
PostgreSQL的流複製,從整體上看,可以粗分為同步與非同步兩種模式,其中涉及的主要參數包括synchronous_commit和synchronous_standby_names 主節點synchronous_commit參數設置 synchronous_commit事務提交模式,類似於MySQ ...
PostgreSQL的流複製,從整體上看,可以粗分為同步與非同步兩種模式,其中涉及的主要參數包括synchronous_commit和synchronous_standby_names
主節點synchronous_commit參數設置
synchronous_commit
事務提交模式,類似於MySQL的innodb_flush_log_at_trx_commit參數,對應著事務提交後返回給客戶端提交成功的時機,可以是off, local, remote_write, remote_apply, or on
不同的值意味著可以在不同的時機反饋事務提交成功的標記,也對應著不同的安全級別,同時影響著事務提交等待的時間。
特定的實用命令,如DROP TABLE,被強制按照同步提交而不考慮synchronous_commit的設定。這是為了確保伺服器文件系統和資料庫邏輯狀態之間的一致性。支持兩階段提交的命令頁總是同步提交的,如PREPARE TRANSACTION。
##單實例模式
1. synchronous_commit=off
設置成off表示提交事務時不需等待相應WAL數據寫入本地WAL日誌文件即可向客戶端返回成功。當資料庫宕機時最新提交的少量事務可能丟失,但資料庫重啟後會認為這些事務異常中止。
設置成off能夠提升資料庫性能,因此對於數據準確性沒有精確要求同時追求資料庫性能的場景建議設置成off。
2. synchronous_commit=on / local
單實例下設置成 on或local均表示提交事務時需等待相應WAL數據寫入本地WAL日誌文件後才向客戶端返回成功。設置成on理論上事務是絕對安全的,但相對與off需要略微多一點額外的耗時。
##複製模式
1. synchronous_commit=off
含義同上,表示提交事務時不需等待本地相應WAL數據寫入本地WAL日誌文件即可向客戶端返回成功。
2. synchronous_commit=local
含義同上,表示提交事務時需等待相應WAL數據寫入本地WAL日誌文件後才向客戶端返回成功,但是不會關心從節點的情況。
3. synchronous_commit=remote_write
如果沒有設置synchronous_standby_names,remote_write跟單實例下synchronous_commit=local含義相同如果設置了設置了synchronous_standby_names:
當流複製主庫提交事務時,需等待備庫接收主庫發送的WAL日誌流並寫入備節點操作系統緩存中,才向客戶端返回成功,此時備庫的WAL還在備庫操作系統緩存中,。
筆者認為這種提交模式在數據安全的情況下,實際上已經足夠了。
除非一個事物提交之後,在standby節點WAL日誌固化之前的wal_writer_delay(預設200毫秒)這個間隔內,同時發生這兩個事件:1,主節點磁碟故障導致數據損壞;2 ,standby節點操作系統發生宕機。才有可能造成數據丟失,其實概率已經非常非常低了
4. synchronous_commit=on
如果未設置synchronous_standby_names,on跟單實例下含義相同
如果設置了synchronous_standby_names,on跟單實例下含義不同,此時表示流複製主庫提交事務時,需等待備庫接收主庫發送的WAL日誌流並寫入WAL文件,也即主備的WAL日誌同時落盤之後,之後才向客戶端返回成功。
5. synchronous_commit=remote_apply|
如果未設置synchronous_standby_names,remote_apply等同於on,跟單實例下含義相同。
表示流複製主庫提交事務時 ,需等待備庫完成相應的WAL日誌的apply才向客戶端返回成功。
也就是說從數據需要接收主節點WAL日誌,並且完成了WAL的“翻譯”工作,主備數據完全一致的情況下才返回事務提交成功的標記
與synchronous_commit相關的其他參數:
wal_writer_delay
非同步提交時,也即synchronous_commit=off時,經過wal_writer_delay(預設200毫秒)之後會自動將wal日誌持久化
fsync
如果該參數開啟,PostgreSQL伺服器將通過發出fsync()系統調用或各種等效方法(參見wal_sync_method)來確保更新被物理地寫入磁碟。這確保了在操作系統或硬體崩潰後,資料庫集群可以恢復到一致狀態。
雖然關閉fsync通常可以提高性能,但在電源故障或系統崩潰的情況下,這可能會導致無法恢復的數據損壞。因此,只有當您可以輕鬆地從外部數據重新創建整個資料庫時,才建議關閉fsync。
commit_delay
類似於MySQL的group commit原理,設置commit_delay會在執行WAL刷新之前添加時間延遲。 如果系統負載足夠高,使得在給定時間間隔內有更多事務準備提交,這可以通過允許更多事務通過單個WAL刷新來提高組提交吞吐量。
然而,這也會增加延遲,最多為每個WAL刷新的commit_delay。 因為如果沒有其他事務準備提交,延遲就是浪費的,所以只有在至少有 commit_siblings其他事務活動時才會執行延遲, 當要啟動刷新時,如果fsync被禁用,則不會執行延遲。
如果未指定單位,則將其視為微秒。 預設commit_delay為零(無延遲)。 只有超級用戶和具有適當SET許可權的用戶才能更改此設置。
從節點的standby_names設置
在synchronous_standby_names指定的備用節點的名稱,備用伺服器可以通過查詢pg_stat_replication視圖中的application_name欄位來得到。
如果未明確設置application_name,則將使用備用伺服器的cluster_name(在PostgreSQL 12及更高版本中),但是預設情況下postgresql.auto.conf是不包含application_name,cluster_name也是空的,所以這個application_name只能是預設字元串walreceiver,而walreceiver是不具備實際意義的。
1,在從節點postgresql.auto.conf添加application_name信息
在搭建流複製的過程中,使用pg_basebackup會備份主庫的之後,備份文件中會自動生成一個postgresql.auto.conf的文件,這個文件中包含了primary_conninfo和primary_slot_name。
預設是不包含application_name信息的,所以流複製啟動之後,主節點上看到的是一個walreceiver的通用的名字
primary_conninfo = 'user=replica_user password=123456 channel_binding=disable host=1.1.1.1 port=1234 sslmode=disable sslcompression=0 sslcertmode=disable sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres gssdelegation=0 target_session_attrs=any load_balance_hosts=disable'
primary_slot_name = 'pgstandby_slave01'
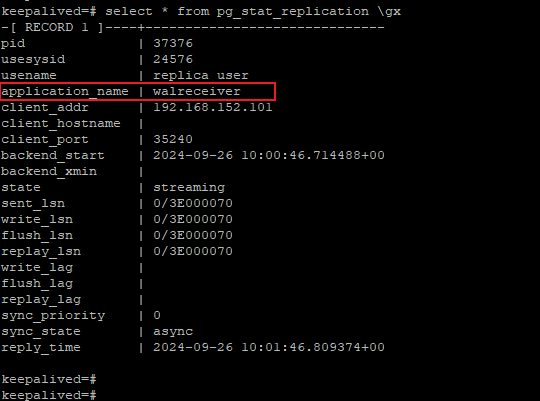
以上是postgresql 16版本的pg_basebackup生成的備份文件中的postgresql.auto.conf,預設情況下primary_conninfo中是不包含application_name的
可以通過再primary_conninfo連接串中增加一個application_name=ubuntu02來標識(當前)從節點的standby_name,比如如下
primary_conninfo = 'application_name=ubuntu02 user=replica_user password=123456 channel_binding=disable host=1.1.1.1 port=1234 sslmode=disable sslcompression=0 sslcertmode=disable sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres gssdelegation=0 target_session_attrs=any load_balance_hosts=disable'
primary_slot_name = 'pgstandby_slave01'
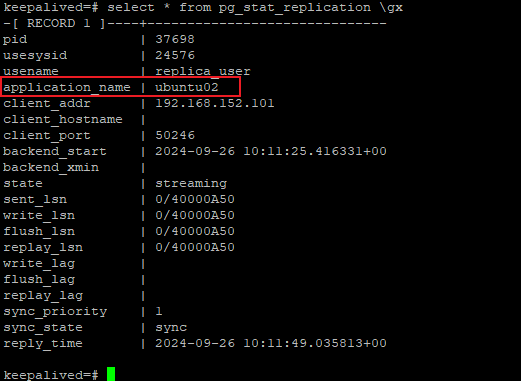
2,設置cluster_name參數
除了上述在postgresql.auto.conf配置文件中添加application_name屬性信息之外,也可以從節點上設置postgresql.conf中的cluster_name參數
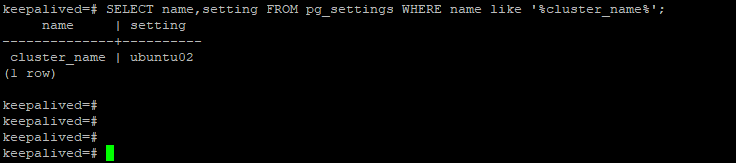
在使用pg_basebackup預設生成的備份文件中,無須在postgresql.auto.conf添加application_name信息,主節點也能識別到從節點的application_name為這裡配置的cluster_name。
synchronous_standby_names設置
該參數指定流複製中需要同步複製的伺服器列表,需要配置standby伺服器的名字,也即主從運行正常情況下,主節點上的pg_stat_replication系統表中的application_name信息,至於什麼是standby伺服器名字,以及如何設置standby伺服器名字,上面也做了闡述,幾種典型的synchronous_standby_names設置方式:
1,設置WAL日誌強同步至某個節點
設置當前節點與ubuntu02節點wal日誌寫入成功後,返回客戶端提交成功
synchronous_standby_names = 'ubuntu02'
2,設置WAL日誌強同步至N個節點中的某M個節點
按照指定節點的順序,WAL至少強同步至兩個節點
synchronous_standby_names = 'FIRST 2 (ubuntu02,ubuntu03,ubuntu04)'
按照指定節點,無順序要求,WAL至少強同步至兩個節點
synchronous_standby_names = 'ANY 2 (ubuntu02,ubuntu03,ubuntu04))'
如果當前節點在事務提交的時候,synchronous_standby_names中的節點未達到當前節點synchronous_commit設定的要求,則當前事務會被掛起,直至滿足synchronous_standby_names中設定的要求
其他修改synchronous_commit提交模式的方式:
單個事務,事務級別: SET LOCAL synchronous_commit = ''
Session級別: SET synchronous_commit = ''
User級別: ALTER USER someuser SET synchronous_commit = ''
Database級別: ALTER DATABASE SET synchronous_commit = ''
實例級別: 修改postgreql.conf的synchronous_commit = ''
參考:
https://www.crunchydata.com/blog/synchronous-replication-in-postgresql
https://pgpedia.info/s/synchronous_standby_names.html


