
XML語言 什麼是XML? XML是指可擴展標記語言(eXtensible Markup Language),它是一種標記語言,很類似HTML。它被設計的宗旨是傳輸數據,而非顯示數據。 XML標簽沒有被預定義,需要用戶自行定義標簽。 XML技術是W3C組織(World Wide Web Consor ...
XML語言
什麼是XML?
XML是指可擴展標記語言(eXtensible Markup Language),它是一種標記語言,很類似HTML。它被設計的宗旨是傳輸數據,而非顯示數據。 XML標簽沒有被預定義,需要用戶自行定義標簽。 XML技術是W3C組織(World Wide Web Consortium萬維網聯盟)發佈的,目前遵循的是W3C組織於2000年發佈的XML1.0規範。 XML被廣泛認為是繼Java之後在Internet上最激動人心的新技術。
XML技術用於解決什麼問題?
在現實生活中存在大量有關係的數據,如右圖所示。
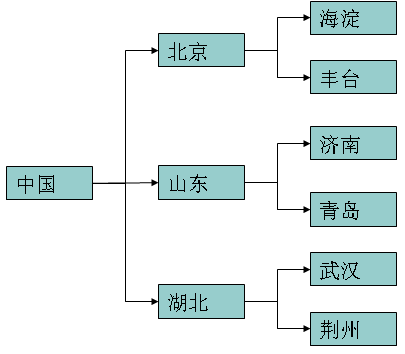
問題:這樣的數據該如何表示並交給電腦處理呢?
XML語言出現的根本目的在於描述向上圖那種有關係的數據。
XML是一種通用的數據交換格式。
在XML語言中,它允許用戶自定義標簽。一個標簽用於描述一段數據;一個標簽可分為開始標簽和結束標簽,在起始標簽之間,又可以使用其它標簽描述其它數據,以此來實現數據關係的描述。
XML中的數據必須通過軟體程式來解析執行或顯示,如IE;這樣的解析程式稱之為Parser(解析器)。
<?xml version="1.0" encoding="UTF-8"?> <中國> <北京> <海澱></海澱> <丰台></丰台> </北京> <山東> <濟南></濟南> <青島></青島> </山東> <湖北> <武漢></武漢> <荊州></荊州> </湖北> </中國>
XML常見應用:
XML技術除用於保存有關係的數據之外,它還經常用作軟體配置文件,以描述程式模塊之間的關係。(如後面將要學習到的Struts、Spring和Hibernate都是基於XML作為配置文件的)
在一個軟體系統中,通過XML配置文件可以提高系統的靈活性。即程式的行為是通過XML文件來配置的,而不是硬編碼。
數據交換:不同語言之間用來交換數據
小型資料庫:用來當資料庫存儲數據。
XML語法:
XML語法:
一個XML文件分為如下幾部分內容:
文檔聲明 元素 屬性 註釋 CDATA區 、特殊字元 處理指令(PI:Processing Instruction)
文檔聲明
在編寫XML文檔時,需要先使用文檔聲明來聲明XML文檔。且必須出現在文檔的第一行。並且必須指定
最簡單的語法:
<?xml version=“1.0”?>
用encoding屬性說明文檔所使用的字元編碼。保存在磁碟上的文件編碼要與聲明的編碼一致。如:
<?xml version=“1.0” encoding=“GB2312”?>
用standalone屬性說明文檔是否獨立,即是否依賴其他文檔。 如:
<?xml version=“1.0” standalone=“yes”?>
yes不用引入外部的文件,no需要引入。(不常用)
元素
標簽
XML元素指XML文件中出現的標簽。
一個標簽分為起始和結束標簽(不能省略)。一個標簽有如下幾種書寫形式:
包含標簽主體:<mytag>some content</mytag>
不含標簽主體:<mytag/>
一個標簽中可以嵌套若幹子標簽,但所有標簽必須合理的嵌套,不允許有交叉嵌套。
<mytag1><mytag2></mytag1></mytag2> WRONG!
一個XML文檔必須有且僅有一個根標簽,其他標簽都是這個根標簽的子標簽或孫標簽。
標簽的空格、換行
對於XML標簽中出現的所有空格和換行,XML解析程式都會當作標簽內容進行處理。例如:下麵兩段內容的意義是不一樣的。

由於在XML中,空格和換行都作為原始內容被處理,所以,在編寫XML文件時,使用換行和縮進等方式來讓原文件中的內容清晰可讀的“良好”書寫習慣可能要被迫改變。
命名規範
一個XML元素可以包含字母、數字以及其它一些可見字元,但必須遵守下麵的一些規範:
區分大小寫,例如,<P>和<p>是兩個不同的標記。
不能以數字或“-” (中劃線)開頭。
不能以xml(或XML、或Xml 等)開頭。
不能包含空格。
名稱中間不能包含冒號(:)。
屬性
一個元素可以有多個屬性,每個屬性都有它自己的名稱和取值,例如:<mytag name=“value” …/>
屬性值一定要用引號(單引號或雙引號)引起來。
屬性名稱的命名規範與元素的命名規範相同
元素中的屬性是不允許重覆的
在XML技術中,標簽屬性所代表的信息也可以被改成用子元素的形式來描述,例如:
<mytag> <name> <firstName/> <lastName/> </name> </mytag>
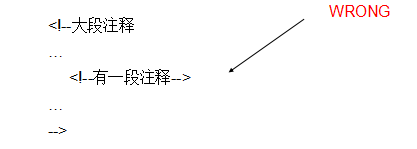
註釋
XML中的註釋語法為:<!--這是註釋-->
註意:
XML聲明之前不能有註釋
註釋不能嵌套,例如:
轉義字元

註:< 和 & 的符號要用轉義字元, > “ ‘ 可以不使用轉義字元。
CDATA區
CDATA是Character Data的縮寫
作用:把標簽當做普通文本內容;
語法:<![CDATA[內容]]>
<![CDATA[ <itcast>www.itcast.cn</itcast> ]]>
以上紅色部分被當做普通文本而不是標簽
處理指令
處理指令,簡稱PI(Processing Instruction)。
作用:用來指揮軟體如何解析XML文檔。
語法:必須以“<?”作為開頭,以“?>”作為結尾。 常用處理指令:
常用處理指令:
XML聲明:
<?xml version=“1.0” encoding=“GB2312”?>
xml-stylesheet指令: 作用:指示XML文檔所使用的CSS樣式XSL。
<?xml-stylesheet type=“text/css” href=“some.css”?>
註:對中文命名的標簽元素不起作用
XML語法規則總結
所有 XML 元素都須有關閉標簽
XML 標簽對大小寫敏感 XML
必須正確地嵌套順序
XML 文檔必須有根元素(只有一個)
XML 的屬性值須加引號
特殊字元必須轉義 --- CDATA
XML 中的空格、回車換行會解析時被保留
XML約束:
為什麼需要約束
1.XML都是用戶自定義的標簽,若出現小小的錯誤,軟體程式將不能正確地獲取文件中的內容而報錯。(如:Tomcat)
2.XML技術中,可以編寫一個文檔來約束一個XML的書寫規範,這個文檔稱之為約束。
兩個概念:
格式良好的XML:遵循XML語法的XML
有效的XML:遵循約束文檔的XML
3.總之:約束文檔定義了在XML中允許出現的元素名稱、屬性及元素出現的順序等等。
XML約束概述
1.什麼是XML約束
在XML技術里,可以編寫一個文檔來約束一個XML
文檔的書寫規範,這稱之為XML約束。
2.為什麼需要XML約束
3.常用的約束技術
XML DTD
XML Schema
XML約束之DTD約束
DTD概述
1.DTD(Document Type Definition),全稱為文檔類型定義。
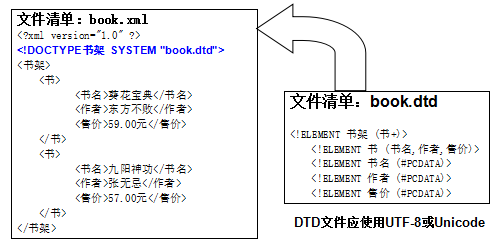
2.書寫完成DTD,並且約束成功後,可以總結書寫的過程,更方便記憶。
複雜標簽:<!ELEMENT 標簽名 (子節點)>
簡單標簽:<!ELEMENT 標簽名 (#PCDATA)>
引入DTD:<!DOCTYPE 根節點 SYSTEM “dtd的地址”>
將DTD與XML文檔關聯三種方式
DTD約束即可以作為一個單獨的文件編寫,也可以在XML文件內編寫
1.使用內部DTD
<!DOCTYPE 根節點 [ DTD的代碼 ]>
2.使用外部DTD
<!DOCTYPE 根節點 SYSTEM “DTD的地址” >
3.使用網路DTD
<!DOCTYPE 根節點 PUBLIC “DTD的名稱” “DTD的地址” >
常見的使用網路DTD約束有 Struts2的框架
在xml文件內編寫DTD
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <!DOCTYPE 書架 [ <!ELEMENT 書架 (書+)> <!ELEMENT 書 (書名,作者,售價)> <!ELEMENT 書名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售價 (#PCDATA)> ]> <書架> <書> <書名>Java就業培訓教程</書名> <作者>張孝祥</作者> <售價>39.00元</售價> </書> ... </書架>
引入外部DTD文檔
XML使用DOCTYPE聲明語句來指明它所遵循的DTD文檔,有兩種形式:
當引用的DTD文檔在本地時,採用如下方式:
<!DOCTYPE 根元素 SYSTEM “DTD文檔路徑”>
如:
<!DOCTYPE 書架 SYSTEM “book.dtd”>
當引用的DTD文檔在公共網路上時,採用如下方式:
<!DOCTYPE 根元素 PUBLIC “DTD名稱” “DTD文檔的URL”>
如:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
DTD約束語法細節
元素定義 屬性定義 實體定義
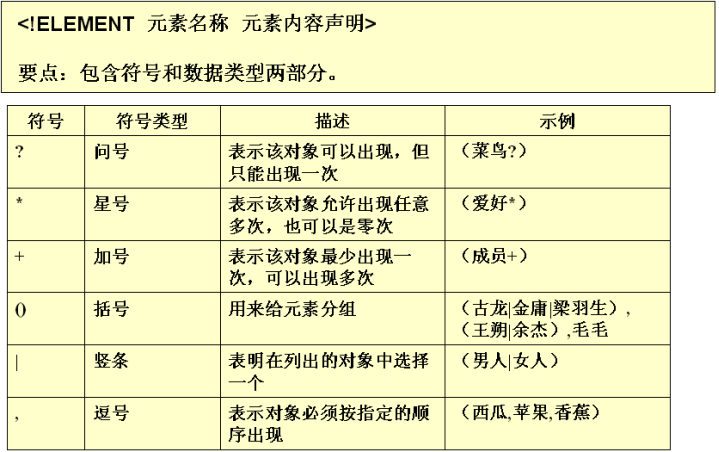
元素(ELEMENT)定義
在DTD文檔中使用ELEMENT關鍵字來聲明一個XML元素。
語法:<!ELEMENT 元素名稱 使用規則>
使用規則:
(#PCDATA):指示元素的主體內容只能是普通的文本.(Parsed Character Data)
EMPTY:用於指示元素的主體為空。比如<br/>
ANY:用於指示元素的主體內容為任意類型。
(子元素):指示元素中包含的子元素

定義子元素及描述它們的關係:
如果子元素用逗號分開,說明必須按照聲明順序去編寫XML文檔。
如: <!ELEMENT FILE (TITLE,AUTHOR,EMAIL)
如果子元素用“|”分開,說明任選其一。
如:<!ELEMENT FILE (TITLE|AUTHOR|EMAIL)
用+、*、?來表示元素出現的次數
如果元素後面沒有+*?:表示必須且只能出現一次
+:表示至少出現一次,一次或多次
*:表示可有可無,零次、一次或多次
?:表示可以有也可以無,有的話只能有一次。零次或一次 如: <!ELEMENT MYFILE ((TITLE*, AUTHOR?, EMAIL)* | COMMENT)>
屬性(ATTLIST)定義

屬性聲明舉例
<!ATTLIST 商品 類別 CDATA #REQUIRED 必須的 顏色 CDATA #IMPLIED 可選的 >
對應的XML為:<商品 類別=“服裝” 顏色=“黃色”/>
屬性值類型
CDATA:表示屬性的取值為普通的文本字元串
ENUMERATED (DTD沒有此關鍵字):表示枚舉,只能從枚舉列表中任選其一,如(雞肉|牛肉|豬肉|魚肉)
ID:表示屬性的取值不能重覆(不能只寫數字)
設置說明
#REQUIRED:表示該屬性必須出現
#IMPLIED:表示該屬性可有可無
#FIXED:表示屬性的取值為一個固定值。語法:#FIXED "固定值"
直接值:表示屬性的取值為該預設值

定義屬性示例
<!ATTLIST 頁面作者 姓名 CDATA #IMPLIED 年齡 CDATA #IMPLIED 聯繫信息 CDATA #REQUIRED 網站職務 CDATA #FIXED "頁面作者" 個人愛好 CDATA "上網" >
屬性的類型可以是一組取值的列表,在 XML 文件中設置的屬性值只能是這個列表中的某個值(枚舉)
<?xml version = "1.0" encoding="GB2312" standalone="yes"?> <!DOCTYPE 購物籃 [ <!ELEMENT 肉 EMPTY> <!ATTLIST 肉 品種 ( 雞肉 | 牛肉 | 豬肉 | 魚肉 ) "雞肉"> ]> <購物籃> <肉 品種="魚肉"/> <肉 品種="牛肉"/> <肉/> </購物籃>
表示屬性的設置值為一個唯一值。
ID 屬性的值只能由字母,下劃線開始,不能出現空白字元
?xml version = "1.0" encoding="GB2312" ?> <!DOCTYPE 聯繫人列表[ <!ELEMENT 聯繫人列表 ANY> <!ELEMENT 聯繫人(姓名,EMAIL)> <!ELEMENT 姓名(#PCDATA)> <!ELEMENT EMAIL(#PCDATA)> <!ATTLIST 聯繫人 編號 ID #REQUIRED> ]> <聯繫人列表> <聯繫人 編號=“p1"> <姓名>張三</姓名> <EMAIL>[email protected]</EMAIL> </聯繫人> <聯繫人 編號=“p2"> <姓名>李四</姓名> <EMAIL>[email protected]</EMAIL> </聯繫人> </聯繫人列表>
實體定義
實體用於為一段內容創建一個別名,以後在XML文檔中就可以使用別名引用這段內容了。
在DTD定義中,一條<!ENTITY …>語句用於定義一個實體。
<!ENTITY 別名 “值”>
在元素中引用 &別名;
定義引用實體
概念:在DTD中定義,在XML中使用
語法:<!ENTITY 實體名稱 “實體內容”>
引用方式(註意是在XML中使用):&實體名稱;
DTD中定義: <!ENTITY copyright “博客園版權所有”>
XML中引用: ©right;
XML約束之Schema
Schema概述:
XML Schema 也是一種用於定義和描述 XML 文檔結構與內容的模式語言,其出現是為了剋服 DTD 的局限性
XML Schema vs DTD:
XML Schema符合XML語法結構。
DOM、SAX等XML API很容易解析出XML Schema文檔中的內容。
XML Schema對名稱空間支持得非常好。
XML Schema比XML DTD支持更多的數據類型,並支持用戶自定義新的數據類型。
XML Schema定義約束的能力非常強大,可以對XML實例文檔作出細緻的語義限制。
XML Schema不能像DTD一樣定義實體,比DTD更複雜,但Xml Schema現在已是w3c組織的標準,它正逐步取代DTD。
好處:
XML Schema是用一套預先規定的XML元素和屬性創建的,這些元素和屬性定義了XML文檔的結構和內容模式。 XML Schema規定XML文檔實例的結構和每個元素/屬性的數據類型
Schema相對於DTD的明顯好處是,XML Schema文檔本身也是XML文檔,而不是像DTD一樣使用自成一體的語法
Schema和DTD區別
XML從SGML中繼承了DTD,並用它來定義內容的模型,驗證和組織元素。同時,它也有很多局限:
DTD不遵守XML語法; DTD不可擴展; DTD不支持命名空間的應用; DTD沒有提供強大的數據類型支持,只能表示很簡單的數據類型。
Schema完全剋服了這些弱點,使得基於Web的應用系統交換XML數據更為容易。下麵是它所展現的一些新特性:
Schema完全基於XML語法,不需要再學習特殊的語法; Schema能用處理XML文檔的工具處理,而不需要特殊的工具; Schema大大擴充了數據類型,支持booleans、numbers、dates and times、URIs、integers、decimal numbers和real numbers等; Schema支持原型,也就是元素的繼承。如:我們定義了一個“聯繫人”數據類型,然後可以根據它產生“朋友聯繫人”和“客戶聯繫”兩種數據類型; Schema支持屬性組。我們一般聲明一些公共屬性,然後可以應用於所有的元素,屬性組允許把元素、屬性關係放於外部定義、組合; 開放性。原來的DTD只能有一個DTD應用於一個XML文檔,現在可以有多個Schema運用於一個XML文檔。
Schema一些概念
XML Schema 文件自身就是一個XML文件,但它的擴展名通常為.xsd
和XML文件一樣,一個XML Schema文檔也必須有一個根結點,但這個根結點的名稱為Schema
應用schema約束 開發xml 過程:

編寫了一個XML Schema約束文檔後,通常需要把這個文件中聲明的元素綁定到一個URI地址上,這個URI地址叫namespace名稱空間,以後XML文件就可以通過這個URI(即名稱空間)引用綁定指定名稱空間的元素
XMLSchema文檔基本結構
在W3C XML schema規範中規定:所有的Schema文檔都使用<schema>作為其根元素

<schema>元素可以包含一些屬性。一個XML schema聲明看起來經常以如下的形式出現

Schema入門案例
book.xsd文件
<?xml version="1.0" encoding="UTF-8" ?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www. itcast.cn" elementFormDefault="qualified"> <xs:element name='書架' > <xs:complexType> <xs:sequence maxOccurs='unbounded' > <xs:element name='書' > <xs:complexType> <xs:sequence> <xs:element name='書名' type='xs:string' /> <xs:element name='作者' type='xs:string' /> <xs:element name='售價' type='xs:string' /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
<?xml version="1.0" encoding="UTF-8"?> <itcast:書架 xmlns:itcast="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=“http://www.itcast.cn book.xsd"> <itcast:書> <itcast:書名>九陰真經</itcast:書名> <itcast:作者>郭靖</itcast:作者> <itcast:售價>28.00元</itcast:售價> </itcast:書> </itcast:書架>
在XML Schema文檔中聲明名稱空間
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www. itcast.cn" elementFormDefault="qualified" attributeFormDefault="qualified" > <xs:schema>
targetNamespace元素用於指定schema文檔中聲明的元素屬於哪個名稱空間。
elementFormDefault元素用於指定局部元素是否受到該schema指定targetNamespace所指定的名稱空間限定
attributeFormDefault元素用於指定局部屬性是否受到該schema指定targetNamespace所指定的名稱空間限定
名稱空間的概念:
在XML Schema中,每個約束模式文檔都可以被賦以一個唯一的名稱空間,名稱空間用一個唯一的URI(Uniform Resource Identifier,統一資源標識符)表示。 在Xml文件中書寫標簽時,可以通過名稱空間聲明(xmlns),來聲明當前編寫的標簽來自哪個Schema約束文檔。如:
<itcast:書架 xmlns:itcast=“http://www.itcast.cn”> <itcast:書>……</itcast:書> </itcast:書架>
此處使用itcast來指向聲明的名稱,以便於後面對名稱空間的引用。
註意:名稱空間的名字語法容易讓人混淆,儘管以 http:// 開始,那個 URL 並不指向一個包含模式定義的文件。事實上,這個 URL:http://www.itcast.cn根本沒有指向任何文件,只是一個分配的名字。
使用名稱空間引入Schema
為了在一個XML文檔中聲明它所遵循的Schema文件的具體位置,通常需要在Xml文檔中的根結點中使用schemaLocation屬性來指定,例如:
<itcast:書架 xmlns:itcast="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=“http://www.itcast.cn book.xsd">
schemaLocation此屬性有兩個值。第一個值是需要使用的命名空間。第二個值是供命名空間使用的 XML schema 的位置,兩者之間用空格分隔。
註意:在使用schemaLocation屬性時,也需要指定該屬性來自哪裡。
使用預設名稱空間
基本格式:
xmlns="URI"
舉例:
<書架 xmlns=" http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=“http://www.itcast.cn book.xsd"> <書> <書名>JavaScript網頁開發</書名> <作者>張孝祥</作者> <售價>28.00元</售價> </書> </書架>
使用名稱空間引入多個XML Schema文檔
文件清單:xmlbook.xml
<?xml version="1.0" encoding="UTF-8"?> <書架 xmlns="http://www.it315.org/xmlbook/schema" xmlns:demo="http://www.it315.org/demo/schema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.it315.org/xmlbook/schema http://www.it315.org/xml/book.xsd http://www.it315.org/demo/schema http://www.it315.org/demo.xsd"> <書> <書名>JavaScript網頁開發</書名> <作者>張孝祥</作者> <售價 demo:幣種=”人民幣”>28.00元</售價> </書> </書架>
XML Schema基礎概念
Schema元素:簡單類型和複雜類型
XML Schema規範中將元素分為兩種類型
簡單類型元素:簡單類型元素只能包含字元內容。這些字元可以被約束為特殊的預定義類型或派生類型。例如,可以指定一個簡單元素的內容必須是日期、整數、字元串或者僅僅是一個字元或者一系列字元。type屬性
複雜類型元素:複雜類型元素是包含子元素內容或者屬性的元素 <complexType> <sequence> 子元素
Schema語法
參看w3c文檔
XML編程(CRUD)
XML解析技術概述
XML解析方式分為兩種:
DOM方式和SAX方式
DOM:Document Object Model,文檔對象模型。這種方式是W3C推薦的處理XML的一種方式。
SAX:Simple API for XML。這種方式不是官方標準,屬於開源社區XML-DEV,幾乎所有的XML解析器都支持它。
XML解析開發包 :
JAXP:是SUN公司推出的解析標準實現。
Dom4J:是開源組織推出的解析開發包。(牛,大家都在用,包括SUN公司的一些技術的實現都在用) J
Dom:是開源組織推出的解析開發包。
JAXP:
JAXP:(Java API for XML Processing)開發包是JavaSE的一部分,它由以下幾個包及其子包組成:
org.w3c.dom:提供DOM方式解析XML的標準介面
org.xml.sax:提供SAX方式解析XML的標準介面
javax.xml:提供瞭解析XML文檔的類
javax.xml.parsers包中,定義了幾個工廠類。我們可以通過調用這些工廠類,得到對XML文檔進行解析的DOM和SAX解析器對象。 DocumentBuilderFactory
SAXParserFactory
DOM解析:
使用JAXP進行DOM解析
javax.xml.parsers 包中的DocumentBuilderFactory用於創建DOM模式的解析器對象 , DocumentBuilderFactory是一個抽象工廠類,它不能直接實例化,但該類提供了一個newInstance方法 ,這個方法會根據本地平臺預設安裝的解析器,自動創建一個工廠的對象並返回。
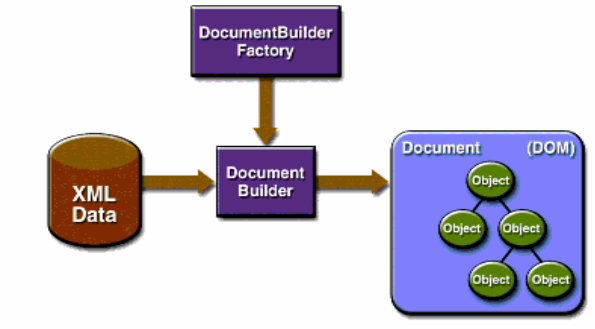
獲得JAXP中的DOM解析器
調用 DocumentBuilderFactory.newInstance() 方法得到創建 DOM 解析器的工廠。
調用工廠對象的 newDocumentBuilder方法得到 DOM 解析器對象。
調用 DOM 解析器對象的 parse() 方法解析 XML 文檔,得到代表整個文檔的 Document 對象,進行可以利用DOM特性對整個XML文檔進行操作了。
DOM編程介紹
DOM模型(document object model)
DOM解析器在解析XML文檔時,會把文檔中的所有元素,按照其出現的層次關係,解析成一個個Node對象(節點)。
在dom中,節點之間關係如下:
位於一個節點之上的節點是該節點的父節點(parent)
一個節點之下的節點是該節點的子節點(children)
同一層次,具有相同父節點的節點是兄弟節點(sibling)
一個節點的下一個層次的節點集合是節點後代(descendant)
父、祖父節點及所有位於節點上面的,都是節點的祖先(ancestor)
節點類型:Node對象
Node對象提供了一系列常量來代表結點的類型,當開發人員獲得某個Node類型後,就可以把Node節點轉換成相應的節點對象(Node的子類對象),以便於調用其特有的方法。(查看API文檔)
Node對象提供了相應的方法去獲得它的父結點或子結點。編程人員通過這些方法就可以讀取整個XML文檔的內容、或添加、修改、刪除XML文檔的內容了。
DOM方式解析XML文件
DOM解析編程:
1獲取指定節點的集合
2查找某一個節點
3刪除結點
4更新結點內容
5添加節點
6獲取所有的節點的名稱(遞歸遍歷)
具體步驟為:
1通過document.getElementsByTagName(“”) 可以獲取節點集合 返回NodeList
2通過Document.createElement(“”)可以創建元素對象。
3Node對象中可以設置文本內容 setTextContent()
4通過Node的appendChild()方法加入子節點。
5需要把記憶體中的DOM樹形結構回寫到xml文件中。
6TransformerFactory工廠類創建Transformer回寫類,通過transform(Souuce,Result)方法回寫xml。
7New DOMSource(document) 和 new StreamResult(xml) 回寫完成。
8遞歸方法就是自己調用自己
public static void getNodeName(Node node){
if(node.getNodeType() == Node.ELEMENT_NODE){
System.out.println(node.getNodeName());
}
NodeList nodeList = node.getChildNodes();
for(int i=0;i<nodeList.getLength();i++){
Node child = nodeList.item(i);
getNodeName(child);
}
}
更新XML文檔
javax.xml.transform包中的Transformer類用於把代表XML文件的Document對象轉換為某種格式後進行輸出,例如把xml文件應用樣式表後轉成一個html文檔。利用這個對象,當然也可以把Document對象又重新寫入到一個XML文件中。
Transformer類通過transform方法完成轉換操作,該方法接收一個源和一個目的地。我們可以通過:
javax.xml.transform.dom.DOMSource類來關聯要轉換的document對象
用javax.xml.transform.stream.StreamResult 對象來表示數據的目的地。
Transformer對象通過TransformerFactory獲得。
SAX解析:
SAX解析的優點:
在使用 DOM 解析 XML 文檔時,需要讀取整個 XML 文檔,在記憶體中構架代表整個 DOM 樹的Doucment對象,從而再對XML文檔進行操作。此種情況下,如果 XML 文檔特別大,就會消耗電腦的大量記憶體,並且容易導致記憶體溢出。
SAX解析允許在讀取文檔的時候,即對文檔進行處理,而不必等到整個文檔裝載完才會文檔進行操作
解析器和事件處理器:
SAX採用事件處理的方式解析XML文件,利用 SAX 解析 XML 文檔,涉及兩個部分:解析器 和事件處理器:
解析器可以使用JAXP的API創建,創建出SAX解析器後,就可以指定解析器去解析某個XML文檔。
解析器採用SAX方式在解析某個XML文檔時,它只要解析到XML文檔的一個組成部分,都會去調用事件處理器的一個方法,解析器在調用事件處理器的方法時,會把當前解析到的xml文件內容作為方法的參數傳遞給事件處理器。
事件處理器由程式員編寫,程式員通過事件處理器中方法的參數,就可以很輕鬆地得到sax解析器解析到的數據,從而可以決定如何對數據進行處理。
SAX解析原理:
SAX 是事件驅動的 XML 處理方法
它是基於事件驅動的
startElement() 回調在每次 SAX 解析器遇到元素的起始標記時被調用
characters() 回調為字元數據所調用
endElement() 為元素的結束標記所調用
DefaultHandler類(在 org.xml.sax.helpers 軟體包中)來實現所有這些回調,並提供所有回調方法預設的空實現
SAX的事件驅動模型:
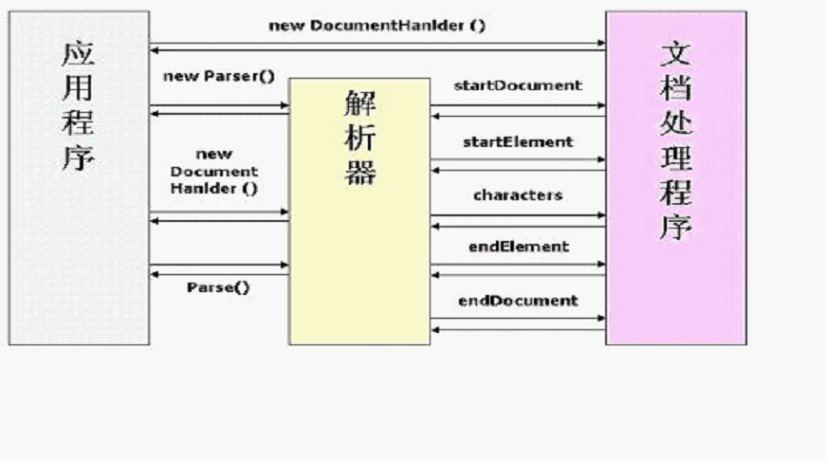
SAX DocumentHandler示例
SAX 解析器採用了基於事件的模型,它在解析XML文檔的時候可以觸發一系列的事件
發生相應事件時,將調用一個回調方法
<?xml version=“1.0” encoding=“utf-8”?> <config> <server>UNIX</server> </config>
Start document
Start element (config)
Characters (whitespace)
Start element (server)
Characters (UNIX)
End element (server)
Characters (whitespace)
End element (config)
End document
使用SAX方式解析XML:
使用SAXParserFactory創建SAX解析工廠
SAXParserFactory spf = SAXParserFactory.newInstance();
通過SAX解析工廠得到解析器對象
SAXParser sp = spf.newSAXParser();
通過解析器對象解析xml文件 xmlReader.parse("book.xml“,new XMLContentHandler());
這裡的XMLContentHandler 繼承 DefaultHandler
SAX 代碼例子
public class XMLContentHandler extends DefaultHandler{ //當前元素中的數據 private String currentData; //取得元素數據 public void characters(char[] ch, int start, int length) throws SAXException { currentData=new String(ch,start,length); } //在解析整個文檔結束時調用 public void endDocument() throws SAXException { System.out.println("結束文檔"); } //在解析元素結束時調用 public void endElement(String uri, String localName, String name) throws SAXException { System.out.println("節點數據 *************************"+this.currentData); System.out.println("結束元素 ************"+name); } //在解析整個文檔開始時調用 public void startDocument() throws SAXException { System.out.println("開始文檔"); } //在解析元素開始時調用 public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { System.out.println("開始元素 ************"+name); } }
DOM解析和SAX解析總結:
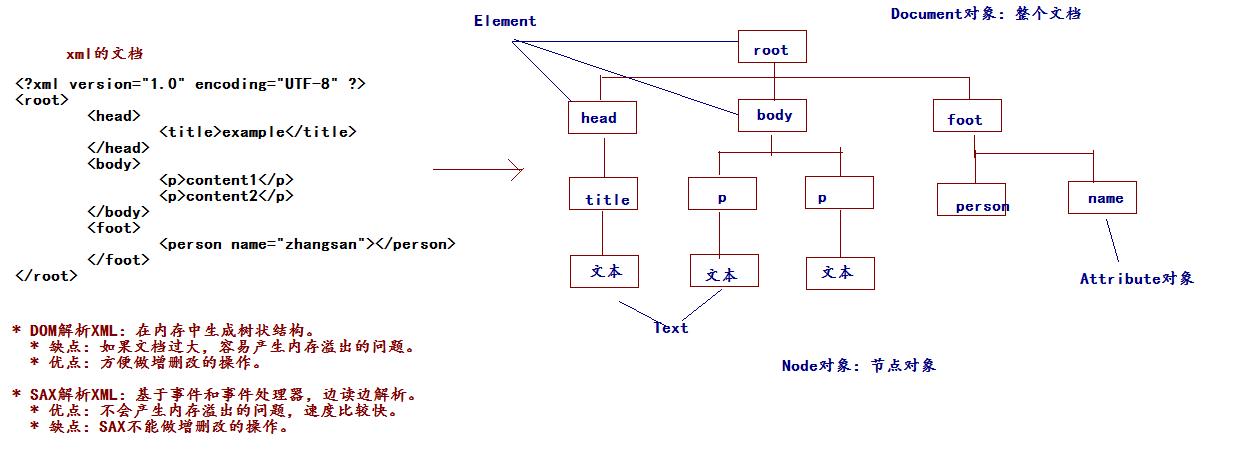
通過dom.xml的文件畫圖解析DOM和SAX的關係
首先DOM解析XML也是在記憶體中形成一個樹狀結構。
DOM解析:把整個XML文檔先載入到記憶體中,形成樹狀結構。
缺點:如果文檔非常大,載入到記憶體中容易產生記憶體溢出的問題。
優點:因為節點與節點之間有關係,進行增刪改非常方便。
SAX解析:基於事件驅動的,邊讀邊解析。
缺點:不能進行增刪改的操作。
優點:文檔大也不會有記憶體溢出的問題,查找非常方便。
DOM4J解析XML文檔:
Dom4j是一個簡單、靈活的開放源代碼的庫。Dom4j是由早期開發JDOM的人分離出來而後獨立開發的。與JDOM不同的是,dom4j使用介面和抽象基類,雖然Dom4j的API相對要複雜一些,但它提供了比JDOM更好的靈活性。
Dom4j是一個非常優秀的Java XML API,具有性能優異、功能強大和極易使用的特點。現在很多軟體採用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j開發,需下載dom4j相應的jar文件。
Document對象
DOM4j中,獲得Document對象的方式有三種:
1.讀取XML文件,獲得document對象
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document對象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主動創建document對象.
Document document = DocumentHelper.createDocument();
//創建根節點
Element root = document.addElement("members");
節點對象
1.獲取文檔的根節點.
Element root = document.getRootElement();
2.取得某個節點的子節點.
Element element=node.element(“書名");
3.取得節點的文字
String text=node.getText();
4.取得某節點下所有名為“member”的子節點,併進行遍歷.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something }
5.對某節點下的所有子節點進行遍歷.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something }
6.在某節點下添加子節點.
Element ageElm = newMemberElm.addElement("age");
7.設置節點文字.
element.setText("29");
8.刪除某節點.
//childElm是待刪除的節點,parentElm是其父節點
parentElm.remove(childElm);
9.添加一個CDATA節點.
Element contentElm = infoElm.addElement("content");
contentElm.addCDATA(diary.getContent());
節點對象屬性
1.取得某節點下的某屬性
Element root=document.getRootElement();
//屬性名name Attribute attribute=root.attribute("size");
2.取得屬性的文字
String text=attribute.getText();
3.刪除某屬性
Attribute attribute=root.attribute("size");
root.remove(attribute);
4.遍歷某節點的所有屬性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text); }
5.設置某節點的屬性和文字.
newMemberElm.addAttribute("name", "sitinspring");
6.設置屬性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
將文檔寫入XML文件
1.文檔中全為英文,不設置編碼,直接寫入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文檔中含有中文,設置編碼格式寫入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定XML編碼
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
writer.write(document);
writer.close();
Dom4j在指定位置插入節點
1.得到插入位置的節點列表(list)
2.調用list.add(index,elemnent),由index決定element的插入位置。
Element元素可以通過DocumentHelper對象得到。示例代碼:
Element aaa = DocumentHelper.createElement("aaa");
aaa.setText("aaa");
List list = root.element("書").elements();
list.add(1, aaa);
//更新document
字元串與XML的轉換
1.將字元串轉化為XML
String text = "<members> <member>sitinspring</member></members>";
Document document = DocumentHelper.parseText(text);
2.將文檔或節點的XML轉化為字元串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();


