
背景 目前對於時序大數據的存儲和處理往往採用關係型資料庫的方式進行處理,但由於關係型資料庫天生的劣勢導致其無法進行高效的存儲和數據的查詢。時序大數據解決方案通過使用特殊的存儲方式,使得時序大數據可以高效存儲和快速處理海量時序大數據,是解決海量數據處理的一項重要技術。該技術採用特殊數據存儲方式,極大提 ...
背景
目前對於時序大數據的存儲和處理往往採用關係型資料庫的方式進行處理,但由於關係型資料庫天生的劣勢導致其無法進行高效的存儲和數據的查詢。時序大數據解決方案通過使用特殊的存儲方式,使得時序大數據可以高效存儲和快速處理海量時序大數據,是解決海量數據處理的一項重要技術。該技術採用特殊數據存儲方式,極大提高了時間相關數據的處理能力,相對於關係型資料庫它的存儲空間減半,查詢速度極大的提高。時間序列函數優越的查詢性能遠超過關係型資料庫,Informix TimeSeries非常適合在物聯網分析應用。定義
時間序列資料庫主要用於指處理帶時間標簽(按照時間的順序變化,即時間序列化)的數據,帶時間標簽的數據也稱為時間序列數據。
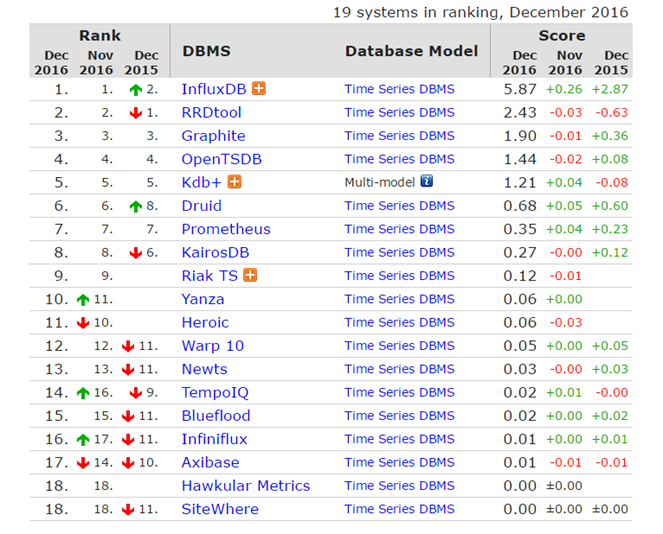
最新時序資料庫排名:
特點& 分類:
- 專門優化用於處理時間序列數據
- 該類數據以時間排序
- 由於該類數據通常量級大(因此Sharding和Scale非常重要)或邏輯複雜(大量聚合,上取,下鑽),關係資料庫通常難以處理
- 時間序列數據按特性分為兩類
- 高頻率低保留期(數據採集,實時展示)
- 低頻率高保留期(數據展現、分析)
- 按頻度
- 規則間隔(數據採集)
- 不規則間隔(事件驅動)
- 時間序列數據的幾個前提
- 單條數據並不重要
- 數據幾乎不被更新,或者刪除(只有刪除過期數據時),新增數據是按時間來說最近的數據
- 同樣的數據出現多次,則認為是同一條數據
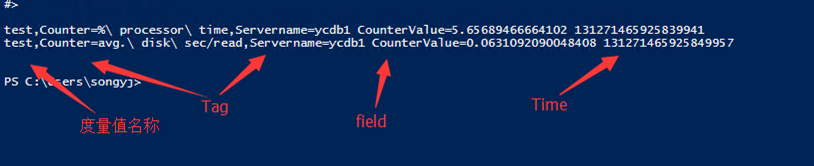
如圖:
時間序列資料庫關鍵比對
|
InfluxDB |
ElasticSearch |
|
流行(TSDB排行第一) |
流行(搜索引擎排行第一) |
|
高可用需要收費 |
集群高可用容易實現,免費 |
|
單點寫入性能高 |
單點寫入性能低 |
|
查詢語法簡單,功能強 |
查詢語法簡單,功能強(弱於Influxdb) |
|
後端時序資料庫設計,寫入快 |
設計並不是時序資料庫,後端存儲採用文檔結構,寫入慢 |
由此可見:高頻度低保留期用Influxdb,低頻度高保留期用ES。
其他時序資料庫介紹:

如何使用
數據的查詢與寫入:
- Influxdb與ES都是REST API風格介面
- 通過HTTP Post寫入數據,通過HTTP Get獲取數據,ES還有HTTP Put和Delete等
- 寫入數據可以是JSON格式,Influxdb支持Line Protocol
- JSON格式徒增解析成本,錄入數據格式越簡單越好
- 通常ES搭配Logstash使用,Influxdb搭配telegraf使用
以Influxdb為例,看一些如何插入和查詢數據:
Influxdb的HTTP API
創建DB
[root@host31 ~]# curl -i -XPOST http://192.168.32.31:8086/query --data-urlencode "q=CREATE DATABASE mydb" HTTP/1.1 200 OK Connection: close Content-Type: application/json Request-Id: 42a1f30c-5900-11e6-8003-000000000000 X-Influxdb-Version: 0.13.0 Date: Tue, 02 Aug 2016 22:27:13 GMT Content-Length: 16 {"results":[{}]}[root@host31 ~]#
寫入數據
[root@host31 ~]# curl -i -XPOST http://192.168.32.31:8086/query --data-urlencode "q=CREATE DATABASE mydb" HTTP/1.1 200 OK Connection: close Content-Type: application/json Request-Id: 42a1f30c-5900-11e6-8003-000000000000 X-Influxdb-Version: 0.13.0 Date: Tue, 02 Aug 2016 22:27:13 GMT Content-Length: 16 {"results":[{}]}[root@host31 ~]#
查詢寫入的數據
[root@host31 ~]# curl -GET 'http://192.168.32.31:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT \"value\" FROM \"cpu_load_short\" WHERE \"region\"='us-west'" { "results": [ { "series": [ { "name": "cpu_load_short", "columns": [ "time", "value" ], "values": [ [ "2015-06-11T20:46:02Z", 0.64 ] ] } ] } ] }[root@host31 ~]#
介紹Telegraf&Logstash:
- 都是數據收集和中轉的工具,架構都是插件式配置
- Telegraf相比Logstash更加輕量
- 都支持大量源,包括關係資料庫、NOSQL、直接收集操作系統信息(Linux、Win)、APP、服務(Docker)
執行模式分為兩種
- 主動:根據配置一次性讀取被收集的數據,收集完成後關閉進程
- 被動:作為進程駐留記憶體,監聽特定埠,等待消息發送
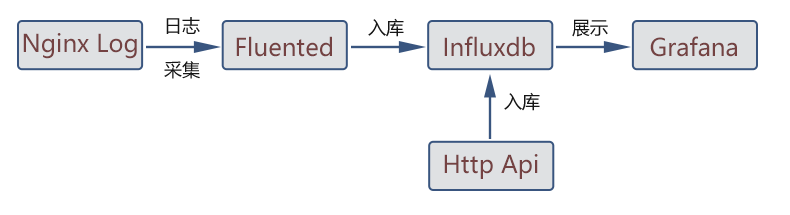
介紹兩種時序資料庫使用的架構:
1.日誌採集,然後存入influxdb,最後在grafana 中進行可視化查詢。
2.資料庫監控,主要通過採集關係型資料庫的性能指標分析資料庫的運行狀態便於監控和管理,如下圖所示

數據可視化展示
數據的可視化展示有很多種選擇,比如ELK中推薦使用kibana,配合es更方便,而搭配influxdb可以使用grafana。
目前grafana支持數據源
– ES
– Influxdb
– Prometheus
– Graphite
– OpenTSDB
– CloudWatch
安裝Grafana
Grafana的安裝很簡單,以Debian安裝為例:
執行命令: $ wget https://grafanarel.s3.amazonaws.com/builds/grafana_2.6.0_amd64.deb $ sudo apt-get install -y adduser libfontconfig $ sudo dpkg -i grafana_2.6.0_amd64.deb 啟動伺服器: $ sudo service grafana-server start
然後即可進行配置使用數據可視化了。這裡就不展開講了。下麵會有獨立文章介紹grafana和kibana。
總結
本篇簡要概述了時序資料庫的內容,介紹了特點並以influxdb為實例對比了與傳統資料庫的區別,以及如何使用Influxdb。最後講解了使用時序資料庫的架構,日誌和監控等,通過grafana進行可視化的數據查詢分析監控等。文章地址https://www.cnblogs.com/wenBlog/p/8297100.html

