節點是否線上。這種監控實現方式是在通過一定時間間隔發送PING命令實現,時間間隔配置通過down-after-milliseconds指定,當超過down-after-milliseconds配置的時間後,如果被PING的資料庫或者sentinel未回覆,則哨兵認為其主觀下線(主觀下線在上面已經介紹了),如果該節點是主庫sentinel會進一步進行判斷是否需要對其進行故障恢復(failover):sentinel會發送SENTINEL is-master-down-by-addr命令詢問其他sentinel節點是否也認為該主庫主觀下線,如果達到指定數量(在示例配置中也進行了說明,示例配置的是2)時,哨兵會認為其客觀下線,並選取領頭的哨兵(leader)進行故障恢復,選舉過程後續介紹。
選舉完零頭哨兵後,領頭哨兵會開始對主資料庫進行故障恢復,這一過程稱為failover,在選取新的master時候,sentinel會考慮以下情況:
- 跟master斷開連接的時長
- slave的優先順序 (由slave-priority配置指定)
- 複製偏移量offset
- 實例運行的id(run id)
具體的選取順序如下:
如果一個slave跟master斷開連接已經超過了down-after-milliseconds的10倍,外加master宕機的時長,那麼slave就被認為不適合選舉為master,計算公式如下:
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
接下來會對slave進行排序
- 按照slave優先順序進行排序,slave-priority越低,優先順序就越高;
- 如果slave priority相同,那麼比較複製偏移量,offset越靠後(越大)則表明和舊的主庫數據同步越接近,優先順序就越高 ;
- 如果上面兩個條件都相同,那麼選擇一個run id最小的從庫;
選出從庫後,零頭哨兵將向從資料庫發送SLAVEOF NO ONE命令升級其為新的主庫,然後在向其他從庫發送SLAVEOF命令將從的主庫升級到最新的主庫,最後更新內部記錄將已經停止的主庫更新為新的主庫的從庫,使得當該故障的主庫再次恢復時候自動以從庫角色繼續提供服務,從啟動到故障恢復完成這一些列過程即是哨兵的工作的完整流程也是其原理所在。
領頭哨兵選舉
在原理中提及到了,當sentinel發現主庫客觀下線時候會進行領頭哨兵選舉進行故障恢復,其選舉演算法採用Raft演算法,這也為什麼說其設計思想類似與zookpeer,選舉過程大體如下:
- 發現主庫客觀下線的哨兵節點(這裡稱為A)向每個哨兵節點發送命令要求對方選舉自己為領頭哨兵(leader);
- 如果目標哨兵沒有選舉過其他人,則同意將A選舉為領頭哨兵;
- 如果A發現有超過半數且超過quorum參數值的哨兵節點同意選自己成為領頭哨兵,則A哨兵成功選舉為領頭哨兵。
- 當有多個哨兵節點同時參與領頭哨兵選舉時,出現沒有任何節點當選可能,此時每個參選節點等待一個隨機時間進行下一輪選舉,直到選出領頭哨兵。
配置版本號作用
同樣,在原理介紹時候提及到了master的配置版本號,當一個sentinel被授權後,它將會獲得宕掉的master的一份最新配置版本號,當failover執行結束以後,這個版本號將會被用於最新的配置。因為大多數sentinel都已經知道該版本號已經被要執行failover的sentinel拿走了,所以其他的sentinel都不能再去使用這個版本號。這意味著,每次failover都會附帶有一個獨一無二的版本號。我們將會看到這樣做的重要性。
而且,sentinel集群都遵守一個規則:如果sentinel A推薦sentinel B去執行failover,A會等待一段時間後,自行再次去對同一個master執行failover,這個等待的時間是通過failover-timeout配置項去配置的。從這個規則可以看出,sentinel集群中的sentinel不會再同一時刻併發去failover同一個master,第一個進行failover的sentinel如果失敗了,另外一個將會在一定時間內進行重新進行failover,以此類推。
sentinel保證了活躍性:如果大多數sentinel能夠互相通信,最終將會有一個被授權去進行failover.
sentinel也保證了安全性:每個試圖去failover同一個master的sentinel都會得到一個獨一無二的版本號。
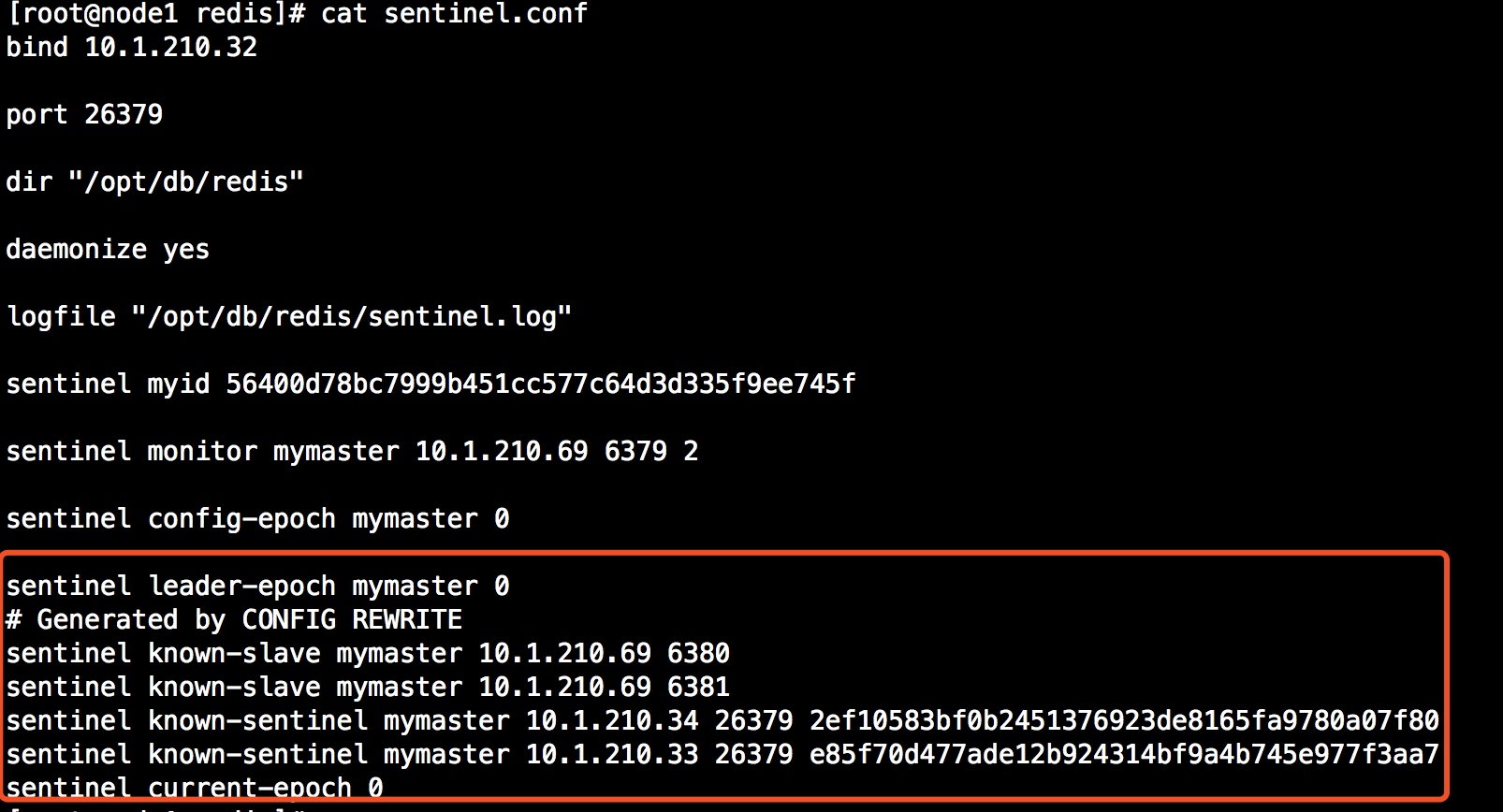
五、Sentinel狀態持久化
snetinel的狀態會被持久化地寫入sentinel的配置文件中。每次當收到一個新的配置時,或者新創建一個配置時,配置會被持久化到硬碟中,並帶上配置的版本戳。這意味著,可以安全的停止和重啟sentinel進程。下麵是被重寫的配置文件截圖:
七、配置傳播
一旦一個sentinel成功地對一個master進行了failover,它將會把關於master的最新配置通過廣播形式通知其它sentinel,其它的sentinel則更新對應master的配置,一個faiover要想被成功實行,sentinel必須能夠向選為master的slave發送SLAVE OF NO ONE命令,然後能夠通過INFO命令看到新master的配置信息。
當將一個slave選舉為master併發送SLAVE OF NO ONE`後,即使其它的slave還沒針對新master重新配置自己,failover也被認為是成功了的,然後所有sentinels將會發佈新的配置信息。
新配在集群中相互傳播的方式,就是為什麼我們需要當一個sentinel進行failover時必須被授權一個版本號的原因。
每個sentinel使用發佈/訂閱的方式持續地傳播master的配置版本信息,配置傳播的發佈/訂閱管道是:__sentinel__:hello,我們可以通過訂閱其頻道查看頻道中的消息,如下:
因為每一個配置都有一個版本號,所以以版本號最大的那個為標準。例如:假設有一個名為mymaster的地址為10.1.210.69:6379。一開始,集群中所有的sentinel都知道這個地址,於是為mymaster的配置打上版本號1。一段時候後mymaster死了,有一個sentinel被授權用版本號2對其進行failover。如果failover成功了,假設地址改為了10.1.210.69:6380,此時配置的版本號為2,進行failover的sentinel會將新配置廣播給其他的sentinel,由於其他sentinel維護的版本號為1,發現新配置的版本號為2時,版本號變大了,說明配置更新了,於是就會採用最新的版本號為2的配置。
八、結束語
從redis的入門再到哨兵模式,再到平時使用其API進行相關操作,通過一段時間的研究對redis也算有了一定層次的認識,所以把這些過程都記錄下來,分享給其他人,希望有更多的人不僅知道如何使用,更能明白其中的原理,在出問題時候能即使的定位問題。當然可能在文章中可能存在不正確的地方也歡迎大家指正,畢竟沒有源碼級別的理解。最後可能需要研究的部分就是redis的集群,後續在研究完之後寫文章介紹,這也算對redis有一個比較全面的認識。


