
今天,上海尚學堂大數據培訓班畢業的一位學生去參加易普軟體公司面試,應聘的職位是大數據開發。面試官問了他10個問題,主要集中在Hbase、Spark、Hive和MapReduce上,基礎概念、特點、應用場景等問得多。看來,還是非常註重基礎的牢固。整個大數據開發技術,這幾個技術知識點占了很大一部分。那本 ...
今天,上海尚學堂大數據培訓班畢業的一位學生去參加易普軟體公司面試,應聘的職位是大數據開發。面試官問了他10個問題,主要集中在Hbase、Spark、Hive和MapReduce上,基礎概念、特點、應用場景等問得多。看來,還是非常註重基礎的牢固。整個大數據開發技術,這幾個技術知識點占了很大一部分。那本篇文章就著重介紹一下這幾個技術知識點。
一、Hbase
1.1、Hbase是什麼?
HBase是一種構建在HDFS之上的分散式、面向列的存儲系統。在需要實時讀寫、隨機訪問超大規模數據集時,可以使用HBase。
儘管已經有許多數據存儲和訪問的策略和實現方法,但事實上大多數解決方案,特別是一些關係類型的,在構建時並沒有考慮超大規模和分散式的特點。許多商家通過複製和分區的方法來擴充資料庫使其突破單個節點的界限,但這些功能通常都是事後增加的,安裝和維護都和複雜。同時,也會影響RDBMS的特定功能,例如聯接、複雜的查詢、觸發器、視圖和外鍵約束這些操作在大型的RDBMS上的代價相當高,甚至根本無法實現。
HBase從另一個角度處理伸縮性問題。它通過線性方式從下到上增加節點來進行擴展。HBase不是關係型資料庫,也不支持SQL,但是它有自己的特長,這是RDBMS不能處理的,HBase巧妙地將大而稀疏的表放在商用的伺服器集群上。
HBase 是Google Bigtable 的開源實現,與Google Bigtable 利用GFS作為其文件存儲系統類似, HBase 利用Hadoop HDFS 作為其文件存儲系統;Google 運行MapReduce 來處理Bigtable中的海量數據, HBase 同樣利用Hadoop MapReduce來處理HBase中的海量數據;Google Bigtable 利用Chubby作為協同服務, HBase 利用Zookeeper作為對應。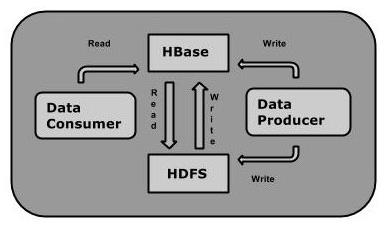
1.2、HBase的特點
◆大:一個表可以有上億行,上百萬列。
◆面向列:面向列表(簇)的存儲和許可權控制,列(簇)獨立檢索。
◆稀疏:對於為空(NULL)的列,並不占用存儲空間,因此,表可以設計的非常稀疏。
◆無模式:每一行都有一個可以排序的主鍵和任意多的列,列可以根據需要動態增加,同一張表中不同的行可以有截然不同的列。
◆數據多版本:每個單元中的數據可以有多個版本,預設情況下,版本號自動分配,版本號就是單元格插入時的時間戳。
◆數據類型單一:HBase中的數據都是字元串,沒有類型。
更多信息閱讀:《Hbase簡介》、《Hbase體系架構和集群安裝》、《HBase數據模型》
二、Spark
Spark是Apache的一個頂級項目,是一個快速、通用的大規模數據處理引擎。Apache Spark是一種快速、通用的集群計算系統。它提供了Java、Scala、Python和R的高級API,以及一個支持通用執行圖的優化引擎。它還支持豐富的高級工具集,包括用於SQL和結構化數據處理的Spark SQL、用於機器學習的MLlib、圖形處理的GraphX和Spark流。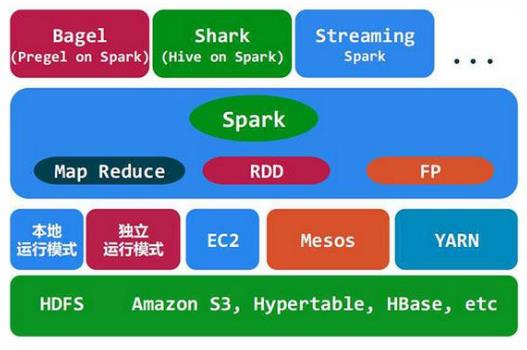
Spark基於map reduce演算法實現的分散式計算,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是Job中間輸出和結果可以保存在記憶體中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需要迭代的Mapreduce的演算法。
Spark的中間數據放到記憶體中,對於迭代運算效率更高。Spark更適合於迭代運算比較多的ML和DM運算。因為在Spark裡面,有RDD的抽象概念。Spark比Hadoop更通用。
Spark可以用來訓練推薦引擎(Recommendation Engine)、分類模型(Classification Model)、回歸模型(Regression Model)、聚類模型(Clustering Model)。
更多關於Spark的文章閱讀:《【上海大數據培訓】Spark集群運行、讀取、寫入Hbase數據》、《【上海大數據培訓】Spark集群的運行過程》
三、Hive
3.1、Hive是什麼
◆由Facebook開源,最初用於解決海量結構化的日誌數據統計問題;
◆構建在Hadoop之上的數據倉庫;
◆Hive定義了一種類SQL查詢語言:HQL(類似SQL但不完全相同);
◆通常用於進行離線數據處理(採用MapReduce);
◆底層支持多種不同的執行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark);
◆支持多種不同的壓縮格式、存儲格式以及自定義函數(壓縮:GZIP、LZO、Snappy、BZIP2.. ;
◆存儲:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定義函數)。
3.2、為什麼要使用Hive
◆簡單、容易上手(提供了類似SQL查詢語言HQL);
◆為超大數據集設計的計算/存儲擴展能力(MR計算,HDFS存儲);
◆統一的元數據管理(可與Presto/Impala/SparkSQL等共用數據)。
3.3 Hive架構

上圖中,可以通過CLI(命令行介面),JDBC/ODBC,Web GUI 訪問hive。於此同時hive的元數據(hive中表結構的定義如表有多少個欄位,每個欄位的類型是什麼)都存儲在關係型資料庫中。三種鏈接hive的方式最後統一通多一個Diveer 的程式將sql 轉化成mapreduce的job任務去執行。
更多Hive信息閱讀:《Hive是什麼?Hive特點、工作原理,Hive架構,Hive與HBase聯繫和區別》、《Hive常用字元串函數彙總》、《Hive數據倉庫之快速入門》
四、Mapreduce
4.1、MapReduce是什麼?
MapReduce 是一個分散式運算程式的編程框架,是用戶開發“基於 hadoop 的數據分析 應用”的核心框架。MapReduce採用"分而治之"的思想,把對大規模數據集的操作,分發給一個主節點管理下的各個分節點共同完成,然後通過整合各個節點的中間結果,得到最終結果。簡單地說,MapReduce就是"任務的分解與結果的彙總"。
在分散式計算中,MapReduce框架負責處理了並行編程中分散式存儲、工作調度、負載均衡、容錯均衡、容錯處理以及網路通信等複雜問題,把處理過程高度抽象為兩個函數:map和reduce,map負責把任務分解成多個任務,reduce負責把分解後多任務處理的結果彙總起來。
4.2、為什麼需要 MapReduce?
◆ 海量數據在單機上處理因為硬體資源限制,無法勝任。
◆ 而一旦將單機版程式擴展到集群來分散式運行,將極大增加程式的複雜度和開發難度。
◆引入 MapReduce 框架後,開發人員可以將絕大部分工作集中在業務邏輯的開發上,而將 分散式計算中的複雜性交由框架來處理。
4.3、MapReduce核心機制
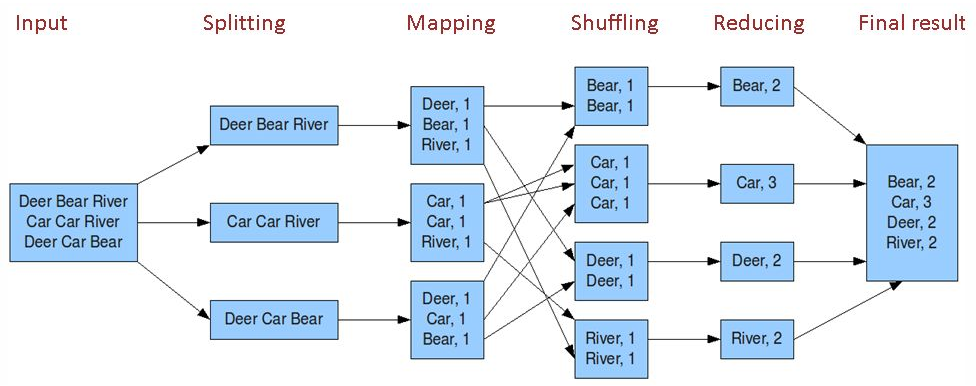
MapReduce核心就是map+shuffle+reducer,首先通過讀取文件,進行分片,通過map獲取文件的key-value映射關係,用作reducer的輸入,在作為reducer輸入之前,要先對map的key進行一個shuffle,也就是排個序,然後將排完序的key-value作為reducer的輸入進行reduce操作,當然一個MapReduce任務可以不要有reduce,只用一個map。
更多MapReduce的文章閱讀:《MapReduce設計及工作原理分析》
以上就是總結的Hbase、Spark、Hive、MapReduce的概念理解和特點,以及一些應用場景和核心機制。歡迎大家評論留言,需要相關學習資料也可以留言聯繫。


