
馬哥原創:用Python採集小紅書評論,抓取欄位包含:筆記鏈接,頁碼,評論者昵稱,評論者id,評論者主頁鏈接,評論時間,評論IP屬地,評論點贊數,評論級別,評論內容。 ...
目錄
一、爬取目標
您好!我是@馬哥python說 ,一名10年程式猿。
我們繼續分享Python爬蟲的案例,今天爬取小紅書上指定筆記("巴勒斯坦"相關筆記)下的評論數據。
老規矩,先展示結果:
截圖1:
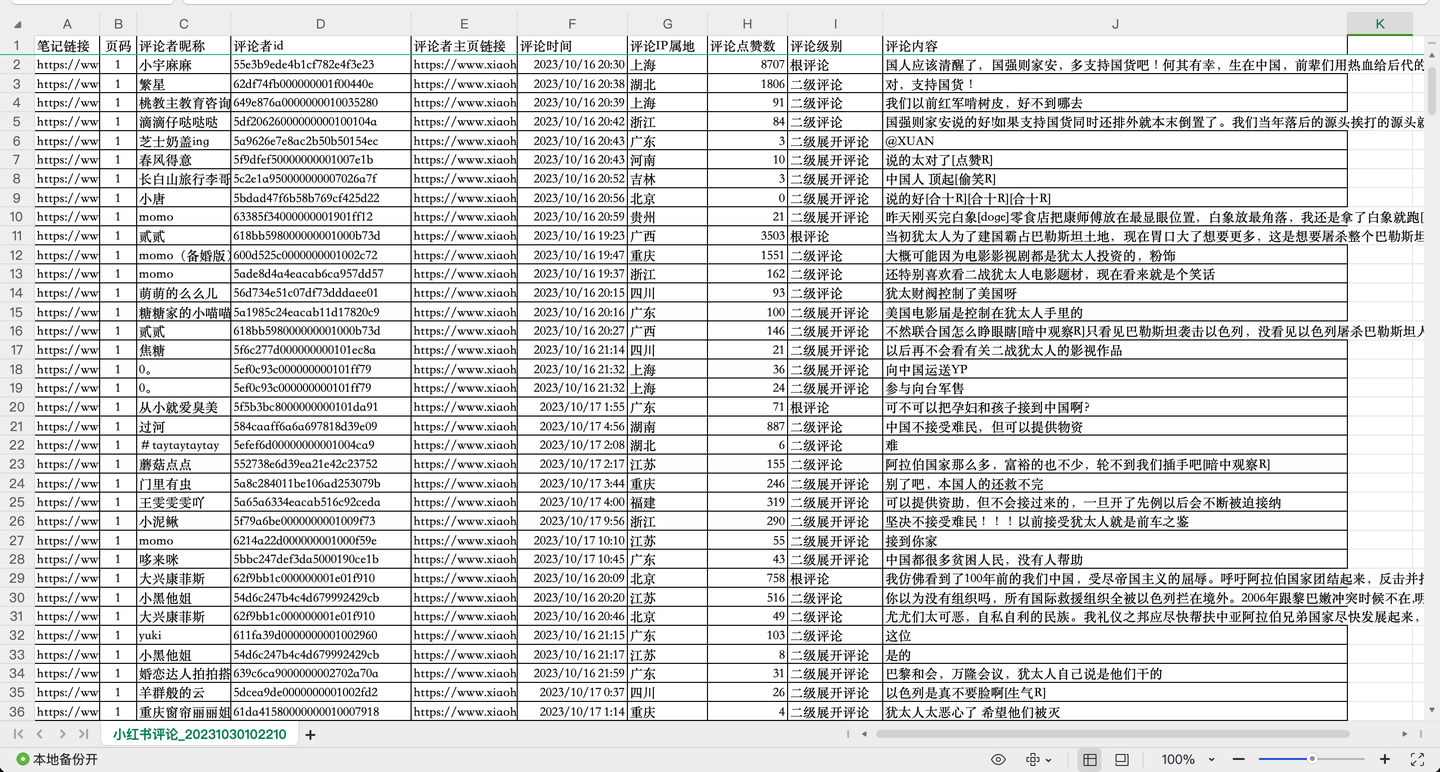
截圖2:
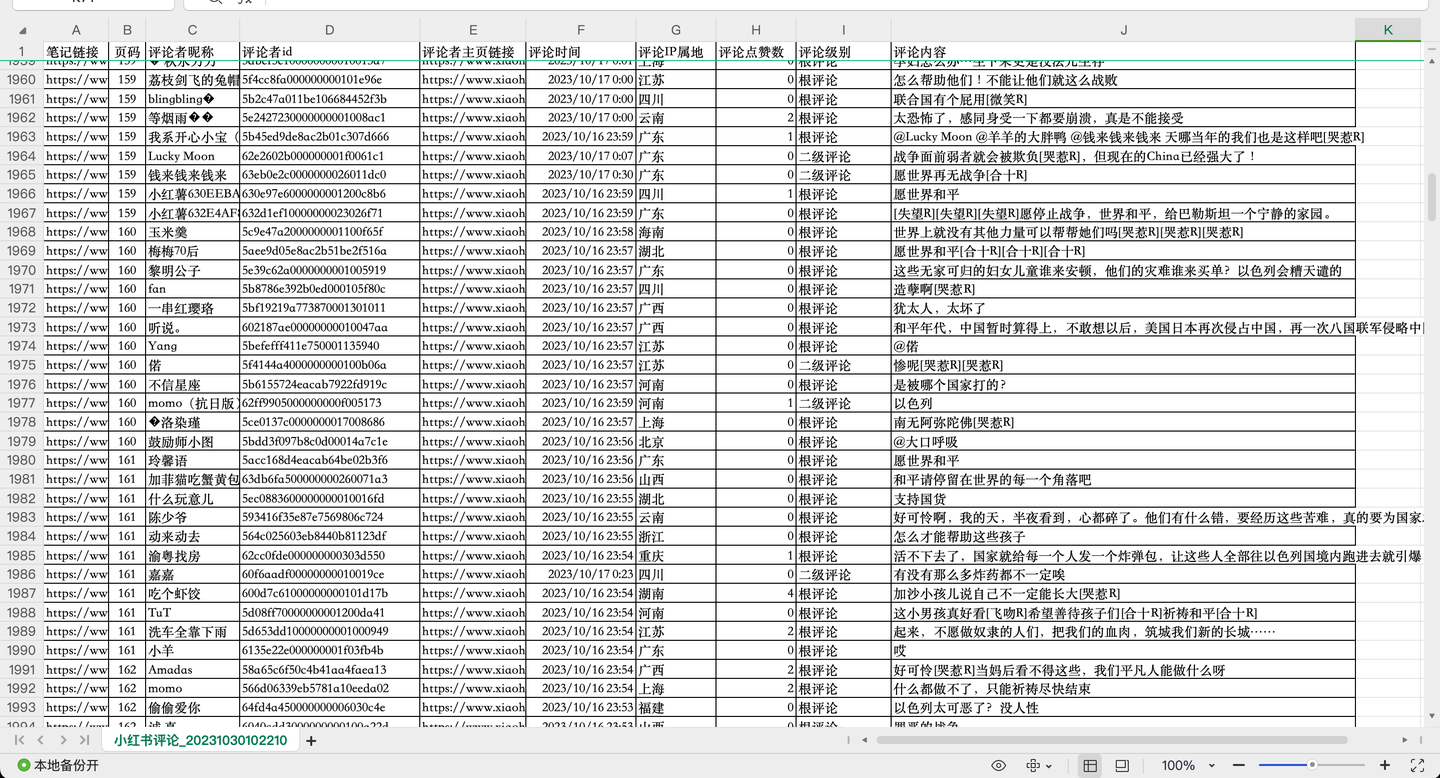
截圖3:
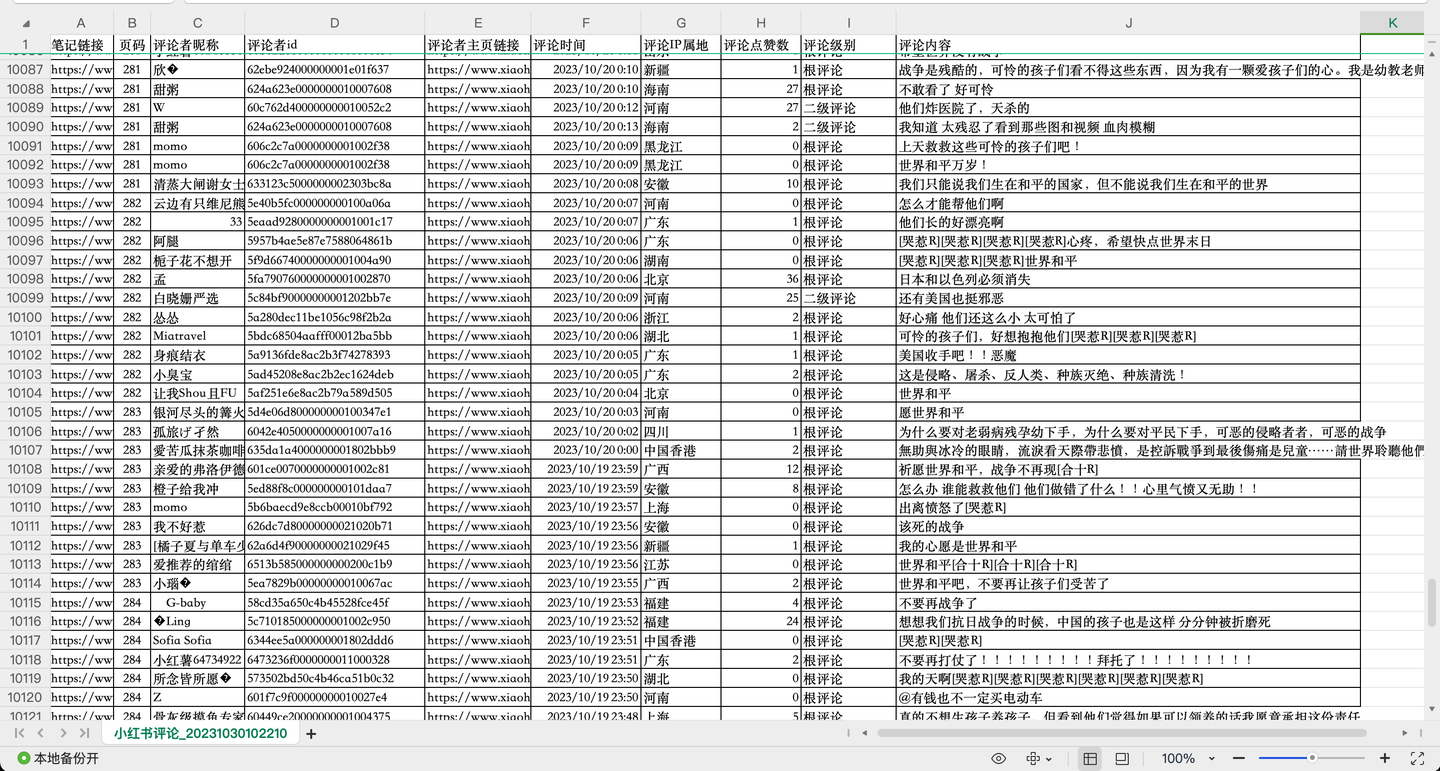
共爬取了1w多條"巴勒斯坦"相關評論,每條評論含10個關鍵欄位,包括:
筆記鏈接, 頁碼, 評論者昵稱, 評論者id, 評論者主頁鏈接, 評論時間, 評論IP屬地, 評論點贊數, 評論級別, 評論內容。
其中,評論級別包括:根評論、二級評論及二級展開評論。
二、爬蟲代碼講解
2.1 分析過程
任意打開一個小紅書筆記的評論,打開瀏覽器的開發者模式,網路,XHR,找到目標鏈接的預覽數據,如下:
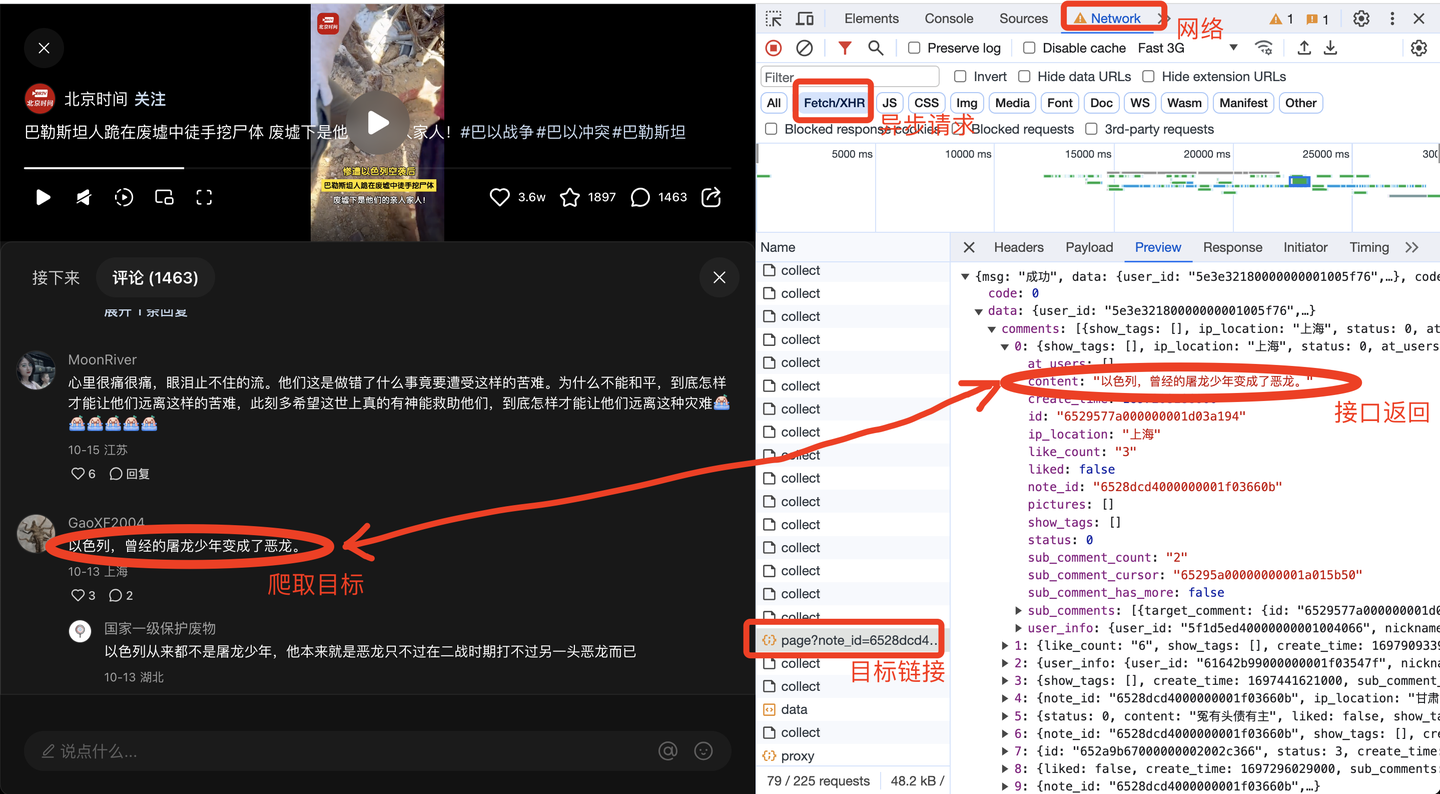
由此便得到了前端請求鏈接,下麵開始開發爬蟲代碼。
2.2 爬蟲代碼
首先,導入需要用到的庫:
import requests
from time import sleep
import pandas as pd
import os
import time
import datetime
import random
定義一個請求頭:
# 請求頭
h1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
# cookie需定期更換
'Cookie': '換成自己的cookie值',
}
經過我的實際測試,請求頭包含User-Agent和Cookie這兩項,即可實現爬取。
其中,Cookie很關鍵,需要定期更換。那麼Cookie從哪裡獲得呢?方法如下:
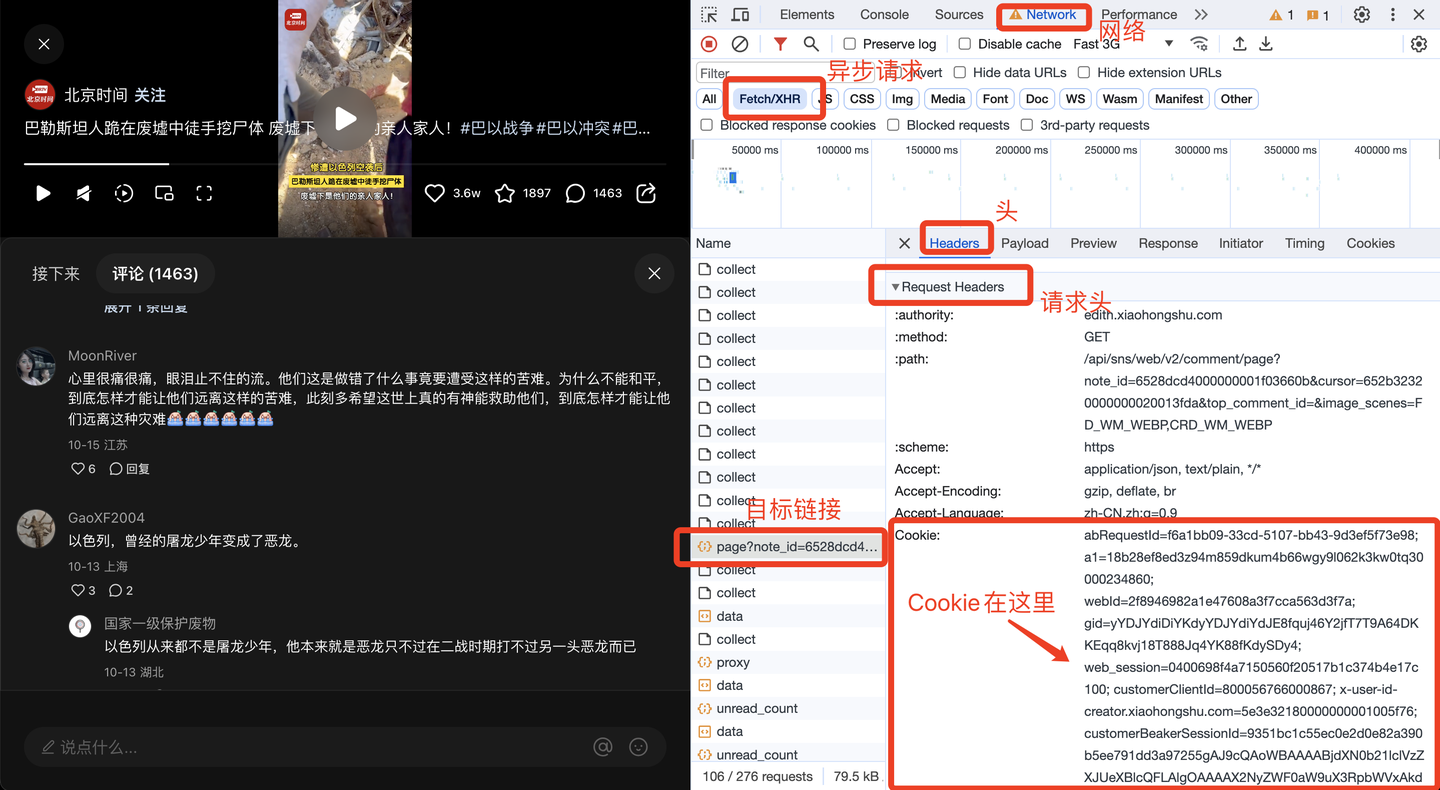
下麵,開發翻頁邏輯。
由於我並不知道一共有多少頁,往下翻多少次,所以採用while迴圈,直到觸發終止條件,迴圈才結束。
那麼怎麼定義終止條件呢?我註意到,在返回數據里有一個叫做"has_more"的參數,大膽猜測它的含義,是否有更多數據,正常情況它的值是true。如果它的值是false,代表沒有更多數據了,即到達最後一頁了,也就該終止迴圈了。
因此,核心代碼結構應該是這樣(以下是偽代碼,主要是表達邏輯,請勿直接copy):
while True:
# 發送請求
r = requests.get(url, headers=h1)
# 解析數據
json_data = r.json()
# 逐條解析
for c in json_data['data']['comments']:
# 評論內容
content = c['content']
content_list.append(content)
# 保存數據到csv
。。。
# 判斷終止條件
next_cursor = json_data['data']['cursor']
if not json_data['data']['has_more']:
print('沒有下一頁了,終止迴圈!')
break
page += 1
另外,還有一個關鍵問題,如何進行翻頁。
查看請求參數,如下:
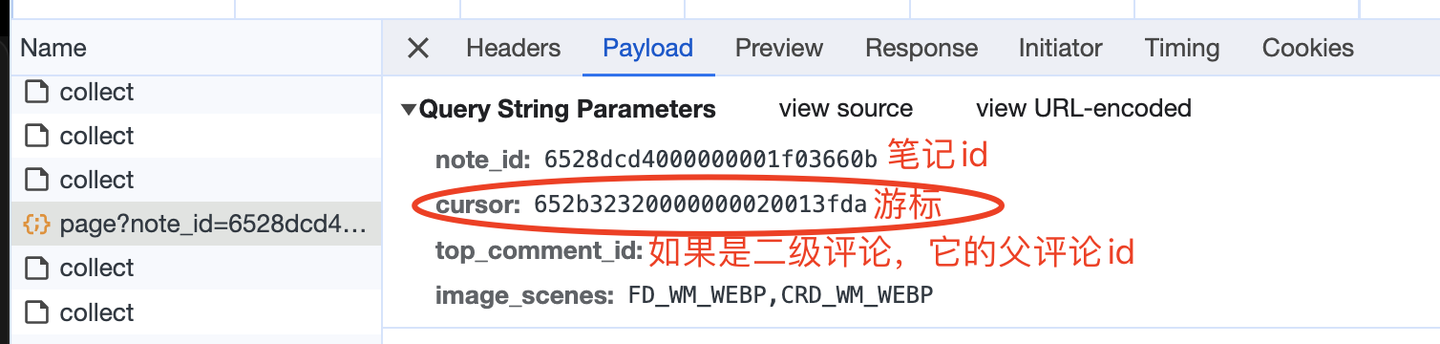
這裡的游標,就是向下翻頁的依據,因為每次請求的返回數據中,也有一個cursor:
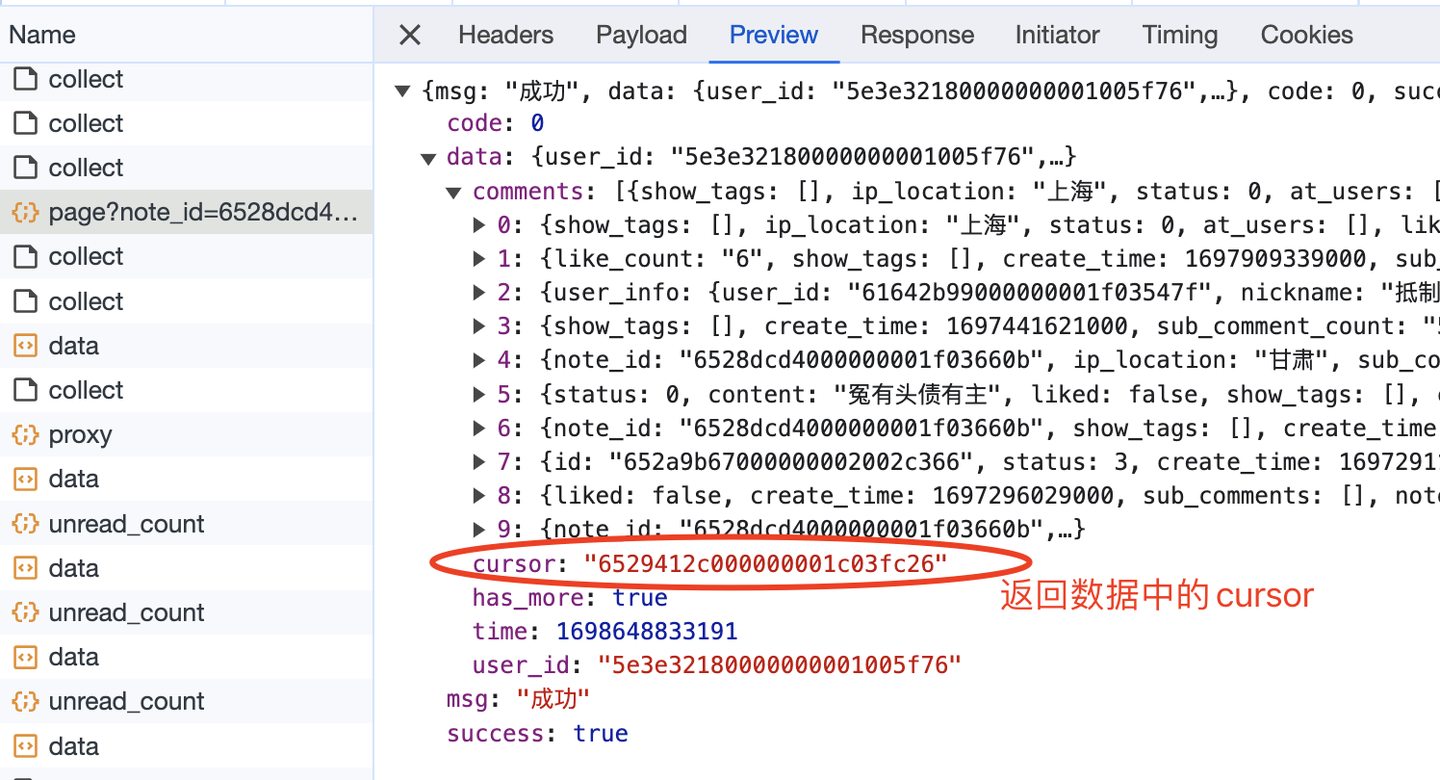
大膽猜測,返回數據中的cursor,就是給下一頁請求用的cursor,所以,這部分的邏輯實現應該如下(以下是偽代碼,主要是表達邏輯,請勿直接copy):
while True:
if page == 1:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP'.format(
note_id)
else:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP&cursor={}'.format(
note_id, next_cursor)
# 發送請求
r = requests.get(url, headers=h1)
# 解析數據
json_data = r.json()
# 得到下一頁的游標
next_cursor = json_data['data']['cursor']
另外,我在第一章節提到,還爬到了二級評論及二級展開評論,怎麼做到的呢?
經過分析,返回數據中有個節點sub_comment_count代表子評論數量,如果大於0代表該評論有子評論,進而可以從sub_comments節點中爬取二級評論。
其中,二級展開評論,請求參數中的root_comment_id代表父評論的id,其他邏輯同理,不再贅述。
最後,是順理成章的保存csv數據:
# 保存數據到DF
df = pd.DataFrame(
{
'筆記鏈接': 'https://www.xiaohongshu.com/explore/' + note_id,
'頁碼': page,
'評論者昵稱': nickname_list,
'評論者id': user_id_list,
'評論者主頁鏈接': user_link_list,
'評論時間': create_time_list,
'評論IP屬地': ip_list,
'評論點贊數': like_count_list,
'評論級別': comment_level_list,
'評論內容': content_list,
}
)
# 設置csv文件表頭
if os.path.exists(result_file):
header = False
else:
header = True
# 保存到csv
df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')
至此,爬蟲代碼開發完畢。
完整代碼中,還包含轉換時間戳、隨機等待時長、解析其他欄位、保存Dataframe數據、多個筆記同時迴圈爬取等關鍵邏輯,詳見演示視頻。
三、演示視頻
代碼演示:【Python爬蟲】用python爬了10000條小紅書評論,以#巴勒斯坦#為例
四、獲取完整源碼
get完整源碼:【爬蟲實戰】用Python採集任意小紅書筆記下的評論,爬了10000多條,含二級評論!
我是@馬哥python說,一名10年程式猿,持續分享python乾貨中!


