
一致性Hash演算法。 Hash演算法是為了保證數據均勻的分佈,例如有3個桶,分別是0號桶,1號桶和2號桶;現在有12個球,怎麼樣才能讓12個球平均分佈到3個桶中呢?使用Hash演算法的做法是,將12個球從0開始編號,得到這樣的一個序列:0,1,2,3,4,5,6,7,8,9,10,11。將這個序列中的每 ...
一致性Hash演算法。
Hash演算法是為了保證數據均勻的分佈,例如有3個桶,分別是0號桶,1號桶和2號桶;現在有12個球,怎麼樣才能讓12個球平均分佈到3個桶中呢?使用Hash演算法的做法是,將12個球從0開始編號,得到這樣的一個序列:0,1,2,3,4,5,6,7,8,9,10,11。將這個序列中的每個值模3,不管數字是什麼,得到的結果都是0,1,2,不會超過3,將結果為0的數字放入0號桶,結果為1的數子放入1號桶,結果為2的數字放入2號桶,12個球就均勻的分佈到3個桶中,0,3,6,9,12號球放入0號桶,1,4,7,10號球放入1號桶,2,5,8,11號球放入2號桶。
一致性Hash演算法是在Hash演算法的基礎上實現的,用於解決互聯網中熱點Hotspot問題,將來自網路上的流量動態的劃分到不同的伺服器處理。使用一致性Hash演算法將流量均勻分發到不同伺服器的做法是:
1、求出不同伺服器的哈希值,然後映射到一個範圍為0—2^32-1的數值空間的圓環中,即將首(0)和尾(2^32-1)相接的圓環,如圖1。
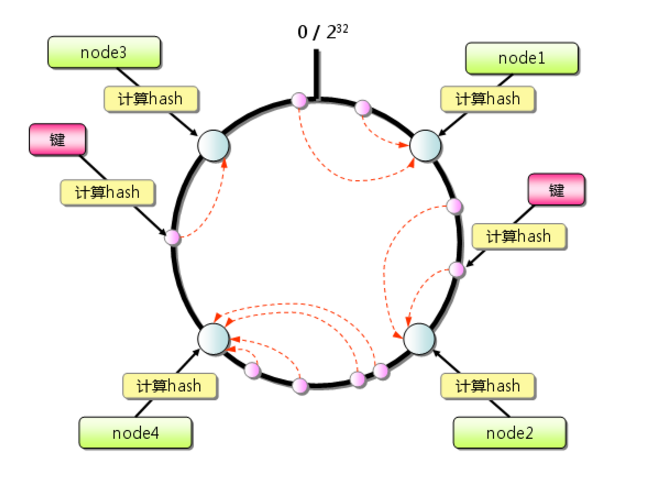
圖1
2、當有一個李四的用戶訪問時,就會給該用戶分配一個隨機數,該隨機數映射到圓環中的任意一個地方,按照圓環順時針的方向查找距離最近的伺服器,然後處理李四用戶的請求。如果找不到伺服器,則有第一臺伺服器來處理。
以上就是兩種Hash演算法的簡單介紹,Hadoop也藉助於這兩種思想來處理大數據計算和海量數據存儲。面對海量的問題時候,一般把這個問題會分成三類:一個是大數據量,一個是大流量,一個是大計算,大流量不屬於本文討論的範圍,大數據量是屬於HDFS的範疇,之後會寫一篇文章講解HDFS的原理。本文重點講述大計算。MapReduce就會Hadoop中採用"分而治之"的思想解決大計算的問題。“分而治之”思想是理解MapReduce的核心,下麵我們採用數錢的場景解釋下“分而治之”的思想。
有一張桌子,上面灑滿了面值100、50、20的鈔票,我們如何能快速的知道這個桌子一共有多少錢呢?通常的做法是請103個人,其中100個人把自己面前的鈔票按照100、50、20的面值整理好併排好序,100的一堆,50的一堆,20的一堆,並且按照100面值的在左邊,50面值的在中間,20面值的在右邊,這100人只負責按照錢的面值分好類別並整理整齊。整理好之後,這100個人執行下一個任務,分別把自己整理好的100元面值這一堆錢發給3個人中的=的A,把50元面值的錢發給3個人中的B,把20元面值的錢發給3個人中的C,這是這100個人的工作就結束。A,B,C這三個人就各自有了不同面值的錢,這三個人不需要去做加法就比如(100+100),只需要去數這個錢的張數,最後就出三個數字,然後把這三個數字加起來就是這一整個桌子的全額度總數。在這個例子中前後經歷了兩個過程,第一個過程是100個人,第二個過程是3個人,100人相當於就是做分解,把一整張桌子的錢去分解成100份,剩下這三個人就是做合併的作用。這就是“分而治之”的思想。
下麵使用Hadoop給出的MapReduce運行圖來解釋上面數錢的流程:
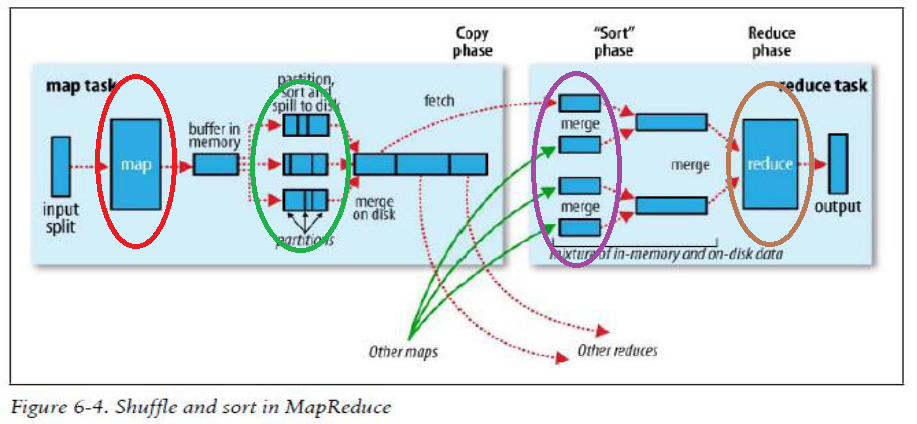
圖2
上圖中紅色的橢圓框的map進程就是對應100個規整錢人中的其中一個,他將桌子上的錢攏到自己面前。綠色橢圓框就是開始規整錢的過程,按照100、50、20面值的錢分成3份,並且按照左邊100,中間50,右邊20的順序排好序。紫色橢圓框是將就是將規整好的錢分發的過程,他將自己和其他99個人都將規整好的100元分發給A,把50元分發給B,把20元分發給C。褐色框就是彙總的過程,對應著上一過程中的A,計算出100面值的有多少張,B計算出50面值的有多少張,C計算20面值的有多少張。然後將A,B,C的的結果相加,就是桌子上鈔票的總數。
其實一個MapReduce真正的運行過程比上述數錢的過程複雜得多,MapReduce的原理必須弄清楚,很多公司面試時都喜歡問MapReduce的運行原理,只有瞭解運行原理,才能在工作中對MapReduce進行調優,因此下圖是每個學習Hadoop的人必須掌握的,下圖的紅色橢圓框是重點,也是優化大有可為之處。
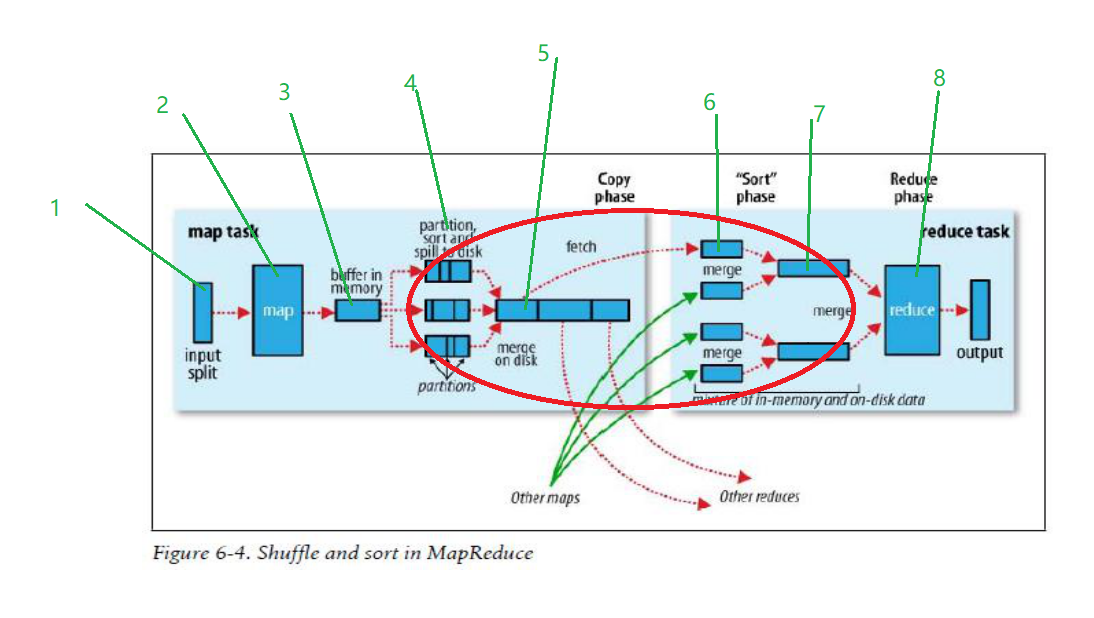
圖3
數據按照箭頭方向從左往右流動,
1、input split過程,通過InputFormat介面從HDFS中讀取數據,然後輸入到map中。預設情況下分片的大小和HDFS中block的大小一致,Hadoop1.x是64M,Hadoop2.x是128M。
2、map函數,一行一行的處理輸入的數據,將每一行數據封裝成<key,value>鍵值對形式。
3、Map進程中有一個記憶體緩衝區用於處理數據,預設是100M,當記憶體中的數據達到80M時,後臺就開啟一個進程,鎖住80M的空間,將數據寫入剩餘的20M空間,同時將80M的數據溢出(spill)到磁碟。
4、在這個階段涉及到數據的分區partition、排序和combiner,這也是mapreduce優化的重點。有幾個partition就有幾個reduce。當數據從記憶體緩存區往磁碟中寫時,會生成很多小的spill文件,每個文件會分為好幾個區,在數錢的例子中,一個spill文件會分為三個分區partition,每個分區中的文件使用快速排序演算法按照key值進行排序。這裡也可以執行combiner操作,但是一定要小心,如果是你求最大最小值,用combiner操作沒問題,如果是求平均值,combiner操作會影響最終的結果。
5、map端歸併文件,spill的小文件過多,達到閾值時,就使用歸併排序演算法將小的spill文件歸併成大的spill文件,大的spill也是分好區,每個分區中的數據也是按照key值排好序。
6、當最後一個map任務執行完畢,生成最後一spill文件之後,就將spill文件中的分區往相應的reduce任務發送,例如partition0發送往reduce0,partition1發送往reduce1,partition2發送往reduce2,以此類推。
7、reduce端歸併文件,將來自不同map端的同一個分區文件使用歸併成一個大的文件。
8、reduce任務開始處理數據,將會後的結果寫入到HDFS中。
圖4是將不同map端同一個分區partition數據發送到reudce端的流程圖。
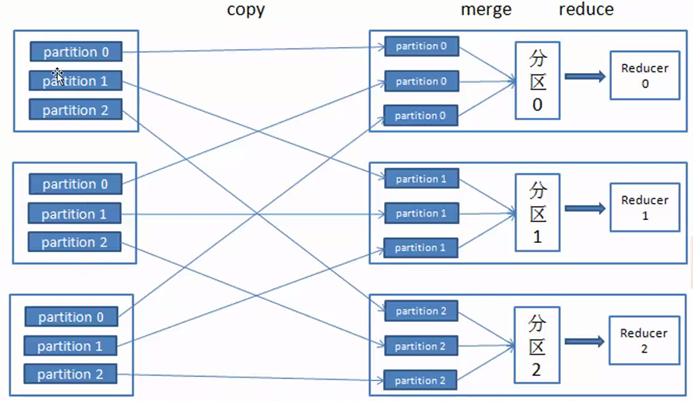
圖4
現在重點介紹partition,sort and spill to disk過程,即分區,排序和溢寫到磁碟過程。請看圖5
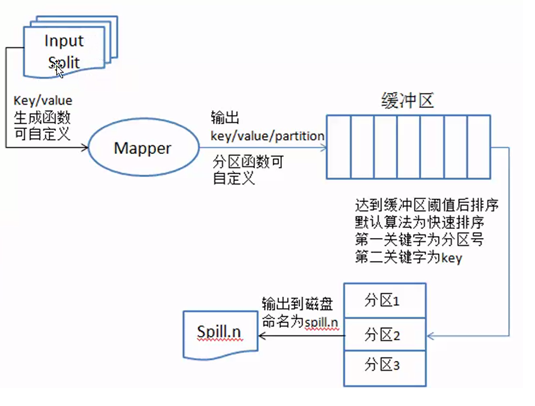
圖5
數據從InputSplit進去到map進程,將數據處理成<key,value>鍵值對的形式,然後發送到記憶體緩存區,根據上面數錢的例子,會有很多如下形式的鍵值對,當有不同分區時,鍵值對為:<0,<100,1>>,<1,<50,1>>,<2,<20,1>>,當只有一個預設分區時,鍵值對為:<100,1>,<50,1>,<20,1>。從記憶體區往磁碟中寫入數據時,先對鍵值對使用快速排序演算法進行排序,第一關鍵字是分區號,第二關鍵字是key,排序的目的是為了將相同的key排到一塊,為了後面的歸併文件做好準備。把記憶體中排好序的數據輸出到磁碟上,每次輸出都會產生很多小的文件數據(spill.n),n表示數字,如圖6所示。
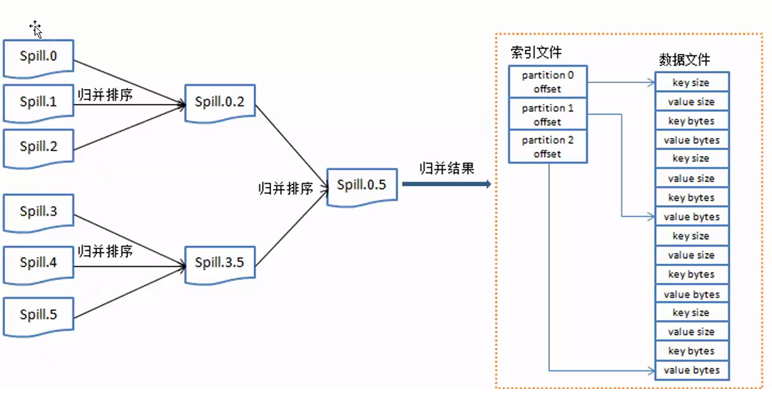
圖6
當spill小文件過多時就執行歸併排序,變成一個大的數據文件,歸併完成後生成大的spill文件中的數據是按照key來做一個整體的排序。

