
1.知識補充 1.1 nolocal關鍵字 在之前的課程中,我們學過global關鍵字。 name = 'root' def outer(): name = "武沛齊" def inner(): global name name = 123 inner() print(name) # 武沛齊 out ...
1.知識補充
1.1 nolocal關鍵字
在之前的課程中,我們學過global關鍵字。
name = 'root'
def outer():
name = "武沛齊"
def inner():
global name
name = 123
inner()
print(name) # 武沛齊
outer()
print(name) # 123
其實,還有一個nolocal關鍵字,用的比較少,此處作為瞭解即可。
name = 'root'
def outer():
name = "武沛齊"
def inner():
nonlocal name
name = 123
inner()
print(name) # 123
outer()
print(name) # root
name = 'root'
def outer():
name = 'alex'
def func():
name = "武沛齊"
def inner():
nonlocal name
name = 123
inner()
print(name) # 123
func()
print(name) # alex
outer()
print(name) # root
name = 'root'
def outer():
name = 'alex'
def func():
nonlocal name
name = "武沛齊"
def inner():
nonlocal name
name = 123
inner()
print(name) # 123
func()
print(name) # 123
outer()
print(name) # root
1.2 yield from
在生成器部分我們瞭解了yield關鍵字,其在python3.3之後有引入了一個yield from。
def foo():
yield 2
yield 2
yield 2
def func():
yield 1
yield 1
yield 1
yield from foo()
yield 1
yield 1
for item in func():
print(item)
1.3 深淺拷貝
-
淺拷貝
-
不可變類型,不拷貝。
import copy v1 = "武沛齊" print(id(v1)) # 140652260947312 v2 = copy.copy(v1) print(id(v2)) # 140652260947312按理說拷貝v1之後,v2的記憶體地址應該不同,但由於python內部優化機制,記憶體地址是相同的,因為對不可變類型而言,如果以後修改值,會重新創建一份數據,不會影響原數據,所以,不拷貝也無妨。
-
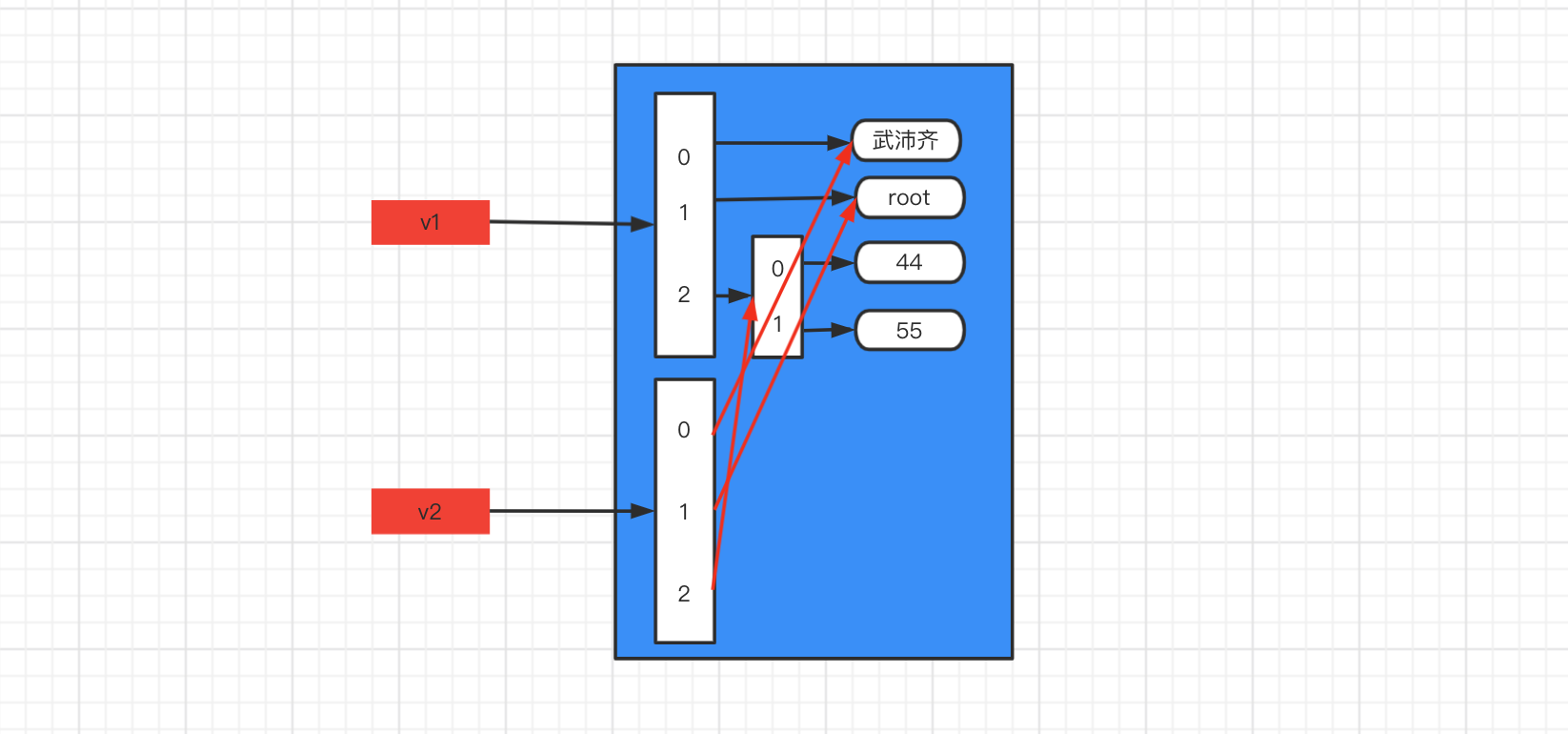
可變類型,只拷貝第一層。
import copy v1 = ["武沛齊", "root", [44, 55]] print(id(v1)) # 140405837216896 print(id(v1[2])) # 140405837214592 v2 = copy.copy(v1) print(id(v2)) # 140405837214784 print(id(v2[2])) # 140405837214592
-
-
深拷貝
-
不可變類型,不拷貝
import copy v1 = "武沛齊" print(id(v1)) # 140188538697072 v2 = copy.deepcopy(v1) print(id(v2)) # 140188538697072特殊的元組:
-
元組元素中無可變類型,不拷貝
import copy v1 = ("武沛齊", "root") print(id(v1)) # 140243298961984 v2 = copy.deepcopy(v1) print(id(v2)) # 140243298961984 -
元組元素中有可變類型,找到所有【可變類型】或【含有可變類型的元組】 均拷貝一份
import copy v1 = ("武沛齊", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]) v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784
-
-
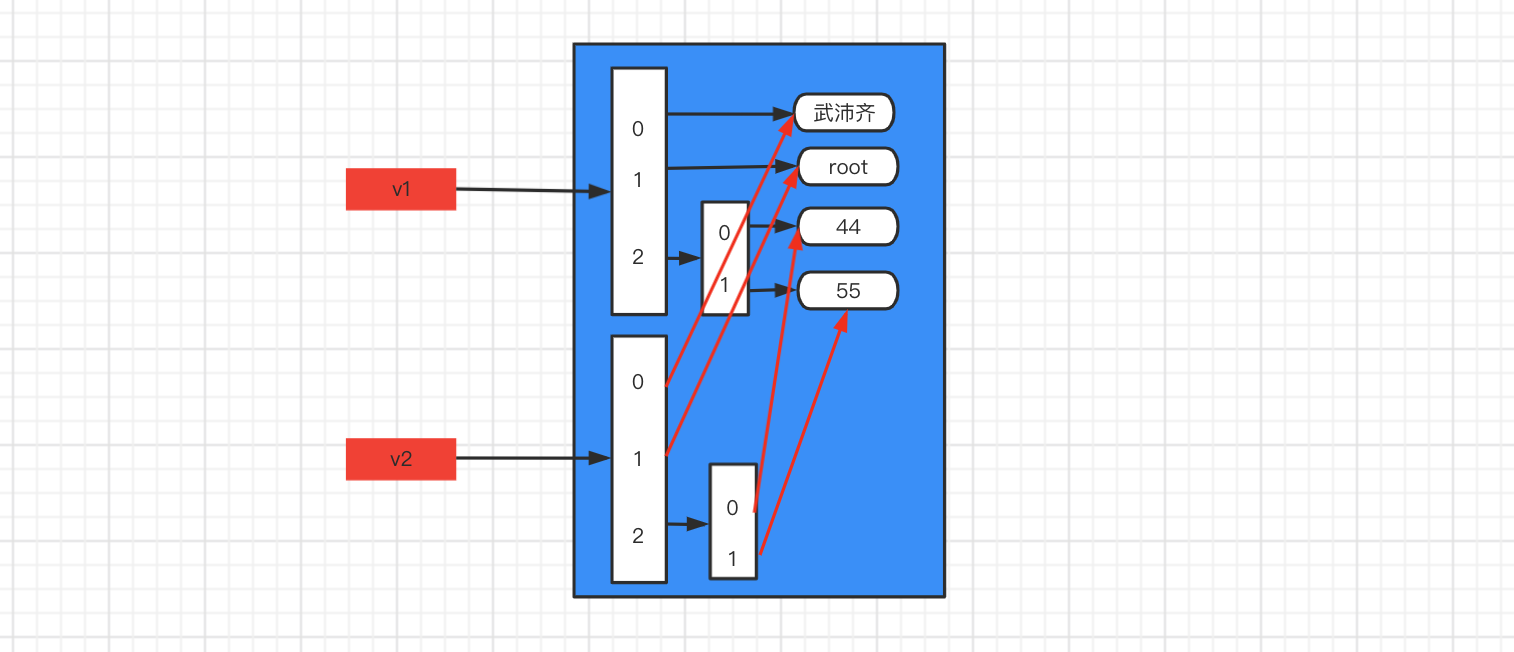
可變類型,找到所有層級的 【可變類型】或【含有可變類型的元組】 均拷貝一份
import copy v1 = ["武沛齊", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]] v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784import copy v1 = ["武沛齊", "root", [44, 55]] v2 = copy.deepcopy(v1) print(id(v1)) # 140405837216896 print(id(v2)) # 140405837214784 print(id(v1[2])) # 140563140392256 print(id(v2[2])) # 140563140535744
-
2.階段總結
3.考試題
- 一個大小為100G的文件 etl_log.txt,要讀取文件中的內容,寫出具體過程代碼。
# 如果文件有多行
with open("etl_log.txt", mode="r", encoding="utf-8") as f:
for line in f:
print(line)
# 文件只有一行
import os
file_size = os.path.getsize("etl_log.txt")
chunk_size = 0
with open("etl_log.txt", mode='r', encoding="utf-8") as f:
while chunk_size < file_size:
data = f.read(1)
chunk_size += len(data)
- 編寫一個函數,這個函數接受一個文件夾名稱作為參數,尋找文件夾中所有文件的路徑並輸入(包含嵌套)。
import os
def get_all_file(folder_name):
data_list = os.walk(folder_name)
for folder_path, folder_list, file_list in data_list:
for file_name in file_list:
file_path = os.path.join(folder_path, file_name)
print(file_path)
- 以下的代碼數據的結果是什麼?
def extend_list(val,data=[]):
data.append(val)
return data
list1 = extend_list(10)
list2 = extend_list(123,[])
list3 = extend_list("a")
print(list1,list2,list3) # [10, 'a'] [123] [10, 'a']
- python代碼獲取命令行參數。
import sys
print(sys.argv)
- 簡述深淺拷貝?
- 淺拷貝:
- 可變類型,只拷貝第一層
- 不可變類型:不拷貝
- 深拷貝:
- 可變類型:找到所有層級的可變類型或含有可變類型的元組均拷貝一份
- 不可變類型:不拷貝
- 元組比較特殊
- 元組中無可變類型,不拷貝
- 元組中有可變類型,會將所有的可變類型或含有可變類型的元組均拷貝一份
- 基於推導式一行代碼生成1-100以內的偶數列表。
even_list = [i for i in range(101) if i % 2 == 0]
print(even_list)
- 請把以下函數轉化為python lambda匿名函數
def add(x,y):
return x+y
add = lambda x, y: x + y
- 看代碼寫結果
def num():
return [lambda x: i * x for i in range(4)]
result = [m(2) for m in num()]
print(result) # [6, 6, 6, 6]
- 列表推導式和生成器表達式 [i % 2 for i in range(10)] 和 (i % 2 for i in range(10)) 輸出結果分別是什麼?
列表推導式的輸出結果:[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
生成器表達式的輸出結果:生成器的地址 - 寫裝飾器
# 寫timer裝飾器實現:計算fun函數執行時間,並將結果給 result,最終列印(不必使用datetime,使用time.time即可)。
@timer
def func():
pass
result = func()
print(result)
import time
import functools
def timer(origin):
@functools.wrap(origin)
def inner(*args, **kwargs):
start = time.time()
res = origin(*args, **kwargs)
end = time.time()
message = "耗時:{}".format(end - start)
print(message)
return res
return inner
@timer
def func():
pass
result = func()
print(result)
-
re的match和search區別?
match會從所給文本的頭開始匹配,如果不符合條件,直接返回none
search會從所給文本中找到第一處匹配規則的文本,然後返回,沒找到就返回none -
什麼是正則的貪婪匹配?或 正則匹配中的貪婪模式與非貪婪模式的區別?
貪婪匹配就是會儘可能多的去匹配符合正則表達式的文本
非貪婪匹配就是只要找到符合正則表達式的文本就返回 -
sys.path.append("/root/mods")的作用?
將"/root/mods"加入sys.path,那麼項目就可以直接導入"/root/mods"下的模塊和包。 -
寫函數
有一個數據結構如下所示,請編寫一個函數從該結構數據中返回由指定的 欄位和對應的值組成的字典。如果指定欄位不存在,則跳過該欄位。 DATA = { "time": "2016-08-05T13:13:05", "some_id": "ID1234", "grp1": {"fld1": 1, "fld2": 2, }, "xxx2": {"fld3": 0, "fld4": 0.4, }, "fld6": 11, "fld7": 7, "fld46": 8 } fields:由"|"連接的以fld開頭的字元串, 如fld2|fld7|fld29 def select(fields): print(DATA) return resultdef select(fields): result = {} field_list = fields.split("|") for field in field_list: data = DATA.get(field) if not data: continue result[field] = data return result -
編寫函數,實現base62encode加密(62進位),例如:
內部維護的數據有:0123456789AB..Zab..z(10個數字+26個大寫字母+26個小寫字母)。
當執行函數:
base62encode(1),獲取的返回值為1
base62encode(61),獲取的返回值為z
base62encode(62),獲取的返回值為10
import string
import itertools
MAP = list(itertools.chain(string.digits, string.ascii_uppercase, string.ascii_lowercase)) # 生成內部維護的數據
def base62encode(data):
total_count = len(MAP)
position_value = []
while data >= total_count:
data, div = divmod(data, total_count) # 得到餘數和商
position_value.insert(0, MAP[div]) # 取得MAP中對應的值放到列表最前面
position_value.insert(0, MAP[data])
res = "".join(position_value)
return res
- 基於列表推導式一行實現輸出9*9乘法表。
print("\n".join([" ".join(["{}*{}={}".format(i, j, i * j) for i in range(1, 10) for j in range(i, 10)])]))

