
集合概述 為了保存數量不確定的數據,以及保存具有映射關係的數據,Java 提供了集合類。集合類主要負責保存、盛裝其他數據,因此集合類也被稱為容器類。所有的集合都位於java.util包下 Java 的集合類主要由兩個介面派生而出:Collection和Map,Collection和Map 是 Jav ...
集合概述
為了保存數量不確定的數據,以及保存具有映射關係的數據,Java 提供了集合類。集合類主要負責保存、盛裝其他數據,因此集合類也被稱為容器類。所有的集合都位於java.util包下
Java 的集合類主要由兩個介面派生而出:Collection和Map,Collection和Map 是 Java 集合框架的根介面,這兩個介面又包含了一些子介面或實現類
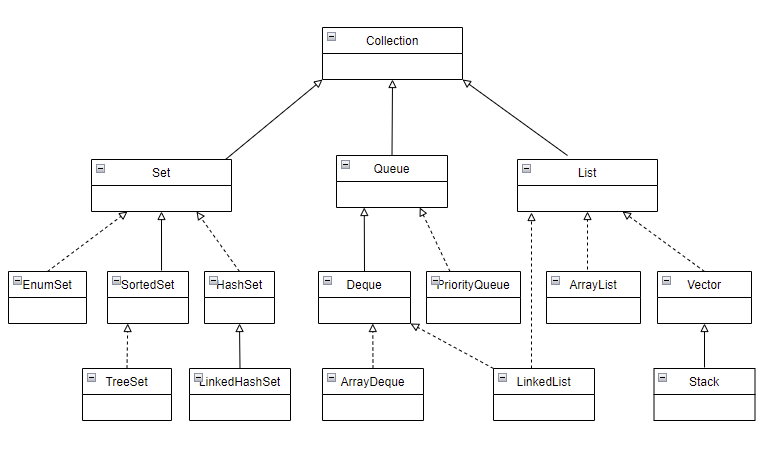
Collection 介面、子介面及其實現類的繼承樹
Map 繼承樹

Collection
Collection 介面是 List、Set 和 Queue 介面的父介面,該介面里定義的方法既可用於操作Set集合,也可用於操作 List 和 Queue 集合。
常用方法
boolean add(Object o)該方法用於向集合里添加一個元素,如果集合對象被改變了,則返回 trueboolean addAll(Colleaction c)把集合c 力的所有元素添加到指定集合里,如果集合對象被改變了,則返回 truevoid clear()清除集合里的所有元素, 將集合長度變為 0boolean contains(Object)返回集合里是否包含指定元素boolean containsAll(Collection c)返回集合里是否包含集合c 力的所有元素boolean isEmpty()返回集合是否為空Iterator iterator()返回一個Iterator對象,用於遍歷集合里的元素boolean remove(Object o)刪除集合中的指定元素 o,如果包含了一個或多個元素 o,只刪除第一個符合條件的元素boolean removeAll(Collection c)從集合中刪除集合 c 里包含的所有元素boolean retainAll(Collection c)從集合中上演出 集合c 里不包含的元素int size()該方法返回集合里元素的個數Object[] toArray()該方法把集合轉成一個數組,所有的集合元素變成對應的數組元素boolean removeIf(Predicate<? super E> filter)通過Lambda表達式 批量刪除符合filter條件的所有元素
集合遍歷
使用 Lambda 表達式遍歷集合
Java 8 為 Iterable 介面提供了一個 forEach(Consumer action) 預設方法, 該方法所需參數的類型是一個函數式介面, 而Iterable 介面是Collection 介面的父介面, 因此 Collection 集合也可直接調用該方法
Set books = new HashSet();
books.add("三國演義");
books.add("紅樓夢");
books.add("西游記");
books.add("水滸傳");
books.forEach(e -> {
System.out.println(e);
});
使用 Iterator 遍歷集合元素
Iterator 介面也是 Java 集合框架的成員,但它與Collection 系列、Map 系列的集合不一樣:Collection系列集合、Map 系列集合主要用於盛裝其他對象,而Iterator 則主要用於遍歷(即迭代訪問)Collection集合中的元素,Iterator 也被稱為迭代器
Iterator 介面里定義瞭如下4個方法
boolean hasNext()如果被迭代的集合元素還沒有被遍歷完,則返回trueObject next()返回集合里的下一個元素void remove()刪除集合里上一次next 方法返回的元素void forEachRemaining(Consumer action)使用 Lambda 表達式來遍歷集合元素(Java 8新增)
Set books = new HashSet();
books.add("三國演義");
books.add("紅樓夢");
books.add("西游記");
books.add("水滸傳");
// 獲取books 集合對應的迭代器
Iterator iterator = books.iterator();
while (iterator.hasNext()){
String book = (String) iterator.next();
System.out.println(book);
if(book.equals("紅樓夢")){
iterator.remove();
}
}
System.out.println(books);
當使用 Iterator 迭代訪問 Collection 集合元素時,Collection 集合里的元素不能被改變,只有通過 Iterator的
remove()方法刪除上一次next()方法返回的集合元素才可以; 否則將會引發java.util.ConcurrentModificationException異常
使用 Iterator 提供的forEachRemaining(Consumer action) 方法來遍歷
Java 8 為 Iterator 新增了一個forEachRemaining(Consumer action) 方法, 該方法所需的 Consumer 參數同樣也是函數式介面
iterator.forEachRemaining(obj -> {
System.out.println(obj);
});
使用 foreach 迴圈遍歷集合元素
for(Object book : books){
System.out.println(book);
}
Enumeration
Enumeration 介面時Iterator 迭代器的“古老版本”,從JDK 1.0 就已經存在了,此介面只有兩個方法
-
boolean hasMoreElements()如果此迭代器還有剩下的元素,則返回true -
Object nextElement()返回該迭代器的下一個元素,如果還有的話(否則拋出異常)
Enumeration 介面可用於遍歷Hashtable 、Vector,以及另一個極少使用的BitSet 等"古老"的集合類
public class EnumerationTest {
public static void main(String[] args) {
Vector vector = new Vector();
vector.add("三國演義");
vector.add("紅樓夢");
Hashtable scores = new Hashtable();
scores.put("語文",23);
scores.put("數學",33);
Enumeration vectorEnumeration = vector.elements();
while (vectorEnumeration.hasMoreElements()){
System.out.println(vectorEnumeration.nextElement());
}
Enumeration scoresEnumeration = scores.keys();
while (scoresEnumeration.hasMoreElements()){
Object key = scoresEnumeration.nextElement();
System.out.println(key + "-->" + scores.get(key));
}
}
}
輸出
三國演義
紅樓夢
語文-->23
數學-->33
Java 之所以要保留
Enumeration介面,主要是為了照顧以前那些“古老”的程式,因此如果現在編寫 Java 程式,應該儘量採用Iterator迭代器
使用 Stream 操作集合
Java 8新增了Stream、IntStream,LongStream,DoubleStream等流式API,這些API代表多個支持串列和並行聚集操作的元素
Java 8 還未上面每個流式 API 提供了對應的 Builder,例如 Stream.Builder、IntStream.Builder等,開發者可以通過這些Builder來創建對應的流
IntStream is = IntStream.builder()
.add(50)
.add(20)
.add(33)
.build();
System.out.println("is最大值:" + is.max().getAsInt());
System.out.println("is最小值:" + is.min().getAsInt());
System.out.println("is元素數量:" + is.count());
System.out.println("is平均值:" + is.average());
常用方法
Stream 提供了大量的方法進行聚集操作,這些方法既可以是”中間的“(intermediate),也可以是”末端的“(terminal)
- 中間方法:中間操作允許流保持打開狀態,並允許直接調用後續方法
- 末端方法:末端方法是對流的最終操作。當對某個Stream執行末端方法後,該流將會被”消耗“且不可再用
中間方法
filter(Predicate predicate)過濾 Stream 中所有不符合 predicate 的元素mapToXxx(ToXxxFunction mapper)使用ToXxxFunction對流中的元素執行一對一的轉換,該方法返回的新流中包含了ToXxxFunction轉生生成的所有元素peek(Consumer action)一次對每個元素執行一些操作,該方法返回的流與原有流包含相同的元素distinct()該方法用於排序流中所有重覆的元素(判斷重覆的標準是使用equals()比較)sorted()該方法用於保證流中的元素在後續訪問中處於有序狀態limit(long maxSize)該方法用於保證對該流的後續訪問中最大允許訪問的元素個數
末端方法
forEach(Consumer action)遍歷流中所有元素,對每個元素執行 actiontoArray()將流中所有元素轉換為一個數組reduce()合併流中的元素min()返迴流中的最小值max()返迴流中的最大值count()返迴流中的所有元素的數量anyMatch(Predicate predicate)判斷流中是否至少包含一個元素符合Predicate 條件allMatch(Predicate predicate)判斷流中是否每個元素都符合Predicate 條件noneMatch(Predicate predicate)判斷流中是否所有元素都不符合Predicate條件findFirst()返迴流中的第一個元素findAny()返迴流中的任意一個元素
操作集合
Collection 介面提供了一個stream()預設方法,該方法可返回該集合對應的流,可通過流式API來操作集合元素
Set books = new HashSet();
books.add("三國演義");
books.add("紅樓夢");
books.add("西游記");
books.add("水滸傳");
System.out.println("書名小於四個字的數量:" +
books.stream().filter(ele -> ((String) ele).length() < 4).count());
System.out.println("依次輸出各書的書名字數");
books.stream()
.mapToInt(ele -> ((String) ele).length())
.forEach(ele -> System.out.println(ele));
books.stream().forEach(ele -> System.out.println(ele));
書名小於四個字的數量:3
依次輸出各書的書名字數
3
4
3
3
水滸傳
三國演義
紅樓夢
西游記
Set 集合
Set 集合和 Collection 基本相同,沒有提供任何額外的方法,不同的是,Set集合不允許包含相同的元素,且通常不能記住元素的添加順序,如果嘗試添加相同的元素,add()方法將會返回false,且新元素不會被加入
HashSet 類
HashSet 是 Set 介面的典型實現,大多是時候使用 Set 集合時就是使用這個實現類。HashSet 按 Hash 演算法來存儲集合中的元素,因此具有很好的存取和查找性能
HashSet 具有以下特點
- 不能保證元素的排列順序
- HashSet 不是同步的,如果有多個線程同時修改HashSet集合,需通過代碼來保證同步
- 集合元素值可以時null
當向 HashSet 集合中存入一個元素時, HashSet 會調用該對象的 hashCode() 方法來得到該對象 hashCode值,然後根據該hashCode 值局的頂該對象在HashSet 中的存儲位置。如果有兩個元素通過equals() 方法比較返回true,但它們的hashCode() 方法返回值不相等,HashSet 將會把它們存儲在不同的位置,依然可以添加成功
就是說,HashSet 集合判斷兩個元素相等的標準是通過equals()和hashCode()方法來比較是否相等
public class A {
@Override
public boolean equals(Object obj) {
return true;
}
}
public class B {
@Override
public int hashCode() {
return 1;
}
}
public class C {
@Override
public int hashCode() {
return 2;
}
@Override
public boolean equals(Object obj) {
return true;
}
}
public class HashSetTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add(new A());
set.add(new A());
set.add(new B());
set.add(new B());
set.add(new C());
set.add(new C());
System.out.println(set);
}
}
輸出
[SetDemo.B@1, SetDemo.B@1, SetDemo.C@2, SetDemo.A@4554617c, SetDemo.A@1b6d3586]
因為兩個C對象
equals()和hashCode()返回總是一致,因此set集合中只添加了一次
LinkedHashSet 類
LinkedHashSet 是HashSet的子類,同樣根據hashCode 值來決定元素的存儲位置,但它同時使用鏈表維護元素的次序,因此當遍歷LinkedHashSet集合時,將會按照元素的添加順序來訪問集合里的元素
有序需要維護元素的插入順序,因此性能會略低HashSet的性能,但在迭代訪問時將有很好的性能,以為它以鏈表來維護內部順序
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet books = new LinkedHashSet();
books.add("三國演藝");
books.add("紅樓夢");
books.add("西游記");
books.add("水滸傳");
System.out.println(books);
}
}
[三國演藝, 紅樓夢, 西游記, 水滸傳]
TreeSet
TreeSet 是SortedSet介面的實現類,正如SortedSet名字所暗示的,TreeSet可以確保集合元素處於排序狀態。
與HashSet相比,TreeSet 還提供瞭如下幾個額外的方法
Comparator comparator()如果TreeSet採用了定製排序,則該方法返回定製排序所使用的Comparator; 如果TreeSet採用了自然排序,則返回nullObject first()返回集合中的第一個元素Object last()返回集合中的最後一個元素Object lower(Object e)返回集合小位於指定元素的元素中最接近指定元素的元素Object higher(Object e)返回集合中大於指定元素的元素中最接近指定元素的元素SortedSet subSet(Object fromElement, Object toElement)返回此Set的子集合範圍從fromElement(包含)到toElement(不包含)SortedSet headSet(Object toElement)返回此Set的子集,由小於toElement的元素組成SortedSet tailSet(Object fromElement)返回此Set的自己,由大於或等於fromElement的元素組成
public class TreeSetTest {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add(20);
set.add(30);
set.add(25);
set.add(2);
set.add(9);
System.out.println("輸出9-25區間的元素:" + set.subSet(9, 25));
System.out.println("輸出小於25的元素:" + set.headSet(25));
System.out.println("輸出小於10並最接近10的元素:" + set.lower(10));
System.out.println("輸出最後一位元素:" + set.last());
}
}
輸出
輸出9-25區間的元素:[9, 20]
輸出小於25的元素:[2, 9, 20]
輸出小於10並最接近10的元素:9
輸出最後一位元素:30
自然排序
TreeSet 會調用集合元素的compareTo(Object obj) 方法來比較元素之間的大小關係,然後將集合元素按升序排列,這種方式就是自然排序
自然排序中, TreeSet集合元素必須實現Comparable 介面。Java 的一些常用類已經實現了Comparable 介面,並提供了比較大小的標準。
BigDecimal、BigInteger以及所有的數值類型對應的包裝類 :按它們對應的數值大小進行比較Character按字元的Unicode值進行比較Booleantrue 大於 falseString依次比較字元串中每個字元的Unicode值Date、Time後面的時間、日期比前面的時間、日期大
大部分類在實現
compareTo(Object obj)方法時,都需要將被比較對象obj強制類型轉換成相同類型,如果希望TreeSet正常運轉,最好只添加同一種類型的對象
定製排序
如果需要實現定製排序,則需要在創建TreeSet 集合對象時,提供一個Comparator 對象與該TreeSet集合關聯,由該Comparator 對象負責集合元素的排序邏輯。由於Comparator 是一個函數式介面,因此可使用Lambda 表達式來代替Comparator 對象
public class M {
int age;
public M(int age) {
this.age = age;
}
@Override
public String toString() {
return "M [age:" + age + "]";
}
}
public class TreeSetCustomSortTest {
public static void main(String[] args) {
// age 越大,M對象越小
TreeSet set = new TreeSet(((o1, o2) -> {
M m1 = (M) o1;
M m2 = (M) o2;
return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0;
}));
set.add(new M(15));
set.add(new M(20));
set.add(new M(10));
set.add(new M(19));
System.out.println(set);
}
}
輸出
[M [age:20], M [age:19], M [age:15], M [age:10]]
EnumSet 類
EnumSet 時專門為枚舉設計的集合類,EnumSet 中的所有元素都必須是指定枚舉類型的枚舉值,該枚舉類型在創建EnumSet 時顯式或隱式地指定
EnumSet有以下特點
EnumSet的集合元素是有序的,EnumSet以枚舉值在Enum類內的定義順序來決定集合元素的順序EnumSet在內部以位向量的形式存儲,這種存儲方式非常緊湊、高效,因此EnumSet對象占用記憶體很小,而且運行效率很好EnumSet集合不允許接入null元素,如果試圖插入null元素,EnumSet將拋出NullPointerException異常
EnumSet沒有暴漏任何構造器來創建該類的實例,只能通過靜態方法來創建對象,EnumSet類提供瞭如下常用的靜態方法來創建EnumSet對象
EnumSet allOf(Class elementType)創建一個包含指定枚舉類里所有枚舉值的EnumSet集合EnumSet complementOf(EnumSet s)創建一個其元素類型與指定EnumSet里元素類型相同的EnumSet集合,新EnumSet集合包含原EnumSet集合所不包含的、此枚舉類剩下的枚舉值EnumSet copyOf(Collection c)使用一個普通集合來創建EnumSet集合EnumSet copyOf(EnumSet s)創建一個與指定EnumSet具有相同元素類型,相同元素集合元素的EnumSet集合EnumSet noneOf(Class elementType)創建一個元素類型為指定枚舉類型的空EnumSetEnumSet of(E first,E... rest)創建一個包含一個或多個枚舉值的EnumSet集合,傳入的多個枚舉值必須屬於同一個枚舉類EnumSet range(E from,E to)創建一個包含從from枚舉值到to枚舉值範圍內所有枚舉值的EnumSet集合
public class EnumSetTest {
public static void main(String[] args) {
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println("es1:" + es1);
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println("es2:" + es2);
es2.add(Season.FALL);
es2.add(Season.SPRING);
System.out.println("es2:" + es2);
EnumSet es3 = EnumSet.of(Season.SPRING,Season.FALL);
System.out.println("es3:" + es3);
EnumSet es4 = EnumSet.range(Season.SPRING,Season.FALL);
System.out.println("es4:" + es4);
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println("es5:" + es5);
EnumSet es6 = EnumSet.copyOf(es4);
System.out.println("es6:" + es6);
HashSet hashSet = new HashSet();
hashSet.add(Season.WINTER);
hashSet.add(Season.FALL);
EnumSet es7 = EnumSet.copyOf(hashSet);
System.out.println("es7:" + es7);
HashSet books = new HashSet();
books.add("三國演義");
books.add("紅樓夢");
EnumSet es8 = EnumSet.copyOf(books);
System.out.println("es8:" + es8);
}
}
es1:[SPRING, SUMMER, FALL, WINTER]
es2:[]
es2:[SPRING, FALL]
es3:[SPRING, FALL]
es4:[SPRING, SUMMER, FALL]
es5:[WINTER]
es6:[SPRING, SUMMER, FALL]
es7:[FALL, WINTER]
Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Enum
at java.util.EnumSet.copyOf(EnumSet.java:176)
at SetDemo.EnumSetTest.main(EnumSetTest.java:33)
各 Set 實現類的性能分析
TreeSet 需要額外的紅黑樹演算法來維護元素的次數,因此性能低於HashSet。只有需要一個保持排序的 Set時,才應該使用TreeSet
LinkedHashSet 是HashSet的子類,對於普通的插入,刪除操作,LinkedHashSet要比HashSet略微慢一點,這是由於維護鏈表所帶來的額外開銷造成的,但由於有了鏈表,遍歷LinkedHashSet 會更快
EnumSet 是所有 Set 實現類中性能最好的,但它只能保存同一個枚舉類的枚舉值作為集合元素
HashSet,TreeSet,EnumSet都是線程不安全的,如果有多線程同時操作該Set集合,則必須手動從代碼上保證Set集合的同步性
List 集合
List 集合代表一個元素有序、可重覆的集合,集合中的每個元素都有其對應的順序索引。List 集合允許使用重覆元素,可以通過索引來訪問指定位置的集合元素。 List 集合預設按元素的添加順序設置元素的索引
List 介面
List 作為 Collection 介面的子介面,可以使用 Collection 介面里的全部方法。由於List 是有序集合,因此 List 集合里增加了一些根據索引來操作集合元素的方法
add(int index, Object element)將元素element插入到List集合的index處boolean add(int index,Collection c)將集合c所包含的所有元素都插入到List集合的index處Object get(int index)返回集合index索引處的元素int indexOf(Object o)返回對象o在List集合中第一次出現的位置索引int lastIndexOf(Object)返回對象o在List集合中最後一次出現的位置索引Object remove(int index)刪除並返回index索引處的元素Object set(int index,Object element)將index索引處的元素替換成element對象, 返回被替換的舊元素List subList(int fromIndex,int toIndex)返回從索引fromIndex(包含)到索引toIndex(不包含)處所有集合元素組成的子集合
除此之外, Java 8 還為List添加瞭如下兩個預設方法
void replaceAll(UnaryOperator operator)根據operator指定的計算規則重新設置List 集合的所有元素void sort(Comparator c)根據Comparator 參數對List 集合的元素排序
public class ListTest {
public static void main(String[] args) {
List books = new ArrayList();
books.add("三國演義");
books.add("紅樓夢");
books.add("西游記");
for (int i = 0; i < books.size(); i++) {
System.out.println(books.get(i));
}
// 將 水滸傳 插入到索引為2的位置
books.add(2, "水滸傳");
System.out.println("books.add(2,\"水滸傳\"):" + books);
books.remove(3);
System.out.println("books.remove(3):" + books);
System.out.println("books.indexOf(new String(\"紅樓夢\")):" + books.indexOf(new String("紅樓夢")));
books.set(2, "朝花夕拾");
System.out.println("books.set(2,\"朝花夕拾\"):" + books);
System.out.println("books.subList(1, 2):" + books.subList(1, 2));
books.add("海底兩萬里");
books.add("鋼鐵是怎麼煉成的");
System.out.println(books);
// 根據書名長度排序
books.sort(((o1, o2) -> ((String) o1).length() - ((String) o2).length()));
System.out.println(books);
// 將集合元素全部替換為每個元素的字元長度
books.replaceAll(ele -> ((String)ele).length());
System.out.println(books);
}
}
輸出
三國演義
紅樓夢
西游記
books.add(2,"水滸傳"):[三國演義, 紅樓夢, 水滸傳, 西游記]
books.remove(3):[三國演義, 紅樓夢, 水滸傳]
books.indexOf(new String("紅樓夢")):1
books.set(2,"朝花夕拾"):[三國演義, 紅樓夢, 朝花夕拾]
books.subList(1, 2):[紅樓夢]
[三國演義, 紅樓夢, 朝花夕拾, 海底兩萬里, 鋼鐵是怎麼煉成的]
[紅樓夢, 三國演義, 朝花夕拾, 海底兩萬里, 鋼鐵是怎麼煉成的]
[3, 4, 4, 5, 8]
List 判斷兩個對象相等是通過
equals()方法進行判斷
List 除了iterator() 方法之外,還額外提供了listIterator() 方法,該方法返回一個ListIterator 對象,ListIterator 介面繼承了 Iterator 介面,提供了轉沒操作List的方法。 ListIterator 介面在Iterator 介面基礎上增加瞭如下的方法
boolean hasPrevious()返回該迭代器關聯的集合是否還有上一個元素Object previous()返回迭代器的上一個元素void add(Object o)在指定位置插入一個元素
public class ListIteratorTest {
public static void main(String[] args) {
List books = new ArrayList();
books.add("三國演義");
books.add("紅樓夢");
books.add("西游記");
ListIterator iterator = books.listIterator();
while (iterator.hasNext()){
String book = (String) iterator.next();
System.out.println(book);
if(book.equals("紅樓夢")){
iterator.add("水滸傳");
}
}
System.out.println("-----分割線-------");
while (iterator.hasPrevious()){
String book = (String) iterator.previous();
System.out.println(book);
}
}
}
輸出
三國演義
紅樓夢
西游記
-----分割線-------
西游記
水滸傳
紅樓夢
三國演義
ArrayList
ArrayList 是List的典型實現類,完全支持上面介紹的List 介面的全部功能
ArrayList 是基於數組實現的List 類,通過使用initialCapacity 參數來設置該數組的長度,當向ArrayList 添加元素超出數組的長度時,initialCapacity 會自動增加
通常無需關心initalCapacity,但如果要添加大量元素時,可使用ensureCapacity(int minCapacity)方法一次性增加initalCapacity。這樣可以減少重新分配次數,從而提高性能,如果一開就知道集合需要保存多少元素,則可以在創建時就通過ArrayList(int initialCapacity) 指定initalCapacity
除此之外ArrayList 還提供了void trimToSize() 方法,用於調整數組長度為當前元素的個數,可以減少集合對象占用的存儲空間
LinkedList
LinkedList 類是 List 介面的實現類,除此之外,LinkedList 還實現了Deque介面,可以被當成雙端隊列來使用,因此既可以被當成“棧” 來使用,也可以當成隊列來使。
public class LinkedListTest {
public static void main(String[] args) {
LinkedList books = new LinkedList();
// 將字元串元素即入隊列的尾部
books.offer("三國演義");
// 將一個字元串元素加入棧的頂部
books.push("西游記");
// 將字元串元素添加到隊列的頭部 相當於棧的頂部
books.offerFirst("朝花夕拾");
// 按索引訪問來遍歷元素
for (int i = 0; i < books.size(); i++) {
System.out.println("遍歷中:" + books.get(i));
}
// 訪問並不刪除頂棧的元素
System.out.println(books.peekFirst());
// 訪問並不刪除隊列的最後一個元素
System.out.println(books.peekLast());
// 將棧頂的元素彈出"棧"
System.out.println(books.pop());
System.out.println(books);
// 訪問並刪除隊列的最後一個元素
System.out.println(books.pollLast());
System.out.println(books);
}
}
輸出
遍歷中:朝花夕拾
遍歷中:西游記
遍歷中:三國演義
朝花夕拾
三國演義
朝花夕拾
[西游記, 三國演義]
三國演義
[西游記]
Vector
Vector 是一個古老的集合(從JDK1.0 就有了),在用法上和ArrayList 幾乎完全相同,同樣是基於數組實現的List類,Vector 具有很多缺點,通常儘量少用 Vector,這裡瞭解即可
與ArrayList 不同的是,Vector 是線程安全的,因此性能也低於ArrayList
public class VectorTest {
public static void main(String[] args) {
Vector books = new Vector();
books.add("三國演義");
// Vector 原有方法 與Add()一致
books.addElement("紅樓夢");
books.add("西游記");
for (int i = 0; i < books.size(); i++) {
System.out.println(books.get(i));
}
// 將 水滸傳 插入到索引為2的位置
books.add(2, "水滸傳");
System.out.println("books.add(2,\"水滸傳\"):" + books);
books.remove(3);
System.out.println("books.remove(3):" + books);
System.out.println("books.indexOf(new String(\"紅樓夢\")):" + books.indexOf(new String("紅樓夢")));
books.set(2, "朝花夕拾");
System.out.println("books.set(2,\"朝花夕拾\"):" + books);
System.out.println("books.subList(1, 2):" + books.subList(1, 2));
books.add("海底兩萬里");
books.add("鋼鐵是怎麼煉成的");
System.out.println(books);
// 根據書名長度排序
books.sort(((o1, o2) -> ((String) o1).length() - ((String) o2).length()));
System.out.println(books);
// 將集合元素全部替換為每個元素的字元長度
books.replaceAll(ele -> ((String)ele).length());
System.out.println(books);
}
}
輸出
三國演義
紅樓夢
西游記
books.add(2,"水滸傳"):[三國演義, 紅樓夢, 水滸傳, 西游記]
books.remove(3):[三國演義, 紅樓夢, 水滸傳]
books.indexOf(new String("紅樓夢")):1
books.set(2,"朝花夕拾"):[三國演義, 紅樓夢, 朝花夕拾]
books.subList(1, 2):[紅樓夢]
[三國演義, 紅樓夢, 朝花夕拾, 海底兩萬里, 鋼鐵是怎麼煉成的]
[紅樓夢, 三國演義, 朝花夕拾, 海底兩萬里, 鋼鐵是怎麼煉成的]
[3, 4, 4, 5, 8]
Vector 還提供了一個Stack 子類,用於模擬”棧“這種數據結構(後進先出)
Object peek()返回”棧“的第一個元素, 但並不將該元素”pop“ 出棧Object pop()返回”棧“的第一個元素, 並將該元素”pop“ 出棧Object push(Object item)將一個元素”push“進棧,最後一個進”棧“的元素總是位於”棧“頂
public class StackTest {
public static void main(String[] args) {
Stack stack = new Stack();
stack.push("張三");
stack.add("李四");
stack.add("王五");
stack.push("趙六");
System.out.println(stack);
System.out.println(stack.peek());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack);
}
}
輸出
[張三, 李四, 王五, 趙六]
趙六
[張三, 李四, 王五, 趙六]
趙六
[張三, 李四, 王五]
王五
[張三, 李四]
由於
Stack繼承了Vctor,因此它也是一個非常古老的Java 集合類,它同樣是線程安全的、性能較差的,因此應該儘量少用Stack類。 如果需要使用”棧“這種數據介面,建議使用ArrayDeque代替它
Queue 集合
Queue 用於模擬隊列這種數據結構,隊列通常指”先進先出“(FIFO)的容器。新元素插入(offer)到隊列的尾部,訪問元素(poll)操作會返回隊列頭部的元素。通常,隊列不允許隨機訪問隊列中的元素
Queue 介面中定義瞭如下幾個方法
void add(Object e)見通過指定元素加入此隊列的尾部Object element()獲取隊列頭部的元素,但是不刪除該元素boolean offer(Object e)將指定哦元素加入此隊列的尾部。當使用有容量限制的隊列時,此方法通常比add(Object e)好Object peek()獲取隊列頭部的元素, 但是不刪除該元素。 如果此隊列為空, 則返回nullObject poll()獲取隊列頭部的元素,並刪除該元素
PriorityQueue 實現類
PriorityQueue 是一個特殊隊列,即優先隊列。 優先隊列的作用是能保證每次取出的元素都是隊列中權值最小的。因此當調用peek() 方法或者poll() 方法取出隊列中的元素時,並不是取出最先進入隊列的元素,而是取出隊列中最小的元素
public class PriorityQueueTest {
public static void main(String[] args) {
PriorityQueue pq = new PriorityQueue();
pq.offer(20);
pq.offer(33);
pq.offer(15);
pq.offer(23);
for (int i = 0; i < 4; i++) {
System.out.println(pq.poll());
}
}
}
輸出
15
20
23
33
PriorityQueue 不允許插入 null 元素,它還需要對隊列元素進行排序,PriortyQueue 的元素有兩種排序方式
- 自然排序:採用自然順序的
PriorityQueue集合中的元素必須實現了Comparable介面,而且應該是同一個類的多個實例,否則可能導致ClassCastException異常 - 定製排序:創建
PriorityQueue隊列時,傳入一個Comparator對象,該對象負責對隊列中的所有元素進行排序。採用定製排序時不要求隊列元素實現Comparable介面
Deque 介面
Deque 介面時Queue 介面的子介面,它代表一個雙端隊列,Deque 介面里定義了一些雙端隊列的方法,這些方法允許從兩端來操作隊列的元素
void addFirst(Object e)將指定元素插入該雙端隊列的開頭void addLast(Object e)將指定元素插入該雙端隊列的末尾Iterator descendingIterator()返回該雙端隊列對應的迭代器,該迭代器將以你想順序來迭代隊列中的元素Object getFirst()獲取但不刪除雙端隊列的第一個元素Object getLast()獲取但不刪除雙端隊列的最後一個元素boolean offerFirst(Object e)將指定元素插入該雙端隊列的開頭boolean offerLast(Object e)將指定元素插入該雙端隊列的末尾Object peekFirst()獲取但不刪除該雙端隊列的第一個元素;如果此雙端隊列為空,則返回nullObject peekLast()獲取但不刪除該雙端隊列的最後一個元素;如果此雙端隊列為空,則返回nullObject pollFirst()獲取並刪除該雙端隊列的第一個元素;如果此雙端隊列為空,則返回nullObject pollLast()獲取並刪除該雙端隊列的最後一個元素;如果此雙端隊列為空,則返回nullObject pop()pop出雙對隊列所表示的棧的棧頂元素。相當於removeFirst()(棧方法)void push(Object e)將一個元素 push進該雙端隊列所表示的棧的棧頂 (棧方法)Object removeFirst()獲取並刪除該雙端隊列的第一個元素Object removeFirstOccurrence(Object o)刪除該雙端隊列的第一次出現的元素oObject removeLast()獲取並刪除該雙端隊列的最後一個元素boolean removeLastOccurrence(Object o)刪除該雙端隊列的最後一次出現的元素o
從以上方法可以看到,Deque 不僅可以當成雙端隊列使用,而且可以被當成棧來使用,因為該類里還包含了pop(出棧)、push(入棧) 兩個方法
ArrayDeque 類
ArrayDeque 是Deque的實現類,從名稱可以看出,它是一個基於數組實現的雙端隊列,創建Deque 時同樣可指定一個numElements 參數,該參數用於指定 Object[] 數組的長度;如果不指定,Deque底層數組的長度為16
將ArrayDeque 當作棧來使用
public class ArrayDequeStack {
public static void main(String[] args) {
ArrayDeque stack = new ArrayDeque();
stack.push("三國演義");
stack.push("西游記");
stack.push("朝花夕拾");
System.out.println(stack);
// 取隊列頭部的元素, 但是不刪除該元素
System.out.println(stack.peek());
// 出棧
System.out.println(stack.pop());
System.out.println(stack);
}
}
[朝花夕拾, 西游記, 三國演義]
朝花夕拾
朝花夕拾
[西游記, 三國演義]
將ArrayDeque 當作隊列來使用
public class ArrayDequeQueue {
public static void main(String[] args) {
ArrayDeque queue = new ArrayDeque();
queue.offer("三國演義");
queue.offer("西游記");
queue.offer("朝花夕拾");
System.out.println(queue);
// 取隊列頭部的元素, 但是不刪除該元素
System.out.println(queue.peek());
// poll 出第一個元素
System.out.println(queue.poll());
System.out.println(queue);
}
}
[三國演義, 西游記, 朝花夕拾]
三國演義
三國演義
[西游記, 朝花夕拾]
Map 集合
Map 用於保存具有映射關係的數據,因此Map 集合里保存著兩組值,一組用於保存Map 里的key,另外一組值用於保存Map里的value, Map 的 key 不允許重覆
key 和 value 之間存在單向一對一關係,即通過指定的key,總能找到唯一的、確定的value
Map 介面中定義瞭如下常用的方法
void clean()刪除該Map對象中所有的key-value對boolean containsKey(Object key)查詢Map中是否包含指定的key,如果包含則返回trueSet entrySet()返回Map中所包含的key-value所組成的Set集合,每個集合元素都是Map.Entry對象Object get(Object key)返回指定key所對應的value; 如果Map不包含此key,則返回nullboolean isEmpty()查詢該Map是否為空Set keySet返回該Map中所有key組成的Set集合Object put(Object key,Object value)添加一個key-value對,如果當前Map中已有一個與該key相等的key-value對,則新的key-value對會覆蓋原來key-value對void putAll(Map m)將指定Map中的key-value對複製到本Map中Object remove(Object key)刪除指定key所對應的key-value對,返回被刪除key所關聯的value,如果key不存在則返回nullboolean remove(Object key,Object value)刪除指定key、value所對應的key-value對,如果成功刪除,則返回true。(Java 8新增)int size()返回該Map里的key-value對的個數Collection values()返回該Map 里所有value組成的Collection
Map 中包括一個內部類Entry,該類封裝了一個key-value對。 Entry含有如下三個方法
Object getKey()返回該Entry里包含的key值Object getValue()返回該Entry里包含的value值Object setValue(V value)設置該Entry里包含的value值,並返回新設置的value值
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("三國演義", 25);
map.put("朝花夕拾", 33);
map.put("紅樓夢", 62);
// key重覆,會把value覆蓋上去而不是新增
map.put("紅樓夢", 99);
// 如果新value覆蓋了原有的value,該方法返回被覆蓋的value
System.out.println(map.put("朝花夕拾", 1));
System.out.println(map);
System.out.println("是否包含key為三國演義:" + map.containsKey("三國演義"));
System.out.println("是否包含值為99的value:" + map.containsValue(99));
// 遍歷map所有key集合
for (Object key : map.keySet()) {
System.out.println(key + "-->" + map.get(key));
}
// 根據key刪除key-value對
map.remove("三國演義");
System.out.println(map);
}
}
輸出
33
{三國演義=25, 紅樓夢=99, 朝花夕拾=1}
是否包含key為三國演義:true
是否包含值為99的value:true
三國演義-->25
紅樓夢-->99
朝花夕拾-->1
{紅樓夢=99, 朝花夕拾=1}
Java8 為 Map 新增的方法
Java 8除了為Map 增加了remove(Object key,Object value) 預設方法以外,還增加瞭如下方法
Object compute(Object key,BiFunction remappingFunction)該方法使用remappingFunction根據原key-value對計算一個新value。只要新value不為null,就使用新value覆蓋原value;如果原value不為null,但新value為null,則刪除原key-value對;如果原value新value都為null, 那麼該方法不改變任何key-value對,直接返回`null``Object computeIfAbsent(Object key, Function mappingFunction)如果傳給該方法的key參數在Map中對應的value為null,則使用mappingFunction根據key計算一個新的結果,如果計算結果不為null,則用計算結果覆蓋原有的value。如果原Map不包括該key,那麼該方法會添加一組key-value對;(如果key對應的value不為null,不做任何操作)Object computeIfPresent(Object key,Bifunction remappingFunction)如果傳給該方法的key參數在Map中對應的value不為null,該方法將使用remappingFunction根據原key、value計算一個新的結果,如果計算結果不為null,則使用該結果覆蓋原來的value;如果結算結果為null,則刪除原key-value對void forEach(BiConsumer action)可通過Lambda 遍歷key-value對Object getOrDefault(Object key,V defaultValue)獲取指定 key 對應的 value。如果key不存在,則返回defaultValueObject merge(Object key,Object value,BiFunction remappingFunction)該方法會現根據key 參數獲取該Map 中對應的value。如果獲取到的value為null,則直接用傳入的value覆蓋原有的value(如果key不存在,會添加一組key-value);如果獲取的value不為null,則使用remappingFunction函數根據原value,新value計算一個新的結果,並用得到的結果覆蓋原有的valueObjcet putIfAbsent(Object key,Object value)該方法會自動檢測指定key對應的value是否為null,如果該key對應的value為null,該方法將會用新value代替原來的null值,如果key不存在,則會添加新的key-value對Object replace(Object key,Object value)將Map中指定key對應的value替換成新value。如果key不存在不會添加新的key-value對,並返回nullboolean replace(K key,V oldValue,V newValue)將 Map中指定key-value對的原value替換成新value。如果在Map中找到指定的key-value對,則執行替換並返回true,否則返回falseboolean replaceAll(BiFunction function)該方法使用BiFunction對原key-value對執行計算,並將計算結果作為該key-value對的value值
public class MapTest2 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("三國演義", 25);
map.put("朝花夕拾", 33);
map.put("紅樓夢", 62);
map.put("海底兩萬里", null);
map.replace("紅樓夢", 20);
System.out.println(map);
// 修改海底兩萬里的值,因為其值是null 所以直接用32覆蓋到value上
map.merge("海底兩萬里", 32, (oldVal, par) -> {
return 30;
});
System.out.println(map);
// 修改海底兩萬里的值,因為其值不是null,所以通過 Lambda 計算兩個value的值,將結果覆蓋到此鍵值對的value上
map.merge("海底兩萬里", 32, (oldVal, par) -> {
return (int) oldVal + (int) par;
});
System.out.println(map);
// 因為新value為null 所以刪除key為 紅樓夢的鍵值對
map.compute("紅樓夢", (k, v) -> {
return null;
});
System.out.println(map);
// 將key 為"海底兩萬里" 的值 改為該key的長度,由於key對應的value 不為null,所以這裡沒有變動
map.computeIfAbsent("海底兩萬里", key -> {
return ((String) key).length();
});
System.out.println(map);
// 將key 為"鋼鐵是怎樣煉成的" 的值 改為該key的長度,因為集合里沒有此key 所以增加了一對key-value
map.computeIfAbsent("鋼鐵是怎樣煉成的", key -> {
return ((String) key).length();
});
System.out.println(map);
// 將key 為"海底兩萬里" 的值增加10
map.computeIfPresent("海底兩萬里", (key, value) -> {
return (Integer) value + 10;
});
System.out.println(map);
// 將key為”三國演義“並且值為0的鍵值對的值改為30,以下沒有匹配結果所以不改變
map.replace("三國演義", 0, 30);
System.out.println(map);
// 將key為”三國演義“並且值為25的鍵值對的值改為30,以下有匹配結果所以改變
map.replace("三國演義", 25, 30);
System.out.println(map);
// 獲取水滸傳的值,如果該key不存在,則取defaultValue
System.out.println("水滸傳-->" + map.getOrDefault("水滸傳",3));
// 不存在此key 添加新的鍵值對
map.putIfAbsent("水滸傳",null);
System.out.println(map);
// 水滸傳的值為null 把新值覆蓋到舊值上,
map.putIfAbsent("水滸傳",11);
System.out.println(map);
// 水滸傳的值不為null 不改動
map.putIfAbsent("水滸傳",22);
System.out.println(map);
// 迴圈遍歷
map.forEach((key, value) -> {
System.out.println(key + "-->" + value);
});
}
}
輸出
{三國演義=25, 紅樓夢=20, 海底兩萬里=null, 朝花夕拾=33}
{三國演義=25, 紅樓夢=20, 海底兩萬里=32, 朝花夕拾=33}
{三國演義=25, 紅樓夢=20, 海底兩萬里=64, 朝花夕拾=33}
{三國演義=25, 海底兩萬里=64, 朝花夕拾=33}
{三國演義=25, 海底兩萬里=64, 朝花夕拾=33}
{三國演義=25, 海底兩萬里=64, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
{三國演義=25, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
{三國演義=25, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
{三國演義=30, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
水滸傳-->3
{水滸傳=null, 三國演義=30, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
{水滸傳=11, 三國演義=30, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
{水滸傳=11, 三國演義=30, 海底兩萬里=74, 鋼鐵是怎樣煉成的=8, 朝花夕拾=33}
水滸傳-->11
三國演義-->30
海底兩萬里-->74
鋼鐵是怎樣煉成的-->8
朝花夕拾-->33
HashMap 和 HashTable
HashMap 和 Hashtable 都是 Map 介面的典型實現類,兩者關係類似於 ArrayList 和 Vector的關係:HashTable 是一個古老的 Map 實現類,從JDK 1.0 起就已經出現了,當時,Java 還沒有 Map 介面,因此它包含兩個繁瑣的方法,elements() (類似於values()) 和 keys()(類似於keySet())
Java 8 改進了HashMap的實現,使用HashMap 存在 key 衝突是依然具有較好的性能
此外, Hashtable 和 HashMap 存在幾點區別
Hashtable是一個線程安全的Map實現, 但HashMap是線程不安全的實現類,因此,HashMap的性能更高一點Hashtable不允許使用null作為key和value, 如果試圖把null值 放進Hashtable中,將會引發nullPointerException異常; 但HashMap可以使用null作為key或value- 通過
containsValue()比較兩個value是否相等時,Hashtable只需要兩個對象equals相等即可;HashMap不僅需要equals相等,還需要類型相同
如HashSet 不能保證元素的順序一樣,HashMap、Hashtable 也不能保證key-value 對的順序。此外 判斷key 標準也是通過equals() 方法比較返回true,並且 hashCode 值也相等
public class A {
int count;
public A(int count) {
this.count = count;
}
// 根據count 的值來判斷兩個對象是否相等
@Override
public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (obj != null && obj.getClass() == A.class) {
return ((A) obj).count == this.count;
}
return false;
}
// 根據count 來計算 hashCode 值
@Override
public int hashCode() {
return this.count;
}
}
public class B {
@Override
public boolean equals(Object obj) {
return true;
}
}
比較key
public class HashMapTest {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
ht.put(new B(),"123");
ht.put(new A(111),"321");
System.out.println(ht.containsKey(new B()));
System.out.println(ht.containsKey(new A(111)));
HashMap map = new HashMap();
map.put(new B(),"123");
map.put(new A(111),"321");
System.out.println(map.containsKey(new B()));
System.out.println(map.containsKey(new A(111)));
}
}
輸出
false
true
false
true
比較 value
public class HashMapTest {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
ht.put(new A(123),"三國演義");
ht.put(new A(321),"紅樓夢");
ht.put(new A(111),new B());
System.out.println(ht.containsValue("測試"));
HashMap map = new HashMap();
map.put(new A(123),"三國演義");
map.put(new A(321),"紅樓夢");
map.put(new A(111),new B());
System.out.println(map.containsValue(new String("測試")));
System.out.println(map.containsValue(new B()));
}
}
輸出
true
false
true
LinkedHashMap
LinkedHashMap 使用雙向鏈表來維護元素的順序,該鏈表負責維護Map的迭代順序,迭代順序與元素的插入順序保持一致
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap scores = new LinkedHashMap();
scores.put("語文", 88);
scores.put("數學", 90);
scores.put("英語", 22);
scores.forEach((k, v) -> {
System.out.println(k + "-->" + v);
});
}
}
輸出
語文-->88
數學-->90
英語-->22
Properties
Properties 是Hashtable的子類。該對象在處理屬性文件時特別方便。Properties 類可以把Map 對象和屬性文件關聯起來,從而可以把Map對象中的key-value 對寫入屬性文件中,也可以把屬性文件中的"屬性名=屬性值"載入到Map對象中
Properties 提供瞭如下方法
String getProperty(String key)獲取Properties中指定屬性名對應的屬性值String getProperty(String key,String defaultValue)獲取Properties中指定屬性名對應的屬性值,如果該Properties中不存在此key,則獲得指定預設值Object setProperty(String key,String value)設置屬性值void load(InputStream inStream)從屬性文件(輸入流)中載入key-value對,把載入到的key-value對追加到Properties里void store(OutputStream out,String comments)將Properties中的元素輸出到指定的文件(輸出流)中
public class PropertiesTest {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("username","root");
props.setProperty("password","123456");
props.store(new FileOutputStream("a.ini"),"comment line");
Properties props2 = new Properties();
props2.load(new FileInputStream("a.ini"));
System.out.println(props2);
}
}
輸出
{password=123456, username=root}
a.ini
#comment line
#Wed Sep 13 20:33:14 CST 2023
password=123456
username=root
SortedMap 介面和 TreeMap 實現類
與Set介面相似,Map 介面也派生出一個SortedMap 子介面,SortedMap 介面也有一個TreeMap 實現類
TreeMap底層通過紅黑樹(Red-Black tree)實現,也就意味著containsKey(), get(), put(), remove()都有著log(n)的時間複雜度。
TreeMap 也有兩種排序方式
- 自然排序:
TreeMap的所有key必須實現Comparable介面,而且所有的key應該是同一個類的對象,否則將會拋出ClassCastException異常 - 定製排序:創建
TreeMap時,傳入一個Comparator對象,該對象負責對TreeMap中的所有key進行排序。採用定製排序不要求Map的key實現Comparator介面
TreeMap 提供了一些列根據key順序訪問key-value對的方法
Map.Entry firstEntry()返回該Map中的最小key所對應的key-value對,如果該Map為空,則返回nullMap.Entry lastEntry()返回該Map的最大key所對應的key-value對,如果該Map為空,則返回nullObject firstKey()返回該Map中的最小key值,如通過該Map為空,則返回nullObject lastKey()返回該Map中的最大key值,如通過該Map為空,則返回nullMap.Entry higherEntry(Object key)返回該Map中位於key的後一位key-value對Map.Entry lowerEntry(Object key)返回該Map中位於key的前一位key-value對Object higherKey(Object key)返回該Map中位於key的後一位key值Object lowerKey(Object key)返回該Map中位於key的前一位key值NavigableMap subMap(Object fromKey,boolean fromInclusive,Object toKey,boolean toInclusive)返回該Map 的子Map, 其key 的範圍是從fromKey(是否包括取決去第二個參數) 到toKey(是否包括取決第四個參數)SortedMap subMap(Object fromKey,Object toKey)返回該Map的子Map,其key的範圍是從fromKey(包括)到toKey(不包括)SortedMap tailMap(Object fromKey)返回該

