
最近因為公司業務需要,又有機會擼winform了,這次的需求是因為公司有項目申報的這塊業務,項目申報前期需要關註政府發佈的相關動態信息,政府部門網站過多,人工需要一個一個網站去瀏覽和查閱,有時候還會遺漏掉,因此呢,我們打算用爬蟲+移動端web來做,我呢主要負責爬蟲和web Api。 爬蟲篇 爬蟲主要 ...
最近因為公司業務需要,又有機會擼winform了,這次的需求是因為公司有項目申報的這塊業務,項目申報前期需要關註政府發佈的相關動態信息,政府部門網站過多,人工需要一個一個網站去瀏覽和查閱,有時候還會遺漏掉,因此呢,我們打算用爬蟲+移動端web來做,我呢主要負責爬蟲和web Api。
爬蟲篇
爬蟲主要採用.Net強大的開源解析HTML元素的類庫HtmlAgilityPack,操作過XML的童鞋應該很快就可以上手,通過分析XPath來解析HTML,非常的方便的,不過還有一款不錯的叫Jumony,沒用過,對HtmlAgilityPack比較熟悉,所以首選了HtmlAgilityPack來作為主力軍。
HtmlAgilityPack的基本使用可以參考這篇 https://www.cnblogs.com/GmrBrian/p/6201237.html,
效果圖,多圖慎入



採集廣西財政廳例子
因為是政府發佈的出來的信息,所以信息的對外開放的,只是機器代替人工來瀏覽,不會被和諧的,主要採集文章列表和文章內容,以廣西財政廳網站為例子。
First
載入網站這個就不用說了,先查看網站的字元編碼,如圖<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> ,然後設置HtmlAgilityPack中的OverrideEncoding屬性,

htmlAgilityPack.OverrideEncoding = Encoding.UTF8;
Second
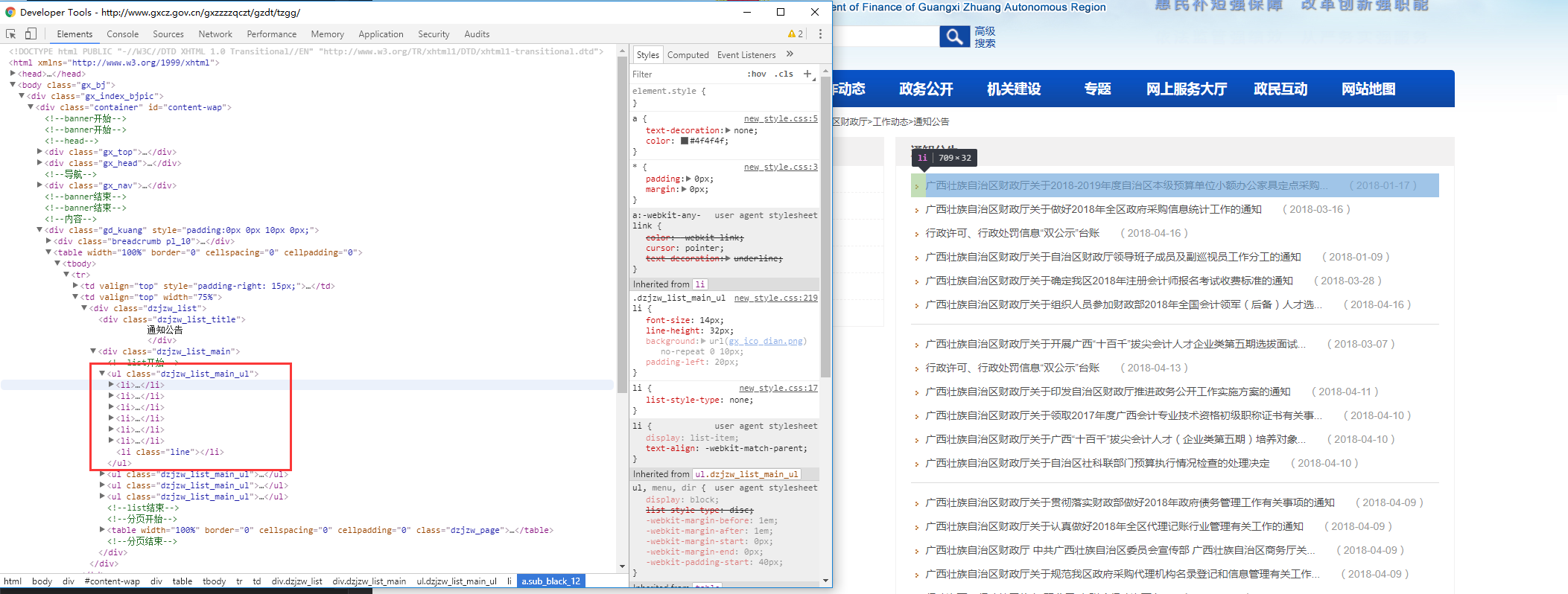
分析文章列表,瀏覽器F12查看HTML標簽情況,可以分析出XPath為
//ul[@class='dzjzw_list_main_ul']//li
流程代碼:
//獲取第一頁的內容 HtmlNode row = GetHtmlDoc(htmlWeb, url); //根據xpath獲取列表 var list = row.SelectNodes("//ul[@class='dzjzw_list_main_ul']//li"); foreach (var data in list) { .... } /// <summary> /// 這裡偶爾會瀏覽網頁失敗的,所以失敗了多瀏覽幾次 /// </summary public static HtmlNode GetHtmlDoc(HtmlWeb htmlWeb, string url) { try { var doc = GetDoc(htmlWeb, url); if (doc == null) { int againIdx = 0; while (againIdx++ < 5) { System.Threading.Thread.Sleep(1000); doc = GetDoc(htmlWeb, url); if (doc != null) break; } if (doc == null) { var htmlData = HttpHelper.Get<string>(url).Result;//.GetStringAsync(url).Result; return HtmlNode.CreateNode(htmlData); } else { return doc.DocumentNode; } } return doc.DocumentNode; } catch { Log.Error("未能正確訪問地址:" + url); return null; } }
文章內容的鏈接的XPath標簽
//a
文章發佈的時間XPath標簽
//span[@class='date']
都可以使用 HtmlNode.InnerText 來獲取到相關值,非常的方便。
Third
文章詳細內容也如此,通過分析XPath來分析即可,最頭疼的是翻頁的問題,因為政府網站使用的技術一般都是比較那個的,你懂的,在這裡的翻頁也比較簡單,通過拼接URL來進行翻頁即可,有些使用到oncilck來觸發的,有些表單提交,要具體問題具體分析了,用Fiddler和瀏覽器的F12大法來分析翻頁數據來源,所以這裡的例子比較簡單

Fourth
爬取到的之後,再來一個釘釘通知,在群裡拉入一個機器人,可以參考釘釘的開發文檔(https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.ece6g3&treeId=257&articleId=105735&docType=1#)



這樣我們爬取的消息就第一時間通知到群里的小伙伴啦,是不是很炫酷,哈哈哈。
後面做完了再上傳到GitHub吧,下班下班。


