
Web層緩存顯著提高了應用性能,通過減少重覆的數據處理和資料庫查詢來加快響應時間。Redis作為高效的記憶體數據結構存儲系統,在實現緩存層中發揮了重要作用,它支持各種數據結構,能夠迅速存取數據,從而減少資料庫負擔,提升用戶體驗。然而,緩存機制也面臨挑戰,如緩存穿透、緩存擊穿和緩存雪崩等問題。緩存穿透通... ...
Web層緩存對於提高應用性能至關重要,它通過減少重覆的數據處理和資料庫查詢來加快響應時間。例如,如果一個用戶請求的數據已經緩存,伺服器可以直接從緩存中返回結果,避免了每次請求都進行複雜的計算或資料庫查詢。這不僅提高了應用的響應速度,還減輕了後端系統的負擔。
Redis是一個流行的記憶體數據結構存儲系統,常用於實現高效的緩存層。它支持各種數據結構,如字元串、哈希、列表、集合等,能夠迅速存取數據。通過將常用的數據緩存到Redis中,應用可以大幅度降低資料庫負擔,同時提升用戶體驗。
緩存問題詳解
在本章中,我們將不深入探討Redis的基本緩存機制,而是專註於如何防範Redis失效可能帶來的不必要損失。我們將詳細討論緩存穿透、緩存擊穿和緩存雪崩等問題的產生原因及其解決策略。讓我們開始深入瞭解這些內容。
緩存穿透
緩存穿透指的是查詢一個根本不存在的數據時,緩存層和存儲層都未能命中。這種情況通常出於容錯考慮,如果存儲層未能找到數據,系統通常不會將其寫入緩存層。結果就是每次請求不存在的數據時,系統都需要直接訪問存儲層進行查詢,從而失去了緩存保護後端存儲的本質意義。這不僅增加了存儲層的負擔,也降低了系統的整體性能。
造成緩存穿透的基本原因主要有兩個:
- 自身業務代碼或數據問題:這類問題通常源於業務邏輯的缺陷或數據不一致。例如,如果業務代碼未能正確處理某些數據查詢,或數據源本身存在缺陷(如數據丟失、數據錯誤等),可能導致請求的查詢始終無法在緩存或存儲層找到對應的數據。這種情況下,緩存層無法有效地存儲和返回查詢結果,從而導致每次請求都需要直接訪問存儲層。
- 惡意攻擊或爬蟲行為:惡意攻擊者或自動化爬蟲可能會發起大量的請求,嘗試查詢大量不存在的數據。由於這些請求不斷打擊緩存和存儲層,造成大量的空命中(即查詢結果始終為空),不僅會消耗大量系統資源,還可能導致緩存層和存儲層的壓力顯著增加,從而影響系統的整體性能和穩定性。
解決方案——緩存空對象
解決緩存穿透的有效方案之一是緩存空對象。這種方法涉及在緩存層中存儲查詢結果為“空”的標記或對象,以表明特定數據不存在。通過這種方式,當後續請求查詢相同的數據時,系統可以直接從緩存層獲取“空對象”,而不必重新訪問存儲層。這不僅減少了對存儲層的頻繁訪問,還提高了系統的整體性能和響應速度,從而有效緩解緩存穿透問題。
String get(String key) {
// 從緩存中獲取數據
String cacheValue = cache.get(key);
// 緩存命中
if (cacheValue != null) {
return cacheValue;
}
// 緩存未命中,從存儲中獲取數據
String storageValue = storage.get(key);
// 如果存儲中數據為空,則設置緩存並設定過期時間
if (storageValue == null) {
cache.set(key, ""); // 存儲空對象標記
cache.expire(key, 60 * 5); // 設置過期時間(300秒)
} else {
// 存儲中數據存在,則緩存該數據
cache.set(key, storageValue);
}
return storageValue;
}
解決方案——布隆過濾器
對於惡意攻擊中通過請求大量不存在的數據造成的緩存穿透問題,可以使用布隆過濾器來進行初步過濾。布隆過濾器是一種空間效率極高的概率型數據結構,它能有效地判斷一個元素是否可能存在於集合中。具體而言,當布隆過濾器表示某個值可能存在時,實際情況可能是該值存在,也可能是布隆過濾器的誤判;但當布隆過濾器表示某個值不存在時,則可以肯定該值確實不存在。
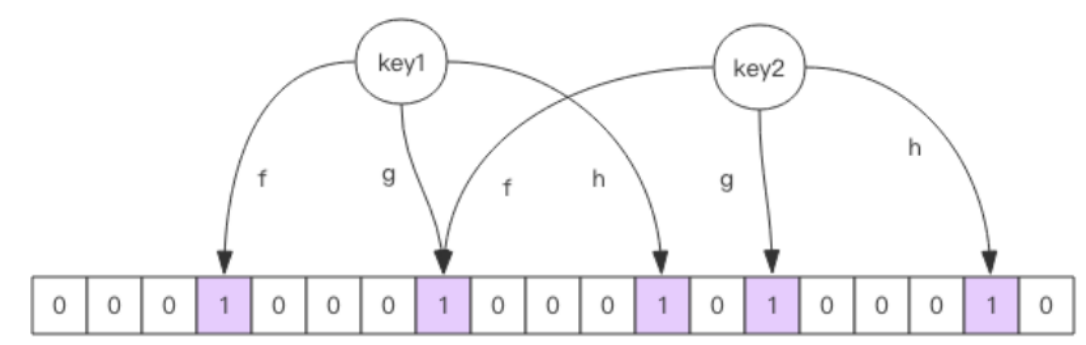
布隆過濾器是一種高效的概率型數據結構,由一個大型位數組和多個獨立的無偏哈希函數組成。無偏哈希函數的特點是能夠將輸入元素的哈希值均勻地分佈到位數組中,減少哈希衝突。添加一個鍵(key)到布隆過濾器時,首先使用這些哈希函數對鍵進行哈希運算,每個哈希函數生成一個整數索引值。然後,這些索引值經過對位數組長度的取模運算,確定在位數組中的具體位置。接著,將這些位置的值設置為1,標記該鍵的存在。
當查詢布隆過濾器中某個鍵(key)是否存在時,操作過程與添加鍵時類似。首先,使用多個哈希函數對鍵進行哈希運算,得到多個位置索引。然後,檢查這些索引對應的位數組位置。如果所有相關位置的值都是1,那麼可以推測該鍵可能存在;否則,如果有任意一個位置的值為0,則可以確定該鍵一定不存在。值得註意的是,即使所有相關位置的值均為1,這也僅僅意味著該鍵“可能”存在,而不能絕對確認,因為這些位置可能已經被其他鍵置為1。通過調整位數組的大小和哈希函數的數量,可以優化布隆過濾器的性能,達到較好的準確性與效率平衡。
這種方法特別適用於數據命中率不高、數據集相對固定、對實時性要求不高的應用場景,尤其是在數據集較大時,布隆過濾器可以顯著減少緩存空間的占用。儘管布隆過濾器的實現可能會增加代碼維護的複雜度,但其帶來的記憶體效率和查詢速度的優勢通常值得投入。
布隆過濾器在這類場景中的有效性得益於其能處理大規模數據集而只占用較少的記憶體空間。為了實現布隆過濾器,可以使用Redisson,這是一個支持分散式布隆過濾器的Java客戶端。要在項目中引入Redisson,可以添加以下依賴項:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.2</version> <!-- 請根據需要選擇合適的版本 -->
</dependency>
示例偽代碼:
package com.redisson;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
// 配置Redisson客戶端,連接到Redis伺服器
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
// 創建Redisson客戶端
RedissonClient redisson = Redisson.create(config);
// 獲取布隆過濾器實例,名稱為 "nameList"
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
// 初始化布隆過濾器,預計元素數量為100,000,000,誤差率為3%
bloomFilter.tryInit(100_000_000L, 0.03);
// 將元素 "zhuge" 插入到布隆過濾器中
bloomFilter.add("xiaoyu");
// 查詢布隆過濾器,檢查元素是否存在
System.out.println("Contains 'huahua': " + bloomFilter.contains("huahua")); // 應為 false
System.out.println("Contains 'lin': " + bloomFilter.contains("lin")); // 應為 false
System.out.println("Contains 'xiaoyu': " + bloomFilter.contains("xiaoyu")); // 應為 true
// 關閉Redisson客戶端
redisson.shutdown();
}
}
使用布隆過濾器時,首先需要將所有預期的數據元素提前插入布隆過濾器中,以便它能夠通過其位數組結構和哈希函數有效地檢測元素的存在性。在進行數據插入時,也必須實時更新布隆過濾器,以保證其數據的準確性。
以下是布隆過濾器緩存過濾的偽代碼示例,展示瞭如何在初始化和數據添加過程中操作布隆過濾器:
// 初始化布隆過濾器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
// 設置布隆過濾器的期望元素數量和誤差率
bloomFilter.tryInit(100_000_000L, 0.03);
// 將所有數據插入布隆過濾器
void init(List<String> keys) {
for (String key : keys) {
bloomFilter.add(key);
}
}
// 從緩存中獲取數據
String get(String key) {
// 檢查布隆過濾器中是否存在 key
if (!bloomFilter.contains(key)) {
return ""; // 如果布隆過濾器中不存在,返回空字元串
}
// 從緩存中獲取數據
String cacheValue = cache.get(key);
// 如果緩存值為空,則從存儲中獲取
if (StringUtils.isBlank(cacheValue)) {
String storageValue = storage.get(key);
if (storageValue != null) {
cache.set(key, storageValue); // 存儲非空數據到緩存
} else {
cache.expire(key, 300); // 設置過期時間為300秒
}
return storageValue;
} else {
// 緩存值非空,直接返回
return cacheValue;
}
}
註意:布隆過濾器不能刪除數據,如果要刪除得重新初始化數據。
緩存失效(擊穿)
由於在同一時間大量緩存失效可能會導致大量請求同時穿透緩存,直接訪問資料庫,這種情況可能會導致資料庫瞬間承受過大的壓力,甚至可能引發資料庫崩潰。
解決方案——隨機過期時間
為了緩解這一問題,我們可以採取一種策略:在批量增加緩存時,將這一批數據的緩存過期時間設置為一個時間段內的不同時間。具體來說,可以對每個緩存項設置不同的過期時間,這樣可以避免所有緩存項在同一時刻失效,從而減少瞬時請求對資料庫的衝擊。
以下是具體的示例偽代碼:
String get(String key) {
// 從緩存中獲取數據
String cacheValue = cache.get(key);
// 如果緩存為空
if (StringUtils.isBlank(cacheValue)) {
// 從存儲中獲取數據
String storageValue = storage.get(key);
// 如果存儲中的數據存在
if (storageValue != null) {
cache.set(key, storageValue);
// 設置一個過期時間(300到600秒之間的隨機值)
int expireTime = 300 + new Random().nextInt(301); // Random range: 300 to 600
cache.expire(key, expireTime);
} else {
// 存儲中沒有數據時,設置緩存的預設過期時間(300秒)
cache.expire(key, 300);
}
return storageValue;
} else {
// 返回緩存中的數據
return cacheValue;
}
}
緩存雪崩
緩存雪崩是指在緩存層出現故障或負載過高的情況下,導致大量請求直接涌向後端存儲層,從而引發存儲層的過載或宕機現象。通常,緩存層的作用是有效地承載和分擔請求流量,保護後端存儲層免受高併發請求的壓力。
然而,當緩存層由於某些原因無法繼續提供服務時,比如遇到超大併發的衝擊或者緩存設計不當(例如,訪問一個極大的緩存項 bigkey 導致緩存性能急劇下降),大量的請求將會轉發到存儲層。此時,存儲層的請求量會急劇增加,可能會導致存儲層也發生過載或宕機,從而引發系統級的故障。這種現象被稱為“緩存雪崩”。
解決方案
為了有效預防和解決緩存雪崩問題,可以從以下三個方面著手:
- 保證緩存層服務的高可用性:
確保緩存層的高可用性是避免緩存雪崩的關鍵措施。可以使用如 Redis Sentinel 或 Redis Cluster 等工具來實現緩存的高可用性。Redis Sentinel 提供自動故障轉移和監控功能,可以在主節點出現問題時自動將從節點提升為新的主節點,從而保持服務的連續性。Redis Cluster 通過數據分片和節點間的複製,進一步提高了系統的可用性和擴展性。這樣,即使部分節點發生故障,系統仍能正常運行並繼續處理請求。 - 依賴隔離組件進行限流、熔斷和降級:
利用限流和熔斷機制來保護後端服務免受突發請求的衝擊,可以有效緩解緩存雪崩帶來的壓力。例如,使用 Sentinel 或 Hystrix 等限流和熔斷組件來實施流量控制和服務降級。針對不同類型的數據,可以採取不同的處理策略:- 非核心數據:例如電商平臺中的商品屬性或用戶信息。如果緩存中的這些數據丟失,應用可以直接返回預定義的預設降級信息、空值或錯誤提示,而不是直接查詢後端存儲。這種方式可以減少對後端存儲的壓力,同時為用戶提供一些基本的反饋。
- 核心數據:例如電商平臺中的商品庫存。對於這些關鍵數據,仍然可以嘗試從緩存中查詢,如果緩存缺失,則通過資料庫讀取。這樣即使緩存不可用,核心數據的讀取仍可得到保證,避免了因緩存雪崩導致的系統功能喪失。
- 提前演練和預案制定:
在項目上線之前,進行充分的演練和測試,模擬緩存層宕機後的應用和後端負載情況,識別潛在問題並制定相應的預案。這包括模擬緩存失效、後端服務過載等情況,觀察系統表現,並根據測試結果調整系統配置和策略。通過這些演練,可以發現系統的弱點,並制定相應的應急措施,以應對實際生產環境中的突發情況。這不僅可以提升系統的魯棒性,還可以確保在緩存雪崩發生時,系統能夠迅速恢復正常運行。
通過綜合運用這些措施,可以顯著降低緩存雪崩帶來的風險,提升系統的穩定性和性能。
總結
Web層緩存顯著提高了應用性能,通過減少重覆的數據處理和資料庫查詢來加快響應時間。Redis作為高效的記憶體數據結構存儲系統,在實現緩存層中發揮了重要作用,它支持各種數據結構,能夠迅速存取數據,從而減少資料庫負擔,提升用戶體驗。
然而,緩存機制也面臨挑戰,如緩存穿透、緩存擊穿和緩存雪崩等問題。緩存穿透通過緩存空對象和布隆過濾器來解決,前者避免了每次查詢都訪問資料庫,後者有效減少了惡意請求的影響。緩存擊穿則通過設置隨機過期時間來緩解,這樣可以避免大量請求同時涌向資料庫。對於緩存雪崩,保證緩存層的高可用性、採用限流和熔斷機制,以及制定充分的預案是關鍵。
有效的緩存管理不僅提升了系統性能,還增強了系統的穩定性。瞭解並解決這些緩存問題,能確保系統在高併發環境下保持高效、穩定的運行。精心設計和實施緩存策略是優化應用性能的基礎,持續關註和調整這些策略可以幫助系統應對各種挑戰,保持良好的用戶體驗。
我是努力的小雨,一名 Java 服務端碼農,潛心研究著 AI 技術的奧秘。我熱愛技術交流與分享,對開源社區充滿熱情。同時也是一位掘金優秀作者、騰訊雲內容共創官、阿裡雲專家博主、華為云云享專家。


