
Text To SQL 指的是將自然語言轉化為能夠在關係型資料庫中執行的結構化查詢語言(簡稱 SQL)。近年來,伴隨人工智慧大模型技術的不斷進步,Text To SQL 任務的成功率顯著提升,這得益於大模型的推理、理解以及指令遵循等能力。 對於大數據平臺來說,集成 Text To SQL 功能意義非 ...
Text To SQL 指的是將自然語言轉化為能夠在關係型資料庫中執行的結構化查詢語言(簡稱 SQL)。近年來,伴隨人工智慧大模型技術的不斷進步,Text To SQL 任務的成功率顯著提升,這得益於大模型的推理、理解以及指令遵循等能力。
對於大數據平臺來說,集成 Text To SQL 功能意義非凡。首先,這能夠大幅優化用戶體驗;其次,Text To SQL 功能能夠提高數據開發人員的工作效率,他們能夠憑藉自然語言描述來完成 SQL 任務的開發,進而極大地節省學習和編寫複雜 SQL 語句的時間;最後,Text To SQL 功能降低了資料庫查詢的門檻,使得更多非技術人員能夠參與到資料庫查詢工作中,讓更多人得以享受大數據帶來的便利。
本文將探討袋鼠雲在 Text To SQL 領域的探索與實踐,分享如何實現更高效、更準確的自然語言到 SQL 的轉換。
基於 LLM 實現 Text To SQL
設計基於大模型(LLM)的 Text To SQL 系統是一項複雜且精細的任務,包括多個步驟和環節,每個步驟都需要我們精心設計和處理。首先,我們需要將資料庫中表的元信息進行組織。此步驟涉及到將每一個表的詳細信息,如欄位名稱、類型、關係等,寫入到向量資料庫中,這樣就可以為後續的 SQL 生成提供必要的信息,這一步對於後續的 SQL 生成至關重要。
接著,我們需要對用戶輸入的自然語言加以理解。在這一步,我們將會運用先進的 embedding 模型。憑藉這種模型,能夠將用戶輸入的語言實施向量化處理,把每一個詞或者片語轉化為一個具備特定維度的向量。隨後,我們會前往向量資料庫中展開查找,匹配相關的表元數據信息,如此一來,我們便能知曉用戶的查詢意圖與哪些表存在關聯。
最後,我們把上一步匹配所得的表元數據信息與用戶的問題加以合併,生成最終的 prompt。此 prompt 包括了全部所需的信息,涵蓋角色表述、用戶的初始問題、我們匹配到的相關表元數據信息以及一些約束條件。而後,我們把這個 prompt 交付給 LLM 模型,讓模型依據這些信息生成最終的 SQL 查詢語句。這一過程需要大模型(LLM)強大的計算能力以及精準的理解能力,以保障生成的 SQL 語句能夠確切地反映用戶的查詢意圖。
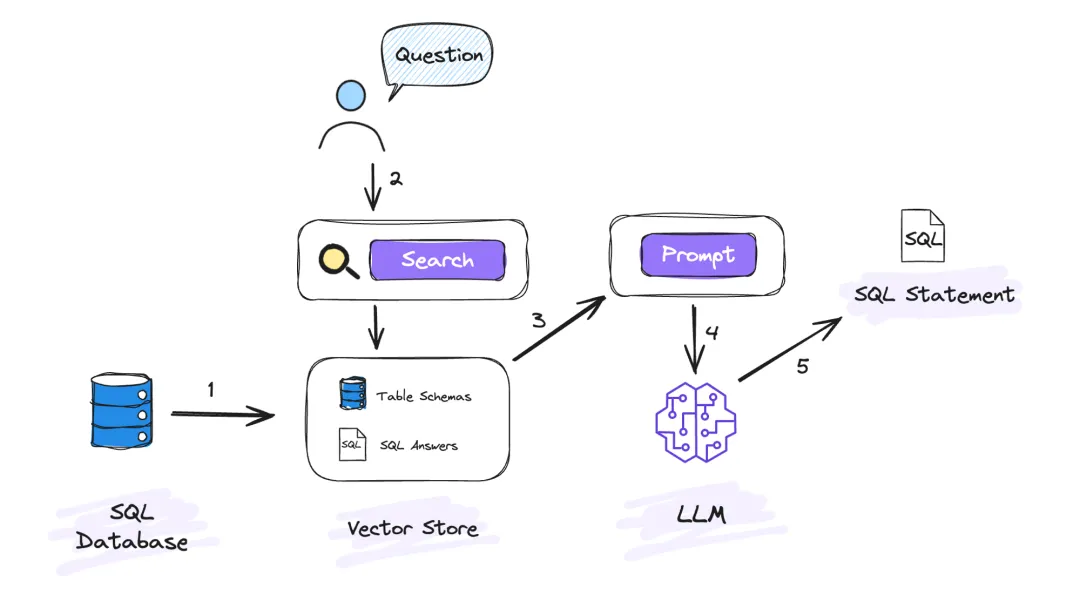
在數棧中實現 Text To SQL
● 表 schema 寫入向量資料庫
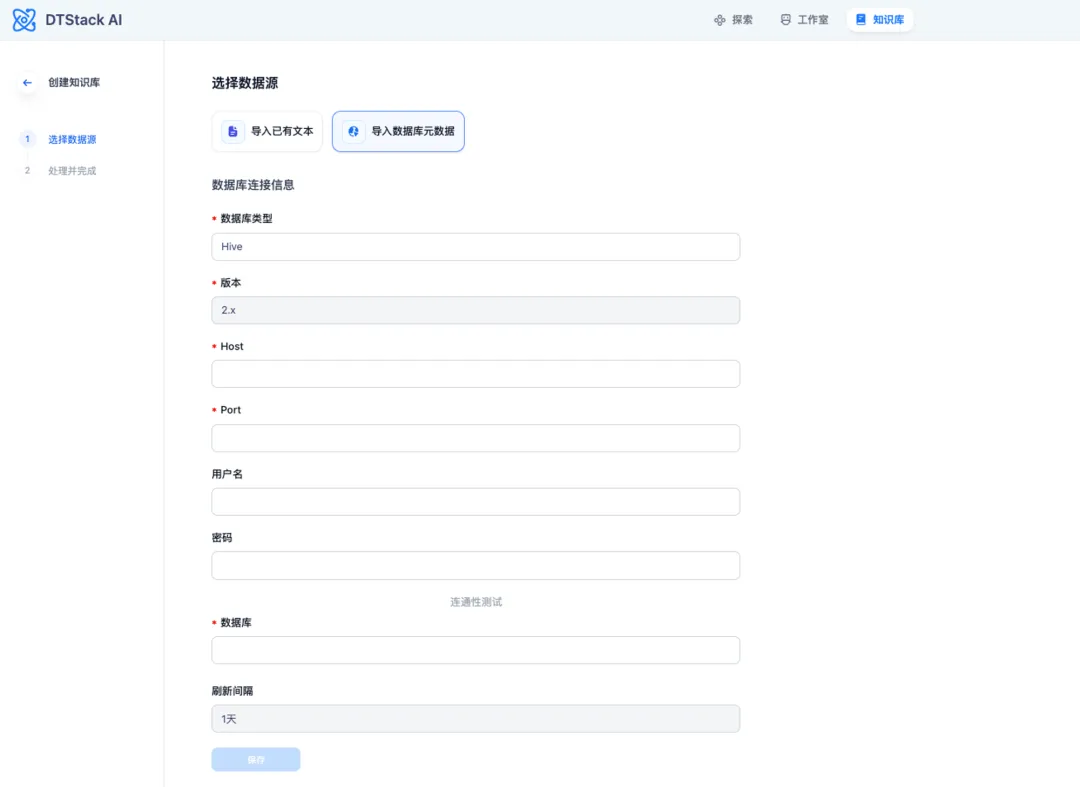
為了便於將資料庫元數據置入向量資料庫,在數棧中,我們研發了能夠一鍵導入資料庫表元數據信息的功能,並且支持自動刷新,如上圖所示。
在此過程里,最為重要的當屬如何對錶的元數據信息進行組織,這一步極為關鍵,因為它會直接作用於 SQL 生成的準確性。我們所設計的表元數據信息組織格式如下:
table_name(column_name column_type column_comment,[...]), table_comment=""
● 根據用戶問題匹配相關表元數據
這一步所面臨的關鍵問題在於如何精準匹配到與用戶輸入問題相關的所有表元數據信息。為此,我們選用了對中文支持良好的 bge-large-zh-v1.5 embedding 模型,來對用戶輸入的問題進行向量化處理,以便充分領會用戶的意圖。
而在檢索元數據信息方面,我們採用了混合檢索的模式,即將向量化檢索與全文搜索相結合。具體來說,首先依據用戶問題生成的向量,在向量資料庫中匹配出 TopK 條信息;接著運用 bm25 演算法對錶元信息進行一次全文搜索並獲取結果;最後將向量檢索和全文搜索所獲取的結果予以合併,併進行一次相關性排序,從而得到最終的結果。
● 生成 Prompt
構建請求大模型的 Prompt。這裡分享一個小技巧,就是使用 XML 標簽來分隔 Prompt 中的每一部分內容。這種方法非常有效,因為大語言模型已經接受了大量包含 XML 格式的網頁內容的訓練,因此能夠理解其結構,這樣就能很好的幫助大模型完整識別到 Prompt 中的每一部分。
如下是我們定義生成 Text To SQL 的 Prompt 模版,
<context>
表結構信息如下:
{{表結構信息}}
</context>
<objective>
你是一個高級SQL生成器,能夠根據不同的SQL方言生成相應的SQL語句。你需要將用戶輸入的自然語言轉化為SQL,請按照以下步驟操作:
1. 請一步步思考並仔細分析用戶的自然語言輸入,確保充分理解用戶的意圖。
2. 識別目標資料庫類型為{{SQL方言}} SQL
3. 考慮該資料庫類型的特定語法和函數。
4. 根據理解的用戶意圖,設計SQL查詢的基本結構。
5. 應用資料庫特定的語法規則,對基本結構進行調整。
6. 優化查詢以提高性能(如適用)。
7. 生成最終的SQL語句。
在生成SQL時,請特別註意以下幾點:
- 使用{{SQL方言}} SQL特有的函數和語法結構 - 考慮該資料庫類型的查詢優化技巧
- 確保生成的SQL語句在語法和邏輯上的正確性
如果用戶的請求不明確或需要額外信息,請提出澄清性問題。
</objective>
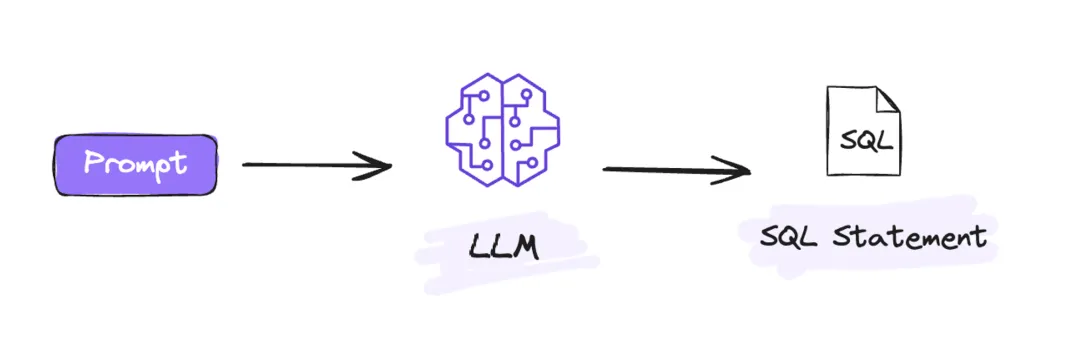
● Prompt 構建完成後請求 LLM,生成 SQL
Prompt 構建完成後將 Prompt 發給大模型(LLM)執行,經過大模型(LLM)的推理能力生成 SQL。
Text To SQL 的優化手段
上文介紹了 Text To SQL 的一般流程,在這個流程中還可以加入一些優化手段來進一步提高生成 SQL 的準確率,下麵分享兩個優化技巧。
● Prompt Engineering - 動態少樣本
Medprompt 是微軟提出的一種極為有效的提示策略,動態少樣本則屬於 Medprompt 提示策略中的一項技巧。使用動態少樣本可以進一步挖掘大模型的能力,提升響應的準確率。
在 Text To SQL 中如何使用動態少樣本,首先可以結合自己的業務場景寫出一些具有針對性的 SQL 生成問答對,然後將生成的這些問答對寫入到向量資料庫中,構建 Prompt 時根據用戶輸入問題進行一次向量檢索然後將結果寫入到 Prompt 中。
大模型存在不能理解某些領域的專有辭彙問題,這個問題也可以通過這種方法解決,對於不能識別的辭彙語句可以提前生成 SQL 生成問答對,生成 Prompt 時進行動態匹配,作為上下文發送給 LLM,這樣 LLM 就能理解了。
● 模型微調
大模型(LLM)自身已然擁有 Text To SQL 的能力,而且通常模型規模越大,Text To SQL 的能力便越強。不管是大模型還是小模型,均能夠通過微調來進一步增強 Text To SQL 的能力。當下,與 Text To SQL 相關的開源數據集眾多,例如 WikiSQL、Spider 等等。
目前我們所採用的模型為阿裡開源的通義千問 Qwen1.5-14B-Chat ,並運用 Spider 數據集進行了微調,模型微調前後在 Spider 數據集上的評測數據如下:

Text To SQL 在數棧中的應用
數棧作為一個大數據開發平臺,始終專註於推動技術創新,提升用戶體驗。為了更進一步提高開發人員的工作效率並簡化數據處理流程,數棧開發團隊研發了「棧語妙編」智能助手。
「棧語妙編」智能助手能夠把用戶的自然語言描述轉換為 SQL 語句,開發人員只需將待開發的 SQL 任務以自然語言進行描述,「棧語妙編」助手便會生成相應的 SQL ,如此一來,顯著提升了開發人員的工作效率,使其能夠將更多精力聚焦於數據分析和業務邏輯方面。
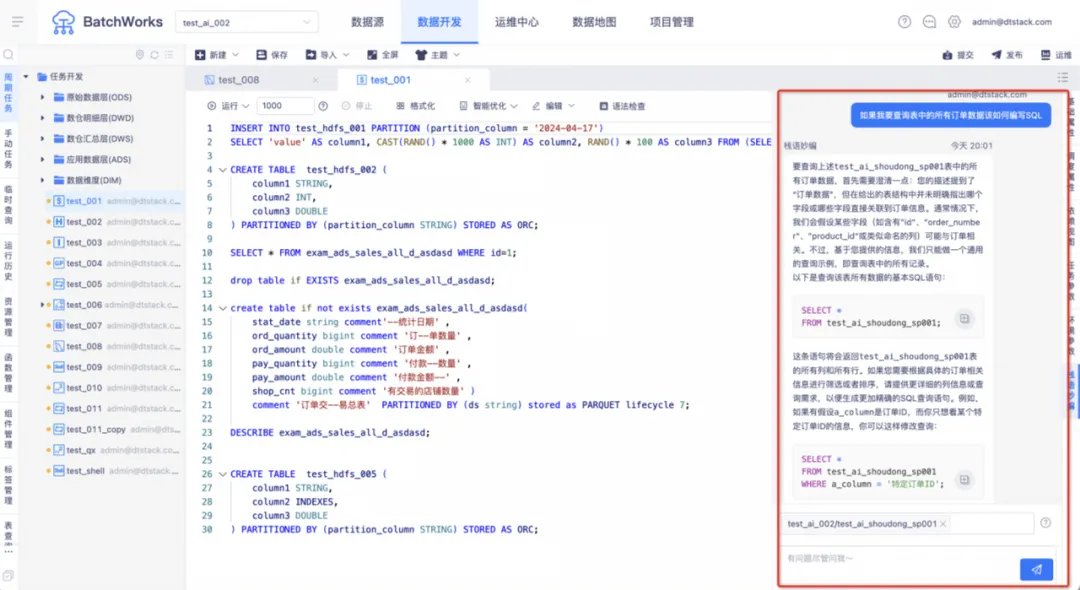
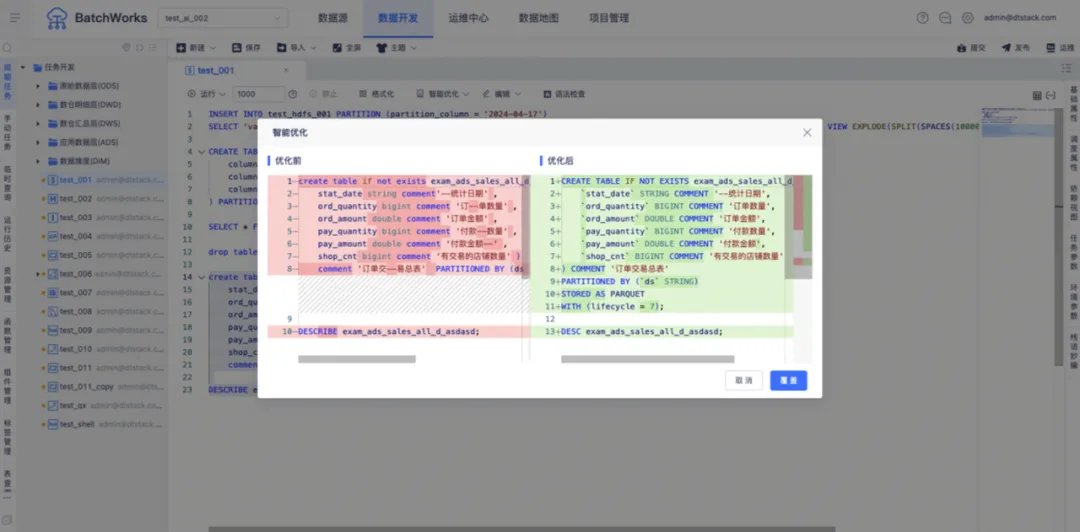
「棧語妙編」智能助手不僅可以根據自然語言生成 SQL,還可以對已有的 SQL 任務進行智能優化、SQL 糾錯、代碼補全和添加註釋。
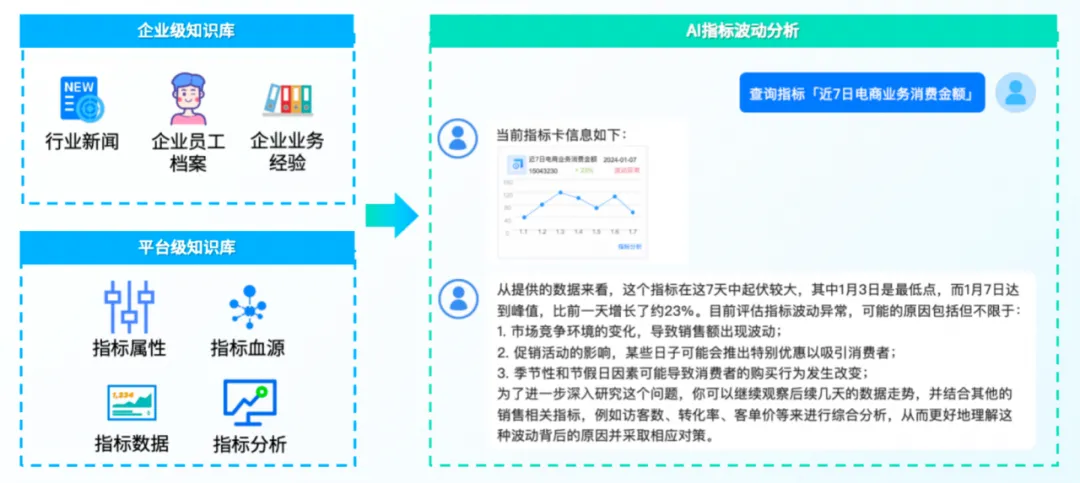
指標平臺在數據驅動決策中扮演著至關重要的角色,為了使指標平臺進入到一個新的智能化階段,我們正在積極結合大模型(LLM)來提升指標平臺的易用性、智能化程度和降低使用門檻,Text To SQL就是其中之一。
「袋鼠雲指標管理平臺」引入 Text To SQL 技術後,用戶可以通過日常使用的自然語言來查詢複雜的指標數據,並能基於查詢結果進行深入分析,而無需掌握專業的 SQL 語法或瞭解底層數據結構。
《行業指標體系白皮書》下載地址:https://www.dtstack.com/resources/1057?src=szsm
《數棧產品白皮書》下載地址:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky


