
Qt 是一個跨平臺C++圖形界面開發庫,利用Qt可以快速開發跨平臺窗體應用程式,在Qt中我們可以通過拖拽的方式將不同組件放到指定的位置,實現圖形化開發極大的方便了開發效率,本章將重點介紹`QSqlDatabase`資料庫模塊的常用方法及靈活運用。Qt SQL模塊是Qt框架的一部分,它提供了一組類和函... ...
Java 記憶體模型
Java 記憶體模型(Java Memory Model)的主要目的是定義程式中各種變數的訪問規則,即關註在虛擬機中把變數值存儲到記憶體和從記憶體中取出變數值這樣的底層細節
1. 主記憶體與工作記憶體
Java 記憶體模型規定了 所有的變數都存儲在主記憶體(Main Memory)中(虛擬機記憶體的一部分)。每條線程還有自己的工作記憶體(Working Memory),線程的工作記憶體中保存了被該線程使用的變數的主記憶體副本,線程對變數的所有操作都必須在工作記憶體中進行,而不能直接讀寫主記憶體中的數據。不同的線程之間也無法直接訪問對方工作記憶體中的變數,線程間變數值的傳遞均需要通過主記憶體來完成
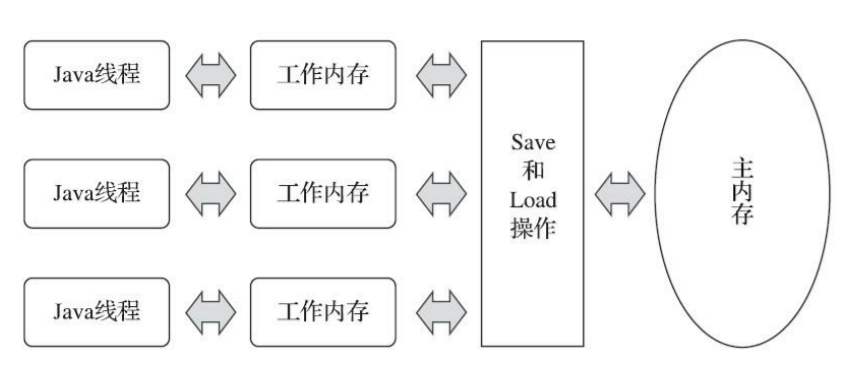
深入理解Java虛擬機(第3版) - 圖12-2 線程、主記憶體、工作記憶體三者的交互關係
2. 記憶體間交互操作
關於主記憶體與工作記憶體之間具體的交互協議,Java 記憶體模型中定義了以下 8 種操作來完成。JVM 實現時必須保證下麵提及的每一種操作都是原子的、不可再分的
- 作用於主記憶體的變數
- lock(鎖定):把一個變數標識為一條線程獨占的狀態
- unlock(解鎖):把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他線程鎖定
- read(讀取):把一個變數的值從主記憶體傳輸到線程的工作記憶體中,以便隨後的 load 動作使用
- write(寫入):把 store 操作從工作記憶體中得到的變數的值放入主記憶體的變數中
- 作用於工作記憶體的變數
- load(載入):把 read 操作從主記憶體中得到的變數值放入工作記憶體的變數副本中
- use(使用):把工作記憶體中一個變數的值傳遞給執行引擎,每當虛擬機遇到一個需要使用變數的值的位元組碼指令時將會執行這個操作
- assign(賦值):把一個從執行引擎接收的值賦給工作記憶體的變數,每當虛擬機遇到一個給變數賦值的位元組碼指令時執行這個操作
- store(存儲):把工作記憶體中一個變數的值傳送到主記憶體中,以便隨後的 write 操作使用
如果要把一個變數從主記憶體拷貝到工作記憶體,那就要按順序執行 read 和 load 操作,如果要把變數從工作記憶體同步回主記憶體,就要按順序執行 store 和 write 操作。Java 記憶體模型只要求上述兩個操作必須按順序執行,但不要求是連續執行,中間可插入其他指令
Java 記憶體模型還規定了在執行上述 8 種基本操作時必須滿足如下規則
- 不允許 read 和 load、store 和 write 操作之一單獨出現,即不允許一個變數從主記憶體讀取了但工作記憶體不接受,或者工作記憶體發起回寫了但主記憶體不接受的情況出現
- 不允許一個線程丟棄它最近的 assign 操作,即變數在工作記憶體中改變了之後必須把該變化同步回主記憶體
- 不允許一個線程無原因地(沒有發生過任何 assign 操作)把數據從線程的工作記憶體同步回主記憶體中
- 一個新的變數只能在主記憶體中誕生,不允許在工作記憶體中直接使用一個未被初始化(load 或 assign)的變數,換句話說就是對一個變數實施 use、store 操作之前,必須先執行 assign 和 load 操作
- 一個變數在同一個時刻只允許一條線程對其進行 lock 操作,但 lock 操作可以被同一條線程重覆執行多次,多次執行 lock 後,只有執行相同次數的 unlock 操作,變數才會被解鎖
- 如果對一個變數執行 lock 操作,那將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前,需要重新執行 load 或 assign 操作以初始化變數的值
- 如果一個變數事先沒有被 lock 操作鎖定,那就不允許對它執行 unlock 操作,也不允許去 unlock 一個被其他線程鎖定的變數
- 對一個變數執行 unlock 操作之前,必須先把此變數同步回主記憶體中(執行 store、write 操作)
3. 對於 volatile 型變數的特殊規則
關鍵字 volatile 可以說是 JVM 提供的最輕量級的同步機制,但是它並不容易被正確、完整地理解,以至於許多程式員都習慣去避免使用它,遇到需要處理多線程數據競爭問題的時候一律使用 synchronized 來進行同步
- 在功能上,鎖更強大;在性能上,volatile 更有優勢
當一個變數被定義成 volatile 之後,它將具備兩項特性
3.1 保證線程間變數的可見性
被 volatile 修飾的變數,當一條線程修改了這個變數的值,新值對於其他線程來說是可以立即得知的。而普通變數並不能做到這一點,普通變數的值線上程間傳遞時均需要通過主記憶體來完成
- 普通變數讀:優先從本地記憶體內讀取
- 普通變數寫:線程對普通變數的更改不會立即同步到主記憶體,其他線程工作記憶體放的該變數的副本也不會立即更新。如果其他線程需要操作該變數,可能會讀取到舊值
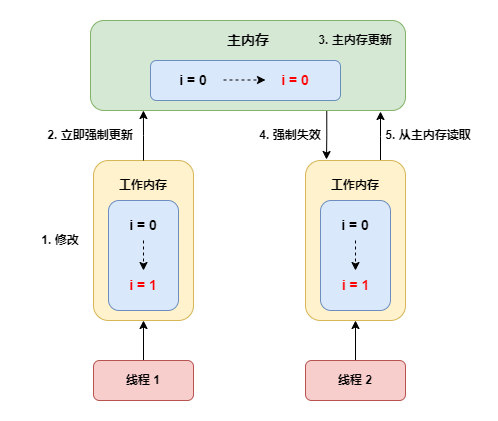
- volatile 變數讀:Java 記憶體模型會將該線程對應的工作記憶體內變數的緩存置為無效,從主記憶體中讀取共用變數的值
- volatile 變數寫:在本工作記憶體中修改完成後,立即將修改後的值刷新到主記憶體中。如果有其他線程存有該變數的副本,會被強制失效。如果其他線程需要操作該變數,就會從主記憶體中載入最新的值
3.1.1 無法保證原子性
volatile 變數的運算在併發下一樣是不安全的
public class Test {
private static volatile int race = 0;
public static void incr() {
race++;
}
public static void main(String[] args) {
Thread[] arr = new Thread[20];
for (int i = 0; i < arr.length; i++) {
arr[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
incr();
}
});
arr[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(race);
}
}
該段代碼的期望值為 200000,而實際執行得到的結果且千奇百怪,volatile 確實保證了可見性,但 race++ 並不是一個原子操作,它需要先取值,再加 1,再寫入到工作記憶體中
volatile 變數在不符合以下兩條規則的運算場景中,需要通過加鎖(或者使用原子類)來保證原子性
- 運算結果並不依賴變數的當前值,或者能夠確保只有單一的線程修改變數的值
- 變數不需要與其他的狀態變數共同參與不變約束
3.2 禁止指令重排序
普通的變數僅會保證在該方法的執行過程中所有依賴賦值結果的地方都能獲取到正確的結果,而不能保證變數賦值操作的順序與程式代碼中的執行順序一致。因為在同一個線程的方法執行過程中無法感知到這點,這就是 Java 記憶體模型中描述的所謂線程內表現為串列的語義(Within-Thread As-If-Serial Semantics)
3.2.1 指令重排序
在 CPU 的實際工作中,每個指令會包含多個步驟,不同的步驟涉及的硬體也可能不同。出於性能考慮,流水線技術誕生了,不需要等待當前的指令執行完,就可以執行下一條指令
# 例如,需要給變數 a、b 進行賦值,一次賦值的操作有從記憶體中取值、賦值、寫回記憶體,每個操作只能同時有一個在運行,且每個操作都需要1秒鐘時間執行完
# 按照順序先後執行,執行完需6秒
a: 取->賦->寫
b: 取->賦->寫
# 使用流水線技術,執行完需4秒
a: 取->賦->寫
b: 取->賦->寫
但是流水線最怕的就是中斷,一旦被中斷,所有的硬體設備都會進入一個停頓期,再次滿載又需要幾個周期,因此,性能損失會比較大
# 依照上面的例子,增加c=a+b和對變數d的賦值
# 由於c取值時,b還未完成賦值,造成中斷,b完成賦值後,c繼續運行
a: 取->賦->寫
b: 取->賦->寫
c: X->取->賦->寫
d: X->取->賦->寫
指令重排就是減少中斷的一種技術,電腦為了優化程式的執行性能而對指令進行重新排序,使得執行代碼時不一定是按照代碼的順序執行
- 編譯器優化重排:編譯器在 不改變單線程程式語義 的前提下,可以重新安排語句的執行順序
- 指令並行重排:現代處理器採用了指令級並行技術來將多條指令重疊執行。如果 不存在數據依賴性,處理器可以改變語句對應的機器指令的執行順序
- 記憶體系統重排:不是真正意義上的重排序。由於主存和本地記憶體的數據同步存在時間差,導致同一時間點各個工作記憶體內看到的共用變數的值是不一致的,就好像記憶體訪問指令發生了重排序一樣
Java 源代碼會經歷編譯器優化重排、指令並行重排、記憶體系統重排的過程,最終才變成操作系統可執行的指令序列
# 依照上面的例子,先對變數d進行賦值,再執行c=a+b
# 對c和d的結果沒有影響,且提高了流水線的效率
a: 取->賦->寫
b: 取->賦->寫
d: 取->賦->寫
c: 取->賦->寫
指令重排提高了 CPU 的執行性能,但卻導致了指令亂序的問題。當然並不是說指令能任意重排,處理器必須能正確處理指令依賴情況保障程式能得出正確的執行結果。比如說上面的例子,變數 c 得依賴變數 a、 b,所以變數 a、b 與變數 c 之間的順序不能重排,而變數 d 不依賴於其他變數,所以他就可以重排,同理 a、b 之間也可以重排,只要保證他們的順序在變數 c 之前執行即可。所以在同一個處理器中,重排序過的代碼看起來依然是有序的
- as-if-serial 語義:所有的動作都可以為了優化而被重排序,但是必須保證它們重排序後的結果和程式代碼本身的應有結果是一致的
指令重排可以保證串列語義一致,但是沒有義務保證多線程間的語義也一致。所以在多線程下,指令重排序可能會導致一些問題
3.2.2 volatile 禁止指令重排序原理
JVM 通過記憶體屏障(Memory Barrier,或記憶體柵欄 Memory Fence)禁止 CPU 的指令重排序。記憶體屏障是一種 CPU 指令
- 阻止屏障兩側的指令重排序
- 強制把寫緩衝區/高速緩存中的臟數據等寫回主記憶體,或者讓緩存中相應的數據失效
編譯器在生成位元組碼時,會在指令序列中插入記憶體屏障來禁止特定類型的處理器重排序。編譯器選擇了一個比較保守的 JMM 記憶體屏障插入策略,這樣可以保證在任何處理器平臺,任何程式中都能得到正確的 volatile 記憶體語義
記憶體屏障分類
# LoadLoad:確保之前的讀取操作要先於之後的讀取完畢
# 在Load2被讀取前,要確保Load1已被讀取完畢
Load1;LoadLoad;Load2;
# StoreStore:確保之前的寫入操作先於之後的對其他處理器可見
# 在Store2寫入操作執行前,要確保Store1的寫入操作已對其他處理器可見
Store1;StoreStore;Store2;
# LoadStore:確保之前的讀取操作先於之後的寫入操作對其他處理器可見
# 在Store2被刷出前,要確保Load1已被讀取完畢
Load1;LoadStore;Store2;
# StoreLoad:確保之前的寫入操作先於之後的讀取操作對其他處理器可見
# 在Load2被讀取前,要確保Store1已對所有處理器可見
Store1;StoreLoad;Load2;
- StoreLoad 屏障開銷最大,在大多數處理器的實現中,這個屏障是個萬能屏障,兼具其它三種記憶體屏障的功能
重排序規則
| 是否能重排序 | 第二個操作 | ||
|---|---|---|---|
| 第一個操作 | 普通讀 / 寫 | volatile 讀 | volatile 寫 |
| 普通讀 / 寫 | NO | ||
| volatile 讀 | NO | NO | NO |
| volatile 寫 | NO | NO | |
- 如果第一個操作是 volatile 讀,那無論第二個操作是什麼,都不能重排序
- 如果第二個操作是 volatile 寫,那無論第一個操作是什麼,都不能重排序
- 如果第一個操作是 volatile 寫,第二個操作是 volatile 讀,那不能重排序
4. 針對 long 和 double 型變數的特殊規則
Java 記憶體模型要求 lock、unlock、read、load、assign、use、store、write 這八種操作都具有原子性,但是對於 64 位的數據類型(long 和 double),在模型中特別定義了一條寬鬆的規定:允許虛擬機將沒有被 volatile 修飾的 64 位數據的讀寫操作劃分為兩次 32 位的操作來進行,即允許虛擬機實現自行選擇是否要保證 64 位數據類型的 load、store、read 和 write 這四個操作的原子性,這就是所謂的 long 和 double 的非原子性協定(Non-Atomic Treatment of double and long Variables)
如果有多個線程共用一個並未聲明為 volatile 的 long 或 double 類型的變數,並且同時對它們進行讀取和修改操作,那麼某些線程可能會讀取到一個既不是原值,也不是其他線程修改值的代表了半個變數的數值,不過這種讀取到半個變數的情況是非常罕見的
5. 原子性、可見性與有序性
5.1 原子性(Atomicity)
一個操作或者多個操作要麼全部執行且執行的過程不會被任何因素打斷,要麼都不執行
由 Java 記憶體模型來直接保證的原子性變數操作包括 read、load、assign、use、store 和 write,可以大致的認為基本數據類型的讀寫都是具備原子性的
如果應用場景需要一個更大範圍的原子性保證,Java 記憶體模型還提供了 lock 和 unlock 操作來滿足這種需求,儘管虛擬機未把 lock 和 unlock 操作直接開放給用戶使用,但是卻提供了更高層次的位元組碼指令 monitorenter 和 monitorexit 來隱式地使用這兩個操作。這兩個位元組碼指令反映到 Java 代碼中就是同步塊,synchronized 關鍵字,因此在 synchronized 塊之間的操作也具備原子性
5.2 可見性(Visibility)
當一個線程修改了共用變數的值時,其他線程能夠立即得知這個修改
Java 記憶體模型通過在變數修改後將新值同步回主內
存,在變數讀取前從主記憶體刷新變數值這種依賴主記憶體作為傳遞媒介的方式來實現可見性的,無論是普通變數還是 volatile 變數都是如此
普通變數與 volatile 變數的區別是,volatile 的特殊規則保證了新值能立即同步到主記憶體,以及每次使用前立即從主記憶體刷新。因此可以說 volatile 保證了多線程操作時變數的可見性,而普通變數則不能保證這一點
除了 volatile 之外,Java 還有兩個關鍵字能實現可見性,它們是 synchronized 和 final
- synchronized:對一個變數執行 unlock 操作之前,必須先把此變數同步回主記憶體中(執行 store、write 操作)
- final:被 final 修飾的欄位在構造器中一旦被初始化完成,且沒有對象逸出(對象未初始化完成就可以被別的線程使用),那麼對於其他線程都是可見的
5.3 有序性(Ordering)
如果在本線程內觀察,所有的操作都是有序的;如果在一個線程中觀察另一個線程,所有的操作都是無序的。前半句是指線程內似表現為串列的語義(As-If-Serial),後半句是指指令重排序現象和工作記憶體與主記憶體同步延遲現象
Java 語言提供了 volatile 和 synchronized 兩個關鍵字來保證線程之間操作的有序性,volatile 關鍵字本身就包含了禁止指令重排序的語義,而 synchronized 則是由一個變數在同一個時刻只允許一條線程對其進行 lock 操作這條規則獲得的,這個規則決定了持有同一個鎖的兩個同步塊只能串列地進入
6. 先行發生原則
如果 Java 記憶體模型中所有的有序性都僅靠 volatile 和 synchronized 來完成,那麼有很多操作都將會變得非常啰嗦,但是我們在編寫 Java 併發代碼的時候並沒有察覺到這一點,這是因為 Java 語言中有一個先行發生(Happens-Before)的原則
- 程式員需要 JMM 提供一個強的記憶體模型來編寫代碼;編譯器和處理器希望 JMM 的約束越弱越好,這樣它們就可以最可能多的做優化來提高性能
- 對於會改變程式執行結果的重排序,JMM 要求編譯器和處理器必須禁止這種重排序
6.1 規則
- 如果一個操作 happens-before 另一個操作,那麼第一個操作的執行結果將對第二個操作可見,並且第一個操作的執行順序排在第二個操作之前
- 兩個操作之間存在 happens-before 關係,並不意味著 Java 平臺的具體實現必須要按照 happens-before 關係指定的順序來執行。如果重排序之後的執行結果,與按 happens-before 關係來執行的結果一致,那麼 JMM 也允許這樣的重排序
# 只要保證A、B happens-before C,A和B就可以進行重排序
A happens-before C
B happens-before C
6.2 天然的先行發生原則
對於程式員來說,自然不想要太過於關註底層實現,只要按照以下規則編寫代碼,就能保證操作間的強可見性
- 程式次序規則:在一個線程內,按照控制流順序,書寫在前面的操作先行發生於書寫在後面的操作
- 管程鎖定規則:一個 unlock 操作先行發生於後面對同一個鎖的 lock 操作
- volatile 變數規則:對一個 volatile 變數的寫操作先行發生於後面對這個變數的讀操作
- 對象終結規則:一個對象的初始化完成(構造函數執行結束)先行發生於它的 finalize 方法的開始
- 傳遞性:如果操作 A 先行發生於操作 B,操作 B 先行發生於操作 C,那就可以得出操作 A 先行發生於操作 C 的結論
- 線程啟動規則:Thread 對象的 start 方法先行發生於此線程的每一個動作
- 線程終止規則:線程中的所有操作都先行發生於對此線程的終止檢測
- 線程中斷規則:對線程 interrupt 方法的調用先行發生於被中斷線程的代碼檢測到中斷事件的發生

