
緩存這個東西相信大家工作中都接觸得比較多,相應的在不同場景下也會遇到各種各樣的問題。下麵我列舉幾種可能會遇到的問題並提供一些解決建議。 1、如何把海量數據存放在緩存中並提供快速查詢 現實中我們的緩存通常都是以string,map,array,list,set,tree等具體的類型或者集合存放記憶體中, ...
緩存這個東西相信大家工作中都接觸得比較多,相應的在不同場景下也會遇到各種各樣的問題。下麵我列舉幾種可能會遇到的問題並提供一些解決建議。
1、如何把海量數據存放在緩存中並提供快速查詢
現實中我們的緩存通常都是以string,map,array,list,set,tree等具體的類型或者集合存放記憶體中,它們的共同點都在於把元素具體內容放到記憶體裡面。這種在元素數量小的時候是沒問題。但一旦數據量過大,消耗的記憶體也會呈現線性增長,最終達到瓶頸,並且查詢效率也可能隨著元素數量增長而下降。比如list與array,沒有數字下標的情況下只能是0(n)遍歷,有人也許會說到map的效率不是很高嗎,查詢效率可以達到O(1)。但這隻是理想情況而已,hash衝突大的情況下map的查詢也會退化,並且map也並沒有解決記憶體消耗的問題。難道就沒有辦法解決這個問題嗎?當然有!答案就是Bit-map和布隆過濾器!
什麼是Bit-map?
所謂的Bit-map就是用一個bit位來標記某個元素對應的Value, 而Key即是該元素或者元素經過轉換(比如hash)得到的值。由於採用了Bit為單位來存儲數據,因此在存儲空間方面,可以大大節省。原理如下圖:
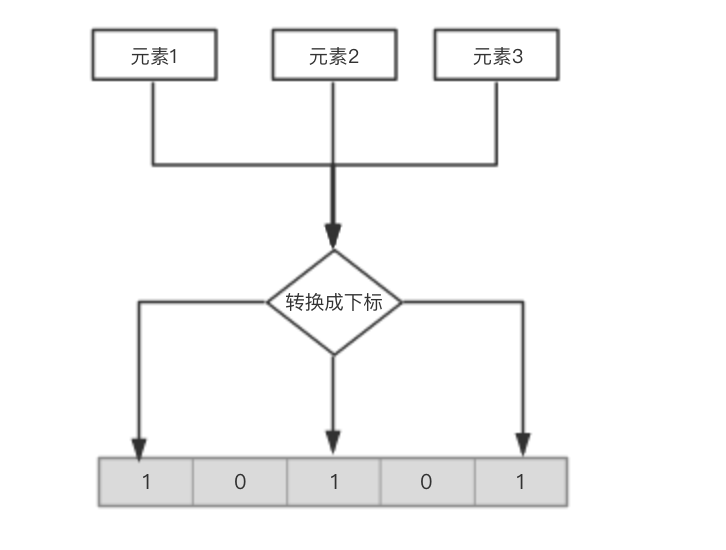
那1M的Bit-map可以表示多少數據呢,1兆位元組(mb)=8388608比特(bit),也就是指我們可以用1M的記憶體表示800W+的數據。。。。
舉個情景比如運營方給了一批100W用戶ID,如果這批用戶在指定時間內購買了某個商品就給用戶派一張優惠劵,假設這100W的用戶的userId都是64位的長整型數。那如何把這100W的用戶存起來節省空間然後訪問的性能也不差?我的建議是放到redis緩存裡面利用redis的setbit,getbit的命令存儲起來和訪問,這樣要比你存db要節省更多的空間並且查詢速度也快~。如果這100W的用戶ID分佈範圍比較隨機,我建議是本地排好序,然後分成幾段用不同Bit-map表示~,這樣就不會造成過多不必要的空間浪費。別外本地排序也要以用Bit-map實現哦。
什麼又是布隆過濾器?
布隆過濾器(英語:Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位向量和一系列隨機映射函數。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和刪除困難。
基本概念和原理:
如果想判斷一個元素是不是在一個集合里,一般想到的是將集合中所有元素保存起來,然後通過比較確定。鏈表、樹、散列表(又叫哈希表,Hash table)等等數據結構都是這種思路。但是隨著集合中元素的增加,我們需要的存儲空間越來越大。同時檢索速度也越來越慢,上述三種結構的檢索時間複雜度分別為O(n),O(logn),O(n/k)
布隆過濾器的原理是,當一個元素被加入集合時,通過K個散列函數將這個元素映射成一個位數組中的K個點,把它們置為1。檢索時,我們只要看看這些點是不是都是1就(大約)知道集合中有沒有它了:如果這些點有任何一個0,則被檢元素一定不在;如果都是1,則被檢元素很可能在。這就是布隆過濾器的基本思想。
所以說布隆過濾器底層還是依賴Bit-map的存儲原理,因為是通過散列函數來進行映射就會有衝突的可能性,當元素a,b的hash出來index是一樣的時候就無法判斷到底Bit-map裡面存的是a還是b。所以一般布隆過濾器是不允許刪除元素的,因為真不知道刪除的是哪個元素。。。。
布隆過濾器hash衝突性與散列函數的設計和Bit-map的大小有關,如果Bit-map太小那必然很多元素都會落到同一個下標,並且後面數量越大衝突也就越大。不過不用太擔心畢竟1M的Bit-map就可以保存800W+數據~。
當你存儲元素量不是很大的話,可以優先考慮散列表(map),數量大時布隆過濾器會不錯的選擇~。
2、高併發時緩存如何更新
在更新緩存時我們通常會加鎖更新,為了減少鎖住的資源,通常用分段鎖的設計,只鎖需要更新的資源。但在高併發的情景下大多數發請求都集中在一個key的時候也就是hot-key的情形下,對緩存進行更新。如果採用加鎖的形式,就只能有一個線程去更新,其它的線程就只能同步阻塞,瞬間就有會大量線程hold住,甚至有可能把線程打滿,這個時候系統的性能就會大打折扣。所以在高併發hot-key的情景下,加鎖更新很影響性能。如果把讀取和更新的操作隔離開來會怎樣,如下圖
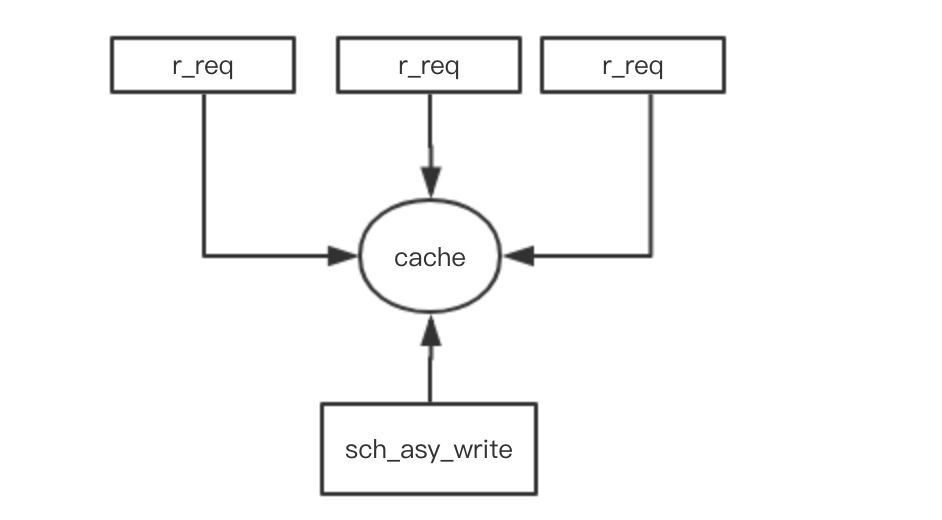
這種方案就是起額外的線程定時去定時去更新cache,這樣讀取線程就不會存在鎖爭的問題。這種通常cache不會設置超時時間,比如guava cache的refreshAfterWrite策略的cache就是永遠不會超時的,只是每次讀取的時候判斷是否到了刷新周期,如果到了選取其中一個線程去更新,其它線程仍然返回舊值。所以這非同步更新cache也不失為一個方法。只是要註意的控制好非同步更新頻率,頻率太小那cache的實時性就會受影響。
3、Redis OR Memcache?
每當有人問我這個東西是用redis還是memcache存起來時,我會建議他從下麵幾個方面去考慮:
1、緩存的更新設置是怎樣的?每次都get,set全部數據嗎還是部分。
2、除了get,set還有其它操作嗎?比如排序,獲取前面5個元素?
3、預計緩存的qps有多少?
4、緩存需要持久化嗎
5、單個緩存有多大
對於redis、memcache來說,我覺得如果是一般業務首先考慮的不應該是兩者的性能問題,而是這兩者提供的數據結構哪個更適切合你當前的業務需求還有將來業務的發展。在這一點方面redis無疑是占據了絕大優勢,因為redis提供了String、Hash、List、Set和Sorted Set五種數據結構,而memcache只有key-value。所以一般我是優先考慮redis的。另外在單個緩存大小方面memcache的value存儲,最大為1M,如果存儲的value很大,只能使用redis。剛提到為什麼不優先考慮性能問題呢?因為這兩者的性能都不算差,並且後面都是可以橫向擴展的,甚至還可以通過其它方式比如增加多層cache如local cache去提升。其實更多還是考慮業務的維護與迭代。如果你是純k-v操作,並且數據量非常大,併發量非常大的業務,這個時候我建議你memcache會更適合你~,如果是其它redis可能會更適合你~。

