
今天看到一個博客園的一篇關於MySQL的IN子查詢優化的案例,一開始感覺有點半信半疑(如果是換做在SQL Server中,這種情況是絕對不可能的,後面會做一個簡單的測試。)隨後動手按照他說的做了一個表來測試驗證,發現MySQL的IN子查詢做的不好,確實會導致無法使用索引的情況(IN子查詢無法使用所以 ...
今天看到一個博客園的一篇關於MySQL的IN子查詢優化的案例,
一開始感覺有點半信半疑(如果是換做在SQL Server中,這種情況是絕對不可能的,後面會做一個簡單的測試。)
隨後動手按照他說的做了一個表來測試驗證,發現MySQL的IN子查詢做的不好,確實會導致無法使用索引的情況(IN子查詢無法使用所以,場景是MySQL,截止的版本是5.7.18)
MySQL的測試環境
測試表如下
create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time datetime, other_col varchar(100) )
建一個存儲過程插入測試數據,測試數據的特點是pay_id可重覆,這裡在存儲過程處理成,迴圈插入300W條數據的過程中,每隔100條數據插入一條重覆的pay_id,時間欄位在一定範圍內隨機
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT) LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN declare cnt int; set cnt = 0; while cnt< loopcount do insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid()); if (cnt mod 100 = 0) then insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid()); end if; set cnt = cnt + 1; end while; END
執行 call test_insert(3000000); 插入303000行數據

兩種子查詢的寫法
查詢大概的意思是查詢某個時間段之內的業務Id大於1的數據,於是就出現兩種寫法。
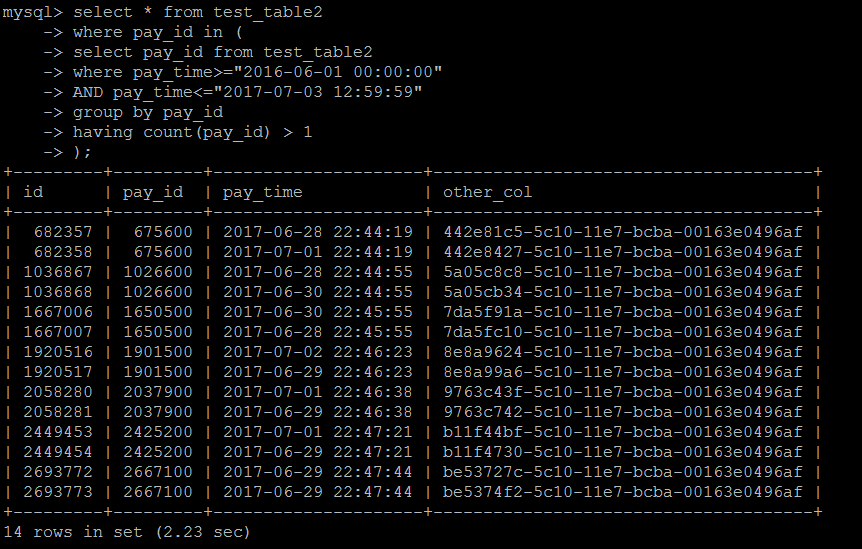
第一種寫法如下:IN子查詢中是某段時間內業務統計行數大於1的業務Id,外層按照IN子查詢的結果進行查詢,業務Id的列pay_id上有索引,邏輯也比較簡單,
這種寫法,在數據量大的時候確實效率比較低,用不到索引
select * from test_table2 force index(idx_pay_id) where pay_id in ( select pay_id from test_table2 where pay_time>="2016-06-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1 );
執行結果:2.23秒
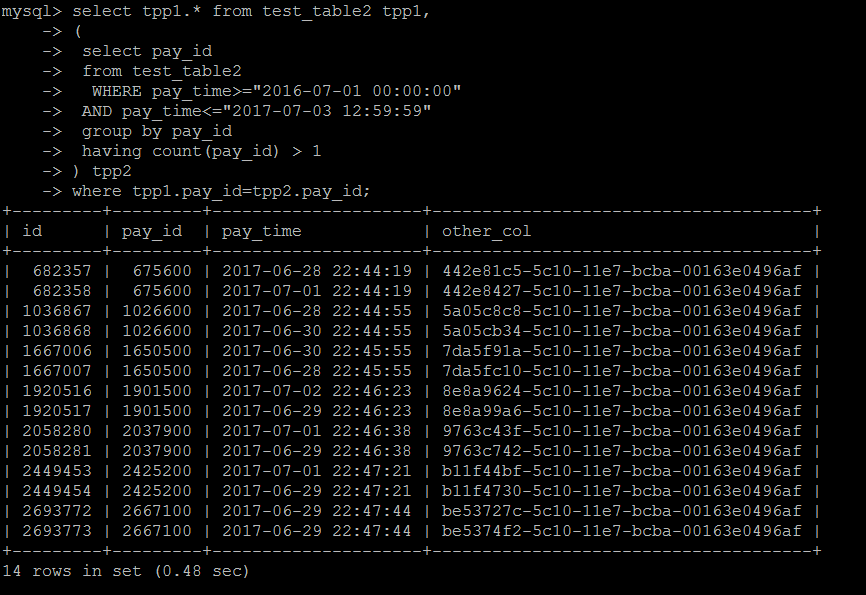
第二種寫法,與子查詢進行join關聯,這種寫法相當於上面的IN子查詢寫法,下麵測試發現,效率確實有不少的提高
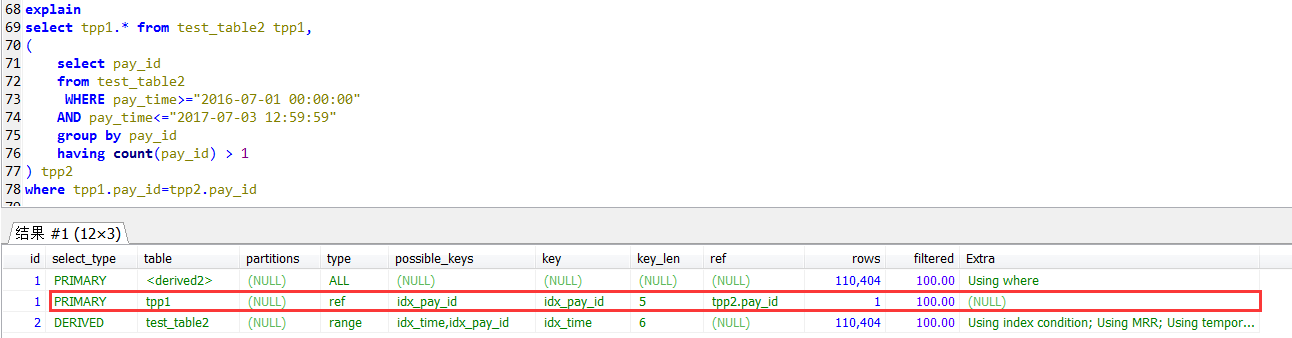
select tpp1.* from test_table2 tpp1, ( select pay_id from test_table2 WHERE pay_time>="2016-07-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1 ) tpp2 where tpp1.pay_id=tpp2.pay_id
執行結果:0.48秒
In子查詢的執行計劃,發現外層查詢是一個全表掃描的方式,沒有用到pay_id上的索引
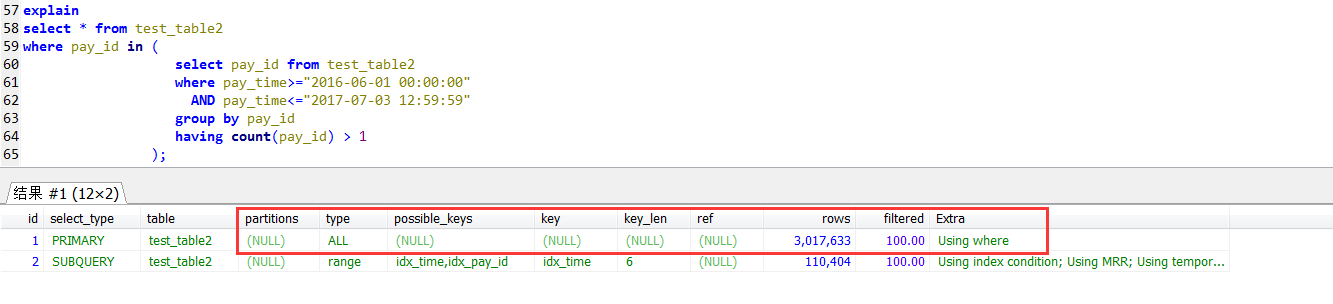
join自查的執行計劃,外層(tpp1別名的查詢)是用到pay_id上的索引的。
後面想對第一種查詢方式使用強制索引,雖然是不報錯的,但是發現根本沒用

如果子查詢是直接的值,則是可以正常使用索引的。

可見MySQL對IN子查詢的支持,做的確實不怎麼樣。
另外:加一個使用臨時表的情況,雖然比不少join方式查詢的,但是也比直接使用IN子查詢效率要高,這種情況下,也是可以使用到索引的,不過這種簡單的情況,是沒有必要使用臨時表的。

下麵是類似案例在sqlserver 2014中的測試,幾萬完全一樣的測試表結構和數量,可見這種情況下,兩種寫法,在SQL Server中可以認為是完全一樣的(執行計劃+效率),這一點SQL Server要比MySQL強不少
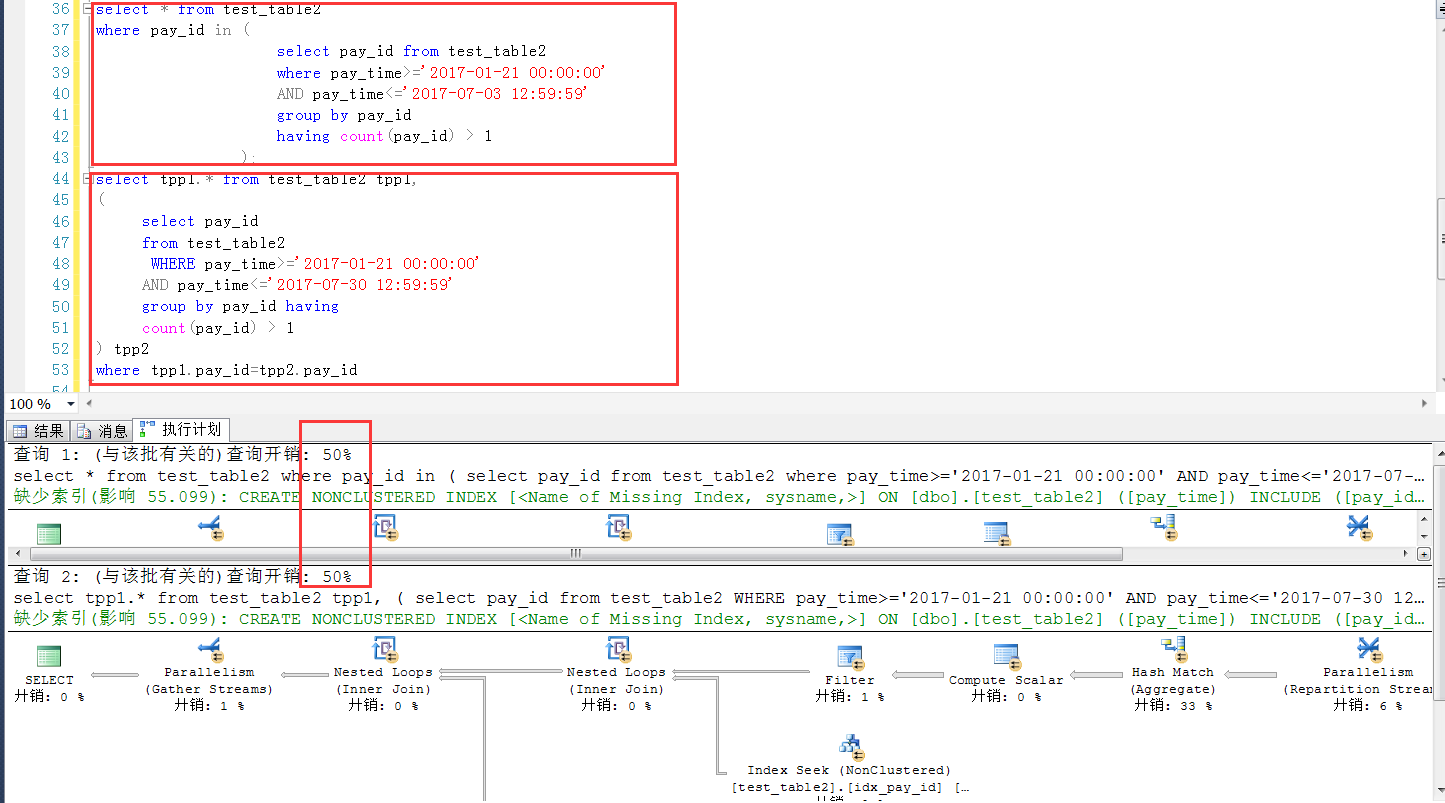
下麵是sqlserver中的測試環境腳本。
create table test_table2 ( id int identity(1,1) primary key, pay_id int, pay_time datetime, other_col varchar(100) ) begin tran declare @i int = 0 while @i<300000 begin insert into test_table2 values (@i,getdate()-rand()*300,newid()); if(@i%1000=0) begin insert into test_table2 values (@i,getdate()-rand()*300,newid()); end set @i = @i + 1 end COMMIT GO create index idx_pay_id on test_table2(pay_id); create index idx_time on test_table2(pay_time); GO select * from test_table2 where pay_id in ( select pay_id from test_table2 where pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-03 12:59:59' group by pay_id having count(pay_id) > 1 ); select tpp1.* from test_table2 tpp1, ( select pay_id from test_table2 WHERE pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-30 12:59:59' group by pay_id having count(pay_id) > 1 ) tpp2 where tpp1.pay_id=tpp2.pay_id
總結:在MySQL數據中,截止5.7.18版本,對IN子查詢,仍要慎用


