
有時候,可能會有一些類似這樣的需求,具體如圖所見,取首字母。 ...
有時候,可能會有一些類似這樣的需求:
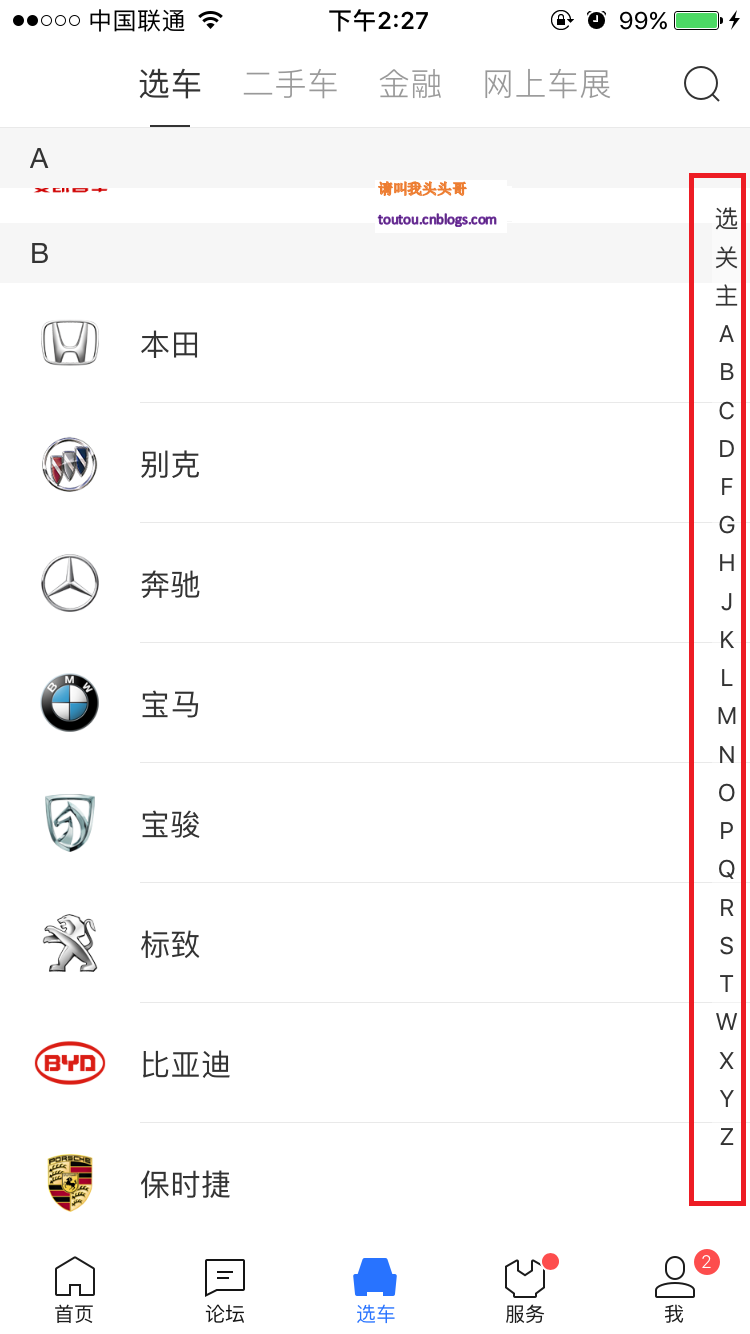
對於這樣的效果,我們可以有類似這樣的解決方案:
package bys.utils; import java.io.UnsupportedEncodingException; /** * Created by toutou on 2014/2/21 */ public class ChineseCharacterHelper { static final int GB_SP_DIFF = 160; // 存放國標一級漢字不同讀音的起始區位碼 static final int[] secPosValueList = { 1601, 1637, 1833, 2078, 2274, 2302, 2433, 2594, 2787, 3106, 3212, 3472, 3635, 3722, 3730, 3858, 4027, 4086, 4390, 4558, 4684, 4925, 5249, 5600 }; // 存放國標一級漢字不同讀音的起始區位碼對應讀音 static final char[] firstLetter = { 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'w', 'x', 'y', 'z' }; /** * 提取漢字字元串的首字母 * @param characters 漢字字元串 * @return */ public static String getSpells(String characters) { StringBuffer buffer = new StringBuffer(); for (int i = 0; i < characters.length(); i++) { char ch = characters.charAt(i); if ((ch >> 7) == 0) { // 判斷是否為漢字,如果左移7為為0就不是漢字,否則是漢字 buffer.append(ch); } else { char spell = getFirstLetter(ch); buffer.append(String.valueOf(spell)); } } return buffer.toString(); } /** * 獲取一個漢字的首字母 * @param ch 漢字 * @return */ public static Character getFirstLetter(char ch) { byte[] uniCode = null; try { uniCode = String.valueOf(ch).getBytes("GBK"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); return null; } if (uniCode[0] < 128 && uniCode[0] > 0) { // 非漢字 return null; } else { return convert(uniCode); } } /** * 獲取一個漢字的拼音首字母。 GB碼兩個位元組分別減去160,轉換成10進位碼組合就可以得到區位碼 * 例如漢字“你”的GB碼是0xC4/0xE3,分別減去0xA0(160)就是0x24/0x43 * 0x24轉成10進位就是36,0x43是67,那麼它的區位碼就是3667,在對照表中讀音為‘n’ */ private static char convert(byte[] bytes) { char result = '#'; int secPosValue = 0; int i; for (i = 0; i < bytes.length; i++) { bytes[i] -= GB_SP_DIFF; } secPosValue = bytes[0] * 100 + bytes[1]; for (i = 0; i < 23; i++) { if (secPosValue >= secPosValueList[i] && secPosValue < secPosValueList[i + 1]) { result = firstLetter[i]; break; } } return result; } }
調用示例 String carName = ChineseCharacterHelper.getSpells(String.valueOf(user.getName().charAt(0))).toUpperCase();


