
《數據資產管理核心技術與應用》是清華大學出版社出版的一本圖書,全書共分10章,第1章主要讓讀者認識數據資產,瞭解數據資產相關的基礎概念,以及數據資產的發展情況。第2~8章主要介紹大數據時代數據資產管理所涉及的核心技術,內容包括元數據的採集與存儲、數據血緣、數據質量、數據監控與告警、數據服務、數據許可權 ...
《數據資產管理核心技術與應用》是清華大學出版社出版的一本圖書,全書共分10章,第1章主要讓讀者認識數據資產,瞭解數據資產相關的基礎概念,以及數據資產的發展情況。第2~8章主要介紹大數據時代數據資產管理所涉及的核心技術,內容包括元數據的採集與存儲、數據血緣、數據質量、數據監控與告警、數據服務、數據許可權與安全、數據資產管理架構等。第9~10章主要從實戰的角度介紹數據資產管理技術的應用實踐,包括如何對元數據進行管理以發揮出數據資產的更大潛力,以及如何對數據進行建模以挖掘出數據中更大的價值。
圖書介紹:數據資產管理核心技術與應用
今天主要是給大家分享一下第四章的內容:
第四章的標題為數據質量的技術實現
內容思維導圖如下:
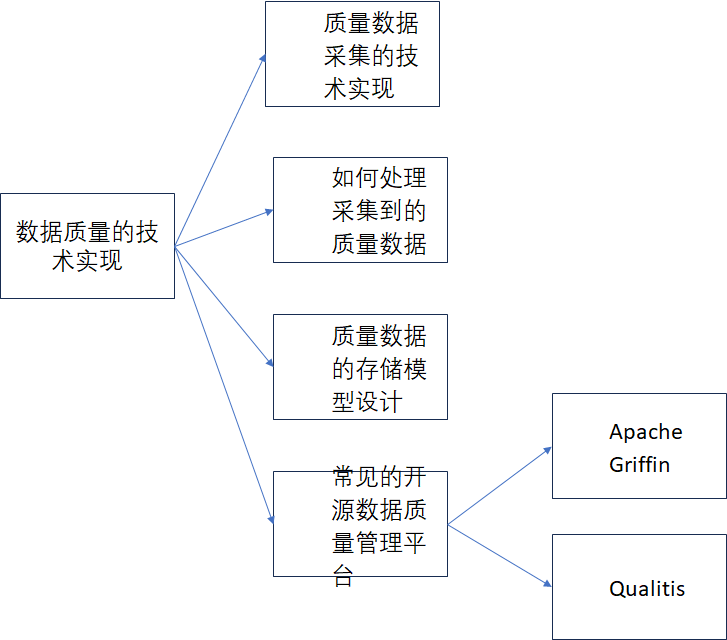
在數據資產管理中,除了元數據和數據血緣外,數據質量也是很重要的一個環節,如下圖所示,數據質量通常是指在數據處理的整個生命周期中,能否始終保持數據的完整性、一致性、準確性、可靠性、及時性等,我們只有知道了數據的質量,才能在數據質量差的時候,能去改進數據。《數據資產管理核心技術與應用》讀書筆記-第四章:數據質量的技術實現
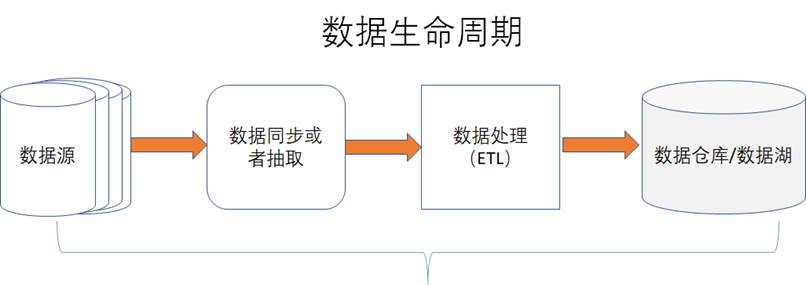
《數據資產管理核心技術與應用》讀書筆記-第四章:數據質量的技術實現
- 完整性:數據是否有丟失,比如數據欄位、數據量是否有丟失。
- 一致性:數據值是否完全一致,比如小數數據的精度是否出現丟失。
- 準確性:數據含義是否準確,比如數據欄位註釋是否準確。
- 可靠性:比如數據存儲是否可靠,是否做了數據災備等。
- 及時性:數據是否出現延遲或者堵塞導致沒有及時入數據倉庫或者數據湖。
正是因為數據質量的重要性,所以在國際上有專門對數據質量進行國際標准定義,比如ISO 8000數據質量系列國際標準中就詳細的描述了數據質量如何衡量以及如何進行認證等,包含了數據質量的特性、特征以及如何進行數據質量的管理、評估等。在ISO 8000中共發佈了21個標準,在網址:https://std.samr.gov.cn/gj/std?op=ISO中可以查詢到ISO 8000質量標準,如下4-0-2所示
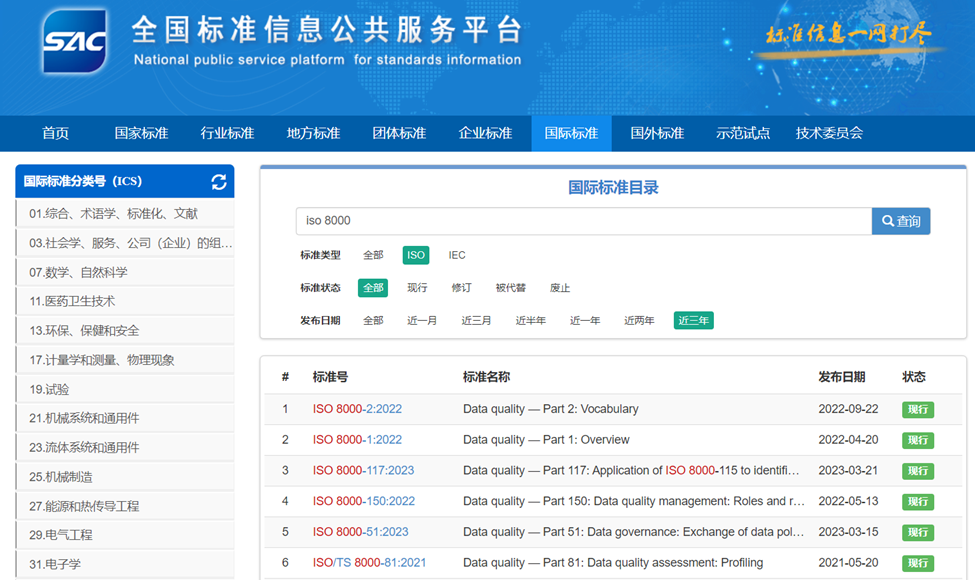
和數據質量相關的主要內容包括如下:
- 1)、ISO 8000-1:2022 Data quality-Part 1: Overview
- 2)、ISO 8000-2:2022 Data quality-Part 2: Vocabulary
- 3)、ISO 8000-8:2015 Data quality-Part 8: Information and data quality: Concepts and measuring
- 4)、ISO/TS 8000-60:2017 Data quality-Part 60:Data quality management: Overview
- 5)、ISO 8000-61:2016 Data quality-Part 61: Data quality management: Process reference model
- 6)、ISO 8000-62:2018 Data quality-Part 62: Data quality management: Organizational process maturity assessment: Application of standards relating to process assessment
- 7)、ISO 8000-63:2019 Data quality-Part 63: Data quality management: Process measurement
- 8)、ISO 8000-64:2022 Data quality-Part 64: Data quality management: Organizational process maturity assessment: Application of the Test Process Improvement method
- 9)、ISO 8000-65:2020 Data quality -Part 65:Data quality management: Process measurement questionnaire
- 10)、ISO 8000-66:2021 Data quality-Part 66: Data quality management: Assessment indicators for data processing in manufacturing operations
- 11)、ISO/TS 8000-81:2021 Data quality-Part 81: Data quality assessment: Profiling
- 12)、ISO/TS8000-82:2022 Data quality-Part 82:Data quality assessment: Creating data rules
- 13)、ISO 8000-100:2016 Data quality-Part 100: Master data: Exchange of characteristic data: Overview
- 14)、ISO 8000-110:2021 Data quality-Part 110: Master data: Exchange of characteristic data: Syntax, semantic encoding, and conformance to data specification
- 15)、ISO 8000-115:2018 Data quality-Part 115: Master data: Exchange of quality identifiers: Syntactic, semantic and resolution requirements
- 16)、ISO 8000-116:2019 Data quality-Part 116: Master data: Exchange of quality identifiers: Application of ISO 8000-115 to authoritative legal entity identifiers
- 17)、ISO 8000-120:2016 Data quality -Part 120: Master data: Exchange of characteristic data: Provenance
- 18)、ISO 8000-130:2016 Data quality-Part 130: Master data: Exchange of characteristic data: Accuracy
- 19)、ISO 8000-140:2016 Data quality- Part 140: Master data: Exchange of characteristic data: Completeness
- 20)、ISO 8000-150:2022 Data quality -Part 150: Data quality management: Roles and responsibilities
- 21)、ISO/TS 8000-311:2012 Data quality-Part 311: Guidance for the application of product data quality for shape (PDQ-S)
1、質量數據採集的技術實現
不管是在數據倉庫還是數據湖中,一開始我們都是不知道數據的質量情況的,需要通過一定的規則定期的到數據湖或者數據倉庫中去採集數據的質量,這個規則是允許用戶自己去進行配置的,通常的流程如下圖所示。
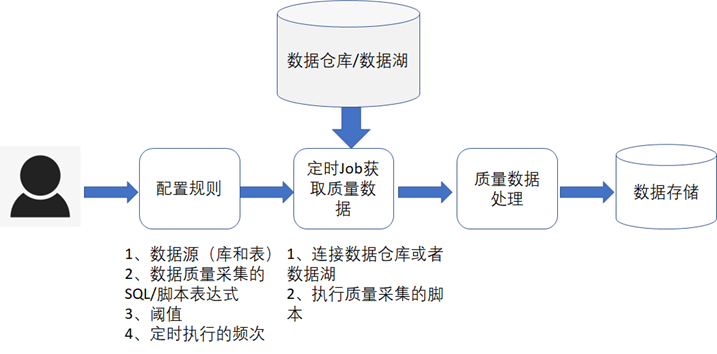
對於一些通用的規則,可以做成規則模板,然後用戶可以直接選擇某個規則進行質量數據採集,常見的通用規則如下表所示。
《數據資產管理核心技術與應用》讀書筆記-第四章:數據質量的技術實現
|
規則 |
描述 |
|
表欄位的空值率 |
採集指定表的指定欄位為空的比率 |
|
表欄位的異常率 |
採集指標表的指定欄位值的異常率,比如性別欄位,只可能為男或者女,對於別的值就是異常值,我們可以根據規則統計出異常值的比率,哪些值是異常值當然也需要支持自定義維護 |
|
表欄位數據格式異常率 |
採集指標表的指定欄位值的數據格式異常率,比如時間格式或者手機號格式不符合指定規則的就是異常數據,我們可以計算出這些格式異常的比率 |
|
表欄位數據的重覆率 |
採集指定表的指定欄位值的重覆率,比如某些欄位的值是不允許重覆的,出現重覆時就是異常 |
|
表欄位的缺失率 |
採集指定表的欄位數量是否和預期的欄位數量一致,如果不一致,就是出現了欄位缺失,就可以統計出欄位的缺失率 |
|
表數據入庫的及時率 |
採集指定的表數據的入庫時間和當前系統時間的差異,然後來計算出數據的及時性以及及時率 |
|
表記錄的丟失率 |
1、 採集指定的表數據的記錄數,然後和預期的數據量或者源表中的數據量進行比較,計算出數據記錄的丟失率 2、 採集指定的表數據的記錄數,然後和周或者月平均值進行比較,判斷數據記錄數是否低於正常標準,從而判斷是否存在丟失。 |
除了通用規則外,肯定還需要支持自定義的規則,自定義的規則可以允許用戶自己編寫SQL腳本、Python語言腳本或者scala 語言腳本。
- SQL腳本:一般是指通過JDBC的方式直接提交和運行SQL腳本從而獲取數據質量結果,常見的關係型資料庫,如MySQL、SQLServer等都是支持JDBC的,並且Hive也是支持JDBC連接的,另外還可以通過SparkSQL Job的方式來運行SQL腳本,如下圖所示。
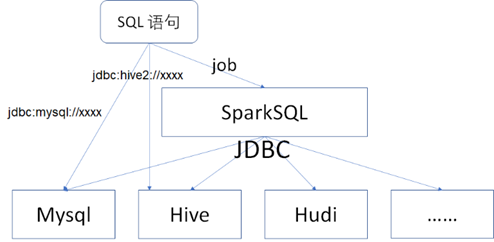
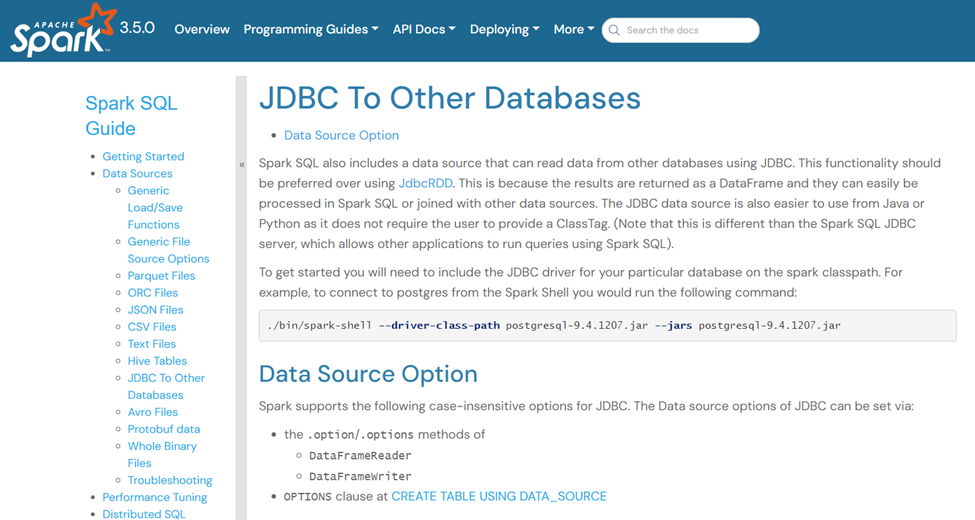
總結下來就是:如果資料庫或者數據倉庫本身支持JDBC 協議,那麼可以直接通過JDBC協議運行SQL語句。如果不支持的話,那麼可以通過SparkSQL job的方式進行過渡,SparkSQL 本身支持連接到Hive、Hudi等數據倉庫或者數據湖,也支持通過JDBC的方式連接到其他的資料庫。在官方網站地址: https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html中有明確的介紹,如下圖所示。
- Python腳本:Python 是一種常用的腳本語言,由於SQL 腳本只支持一些直接用SQL語句就可以查詢到的數據結果,對於一些複雜的場景或者SQL語句無法支持的場景,可以使用Python腳本,並且Spark也是支持Python語言的,如下圖所示。
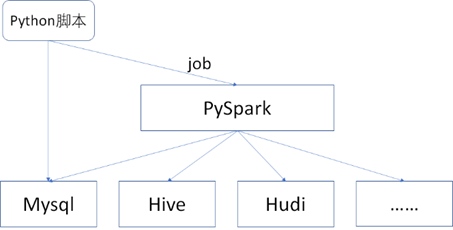
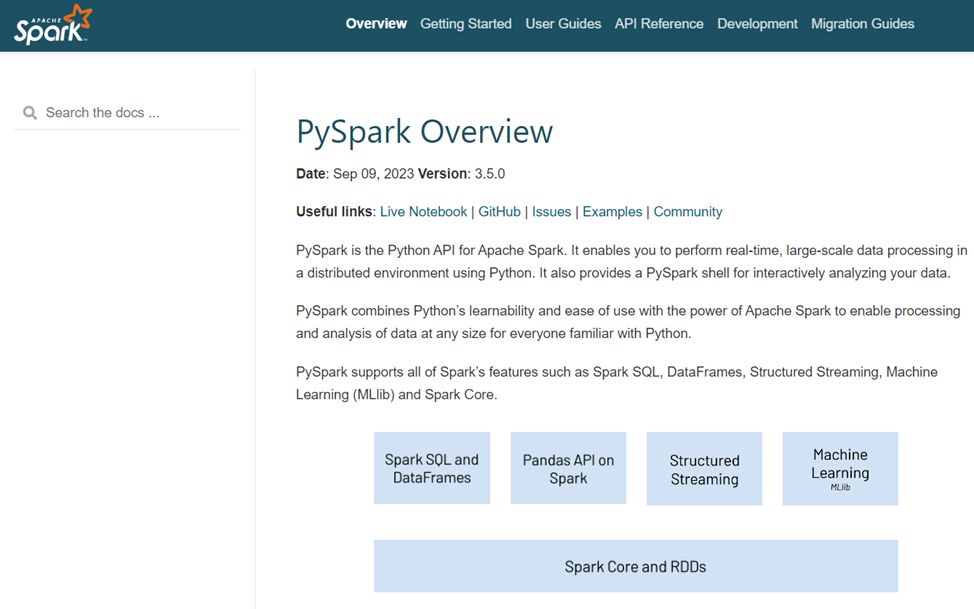
PySpark的相關介紹可以參考網址:https://spark.apache.org/docs/latest/api/python/index.html,如下圖所示。
《數據資產管理核心技術與應用》讀書筆記-第四章:數據質量的技術實現
- Scala腳本:Spark 底層本身主要是通過Scala語言編寫的代碼實現的,很多大數據開發者都很熱衷於使用Scala語言,所以對於Spark Job 採集數據質量時,也可以編寫Scala腳本,如下圖所示。
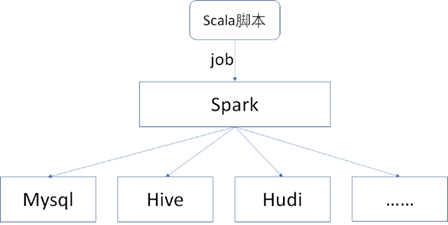
對於採集質量數據時,定時Job的技術選型,筆者在這裡推薦Apache DolphinSchedur這個大數據任務調度平臺。Apache DolphinSchedur是一個分散式、易於擴展的可視化工作流任務調度開源平臺,解決了複雜的大數據任務依賴關係,並支持在各種大數據應用程式的DataOPS中任意編排任務節點之間的關聯關係其以定向非迴圈圖(DAG)流模式組裝任務,可以及時監控任務的執行狀態,並支持重試、指定節點恢復失敗、暫停、恢復和終止任務等操作。官方網址為:https://dolphinscheduler.apache.org/en-us,如下圖所示。
Apache DolphinSchedur 支持二次開發,其Github地址為:https://github.com/apache/dolphinscheduler
相關的部署文檔的地址為:https://dolphinscheduler.apache.org/en-us/docs/3.2.0/installation_menu
如下圖所示,為官方在網址https://dolphinscheduler.apache.org/en-us/docs/3.2.0/architecture/design中提供的技術實現架構圖。
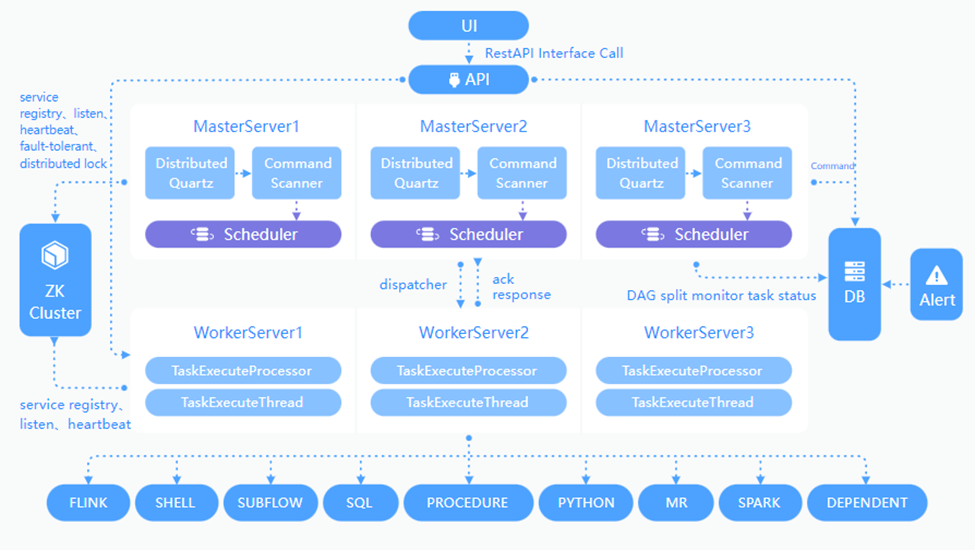
從圖中可以看到,其支持SQL、Python、Spark等任務節點,正好是我們所需要的,而且該平臺是支持分散式部署和調度的,所以不存在任何的性能瓶頸,因為分散式系統支持橫向或者縱向的擴展。
Apache DolphinSchedur 還提供了API的方式進行訪問,官方API文檔地址為:https://dolphinscheduler.apache.org/en-us/docs/3.2.0/guide/api/open-api。
最終採集質量數據的技術實現架構圖如下圖所示。
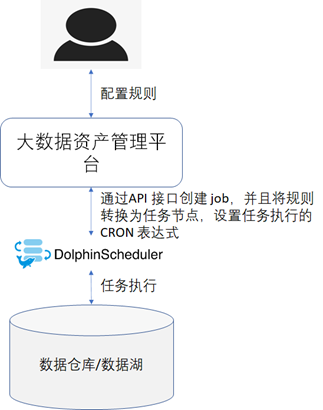
未完待續......《數據資產管理核心技術與應用》是清華大學出版社出版的一本圖書,讀書筆記-第四章:數據質量的技術實現.
作者的原創文章,轉載須註明出處。原創文章歸作者所有,歡迎轉載,但是保留版權。對於轉載了博主的原創文章,不標註出處的,作者將依法追究版權,請尊重作者的成果。

