
近日,袋鼠雲大數據引擎專家郝衛亮,為大家帶來了《袋鼠雲在實時數據湖上的探索與實踐》主題分享,幫助大家能瞭解到什麼是實時數據湖、如何進行數據湖選型及數據平臺建設數據湖的經驗。 如今,大規模、高時效、智能化數據處理已是“剛需”,企業需要更強大的數據處理能力,來應對數據查詢、數據處理、數據挖掘、數據展示以 ...
近日,袋鼠雲大數據引擎專家郝衛亮,為大家帶來了《袋鼠雲在實時數據湖上的探索與實踐》主題分享,幫助大家能瞭解到什麼是實時數據湖、如何進行數據湖選型及數據平臺建設數據湖的經驗。

如今,大規模、高時效、智能化數據處理已是“剛需”,企業需要更強大的數據處理能力,來應對數據查詢、數據處理、數據挖掘、數據展示以及多種計算模型並行的挑戰。
因此,袋鼠雲基於自研的一站式大數據基礎軟體——數棧提出相應的實時數據湖解決方案,能夠相容Iceberg、Hudi等數據湖平臺。實時數據湖提供了多樣化的分析能力,而不限於批處理、流處理、互動式查詢和機器學習;提供了ACID事物能力,可以更好的保障數據質量;提供了完善的數據管理能力,包括數據格式、數據schema等;此外,實時數據湖還提供了存儲介質可擴展的能力,支持HDFS、對象存儲等。從而大大節省了數據存儲成本、提升了開發效率,能夠更快更好地挖掘數據價值。
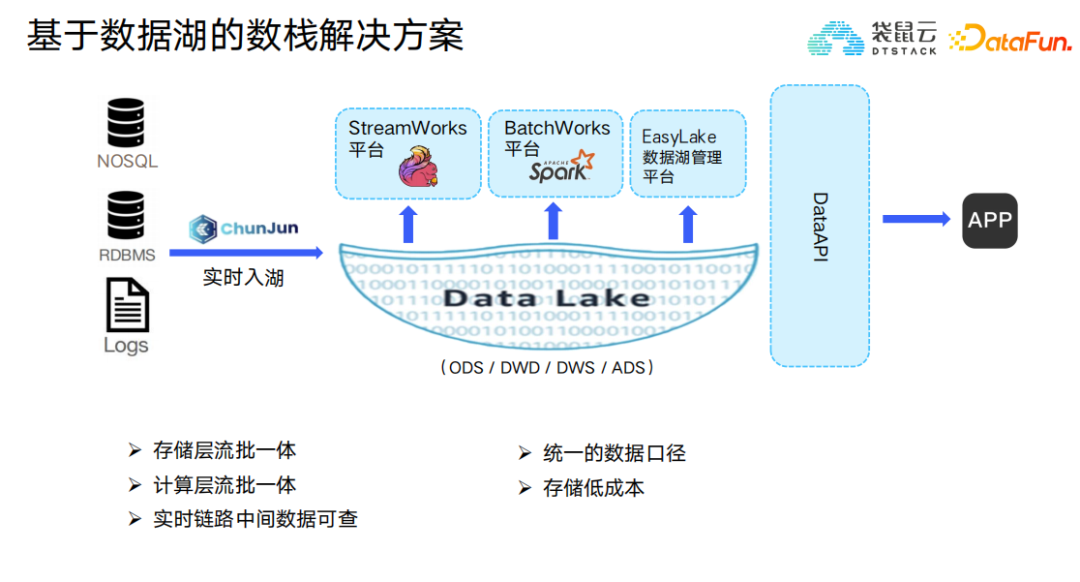
該方案特點在於CDC數據實時入湖,能夠保障技術自主可控、全增量一體化、分鐘級時延、鏈路短、對業務穩定性無影響。
• 實時性高:CDC數據對實時性要求高,數據新鮮度越高,往往業務價值越高
• 歷史數據量大:資料庫的歷史數據規模大
• 強一致性:數據處理必須要保證有序性而且結果需要一致性
• Schema動態演進:資料庫對應的Schema會隨著業務不斷變更
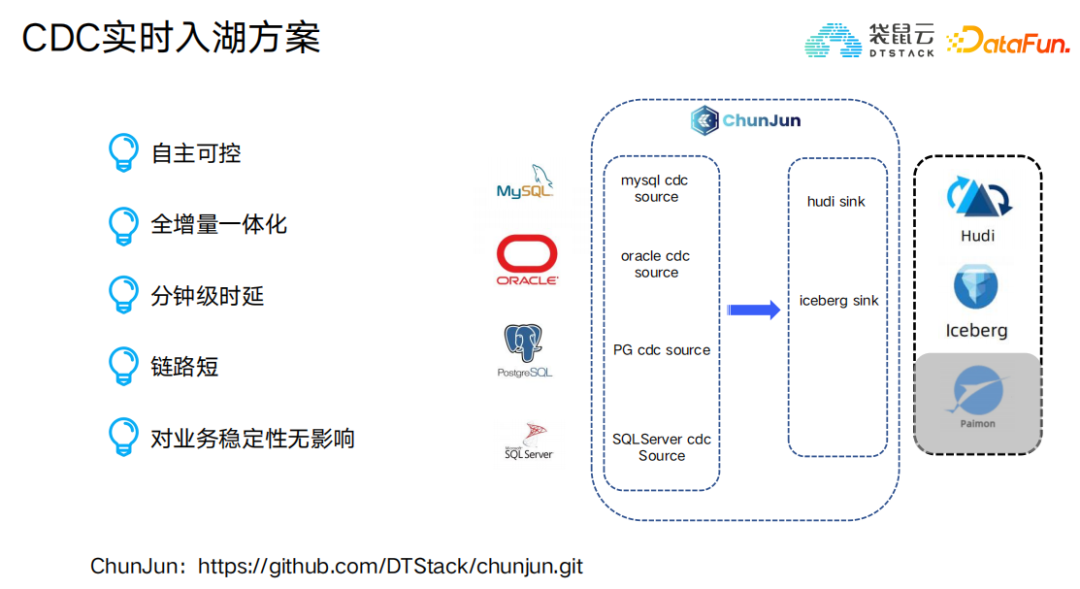
在實時入湖落地過程中,研發團隊也遇到了諸如小文件影響讀寫效率;客戶群體使用的Flink版本大多還停留在1.12;因此需Hudi適配Flink1.12;存在多套Hadoop集群的場景下存在跨集群的需求等問題,最終都一一剋服,提供了完美的解決方案。
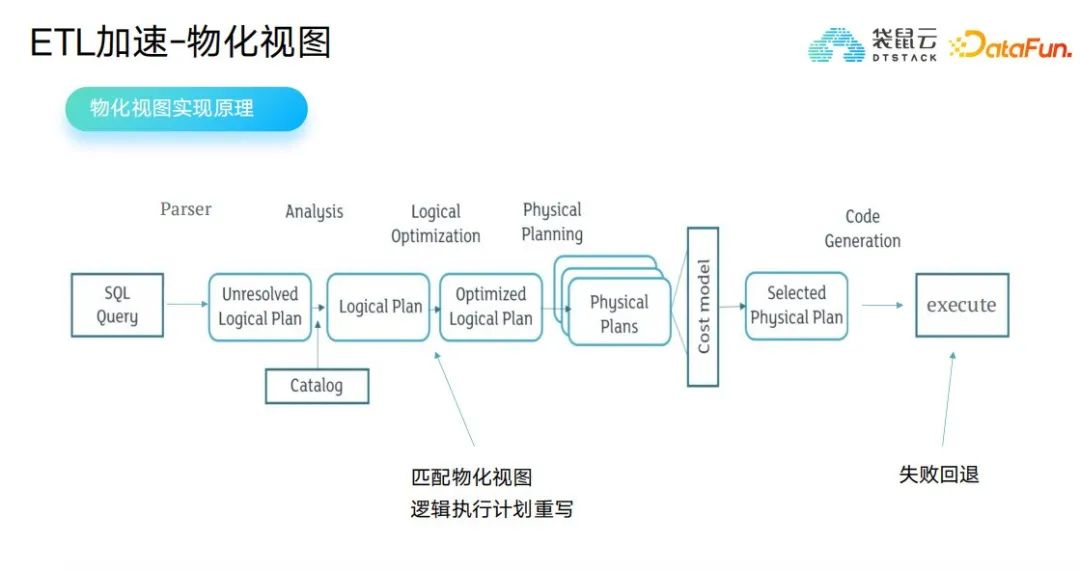
在實時數據湖中包含實時ETL、離線ETL、OLAP三類任務,這三類任務在從ODS層到ADS層加工的過程中,聚合操作越來越多,IO越來越密集,多個任務SQL中具有相同邏輯的SQL片段。為此,技術團隊探索出了物化視圖的方案,完成平臺化數據湖物化視圖管理,Spark、Trino、Flink支持基於數據湖表格式管理物化視圖。
在實時數據湖中基於數據湖構建的物化視圖可實現流、批和OLAP任務之間共用,從而進一步降低實時數據湖中數據在整條鏈路中的延時,從而節省計算成本。
未來,實時數據湖方案還將持續優化,不斷增加平臺湖表管理的易用性;引入Paimon,讓數棧支持對接Paimon、增加基於Paimon的湖倉一體建設;深入並增強內核,提升入湖的的性能;數據湖提供數據共用、支持多引擎,探索數據湖的安全管理方案。
獲取完整PPT:https://www.dtstack.com/resources/1051?src=szsm
想瞭解更多詳情,可點擊觀看視頻講解:https://www.bilibili.com/video/BV1Yu411w7uc/?spm_id_from=333.999.0.0&vd
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack

