
本文主要介紹了筆者的一次flask後端開發的項目實踐中的功能實現,包括文件讀寫、數據讀取、遠程ssh連接、命令行執行、多線程操作等。 ...
Flask後端開發(二) - 功能實現和項目總結
目錄前情回顧
Flask後端開發(一)-基礎知識和前期準備
1. 功能1:修改文件參數值
針對文件參數值的修改,具體流程如下:
- 前端接收用戶修改的數據,傳遞給後端;
- 後端介面接收數據之後,讀取對應文件;
- 定位修改位置,替換數據;
- 返回修改結果給前端。
1.1. 獲取網頁端傳參
前端傳遞參數的方式有兩種,一種是GET,一種是POST,具體可參考Flask後端開發(一)-基礎知識和前期準備
後端接收數據主要使用flask中的request模塊,具體代碼如下:
#包導入
from flask import request
#前後端協商好傳遞數據的名稱之後,後端根據參數名進行接收
if request.method == "POST":
userID= str(request.form.get("userID"))
elif request.method == "GET":
userID= str(request.args.get("userID"))
#如果需要額外處理,例如字元串"a,b,c"需要轉換為列表["a","b","c"],可以使用split函數
BSD= (request.form.get("BSD")).split(",")
#註:上述是代碼片段,而非完整代碼,一般後端接收數據寫在介面函數中
1.2. 讀取文件
1.2.1. 一般文件讀取方式
一般文件包括.txt、.c、.log等文件,其內容讀取主要使用python中file模塊的open函數,具體代碼如下:
path= "文件路徑"
with open(path, "r",encoding='utf8') as file:
file_content = file.read()
#整個文件內容存儲在file_content中
關於file模塊的具體使用,可參考我的這篇博客:【python技巧】文本文件的讀寫操作。
1.2.2. 特殊文件 —— mlx文件
本項目的一個特殊之處就是需要處理.mlx文件(實時腳本文件),這是matlab中的一種文件格式,其內容是二進位的,無法直接讀取。因此,在本文當中,解決方案是將.mlx文件手動轉換為.m文件,然後再讀取.m文件的內容(真的很笨蛋,但是有效)。
對於.m文件,則可以按照一般文件的讀取方式進行讀取。
1.2.3. 特殊文件 —— .xlx文件
本項目中還會涉及到表格文件的數據讀寫,這裡使用的是xlrd模塊,具體代碼如下:
#包導入
import xlrd
#查找對應文件內容
file_path="文件路徑"
#打開表格
wb = xlrd.open_workbook(file_path)
ws = wb.sheet_by_name('Sheet1')
#按行讀取,返回給前端一個行列表:
n_rows = ws.nrows#獲取行數
for i in range(2,n_rows):#按行讀取,進行篩選,第一行是表頭,第二行開始是數據
get_value=ws.cell(i,3).value#獲取第i行第3列的數據
1.3. 查找數據修改位置,替換數據
本項目的需求是修改文件中的對應參數,涉及很多代碼行的參數修改,因此,需要根據變數名查找相關位置。
- 定位
根據pytho字元串中的find函數查找變數名所在的位置,參考博客如下Python find()方法,具體代碼如下:
# 其中file_content是文件內容,變數名是需要查找的變數名
## 1. 調度類型
start_index_1 = file_content.find(
"simParameters.SchedulingType ="
)
end_index_1 = file_content.find(
"simParameters.NumUEs =",
start_index_1,
) # 這之間修改schedulingtype的取值
## 2. UESpeed
start_index_2 = file_content.find(
"simParameters.UESpeed =", end_index_1
)
end_index_2 = file_content.find(
"% Validate the UE positions",
start_index_2,
)
## 3. max_RB
start_index_3 = file_content.find(
"simParameters.NumRBs =", end_index_2
)
end_index_3 = file_content.find(
"simParameters.SCS =",
start_index_3,
)
## 4. SCS
start_index_4 = file_content.find(
"simParameters.SCS =", end_index_3
)
end_index_4 = file_content.find(
"simParameters.DLCarrierFreq =",
start_index_4,
)
這部分的下標定位情況,可參考我的此篇博客:【python技巧】替換文件中的某幾行
- 替換
在本項目中使用的全文替換,具體代碼結構如下:
# 1. 讀取文件
path = "文件路徑"
with open(path, "r",encoding='utf-8') as file:
file_content = file.read()
# 2. 定位
start_index_1 = file_content.find("simParameters.UEPosition =")
end_index_1 = file_content.find("simParameters.UESpeed =",start_index_1) # 這之間修改ue_position的取值
start_index_2 = file_content.find("simParameters.Position = ", end_index_1)
end_index_2 = file_content.find("csirsConfig = nrCSIRSConfig", start_index_2)
if (start_index_1 == -1 or end_index_1 == -1 or start_index_2 == -1 or end_index_1 == -1):
return jsonify({"Error": "找不到對應的參數位置"})
# 3.更新參數值
updated_content = (
file_content[:start_index_1]
+ "simParameters.UEPosition = "
+ str(UE_position)
+ ";\n")
updated_content += file_content[end_index_1:start_index_2]
updated_content += "simParameters.Position = "+str(gNB_position)+";% Position of gNB in (x,y,z) coordinates"
updated_content += file_content[end_index_2:]
# 4. 更新文件
if updated_content != "":
with open(path, "w",encoding="utf-8") as file:
file.write(updated_content)
msg = "成功改變相關文件參數\n"
return jsonify({"Sueecess": msg})
2. 功能2:讀取結果數據
2.1. 實時數據展示如何存儲相關數據?
本項目中matlab會使用作圖程式實時展示每個時隙的運行結果,但是這個作圖程式無法顯示在網頁端,因此,考慮將數據存儲在文件中,然後通過網頁端讀取文件中的數據,進行展示。
實時數據的存儲代碼需要手動添加,在matlab每次作圖調用的函數中添加如下matlab代碼:
date_str=datestr(now,31);
new_str = replace(date_str,' ','_');
new_str=replace(new_str,':','');#添加時間戳
filename=sprintf('./文件夾名/file_name_%s.mat',new_str);#定義文件存儲相對位置
save(filename,"需要存儲的變數名");#存儲變數
2.2. 讀取相關數據,整理、打包、傳遞
2.2.1. 讀取.mat文件
根據添加的代碼,將會得到若幹個.mat文件,需要讀取.mat文件的內容並整理成前端需要的格式。
在本文中,是定義一個文件夾名為A,每個時隙的實時數據存儲為一個.mat文件,文件名為file_name_時間戳.mat,因此需要讀取文件夾A下的所有.mat文件。
在python中讀取.mat文件的具體代碼如下:
#1.包導入
import os
import scipy.io as sio
#2. 讀取數據
file_list=os.listdir("./文件夾名/")#讀取文件夾下所有文件名稱,形成列表
list_1=[]
list_2=[]
for file in file_list:#遍歷文件列表
file_content= sio.loadmat(f"./文件夾/{file}")#讀取文件內容
#這裡的寫法是根據我的.mat文件結構來的,如果不一樣,需要根據自己的文件結構進行修改
list_1.append(file_content["之前存儲的變數名"][0].tolist())
list_2.append(file_content["之前存儲的變數名"][1].tolist())
#之後得到的list_1和list_2就是前端需要的數據
#3. 傳遞給前端
result={
"list_1或者其他變數名":list_1,
"list_2或者其他變數名":list_2,
}
return jsonify(result)#數據打包為json格式,傳遞給前端
2.2.2. 讀取.xlsx文件
在項目中,還需要讀取.xlsx文件,這裡使用的是xlrd模塊,具體代碼如下:
##包導入
import xlrd
# 1. 讀取文件
file_path="文件路徑"
#打開表格
wb = xlrd.open_workbook(file_path)
ws = wb.sheet_by_name('Sheet1')
#數據讀取
list_1=[]
list_2=[]
n_rows = ws.nrows#獲取行數
for i in range(2,n_rows):#按行讀取,進行篩選
list_1.append(float(ws.cell(i,7).value))
list_2.append(float(ws.cell(i,7).value))
#之後得到的list_1和list_2就是前端需要的數據
#3. 傳遞給前端
result={
"list_1或者其他變數名":list_1,
"list_2或者其他變數名":list_2,
}
return jsonify(result)#數據打包為json格式,傳遞給前端
2.2.3. 讀取.txt/.log文件
在項目中,還需要讀取某些文本文件,例如日誌文件存儲的相關數據,這裡使用的是file模塊,具體數據讀取需要用到正則表達式相關知識,可參考博客【python技巧】文本處理-re庫字元匹配,具體代碼如下:
##方式1:要查找的內容為:“serveraddr = xxx",需要提取xxx
path= "文件路徑"
with open(path, "r") as file:
for line in file:
if "serveraddr" in line:
serveraddr_match = re.search(r'serveraddr\s*=\s*"([^"]+)"', line)
serveraddr = serveraddr_match.group(1) if serveraddr_match else ""
elif "serverport" in line:
serverport_match = re.search(r'serverport\s*=\s*"(\d+)"', line)
serverport = (
int(serverport_match.group(1)) if serverport_match else 0
)
##方式2:要查找的內容為:“itemxx: 數據1;數據2;數據3;”,需要提取xxx
path= "文件路徑"
with open(path, "r") as file:
lines = file.readlines() # 一次讀取並存入lines中,行列表
for line in lines: # 查找lines中包含item的行
if item in line: # 待查找的條目,提取關鍵數據
line = line.strip("\n") # 去掉換行符
dataInOneLine = line.split(";") # 分割數據
dataInOneLine[0] = dataInOneLine[0].split(":")[1] # 去掉item部分
for i in range(0, len(dataInOneLine)): # 去掉空格
dataInOneLine[i] = dataInOneLine[i].strip()
break # 找到目標行,跳出迴圈
# 行遍歷完成,得到行遍歷結果dataInOneLine列表,存儲關鍵數據
line_content_list = {
"itemName": item,
"數據項1": dataInOneLine[0],
"數據項2": dataInOneLine[1],
"數據項3": dataInOneLine[2],
}
# 將字典存入result_list,result_list中存儲多條目的關鍵數據
result_list.append(line_content_list)
3. 功能3:運行liunx命令行
這是本項目較難的一個功能點,需要使用python程式連接伺服器,然後執行liunx命令,運行編譯指令和matlab代碼,並且需要將liunx命令的輸出結果實時返回給前端。
3.1. 遠程連接伺服器
遠程伺服器連接使用的是paramiko模塊,先使用pip install paramiko下載模塊,具體代碼如下:
import paramiko
#創建ssh連接,可以復用的公共函數
def create_ssh_client(ip, port, username, password):
ssh_client = paramiko.SSHClient()
ssh_client.load_system_host_keys()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh_client.connect(ip, port, username, password)#連接伺服器
return ssh_client
#調用方式:
gnb_ssh_client = create_ssh_client(gnb_ip, gnb_port, gnb_username, gnb_password)
ue_ssh_client = create_ssh_client(ue_ip, ue_port, ue_username, ue_password)
【註意事項】:為了避免之後命令行執行可能存在的許可權問題和密碼輸入問題,推薦使用root身份進行ssh連接。
3.2. 執行liunx命令
一般來說,使用paramiko的invoke_shell函數,然後使用send函數發送命令,使用recv函數接收命令執行結果,具體代碼如下:
import paramiko
def execute_command(ssh_client, command, output_lines):
channel = ssh_client.invoke_shell()
channel.send(command + '\n')
while not channel.exit_status_ready():
time.sleep(1)
而關於command的具體寫法,這裡我簡單介紹一下:
- 單行命令:
直接字元串賦值即可:
cmd="cd /home'
- 多行命令:
cmd1="cd /home"
cmd2="ls"
cmd3="其他指令"
cmd=cmd1+";"+cmd2+";"+cmd3+"\n"#這樣拼接之後,一次性發送給伺服器就能按順序執行多條命令
- 特殊命令——matlab腳本文件運行
pyhton文件通過遠程伺服器連接執行matlab腳本文件,這裡使用的是matlab -r命令,具體命令如下:
cmd="cd 腳本文件對應文件夾"+";"+"matlab -nodesktop -nosplash -r 腳本文件名,不需要帶.m尾碼"
- 特殊命令——伺服器文件複製
在伺服器A的命令端,需要複製得到伺服器B的相關文件,這裡使用的是scp命令,具體命令如下:
cmd="sshpass -p 伺服器B的密碼 scp -P 伺服器B的埠 root@伺服器B的IP:伺服器內的文件路徑(例如 /home/user/copy_file.txt) 想要複製在伺服器A中的文件位置,例如`/home/user/`"
#sshpass是為了避免scp命令需要輸入密碼,這裡直接將密碼寫在命令中
- 特殊命令——文件許可權修改
在伺服器A的命令端修改相關文件許可權,從而能夠被讀寫,這裡使用的是chmod命令,具體命令如下:
cmd="chmod 777 文件路徑"
3.3. 多線程執行
為了實現下文的實時讀取輸出和隨時終止命令,都需要使用多線程方式,從而讓終端在執行命令行的時候,還能夠接收python發送的新請求,返回終端信息或者執行終止操作。
實現多線程需要用到threading模塊,具體代碼如下:
#包導入
import threading
#全局變數定義
gnb_ssh_client = None
ue_ssh_client = None
gnb_output_lines = []
ue_output_lines = []
execution_in_progress = False # 用於標識執行是否正在進行中
@model_name.route("/start_process", methods=["POST"])
#需要非同步多線程的處理方式
def start_process():
global gnb_ssh_client, ue_ssh_client, execution_in_progress,gnb_output_lines,ue_output_lines
#前端傳遞參數
#cmd定義
#cmd拼接
gnb_command="("+cmd1_gnb+";"+cmd2_gnb+";)"
ue_command="(+"scp2ue_cmd_2+";"+cmd0_ue+";"+cmd1_ue+";"+cmd2_ue+";)"
#連接ssh
if gnb_ssh_client is None:
gnb_ssh_client = create_ssh_client(gnb_ip, gnb_port, gnb_username, gnb_password)
if ue_ssh_client is None:
ue_ssh_client = create_ssh_client(ue_ip, ue_port, ue_username, ue_password)
#執行命令
gnb_output_lines=[]#先清空命令行輸出
ue_output_lines=[]
gnb_thread = threading.Thread(target=execute_command, args=(gnb_ssh_client, gnb_command, gnb_output_lines, "gnb"))
ue_thread = threading.Thread(target=execute_command, args=(ue_ssh_client, ue_command, ue_output_lines, "ue"))
execution_in_progress = True
gnb_thread.start()
ue_thread.start()
return jsonify({"success": "Execution started.","execution_in_progress":execution_in_progress})
#ssh連接的公用函數
def create_ssh_client(ip, port, username, password):
ssh_client = paramiko.SSHClient()
ssh_client.load_system_host_keys()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh_client.connect(ip, port, username, password)
return ssh_client
#命令執行的公用函數:註意和前文的代碼區別,添加了多線程相關代碼
def execute_command(ssh_client, command, output_lines, identifier):
channel = ssh_client.invoke_shell()
output_thread = threading.Thread(target=get_output, args=(channel, output_lines, identifier))
output_thread.start()
channel.send(command + '\n')
while not channel.exit_status_ready():
time.sleep(1)
# 等待輸出線程完成
output_thread.join()
3.4. 實時讀取liunx命令的輸出數據
按照多線程的方式執行代碼之後,如何才能實時獲取命令行的輸出數據呢?
首先我們介紹一下整個命令行執行過程中,前後端所進行的操作:
- step1:
- 前端:發送命令行執行請求;
- 後端:調用命令行執行的介面(例如
/start_process) - 伺服器:建立ssh連接,執行命令行;
- step2:
- 前端:按照一定的時間間隔,發送數據請求;
- 後端:調用數據請求的介面(例如
/get_output) - 伺服器:繼續執行命令,命令行輸出數據被存儲在全局變數中;
- step3:
- 前端:發送終止命令行執行請求;
- 後端:調用終止命令行執行的介面(例如
/stop_process) - 伺服器:終止命令行執行,關閉ssh連接。
因此,此處的實時讀取命令行輸出數據,就是在step2中,前端按照一定的時間間隔,發送數據請求,後端調用數據請求的介面,返回命令行輸出數據。具體代碼如下:
@model_name.route('/get_output', methods=['POST', 'GET'])
def get_output():#讀取全局變數內容即可
global gnb_output_lines, ue_output_lines
gnb_output = "\n".join(gnb_output_lines)
ue_output = "\n".join(ue_output_lines)
return jsonify({
"gnb_output": gnb_output,
"ue_output": ue_output
})
def execute_command(ssh_client, command, output_lines, identifier):
channel = ssh_client.invoke_shell()
output_thread = threading.Thread(target=get_output, args=(channel, output_lines, identifier))#這一步是關鍵,將命令行輸出數據存儲在全局變數中
output_thread.start()
channel.send(command + '\n')
while not channel.exit_status_ready():
time.sleep(1)
# 等待輸出線程完成
output_thread.join()
def get_output(channel, output_lines, identifier):#核心代碼,將命令行執行的輸出數據存儲在全局變數中,需要和上文的`execute_command`函數配合使用
while not channel.exit_status_ready():
if channel.recv_ready():
output = channel.recv(1024).decode('utf-8')
lines = output.split('\n')
for line in lines:
if line.strip():
formatted_line = f"[{identifier}]:{line.strip()}"
#print(formatted_line)
output_lines.append(formatted_line)
3.5. 隨時終止liunx命令的執行
這個功能是為了避免指令執行無法自行終止,需要用戶手動選擇結束模擬。
在多線程的命令行執行中,前端發送請求,而後端在原有ssh連接的基礎上,發送終止命令,具體代碼如下:
@model_name.route('/stop_process', methods=['POST'])
def stop_process():
global gnb_ssh_client, ue_ssh_client, execution_in_progress
if not execution_in_progress:#如果沒有命令行執行,返回錯誤信息
return jsonify({"error": "No execution in progress.","execution_in_progress":execution_in_progress})
if ue_ssh_client is not None:#斷開ued的ssh連接
stop_execution(ue_ssh_client)
ue_ssh_client.close()
ue_ssh_client = None
if gnb_ssh_client is not None:#斷開gnb的ssh連接
stop_execution(gnb_ssh_client)
gnb_ssh_client.close()
gnb_ssh_client = None
execution_in_progress = False
return jsonify({"success": "Execution stopped.","execution_in_progress":execution_in_progress})
#終止指令執行的公用函數
def stop_execution(ssh_client):
ssh_client.invoke_shell().send('\x03') # 發送Ctrl+C來終止命令
4. 其他收穫
4.1. 異常處理
在後端程式執行過程中,可能會出現各種checked exeption,這類異常需要程式員進行捕獲,不然則會影響程式的運行,產生報錯,而這裡我們可以將這些異常捕獲之後,將信息作為返回值傳遞給前端,從而讓用戶知道程式運行成功與否。
具體代碼結構如下:
@model_name.route('/function_name', methods=['POST'])
def function_name():
try:
#程式運行代碼
except Exception as e:
return jsonify({"error": str(e)})
finally:
#程式運行結束後的代碼,例如return jsonify({"success": "Execution stopped."})
4.2 日誌生成
在上一篇博客中,我們提到了分模塊的flask項目結構,而日誌部分的處理,需要在主文件app.py中。添加如下代碼:
import logging
log_filename = 'app.log' # 日誌文件名
log_level = logging.DEBUG # 日誌級別
log_format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s' # 日誌格式
# 配置日誌
logging.basicConfig(filename=os.path.join(os.path.dirname(__file__), log_filename), level=log_level, format=log_format)
則可以在程式運行過程中,將日誌信息存儲在app.log文件中,相關報錯信息也會存儲在該文件中,方便程式員進行調試。
4.3 環境部署
當我們在本地進行程式開發之後,需要將程式部署到伺服器上,而遷移到伺服器上或者別人的電腦上,需要安裝相關的環境。在這種情況下,我們可以將自己開發用到的包進行打包,然後在伺服器上進行安裝,具體步驟如下:
- 將當前環境中的包信息存儲在requirements.txt文件中,存儲在當前文件夾目錄下
pip freeze > requirements.txt
- 將整個項目文件打包之後,其他人可使用如下命令進行安裝:
pip install -r requirements.txt
4.4. vscode遠程連接伺服器
當我們在伺服器上部署完項目代碼之後,可能會經過多次測試和調試,因此代碼會不斷被修改,且會被無數次的運行,如果每次都是本地修改+伺服器部署運行,實在有些不夠優雅,因此,我們可以試著把自己的本地編輯器連接到伺服器上,這樣就可以在本地進行伺服器端代碼的修改,然後直接在伺服器上運行,這樣就可以避免每次修改都需要部署的麻煩。
我在項目中使用的是vscode,具體步驟如下:
- 插件安裝:Remote-SSH
- 選擇新建遠程,輸入ssh連接信息
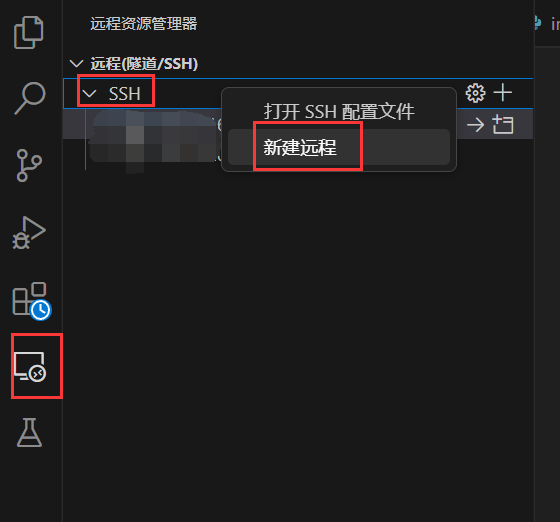

- 連接之後選擇想要編輯的項目文件夾,即可在本地編輯器中進行伺服器端代碼的修改;
- 調試的時候可使用vscode進行運行、部署;
具體的配置細節,可參考博客
5. 項目感受
- 項目的文件讀寫、伺服器連接等都是非常有趣的功能,多線程解決實時輸出算是一個較大的技術難點;
- 項目本身難度不大,主要難點在於理解業務本身,如果有相對應的業務文檔,可能開發效率會更高一點;
- 後端開發部分也需要瞭解基本的前端知識,例如前後端數據傳遞、前端頁面的渲染等,這樣才能更好的理解前端的需求,從而更好的進行後端開發;
- 項目對接需要良好的文檔編輯能力和溝通能力;
- 相關業務的具體實現,也是體現個人智慧的時刻,具體的開發技術和解決問題的智慧都是必不可少的,開發技術是工具,而我們需要用自己已有的工具去實現某些功能,這是一種思維方式,也是一種能力。,當然,技術會的越多,能用的工具越多,解決問題的思路就不會被限制;
- 總會有開發者不會的東西,這是一個學習的過程,重點在於不斷地學習,虛心請教和快速掌握。
6. 後記
如果覺得我寫得還算不錯,不妨點贊關註一波走起~
想看更多博文,請訪問我的各平臺主頁:博客園 / CSDN / 51CTO / 掘金論壇 / 知乎


