
大家好,又見面了。 在此前我的文章中,曾分2篇詳細探討了下JAVA中Stream流的相關操作,2篇文章收穫了累計 10w+閱讀、2k+點贊以及 5k+收藏的記錄。能夠得到眾多小伙伴的認可,是技術分享過程中最開心的事情。 吃透JAVA的Stream流操作,多年實踐總結 講透JAVA Stream的co ...
大家好,又見面了。
在此前我的文章中,曾分2篇詳細探討了下JAVA中Stream流的相關操作,2篇文章收穫了累計 10w+閱讀、2k+點贊以及 5k+收藏的記錄。能夠得到眾多小伙伴的認可,是技術分享過程中最開心的事情。
不少小伙伴在評論中提出了一些的疑問或自己的獨到見解,也在評論區中進行了熱烈的互動討論。梳理了下相關評論內容,針對此前文章中沒有提及的一些典型討論點拿出來聊一聊,也是作為對此前兩篇Java Stream相關文章內容的補充完善。

Stream處理時列表到底迴圈了多少次
看下麵這段Stream使用的常見場景:
Stream.of(17, 22, 35, 12, 37)
.filter(age -> age > 18)
.filter(age -> age < 35)
.map(age -> age + "歲")
.collect(Collectors.toList());
在這段代碼裡面,同時有2個 filter操作和1個 map操作以及1個 collect操作,那麼這段代碼執行的時候,究竟是對這個list執行了幾次迴圈操作呢?是每一個Stream步驟都會進行一次遍歷操作嗎?為了驗證這個問題,我們將上述代碼改寫一下,列印下每個步驟的結果:
List<String> ages = Stream.of(17,22,35,12,37)
.filter(age -> {
System.out.println("filter1 處理:" + age);
return age > 18;
})
.filter(age -> {
System.out.println("filter2 處理:" + age);
return age < 35;
})
.map(age -> {
System.out.println("map 處理:" + age);
return age + "歲";
})
.collect(Collectors.toList());
先執行,得到如下的執行結果。其實結果已經很明顯的可以看出,stream流處理的時候,是對列表進行了一次迴圈,然後順序的執行給定的stream執行語句。
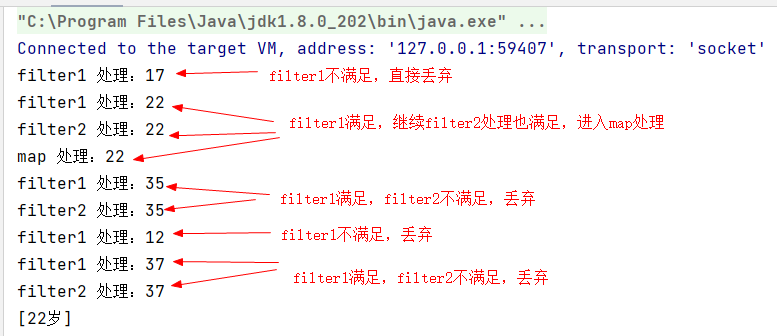
按照上述輸出的結果,可以看出其處理的過程可以等價於如下的常規寫法:
List<Integer> ages = Arrays.asList(17,22,35,12,37);
List<String> results = new ArrayList<>();
for (Integer age : ages) {
if (age > 18) {
if (age < 35) {
results.add(age + "歲");
}
}
}
System.out.println(results);
所以,Stream並不會去遍歷很多次。其實上述邏輯也符合Stream 流水線加工的整體模式,試想一下,一條流水線上分環節加工一件商品,同一件產品也不會在流水線上加工2次的吧~

Stream究竟是讓代碼更易讀還是更難懂
自Java8引入了 Lambda、函數式介面、Stream等新鮮內容以來,針對使用Stream或Lambda語法究竟是讓代碼更易懂還是更複雜的爭議,一直就沒有停止過。有的同學會覺得Stream語法的方式,一眼就可以看出業務邏輯本身的含義,也有一些同學認為使用了Stream之後代碼的可讀性降低了很多。

其實,這是個人編碼模式與理念上的不同感知而已。Stream主打的就是讓代碼更聚焦自身邏輯,省去其餘繁文縟節對代碼邏輯的干擾,整體編碼上會更加的簡潔。但是剛接觸的時候,難免會需要一定的適應期。技術總是在不斷迭代、不斷擁抱新技術、不去刻意排斥新技術,或許是一個更好的選項。
那麼,話說回來,如何讓自己能夠一眼看懂Stream代碼、感受到Stream的簡潔之美呢?分享個人的一個經驗:
- 先瞭解幾個常見的Stream的api的功能含義(Stream的API封裝的很優秀,很多都是字面意義就可以理解)
- 改變意識,聚焦純粹的業務邏輯本身,不要在乎具體寫法細節
下麵舉了個例子,如何用上述的2條方法,快速的讓自己理解一段Stream代碼表達的意思。

那麼上面這段代碼的含義就是,先根據員工子公司過濾所有上海公司的人員,再獲取員工工資最高的那個人信息。怎麼樣?按照這個方法,是不是可以發現,Stream的方式,確實更加容易理解了呢~
在IDEA中debug調試Stream代碼段
技術分享其實是一個雙向的過程,分享的同時,也是自我學習與提升的機會,除了可以梳理髮現一些自己之前忽略的知識點並加以鞏固,還可以在互動的時候get到新的技能。
比如,我在此前的 Java Stream介紹的文章中,有提過基於Stream進行編碼的時候會導致代碼 debug調試的時候會比較困難,尤其是那種只有一行Lambda表達式的情況(因為如果代碼邏輯多行編寫的時候,可以在代碼塊內部打斷點,這樣其實也可以進行debug調試)。

關於這一點,很多小伙伴也有相同的感受,比如下麵這個評論:

你以為這就結束了?接下來一個小伙伴的提示,“震驚”了眾人!納尼?原來Stream代碼段也是可以debug單步調試的?
跟蹤Stream中單步處理過程的操作入口按鈕長這樣:

並且,另一個小伙伴補充說這是IDEA從 2019.03版本開始有的功能:
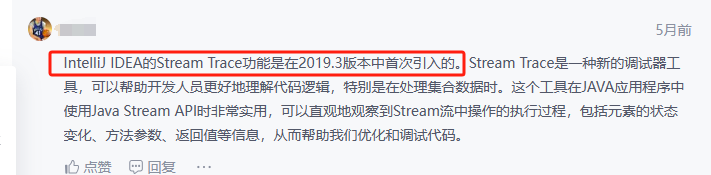
嗯?難怪呢,我一直用的2019.02版本的,所以才沒用上這個功能(強行給自己找了個臺階、哈哈哈)。於是,我悄悄的將自己的idea升級到了最新的2023.02版本(PS:新版本的UI挺好看,就是bug賊多)。好啦,言歸正傳,那麼究竟應該如何利用IDEA來實現單步DEBUG呢?一一起來感受下吧。
在代碼行前面添加斷點的時候,如果要打斷點的這行代碼裡面包含Stream中間方法(map\filter\sort之類的)的時候,會提示讓選擇斷點的具體類型。
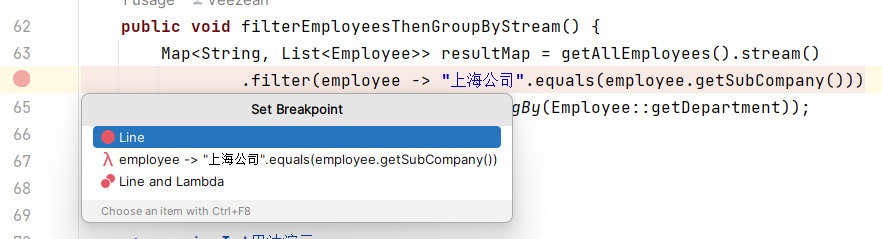
一共有三種類型斷點可供選擇:
- Line:斷點打在這一行上,不會進入到具體的Stream執行函數塊中
- Lambda:代碼打在內部的lambda代碼塊上
- Line and Lambda:代碼走到這行或者執行這一行具體的函數塊內容的時候,都會進入斷點
下麵這個圖可以更清晰的解釋清楚上述三者的區別。一般來說,我們debug的時候,更多的是關註自身的業務具體邏輯,而不會過多去關註Stream執行框架的運轉邏輯,所以大部分情況下,我們選擇第二個Lambda選項即可。
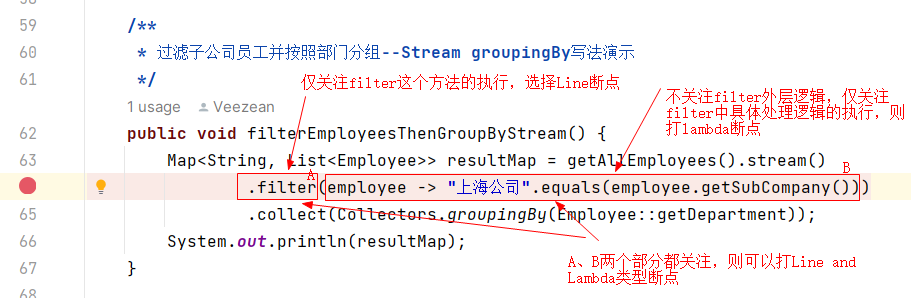
按照上面所述,我們在代碼行前面添加一個Lambda類型斷點,然後debug模式啟動程式執行,等到斷點進入的時候便可以正常的進行debug並查看內部的處理邏輯了。
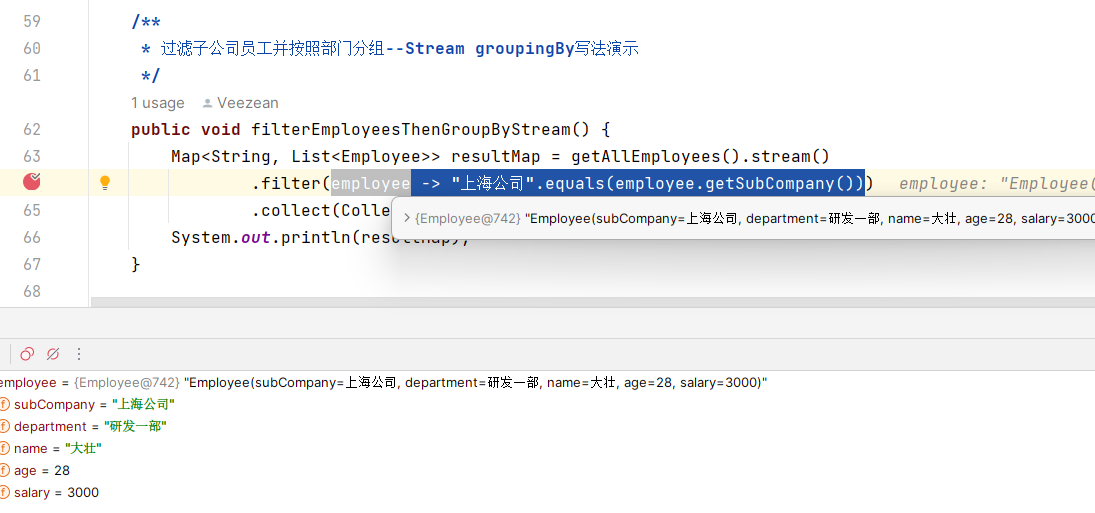
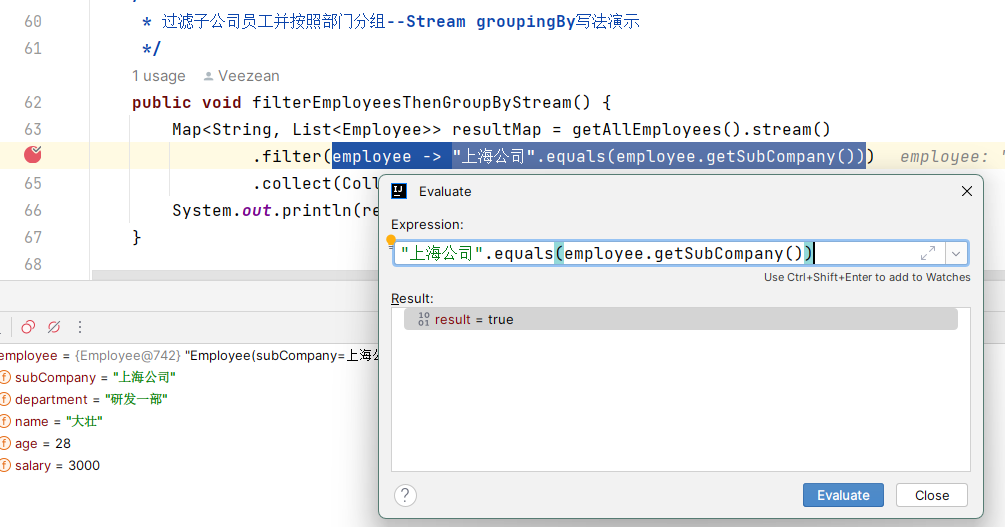
如果遇到圖中這種只有一行的lambda形式代碼,想要看下返回值到底是什麼的,可以選中執行的片段,然後 ALT+F8打開Evaluate界面(或者右鍵選擇 Evaluate Expression),點擊 Evaludate按鈕執行查看具體結果。
大部分情況下,掌握這一點,已經可以應付日常的開發過程中對Stream代碼邏輯的debug訴求了。但是上述過程偏向於細節,如果需要看下整個Stream代碼段整體層面的執行與數據變化過程,就需要上面提到的Stream Trace功能。要想使用該功能,斷點的位置也是有講究的,必須要將斷點打在stream開流的地方,否則看不到任何內容。另外,對於一些新版本的IDEA而言,這個入口也比較隱蔽,藏在了下拉菜單中,就像下麵這個樣子。
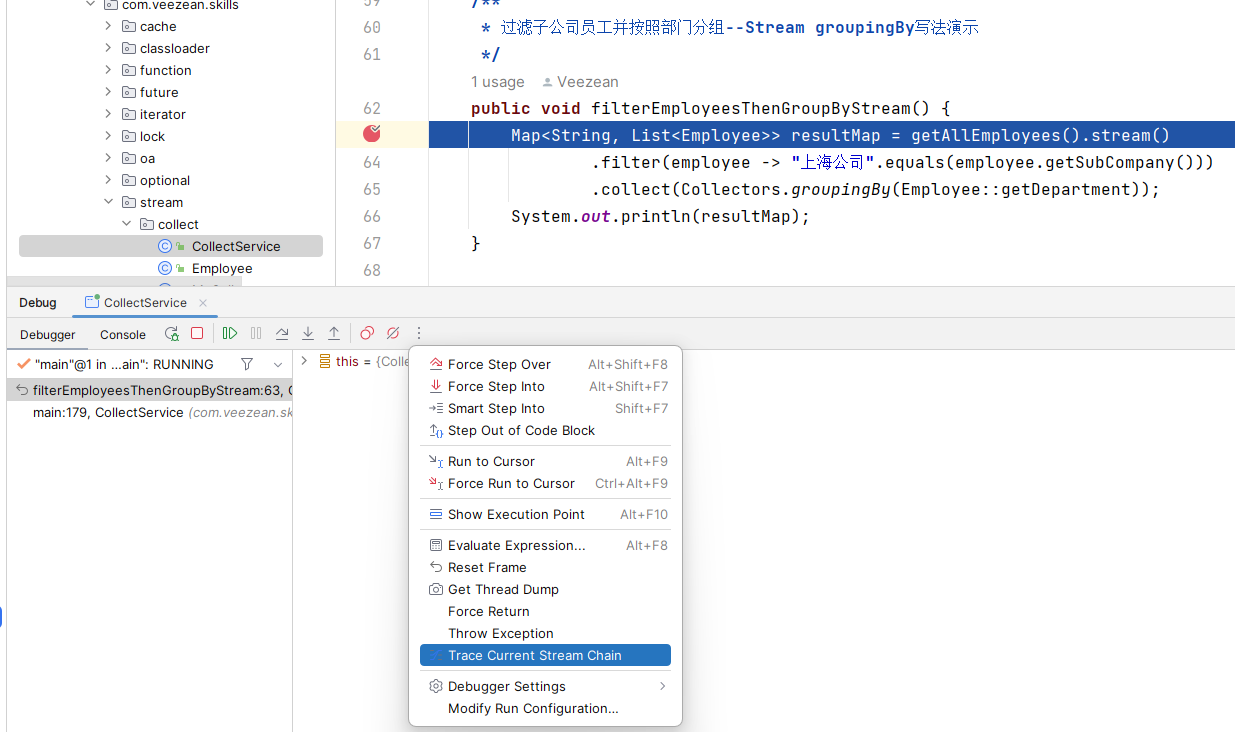
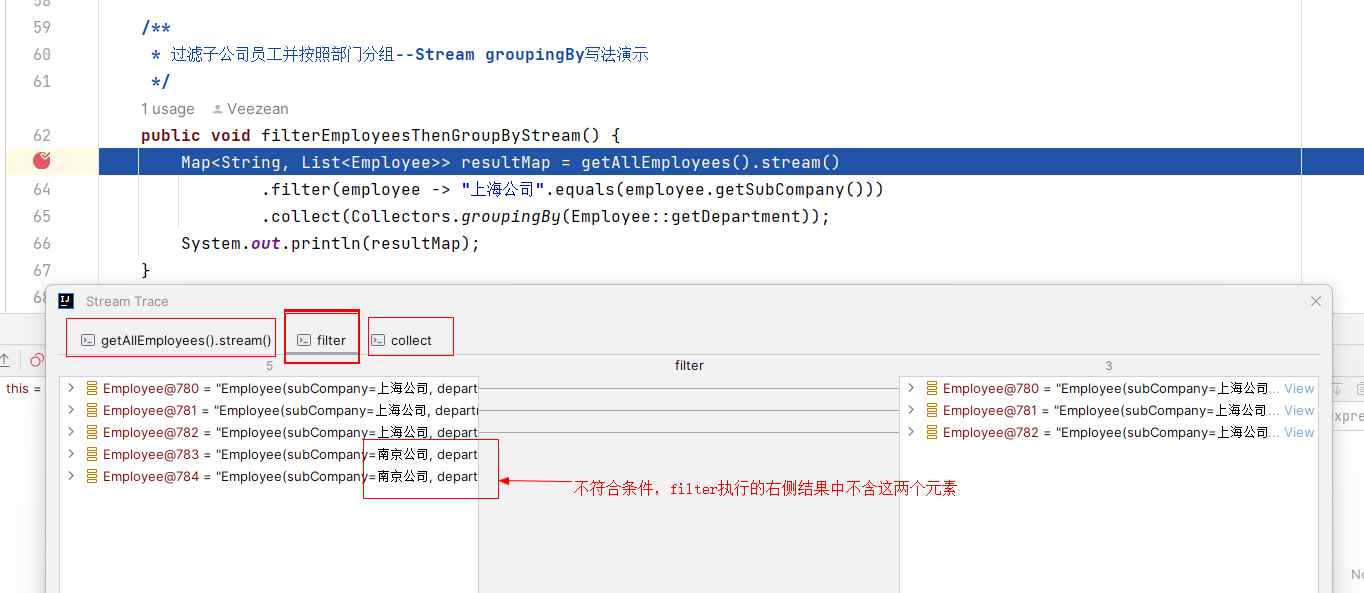
我們找到Trace Current Stream Chain並點擊,可以打開Stream Trace界面,這裡以chain鏈的方式,和stream代碼塊邏輯對應,分步驟展示了每個stream處理環節的執行結果。比如我們以 filter環節為例,視窗中以左右視圖的形式,左側顯示了原始輸入的內容,右側是經過filter處理後符合條件並保留下來的數據內容,並且還有連接線進行指引,一眼就可以看出哪些元素是被過濾捨棄了的:
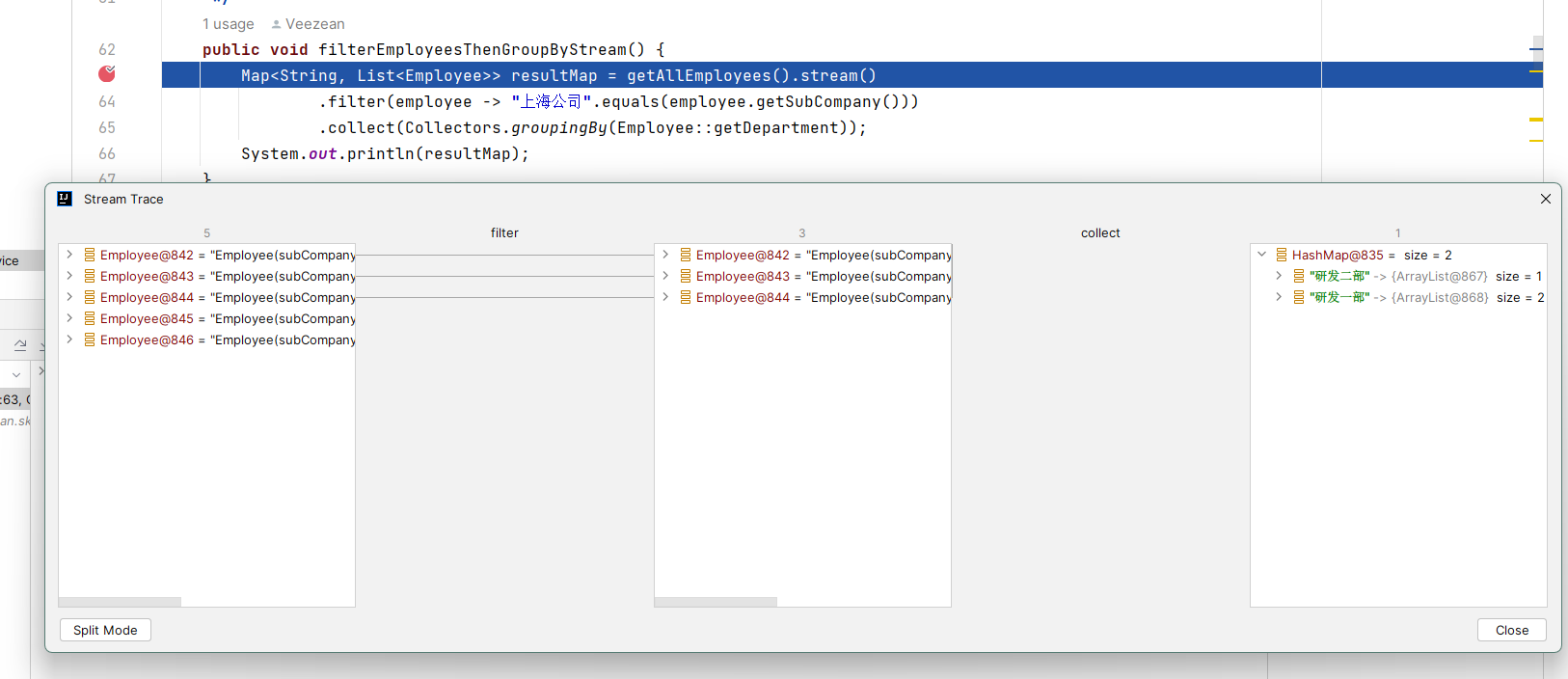
不止於此,Stream Trace除了提供上述分步查看結果的能力,還支持直接顯示整體的鏈路執行全貌。點擊Stream Trace視窗左下角的 Flat Mode按鈕即可切換到全貌模式,可以看到最初原始數據,如何一步步被處理並得到最終的結果。
看到這裡,以後還會說Stream不好調試嗎?至少我不會了。
小心Collectors.toMap出現key值重覆報錯
在我們常規的HashMap的 put(key,value)操作中,一般很少會關註key是否已經在map中存在,因為put方法的策略是存在會覆蓋已有的數據。但是在Stream中,使用 Collectors.toMap方法來實現的時候,可能稍不留神就會踩坑。所以,有小伙伴在評論區熱心的提示,在使用此方法的時候需要手動加上 mergeFunction以防止key衝突。

這個究竟是怎麼回事呢?我們看下麵的這段代碼:
public void testCollectStopOptions() {
List<Dept> ids = Arrays.asList(new Dept(17), new Dept(22), new Dept(22));
// collect成HashMap,key為id,value為Dept對象
Map<Integer, Dept> collectMap = ids.stream()
.collect(Collectors.toMap(Dept::getId, dept -> dept));
System.out.println("collectMap:" + collectMap);
}
執行上述代碼,不出意外的話會出意外。如下結果:
Exception in thread "main" java.lang.IllegalStateException: Duplicate key Dept{id=22}
at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1254)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1320)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
因為在收集器進行map轉換的時候,由於出現了重覆的key,所以拋出異常了。 為什麼會出現異常呢?為什麼不是以為的覆蓋呢?我們看下源碼的實現邏輯:

可以看出,預設情況下如果出現重覆key值,會對外拋出IllegalStateException異常。同時,我們看到,它其實也有提供重載方法,可以由使用者自行指定key值重覆的時候的執行策略:

所以,我們的目標是出現重覆值的時候,使用新的值覆蓋已有的值而非拋出異常,那我們直接手動指定下讓toMap按照我們的要求進行處理,就可以啦。改造下前面的那段代碼,傳入自行實現的 mergeFunction函數塊,即指定下如果key重覆的時候,以新一份的數據為準:
public void testCollectStopOptions() {
List<Dept> ids = Arrays.asList(new Dept(17), new Dept(22), new Dept(22));
// collect成HashMap,key為id,value為Dept對象
Map<Integer, Dept> collectMap = ids.stream()
.collect(Collectors.toMap(
Dept::getId,
dept -> dept,
(exist, newOne) -> newOne));
System.out.println("collectMap:" + collectMap);
}
再次執行,終於看到我們預期中的結果了:
collectMap:{17=Dept{id=17}, 22=Dept{id=22}}
By The Way,個人感覺JDK在這塊的預設實現邏輯有點不合理。雖然現在預設的拋異常方式,可以強制讓使用端感知並去指定自己的邏輯,但這預設邏輯與map的put操作預設邏輯不一致,也讓很多人都會無辜踩坑。如果將預設值改為有則覆蓋的方式,或許會更符合常理一些 —— 畢竟被廣泛使用的HashMap的源碼里,put操作預設就是覆蓋的,不信可以看HashMap源碼的實現邏輯:
慎用peek承載業務處理邏輯
peek和 foreach在Stream流操作中,都可以實現對元素的遍歷操作。區別點在與peek屬於中間方法,而foreach屬於終止方法。這也就意味著peek只能作為管道中途的一個處理步驟,而沒法直接執行得到結果,其後面必須還要有其它終止操作的時候才會被執行;而foreach作為無返回值的終止方法,則可以直接執行相關操作。
那麼,只要有終止方法一起,peek方法就一定會被執行嗎?非也!看版本、看場景! 比如在 JDK1.8版本中,下麵這段代碼中的peek方法會正常執行,但是到了 JDK17中就會被自動優化掉而不執行peek中的邏輯:
public void testPeekAndforeach() {
List<String> sentences = Arrays.asList("hello world", "Jia Gou Wu Dao");
sentences.stream().peek(sentence -> System.out.println(sentence)).count();
}
至於原因,可以看下JDK17官方API文檔中的描述:

因為對於 findFirst、count之類的方法,peek操作被視為與結果無關聯的操作,直接被優化掉不執行了。所以說最好按照API設計時預期的場景去使用API,避免自己給自己埋坑。
我們從peek的源碼的註釋上可以看出,peek的推薦使用場景是用於一些調試場景,可以藉助peek來將各個元素的信息列印出來,便於開發過程中的調試與問題定位分析。
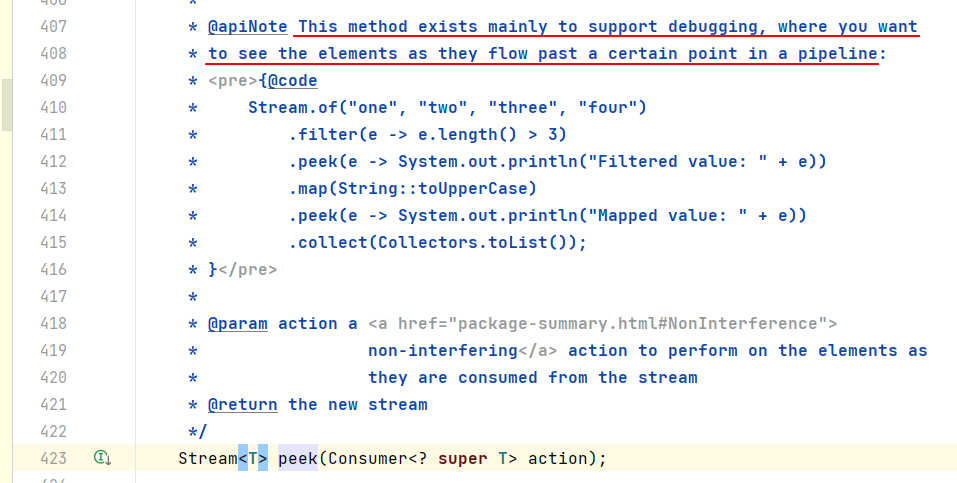
我們再看下peek這個詞的含義解釋:

既然開發者給它起了這麼個名字,似乎確實僅是為了窺視執行過程中數據的變化情況。為了避免讓自己踩坑,最好按照設計者推薦的用途用法進行使用,否則即使現在沒問題,也不能保證後續版本中不會出問題。
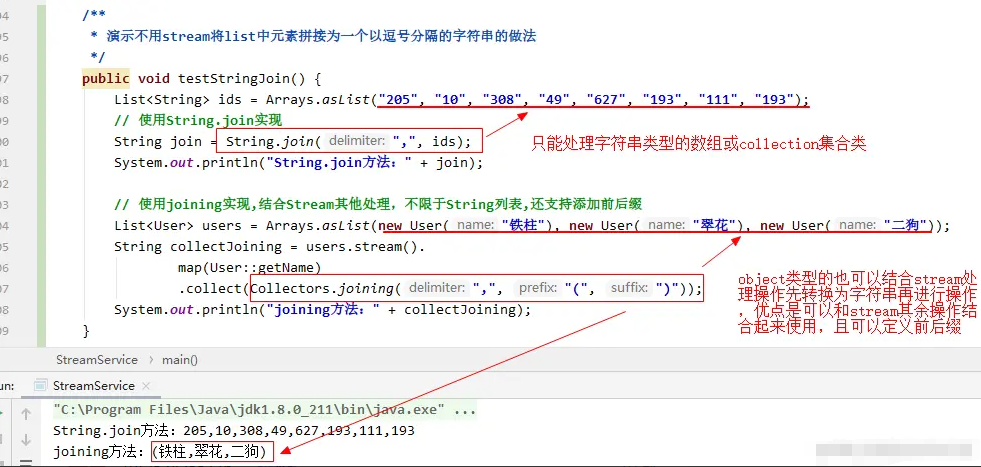
字元串拼接明明有join,那麼Stream中Collectors.join存在意義是啥
在介紹Stream流的收集器時,有介紹過使用 Collectors.joining來實現多個字元串元素之間按照要求進行拼接的實現。比如將給定的一堆字元串用逗號分隔拼接起來,可以這麼寫:
public void testCollectJoinStrings() {
List<String> ids = Arrays.asList("AAA", "BBB", "CCC");
String joinResult = ids.stream().collect(Collectors.joining(","));
System.out.println(joinResult);
}
有很多同學就提出字元串元素拼接直接用 String.join就可以了,完全沒必要搞這麼複雜。

如果是純字元串簡單拼接的場景,確實直接String.join會更簡單一些,這種情況下使用Stream進行拼接的確有些大材小用了。 但是 joining的方法優勢要體現在Stream體系中,也就是與其餘Stream操作可以結合起來綜合處理。String.join對於簡單的字元串拼接是OK的,但是如果是一個Object對象列表,要求將Object某一個欄位按照指定的拼接符去拼接的時候,就力不從心了——而這就是使用 Collectors.joining的時機了。比如下麵的實例:
小結
好啦,關於Java Stream相關的內容點的補充,就聊到這裡啦。如果需要全面瞭解Java Stream的相關內容,可以看我此前分享的文檔。那麼,你對Java Stream是否還有哪些疑問或者自己的獨特理解呢?歡迎一起交流下。
傳送門:
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關註讓我感受到您的支持。也可以關註下我的公眾號【架構悟道】,獲取更及時的更新。
期待與你一起探討,一起成長為更好的自己。

本文來自博客園,作者:架構悟道,歡迎關註公眾號[架構悟道]持續獲取更多乾貨,轉載請註明原文鏈接:https://www.cnblogs.com/softwarearch/p/17698919.html


