
本文出處:http://www.cnblogs.com/wy123/p/7106861.html (保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他) 最近在SQL Server中多次遇到開發人員提交過來的有性能問題的SQL, ...
本文出處:http://www.cnblogs.com/wy123/p/7106861.html
(保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他)
最近在SQL Server中多次遇到開發人員提交過來的有性能問題的SQL,其錶面的原因是表之間去的驅動順序造成的性能問題,
具體表現在(已排除其他因素影響的情況下),存儲過程偶發性的執行時間超出預期,甚至在調試的時候,直接在存儲過程的SQL語句中植入某些具體的參數,在性能上仍達不到預期的響應時間。
此類問題在排除了伺服器資源因素,索引,鎖,parameter sniff等常見問題之後,確認識是表之間的驅動順序造成的,因為在嘗試sql語句的末尾加上option(force order)之後,性能迅速提升。
通常情況下,表之間連接的時候是採用“小表驅動大表”是一種相對比較高效的方式,也即在loop join的時候,先迴圈小表,通過迴圈驅動大表,然後產生查詢結果集。
該性能錶面上看,是表之間的驅動順序順序造成的,在強制一個驅動順序之後,性能有非常明顯的提升,
但是再進一步思考,為什麼預設情況下,SQL Server沒有選擇一個合理的驅動順序?
因此本文就簡單闡述這兩個問題:
1)為什麼表之間的驅動順序會影響性能?
2)為什麼SQL Server在某些情況下沒有選擇出正確的驅動順序?
為什麼表之間的驅動順序會影響性能?
首先演示一下表在連接的時候,驅動順序對性能的影響,其中test_smalltable插入1W行數據,test_bigtable插入10W行測試數據,依次來代表小表與大表
create table test_smalltable ( id int identity(1,1) primary key, otherColumns char(500) ) create table test_bigtable ( id int identity(1,1) primary key, otherColumns char(500) ) declare @i int = 0 while @i<100000 begin if @i<10000 begin insert into test_smalltable values (NEWID()) end insert into test_bigtable values (NEWID()) set @i = @i + 1 end
在測試表寫入數據完成之後,使用一下兩個SQL,通過強制使用loop join的驅動順序的方式來觀察其IO情況
select * from test_smalltable a inner loop join test_bigtable b on a.id = b.id option(force order) GO select * from test_bigtable a inner loop join test_smalltable b on a.id = b.id option(force order) GO
如圖,是兩個SQL執行之後產生的IO信息,可以發現,因為兩個表的驅動順序不一致,導致的邏輯IO幾乎差了一個數量級。
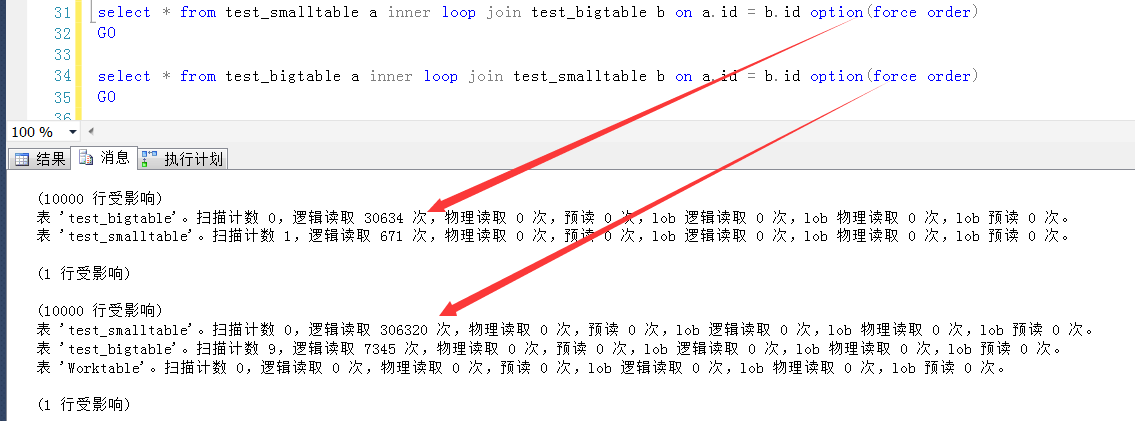
造成此問題的原因,可能有一些難以理解,雙迴圈嵌套,誰在外誰在內還有差別,錶面上看不都是一樣的?其實不然。
loop join是採用的類似如下雙迴圈嵌套的方式來執行的,直至外層的表迴圈結束,迴圈(查詢)完成
foreache(outer_row in outer_table)
{
foreache(internal_row in internal_table)
{
if (outer_row.key = internal_row.key)
{
--輸出結果
}
}
}
以上述測試為例,做一個粗略的對比統計
如果外層是小表(1W行),外層迴圈1W次,分別對內層的大表(10W行)查詢,然後結束查詢,相當於迴圈1W次,分別用Id查詢內層表,
可以粗略地認為整體的代價是:1W+1W*10W = 11W,這裡先忽略具體代價的單位
如果外層是大表(10W行),外層迴圈10W次,分別對內層的小表(1W行)查詢,然後結束查詢,相當於迴圈10W次,分別用Id查詢內層表,
可以粗略地認為整體的代價是:10W+10W*1W = 20W,同理,這裡也先忽略代價的單位
現在就很清楚了,前者(小表驅動大表)的代價是11W,後者(大表驅動小表)的代價是20W,因此,通常來說,小表驅動大表是一種相對較為高效的方式。
但是要註意這裡的大表與小表,不僅僅是“表”級別的概念,因為實際中SQL並沒有這麼簡單,還可以是根據篩選條件過濾之後的結果的概念,這也是引出第二個問題的關鍵點。
為什麼SQL Server在某些情況下沒有選擇出正確的驅動順序
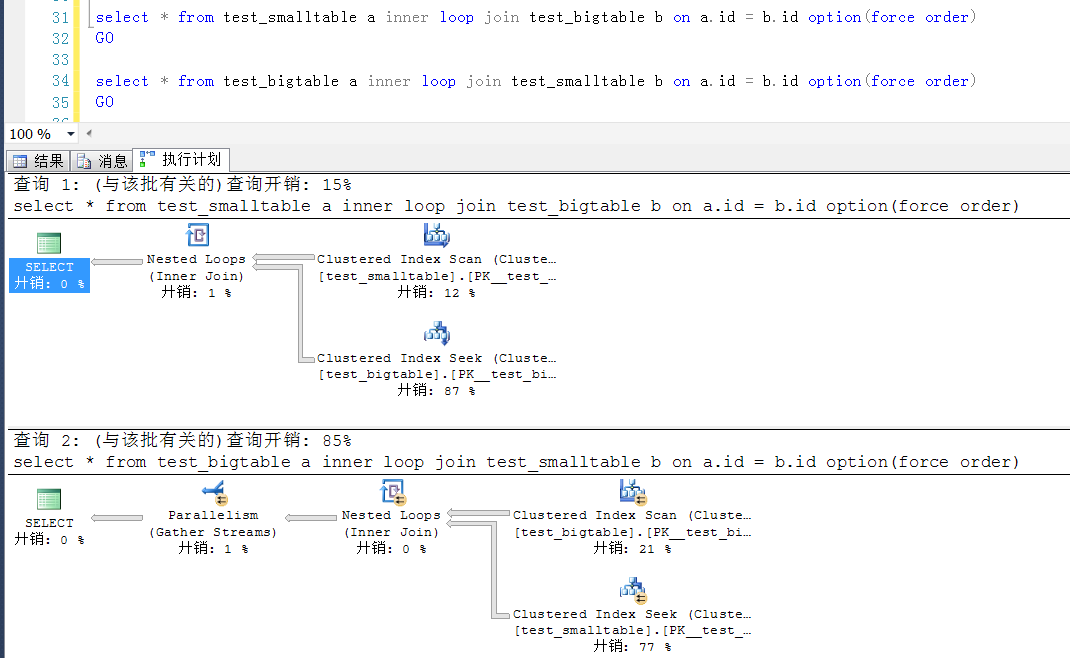
在上述的測試中,如果不加查詢提示,執行計劃的生成是跟表書寫的順序沒有關係的,一下截圖可以看到,書寫順序不一樣,執行計劃仍舊是一樣的。
也就是說,在書寫SQL語句的時候,大表在前或者在後,正常情況下是不影響執行計劃的生成的。

那麼為什麼,一開始提到的問題,為什麼SQL Server在某些情況下沒有選擇出正確的驅動順序還會出現?
實際情況中,SQL的寫法很少有這麼簡單的,更多的時候是在表連接之後,有各種各樣的where條件。
上面說了,大表與小表的概念,不僅僅是“表”級別的概念,更多的是根據篩選條件過濾之後的結果(行數,或者大小)的概念,
比如,如下SQL,在where條件上可能加上各種篩選條件,比如可能是類似於type類型的,可能是時間範圍的,還有可能兩個表上都有某些篩選條件。
select * from test_smalltable a
inner join test_bigtable b on a.id = b.id
where a.otherColumns = '' and b.otherColumns = '' and other filter condition
那麼此時,在面對複雜的查詢的時候,SQL Server如何評估每個表經過各種條件篩選後的結果集的大小?
當然是依據where 後面的篩選條件(或者是on 後面的加的篩選條件),問題就來了,where 後面或者on後面的篩選條件,如何又依據什麼來提供一個大概的篩選後的結果集?
沒錯,又是統計信息!
現在問題就清晰了起來,SQL Server依據統計信息,在經過各種(或許是比較複雜)的篩選條件過濾之後,得到一個“它自己認為的預估大小的結果集”,然後依據這個結果集來決定驅動順序。
SQL Server在“它自己認為的預估大小的結果集”的基礎上進行類似於“小表驅動大表”的方式進行運算(當然不僅僅是loop join,這裡暫不說其他的join方式),
一旦這個預估的結果集的大小有較大的誤差,即便是誤差不大,但是足以改變真正的“小表驅動大表”的方式進行運算,第二個問題就出現了。
因此,總的來說,錯誤的驅動順序,本質上在利用統計信息進行預估的時候,因為統計信息不足夠準確或者預估演算法自己的問題。
參考:http://www.cnblogs.com/wy123/tag/%E7%BB%9F%E8%AE%A1%E4%BF%A1%E6%81%AF%20Statistics/
導致SQL Server錯誤地用大表驅動的方式來執行運算,類似問題就出現了。
鑒於該問題的特殊性,很難造case,就不造case演示了,截兩個實際遇到的對比結果,驅動順序的影響,可能是從0.5秒到10秒的差別,,也可能是1分鐘到10分鐘的差別
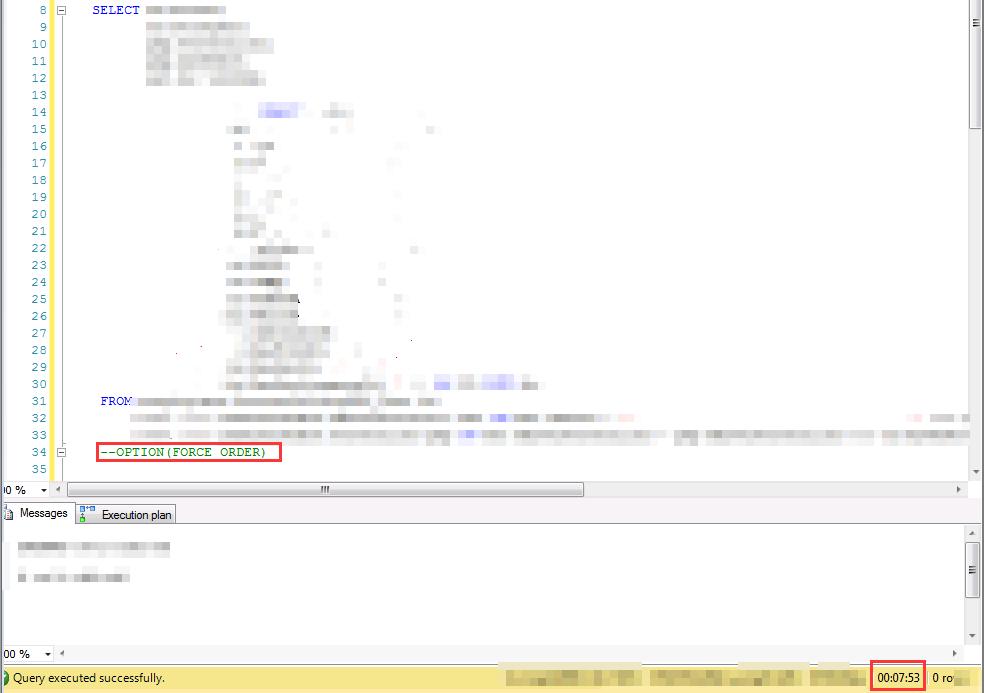
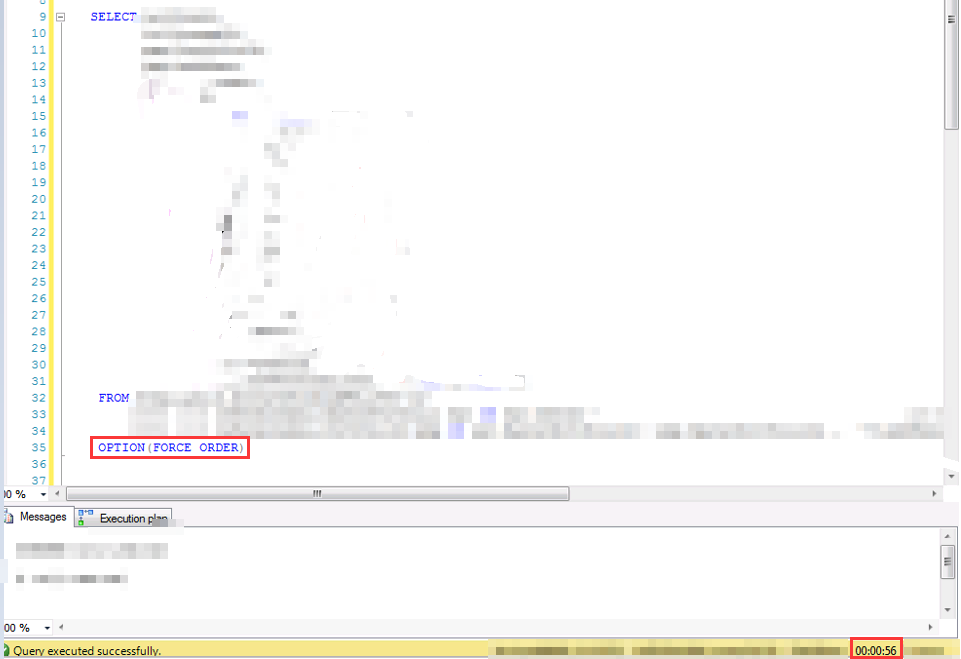
當然,加option(force order)的時候,要註意寫法本身的是不是將小表放在了最前面,
在複雜的情況下,雖然是驅動順序造成的問題,但是加option(force order)並不一定好使,因為多表連接的時候,按照書寫的方式強制驅動,也不一定剛好就是一個合理的驅動順序
甚至有更嚴重的問題出現,參考:http://www.cnblogs.com/wy123/p/6238844.html,因此不建議亂用option(force order)
總結:
面對較為複雜的查詢和篩選條件的時候,尤其是在表中的數據較大的情況下,統計信息生成的預估,以及預估產生的表之間的驅動順序,會對性能產生較大的影響。
面對類似問題,要確實直接原因是什麼,根本原因是什麼,如何快速確認問題,又要如何解決和避免,都是值得思考的,也是做性能優化的時候要考慮的問題之一。

