
開始了,繼續說!字元串替換,就是預留著空間,後邊再定義要填上什麼,這種叫字元串格式化,其有兩種方法: % 和 format %s 就是一個占位符,這個占位符可以被其它的字元串代替 >>> "I like %s" % "python" 'I like python' string.format()的格 ...
開始了,繼續說!字元串替換,就是預留著空間,後邊再定義要填上什麼,這種叫字元串格式化,其有兩種方法: % 和 format
%s 就是一個占位符,這個占位符可以被其它的字元串代替
>>> "I like %s" % "python"
'I like python'
| 占位符 | 說明 |
|---|---|
| %s | 字元串(採用str()的顯示) |
| %r | 字元串(採用repr()的顯示) |
| %c | 單個字元 |
| %b | 二進位整數 |
| %d | 十進位整數 |
| %i | 十進位整數 |
| %o | 八進位整數 |
| %x | 十六進位整數 |
| %e | 指數 (基底寫為e) |
| %E | 指數 (基底寫為E) |
| %f | 浮點數 |
| %F | 浮點數,與上相同 |
| %g | 指數(e)或浮點數 (根據顯示長度) |
| %G | 指數(E)或浮點數 (根據顯示長度) |
string.format()的格式化方法,其中{索引值}作為占位符,這個好變著花樣的玩哦,這個不錯,嘻嘻
>>> s1 = "I like {0}".format("python")
>>> s1
'I like python'
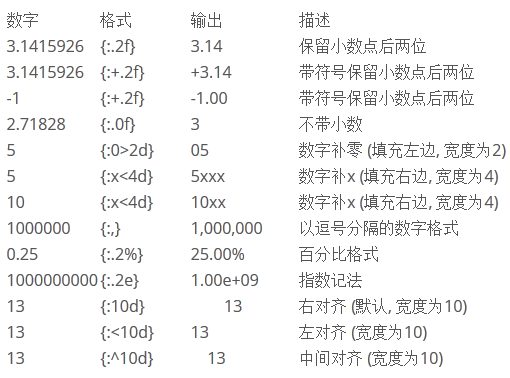
關於類似的操作,還有很多變化,比如輸出格式要寬度是多少等等,找了一個參考圖,你看看開心就好
split 這個函數的作用是將字元串根據某個分割符進行分割
>>> a = "I LOVE PYTHON"
>>> a.split(" ")
['I', 'LOVE', 'PYTHON'] (這是用空格作為分割,得到了一個名字叫做列表(list)的返回值)
>>> b = "www.itdiffer.com"
>>> b.split(".")
['www', 'itdiffer', 'com'] (這是用"."作為分割,得到了一個名字叫做列表(list)的返回值)
String.strip() 去掉字元串的左右空格
String.lstrip() 去掉字元串的左邊空格
String.rstrip() 去掉字元串的右邊空格
String.upper() #String中的字母大寫
String.lower() #String中的字母小寫
String.capitalize() #首字母大寫
String.isupper() #String中的字母是否全是大寫
String.islower() #String中的字母是否全是小寫
String.istitle() #String中字元串中所有的單詞拼寫首字母是否為大寫,且其他字母為小寫
join拼接字元串
>>> b='www.itdiffer.com'
>>> c = b.split(".")
>>> c
['www', 'itdiffer', 'com']
>>> ".".join(c)
'www.itdiffer.com'
>>> "*".join(c)
'www*itdiffer*com'
列表
一些用逗號分隔而有序的數據,用方括弧表示一個list,[ ] 在方括弧裡面,可以是int,也可以是str類型的數據,甚至也能夠是True/False這種布爾值 ['2',3,'北京圖靈','outman']
bool()是一個布爾函數,這個東西後面會詳述。它的作用就是來判斷一個對象是“真”還是“空”(假)
列表可以索引和切片,前面字元串我好像啰嗦過了,都是一樣的
這裡拓展下 雙冒號使用,其實Python序列切片地址可以寫為[開始:結束:步長],那麼其中的開始和結束省略,就出現雙冒號了
開始start省略時,預設從第0項開始。結尾省略的時候,預設到數組最後。步長step省略預設為1。當step等於負數的時候,從右向左取數
>>> alst = [1,2,3,4,5,6]
>>> alst[::-1] #從右向左取數(反轉過來了)
[6,5,4,3,2,1]
上面反轉我們可以用reversed函數
>>> list(reversed(alst))
[6,5,4,3,2,1]
好了下麵我轉用anaconda 裡面的 jupyter打命令演示了(之前是在官方python3.7)沒有 >>>
append()方法在列表的末尾添加一個元素
s = [1,'a','3']
s.append('t')
print(s)
[1, 'a', '3', 't']
insert()任意位插入一個元素 (說到位置,你想到什麼?沒錯,就是索引)
s = [1,'a','3']
s.insert(3,'t') #在索引為3的位置加字元t,也就是字元串3後邊
print(s)
[1, 'a', '3', 't']
使用del語句刪除元素
motorcycles = ['honda', 'yamaha', 'suzuki']
del motorcycles[0]
print(motorcycles)
['yamaha', 'suzuki']
pop()彈出任意位置一個元素 (同樣說位置,還是用索引,彈出?就是拿出來)
motorcycles = ['honda', 'yamaha', 'suzuki']
motorcycles.pop(1) #括弧內不填寫預設為0,經常彈出的這個值我們會用到,這就是特殊的地方
print(motorcycles)
['honda', 'suzuki']
remove()不知道要從列表中刪除的值所處的位置,只知道要刪除的元素的值。(知道你要刪除啊啥,這就夠了)
motorcycles = ['honda', 'yamaha', 'suzuki', 'ducati']
motorcycles.remove('ducati')
print(motorcycles)
['honda', 'yamaha', 'suzuki']
好了,再說幾個,不做命令演示了
list.clear() 從列表中刪除所有元素。相當於 del a[:]
list.index(x) 返回列表中第一個值為 x 的元素的索引。如果沒有匹配的元素就會返回一個錯誤
list.count(x) 返回 x 在列表中出現的次數
list.sort() 對列表中的元素就地進行排序
list.reverse() 就地倒排列表中的元素
list.copy() 返回列表的一個淺拷貝。等同於 a[:] 說說這個吧,你可能會問啥是淺拷貝?演示代碼給你看下,你會發現確實新拷貝的列表ID不一樣,但裡面元素ID一樣
b = ['honda', 'yamaha', 'suzuki']
a = b.copy()
print(id(b)) #查看列表b的ID
print(id(b[1])) #查看列表b中索引值為1的元素ID
print(a)
print(id(a)) #查看列表a的ID
print(id(a[1])) #查看列表a中索引值為1的元素ID
99833224
99844368
['honda', 'yamaha', 'suzuki']
105157704
99844368
list.extend(b) 將一個給定列表中的所有元素都添加到另一個列表中,相當於 a[len(a):] = b 這個理解麽?就是說列表a其切片從索引值"len(a)"到結束的部分就是列表b
a = [1, 2, 3]
b = ['qiwsir', 'python']
a.extend(b)
print(a)
[1, 2, 3, 'qiwsir', 'python'] 這裡你想下和append()的區別
說到這,就不得不深入下,extend函數也是將另外的元素增加到一個已知列表中,其元素必須是iterable,什麼是iterable?也就是可迭代
迭代是重覆反饋過程的活動,其目的通常是為了接近併到達所需的目標或結果
hasattr()的判斷本質就是看那個類型中是否有__iter__函數。可以用dir()找一找,在數字、字元串、列表、元組、集合、字典,誰有__iter__(截圖了,打命令好累)
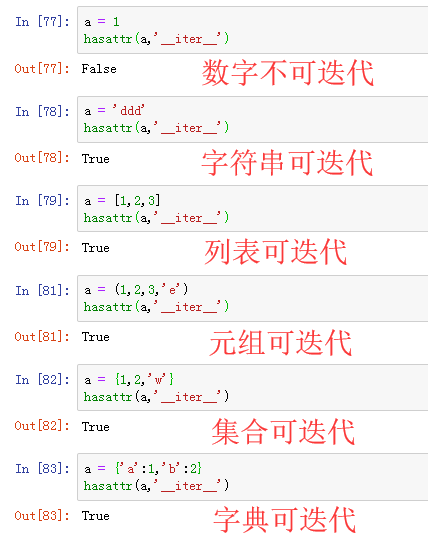 為什麼?數字你搞什麼!
為什麼?數字你搞什麼!
那我們想下,列表都幹啥用呢?
1. 把列表當作堆棧使用
列表方法使得列表可以很方便的做為一個堆棧來使用,堆棧作為特定的數據結構,最先進入的元素最後一個被釋放(後進先出)。用 append() 方法可以把一個元素添加到堆棧頂。用不指定索引的 pop() 方法可以把一個元素從堆棧頂釋放出來
2. 把列表當作隊列使用
可以把列表當做隊列使用,隊列作為特定的數據結構,最先進入的元素最先釋放(先進先出)。不過,列表這樣用效率不高。相對來說從列表末尾添加和彈出很快;在頭部插入和彈出很慢(因為,為了一個元素,要移動整個列表中的所有元素)
3. 列表推導式(可嵌套)
列表推導式為從序列中創建列表提供了一個簡單的方法。普通的應用程式通過將一些操作應用於序列的每個成員並通過返回的元素創建列表,或通過滿足特定條件的元素創建子序列


