
本文內容來自YashanDB官網,具體內容請見(https://www.yashandb.com/newsinfo/7488286.html?templateId=1718516) 測試驗證環境說明 測試用例說明 1、相同版本下,新增表數據量,使統計信息失效。優化器優先使用outline的計劃。 2 ...
第二十七講: 讀寫分離有哪些坑?
簡概
朴素的開篇
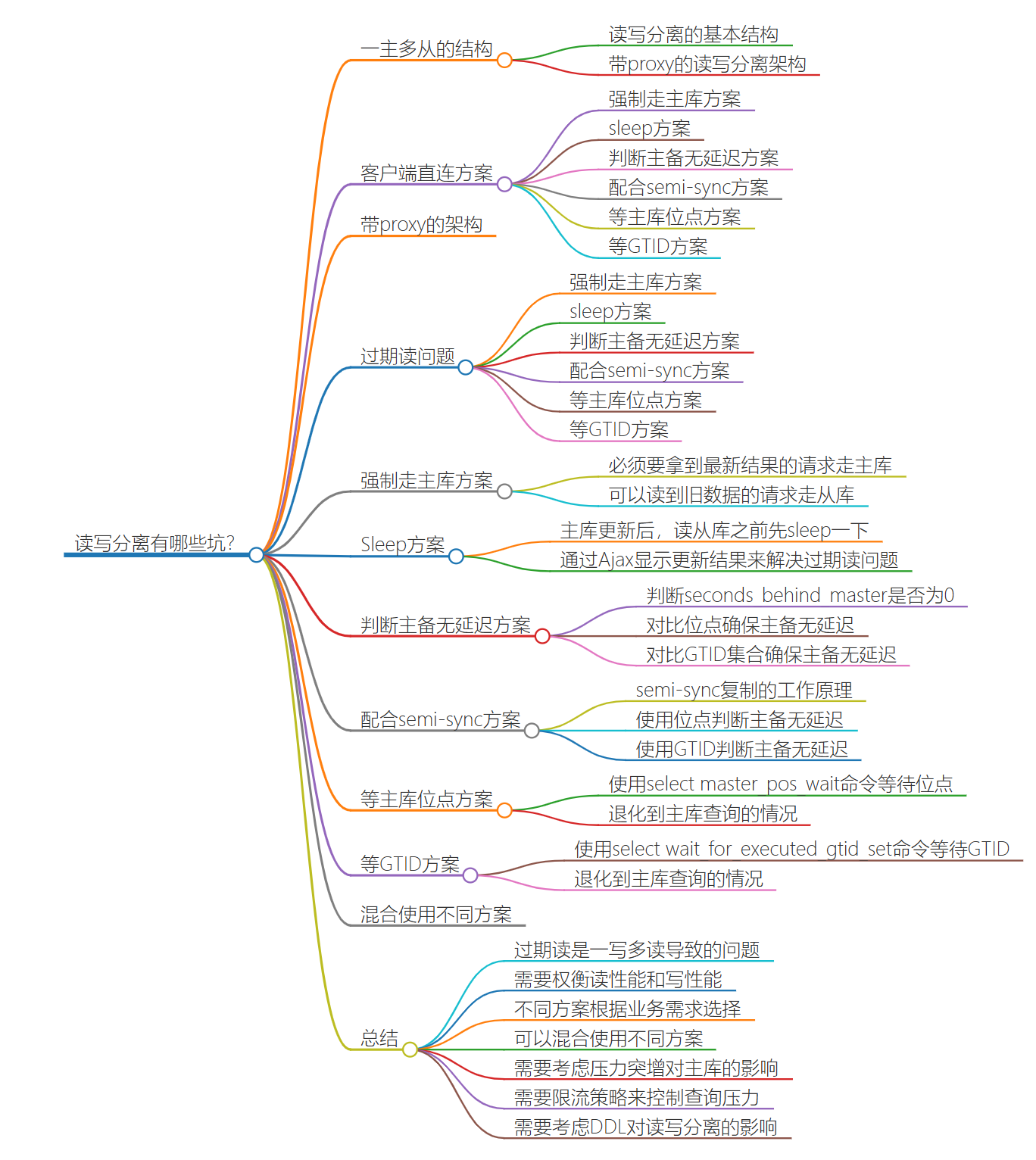
在上一篇文章中,我和你介紹了一主多從的結構以及切換流程。今天我們就繼續聊聊一主多從架構的應用場景:讀寫分離,以及怎麼處理主備延遲導致的讀寫分離問題。我們在上一篇文章中提到的一主多從的結構,其實就是讀寫分離的基本結構了。這裡,我再把這張圖貼過來,方便你理解。
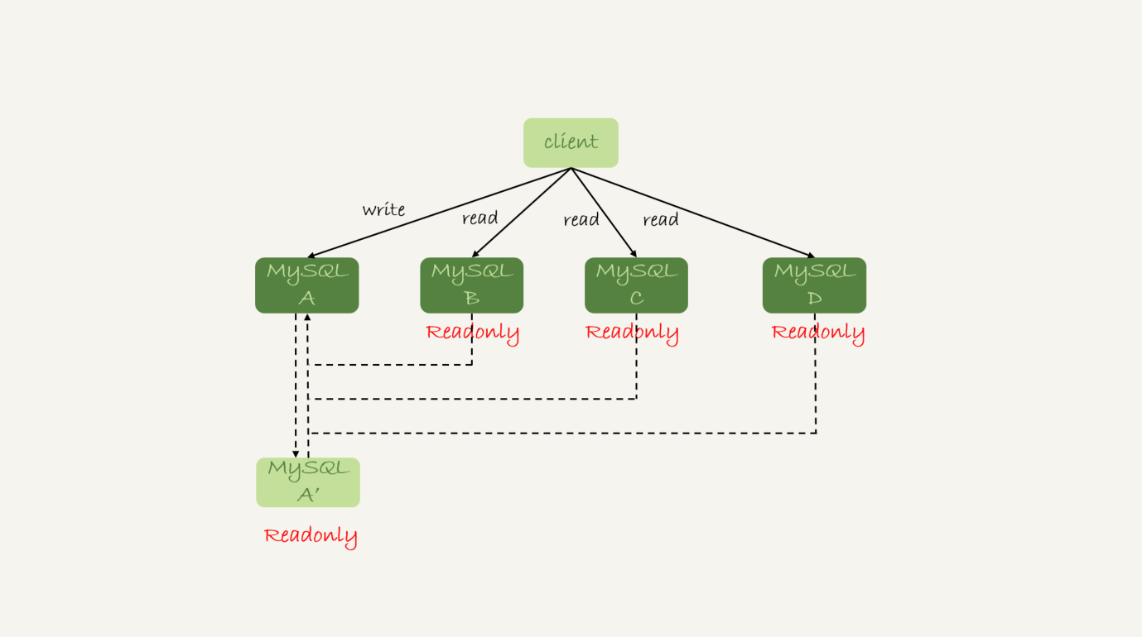
圖 1 讀寫分離基本結構
讀寫分離的主要目標就是分攤主庫的壓力。圖 1 中的結構是客戶端(client)主動做負載均衡,這種模式下一般會把資料庫的連接信息放在客戶端的連接層。也就是說,由客戶端來選擇後端資料庫進行查詢。
還有一種架構是,在 MySQL 和客戶端之間有一個中間代理層 proxy,客戶端只連接 proxy, 由 proxy 根據請求類型和上下文決定請求的分發路由。
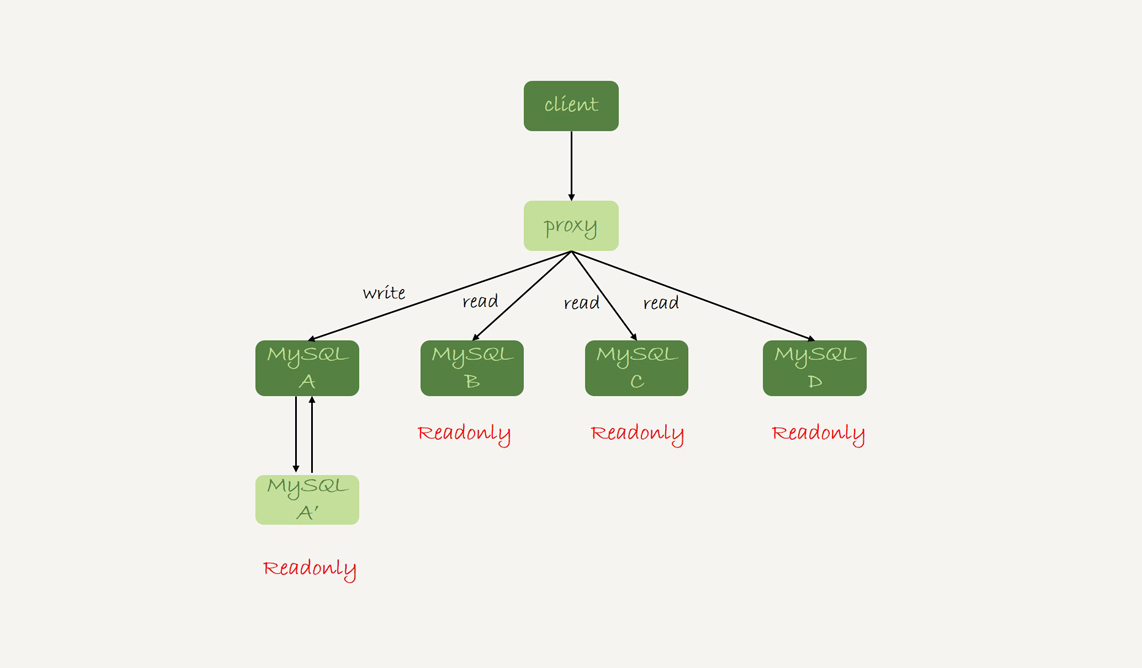
圖 2 帶 proxy 的讀寫分離架構
接下來,我們就看一下客戶端直連和帶 proxy 的讀寫分離架構,各有哪些特點。
客戶端直連方案,因為少了一層 proxy 轉發,所以查詢性能稍微好一點兒,並且整體架構簡單,排查問題更方便。但是這種方案,由於要瞭解後端部署細節,所以在出現主備切換、庫遷移等操作的時候,客戶端都會感知到,並且需要調整資料庫連接信息。你可能會覺得這樣客戶端也太麻煩了,信息大量冗餘,架構很醜。其實也未必,一般採用這樣的架構,一定會伴隨一個負責管理後端的組件,比如 Zookeeper,儘量讓業務端只專註於業務邏輯開發。
帶 proxy 的架構,對客戶端比較友好。客戶端不需要關註後端細節,連接維護、後端信息維護等工作,都是由 proxy 完成的。但這樣的話,對後端維護團隊的要求會更高。而且,proxy 也需要有高可用架構。因此,帶 proxy 架構的整體就相對比較複雜。
理解了這兩種方案的優劣,具體選擇哪個方案就取決於資料庫團隊提供的能力了。
但目前看,趨勢是往帶 proxy 的架構方向發展的。但是,不論使用哪種架構,你都會碰到我們今天要討論的問題:由於主從可能存在延遲,客戶端執行完一個更新事務後馬上發起查詢,如果查詢選擇的是從庫的話,就有可能讀到剛剛的事務更新之前的狀態。這種“在從庫上會讀到系統的一個過期狀態”的現象,
在這篇文章里,我們暫且稱之為“過期讀”。前面我們說過了幾種可能導致主備延遲的原因,以及對應的優化策略,但是主從延遲還是不能 100% 避免的。不論哪種結構,客戶端都希望查詢從庫的數據結果,跟查主庫的數據結果是一樣的。
接下來,我們就來討論怎麼處理過期讀問題。這裡,我先把文章中涉及到的處理過期讀的方案彙總在這裡,以幫助你更好地理解和掌握全文的知識脈絡。這些方案包括:強制走主庫方案;sleep 方案;判斷主備無延遲方案;配合 semi-sync 方案;等主庫位點方案;等 GTID 方案。
強制走主庫方案
強制走主庫方案其實就是,將查詢請求做分類。通常情況下,我們可以將查詢請求分為這麼兩類:
- 對於必須要拿到最新結果的請求,強制將其發到主庫上。比如,在一個交易平臺上,賣家發佈商品以後,馬上要返回主頁面,看商品是否發佈成功。那麼,這個請求需要拿到最新的結果,就必須走主庫。
- 對於可以讀到舊數據的請求,才將其發到從庫上。在這個交易平臺上,買家來逛商鋪頁面,就算晚幾秒看到最新發佈的商品,也是可以接受的。那麼,這類請求就可以走從庫。
你可能會說,這個方案是不是有點畏難和取巧的意思,但其實這個方案是用得最多的。
當然,這個方案最大的問題在於,有時候你會碰到“所有查詢都不能是過期讀”的需求,比如一些金融類的業務。這樣的話,你就要放棄讀寫分離,所有讀寫壓力都在主庫,等同於放棄了擴展性。
因此接下來,我們來討論的話題是:可以支持讀寫分離的場景下,有哪些解決過期讀的方案,並分析各個方案的優缺點。
Sleep 方案
主庫更新後,讀從庫之前先 sleep 一下。具體的方案就是,類似於執行一條 select sleep(1) 命令。這個方案的假設是,大多數情況下主備延遲在 1 秒之內,做一個 sleep 可以有很大概率拿到最新的數據。這個方案給你的第一感覺,很可能是不靠譜兒,應該不會有人用吧?並且,你還可能會說,直接在發起查詢時先執行一條 sleep 語句,用戶體驗很不友好啊。但,這個思路確實可以在一定程度上解決問題。
為了看起來更靠譜兒,我們可以換一種方式。以賣家發佈商品為例,商品發佈後,用 Ajax(Asynchronous JavaScript + XML,非同步 JavaScript 和 XML)直接把客戶端輸入的內容作為“新的商品”顯示在頁面上,而不是真正地去資料庫做查詢。這樣,賣家就可以通過這個顯示,來確認產品已經發佈成功了。等到賣家再刷新頁面,去查看商品的時候,其實已經過了一段時間,也就達到了 sleep 的目的,進而也就解決了過期讀的問題。
你可真是個大聰明
也就是說,這個 sleep 方案確實解決了類似場景下的過期讀問題。但,從嚴格意義上來說,這個方案存在的問題就是不精確。這個不精確包含了兩層意思:
- 如果這個查詢請求本來 0.5 秒就可以在從庫上拿到正確結果,也會等 1 秒;
- 如果延遲超過 1 秒,還是會出現過期讀。
看到這裡,你是不是有一種“你是不是在逗我”的感覺,這個改進方案雖然可以解決類似 Ajax 場景下的過期讀問題,但還是怎麼看都不靠譜兒。
彆著急,接下來我就和你介紹一些更準確的方案。判斷主備無延遲方案要確保備庫無延遲,通常有三種做法。通過前面的第 25 篇文章,我們知道 show slave status 結果里的 seconds_behind_master 參數的值,可以用來衡量主備延遲時間的長短。
所以第一種確保主備無延遲的方法是,每次從庫執行查詢請求前,先判斷 seconds_behind_master 是否已經等於 0。如果還不等於 0 ,那就必須等到這個參數變為 0 才能執行查詢請求。seconds_behind_master 的單位是秒,如果你覺得精度不夠的話,還可以採用對比位點和 GTID 的方法來確保主備無延遲,也就是我們接下來要說的第二和第三種方法。
如圖 3 所示,是一個 show slave status 結果的部分截圖。

圖 3 show slave status 結果
現在,我們就通過這個結果,來看看具體如何通過對比位點和 GTID 來確保主備無延遲。
第二種方法,對比位點確保主備無延遲:Master_Log_File 和 Read_Master_Log_Pos,表示的是讀到的主庫的最新位點;Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是備庫執行的最新位點。
如果 Master_Log_File 和 Relay_Master_Log_File、Read_Master_Log_Pos 和 Exec_Master_Log_Pos 這兩組值完全相同,就表示接收到的日誌已經同步完成。
第三種方法,對比 GTID 集合確保主備無延遲:Auto_Position=1 ,表示這對主備關係使用了 GTID 協議。Retrieved_Gtid_Set,是備庫收到的所有日誌的 GTID 集合;Executed_Gtid_Set,是備庫所有已經執行完成的 GTID 集合。如果這兩個集合相同,也表示備庫接收到的日誌都已經同步完成。
可見,對比位點和對比 GTID 這兩種方法,都要比判斷 seconds_behind_master 是否為 0 更準確。在執行查詢請求之前,先判斷從庫是否同步完成的方法,相比於 sleep 方案,準確度確實提升了不少,但還是沒有達到“精確”的程度。
為什麼這麼說呢?我們現在一起來回顧下,一個事務的 binlog 在主備庫之間的狀態:
- 主庫執行完成,寫入 binlog,並反饋給客戶端;
- binlog 被從主庫發送給備庫,備庫收到;
- 在備庫執行 binlog 完成。
我們上面判斷主備無延遲的邏輯,是“備庫收到的日誌都執行完成了”。
但是,從 binlog 在主備之間狀態的分析中,不難看出還有一部分日誌,處於客戶端已經收到提交確認,而備庫還沒收到日誌的狀態。
如圖 4 所示就是這樣的一個狀態。

圖 4 備庫還沒收到 trx3
- 這時,主庫上執行完成了三個事務 trx1、trx2 和 trx3,其中:trx1 和 trx2 已經傳到從庫,並且已經執行完成了;
- trx3 在主庫執行完成,並且已經回覆給客戶端,但是還沒有傳到從庫中。
如果這時候你在從庫 B 上執行查詢請求,按照我們上面的邏輯,從庫認為已經沒有同步延遲,但還是查不到 trx3 的。嚴格地說,就是出現了過期讀。
那麼,這個問題有沒有辦法解決呢?
配合 semi-sync
要解決這個問題,就要引入半同步複製,也就是 semi-sync replication。semi-sync 做了這樣的設計:事務提交的時候,主庫把 binlog 發給從庫;從庫收到 binlog 以後,發回給主庫一個 ack,表示收到了;主庫收到這個 ack 以後,才能給客戶端返回“事務完成”的確認。
也就是說,如果啟用了 semi-sync,就表示所有給客戶端發送過確認的事務,都確保了備庫已經收到了這個日誌。
在第 25 篇文章的評論區,有同學問到:如果主庫掉電的時候,有些 binlog 還來不及發給從庫,會不會導致系統數據丟失?
答案是,如果使用的是普通的非同步複製模式,就可能會丟失,但 semi-sync 就可以解決這個問題。
這樣,semi-sync 配合前面關於位點的判斷,就能夠確定在從庫上執行的查詢請求,可以避免過期讀。但是,semi-sync+ 位點判斷的方案,只對一主一備的場景是成立的。在一主多從場景中,主庫只要等到一個從庫的 ack,就開始給客戶端返回確認。
這時,在從庫上執行查詢請求,就有兩種情況:
- 如果查詢是落在這個響應了 ack 的從庫上,是能夠確保讀到最新數據;
- 但如果是查詢落到其他從庫上,它們可能還沒有收到最新的日誌,就會產生過期讀的問題。
其實,判斷同步位點的方案還有另外一個潛在的問題,即:如果在業務更新的高峰期,主庫的位點或者 GTID 集合更新很快,那麼上面的兩個位點等值判斷就會一直不成立,很可能出現從庫上遲遲無法響應查詢請求的情況。
實際上,回到我們最初的業務邏輯里,當發起一個查詢請求以後,我們要得到準確的結果,其實並不需要等到“主備完全同步”。為什麼這麼說呢?我們來看一下這個時序圖。

圖 5 主備持續延遲一個事務
圖 5 所示,就是等待位點方案的一個 bad case。
圖中備庫 B 下的虛線框,分別表示 relaylog 和 binlog 中的事務。可以看到,圖 5 中從狀態 1 到狀態 4,一直處於延遲一個事務的狀態。備庫 B 一直到狀態 4 都和主庫 A 存在延遲,如果用上面必須等到無延遲才能查詢的方案,select 語句直到狀態 4 都不能被執行。但是,其實客戶端是在發完 trx1 更新後發起的 select 語句,我們只需要確保 trx1 已經執行完成就可以執行 select 語句了。也就是說,如果在狀態 3 執行查詢請求,得到的就是預期結果了。
到這裡,我們小結一下,semi-sync 配合判斷主備無延遲的方案,存在兩個問題:
- 一主多從的時候,在某些從庫執行查詢請求會存在過期讀的現象;
- 在持續延遲的情況下,可能出現過度等待的問題。
接下來,我要和你介紹的等主庫位點方案,就可以解決這兩個問題。等主庫位點方案要理解等主庫位點方案,我需要先和你介紹一條命令:
select master_pos_wait(file, pos[, timeout]);
這條命令的邏輯如下:
- 它是在從庫執行的;
- 參數 file 和 pos 指的是主庫上的文件名和位置;
- timeout 可選,設置為正整數 N 表示這個函數最多等待 N 秒。
這個命令正常返回的結果是一個正整數 M,表示從命令開始執行,到應用完 file 和 pos 表示的 binlog 位置,執行了多少事務。
當然,除了正常返回一個正整數 M 外,這條命令還會返回一些其他結果,包括:
- 如果執行期間,備庫同步線程發生異常,則返回 NULL;
- 如果等待超過 N 秒,就返回 -1;
- 如果剛開始執行的時候,就發現已經執行過這個位置了,則返回 0。
對於圖 5 中先執行 trx1,再執行一個查詢請求的邏輯,要保證能夠查到正確的數據,我們可以使用這個邏輯:
- trx1 事務更新完成後,馬上執行 show master status 得到當前主庫執行到的 File 和 Position;
- 選定一個從庫執行查詢語句;
- 在從庫上執行 select master_pos_wait(File, Position, 1);如果返回值是 >=0 的正整數,則在這個從庫執行查詢語句;否則,到主庫執行查詢語句。
我把上面這個流程畫出來。

圖 6 master_pos_wait 方案
這裡我們假設,這條 select 查詢最多在從庫上等待 1 秒。那麼,如果 1 秒內 master_pos_wait 返回一個大於等於 0 的整數,就確保了從庫上執行的這個查詢結果一定包含了 trx1 的數據。步驟 5 到主庫執行查詢語句,是這類方案常用的退化機制。
因為從庫的延遲時間不可控,不能無限等待,所以如果等待超時,就應該放棄,然後到主庫去查。你可能會說,如果所有的從庫都延遲超過 1 秒了,那查詢壓力不就都跑到主庫上了嗎?確實是這樣。
但是,按照我們設定不允許過期讀的要求,就只有兩種選擇,一種是超時放棄,一種是轉到主庫查詢。具體怎麼選擇,就需要業務開發同學做好限流策略了。
GTID 方案
如果你的資料庫開啟了 GTID 模式,對應的也有等待 GTID 的方案。MySQL 中同樣提供了一個類似的命令:
select wait_for_executed_gtid_set(gtid_set, 1);
這條命令的邏輯是:
- 等待,直到這個庫執行的事務中包含傳入的 gtid_set,返回 0;
- 超時返回 1。
在前面等位點的方案中,我們執行完事務後,還要主動去主庫執行 show master status。而 MySQL 5.7.6 版本開始,允許在執行完更新類事務後,把這個事務的 GTID 返回給客戶端,這樣等 GTID 的方案就可以減少一次查詢。
這時,等 GTID 的執行流程就變成了:
- trx1 事務更新完成後,從返回包直接獲取這個事務的 GTID,記為 gtid1;
- 選定一個從庫執行查詢語句;
- 在從庫上執行 select wait_for_executed_gtid_set(gtid1, 1);
- 如果返回值是 0,則在這個從庫執行查詢語句;
- 否則,到主庫執行查詢語句。
跟等主庫位點的方案一樣,等待超時後是否直接到主庫查詢,需要業務開發同學來做限流考慮。我把這個流程圖畫出來。

圖 7 wait_for_executed_gtid_set 方案
在上面的第一步中,trx1 事務更新完成後,從返回包直接獲取這個事務的 GTID。
問題是,怎麼能夠讓 MySQL 在執行事務後,返回包中帶上 GTID 呢?
你只需要將參數session_track_gtids設置為 OWN_GTID,然後通過 API 介面 mysql_session_track_get_first 從返回包解析出 GTID 的值即可。在專欄的第一篇文章中,我介紹 mysql_reset_connection 的時候,評論區有同學留言問這類介面應該怎麼使用。
這裡我再回答一下。其實,MySQL 並沒有提供這類介面的 SQL 用法,是提供給程式的 API(https://dev.mysql.com/doc/refman/5.7/en/c-api-functions.html)。比如,為了讓客戶端在事務提交後,返回的 GITD 能夠在客戶端顯示出來,我對 MySQL 客戶端代碼做了點修改,如下所示:

圖 8 顯示更新事務的 GTID-- 代碼
這樣,就可以看到語句執行完成,顯示出 GITD 的值。

圖 9 顯示更新事務的 GTID-- 效果
當然了,這隻是一個例子。你要使用這個方案的時候,還是應該在你的客戶端代碼中調用 mysql_session_track_get_first 這個函數。
小結
在今天這篇文章中,我跟你介紹了一主多從做讀寫分離時,可能碰到過期讀的原因,以及幾種應對的方案。這幾種方案中,有的方案看上去是做了妥協,有的方案看上去不那麼靠譜兒,但都是有實際應用場景的,你需要根據業務需求選擇。即使是最後等待位點和等待 GTID 這兩個方案,雖然看上去比較靠譜兒,但仍然存在需要權衡的情況。
如果所有的從庫都延遲,那麼請求就會全部落到主庫上,這時候會不會由於壓力突然增大,把主庫打掛了呢?其實,在實際應用中,這幾個方案是可以混合使用的。
比如,先在客戶端對請求做分類,區分哪些請求可以接受過期讀,而哪些請求完全不能接受過期讀;然後,對於不能接受過期讀的語句,再使用等 GTID 或等位點的方案。
但話說回來,過期讀在本質上是由一寫多讀導致的。在實際應用中,可能會有別的不需要等待就可以水平擴展的資料庫方案,但這往往是用犧牲寫性能換來的,也就是需要在讀性能和寫性能中取權衡。
問答
最後 ,我給你留下一個問題吧。假設你的系統採用了我們文中介紹的最後一個方案,也就是等 GTID 的方案,現在你要對主庫的一張大表做 DDL,可能會出現什麼情況呢?為了避免這種情況,你會怎麼做呢?
答案
假設,這條語句在主庫上要執行 10 分鐘,提交後傳到備庫就要 10 分鐘(典型的大事務)。那麼,在主庫 DDL 之後再提交的事務的 GTID,去備庫查的時候,就會等 10 分鐘才出現。這樣,這個讀寫分離機制在這 10 分鐘之內都會超時,然後走主庫。
這種預期內的操作,應該在業務低峰期的時候,確保主庫能夠支持所有業務查詢,然後把讀請求都切到主庫,再在主庫上做 DDL。等備庫延遲追上以後,再把讀請求切回備庫。通過這個思考題,我主要想讓關註的是,大事務對等位點方案的影響。
當然了,使用 gh-ost 方案來解決這個問題也是不錯的選擇。


