
Matplotlib 提供了大量配置參數,這些參數可以但不限於讓我們從整體上調整通過 Matplotlib 繪製的圖形樣式,這裡面的參數還有很多是功能性的,和其他工具結合時需要用的配置。 通過plt.rcParams,可以查看所有的配置信息: import matplotlib.pyplot as ...
一、Paxos協議簡介
Paxos演算法由Leslie Lamport在1990年提出,它是少數在工程實踐中被證實的強一致性、高可用、去中心的分散式協議。Paxos協議用於在多個副本之間在有限時間內對某個決議達成共識。Paxos協議運行在允許消息重覆、丟失、延遲或亂序,但沒有拜占庭式錯誤的網路環境中,它利用“大多數 (Majority)機制”保證了2F+1的容錯能力,即2F+1個節點的系統最多允許F個節點同時出現故障。
拜占庭式錯誤釋義:
一般地把出現故障但不會偽造信息的情況稱為“非拜占庭錯誤”(Non-Byzantine Fault)或“故障錯誤”(Crash Fault);而偽造信息惡意響應的情況稱為“拜占庭錯誤”(Byzantine Fault)。
1、核心概念
- Proposal:提案(提案 = 提案編號acceptNumber + 提案值acceptValue);
- Proposal Number:提案編號;
- Proposal Value:提案值;
2、參與角色
- Proposer(提案者):處理客戶端請求,主動發起提案;
- Acceptor (投票者):被動接受提案消息,參與投票並返回投票結果給Proposer以及發送通知給Learner;
- Learner(學習者):不參與投票過程,記錄投票相關信息,並最終獲得投票結果;
在實際的分散式業務場景中,一個伺服器節點或進程可以同時扮演其中的一種或幾種角色,而且在分散式環境中往往同時存在多個Proposer、多個Acceptor和多個Learner。
3、基礎邏輯
Paxos演算法是指一個或多個提案者針對某項業務提出提案,併發送提案給投票者,由投票者投票並最終達成共識的演算法。

”達成共識“過程的特點:
(1)、可以由一個或多個提案者參與;
(2)、由多個投票者參與;
(3)、可以發起一輪或多輪投票;
(4)、最終的共識結果是一個值,且該值為提案者提出的其中某個值;
二、Basic Paxos
1、兩個階段
Basic Paxos演算法分為兩個階段:Prepare階段和Accept階段。
(1). Prepare階段
該階段又分為兩個環節:
- a、Proposer發起廣播消息給集群中的Acceptor發送一個提案編號為n的prepare提案請求。
- b、Acceptor收到提案編號為n的prepare提案請求,則進行以下判斷:
如果該Acceptor之前接受的prepare請求編號都小於n或者之前沒有接受過prepare請求,那麼它會響應接受該編號為n的prepare請求並承諾不再接受編號小於n的Accept請求,Acceptor向Proposer的響應數據包含三部分內容:接受編號n的提案狀態信息,之前接受過的最大提案編號和相應提案值;如果該Acceptor之前接受過至少一個編號大於n的prepare請求,則會拒絕該次prepare請求。
通過以上prepare階段處理流程可以知道:
- a、prepare請求發送時只包含提案編號,不包含提案值;
- b、集群中的每個Acceptor會存儲自己當前已接受的最大提案編號和提案值。
假設分散式環境中有一個Proposer和三個Acceptor,且三個Acceptor都沒有收到過Prepare請求,Prepare階段示意圖如下:
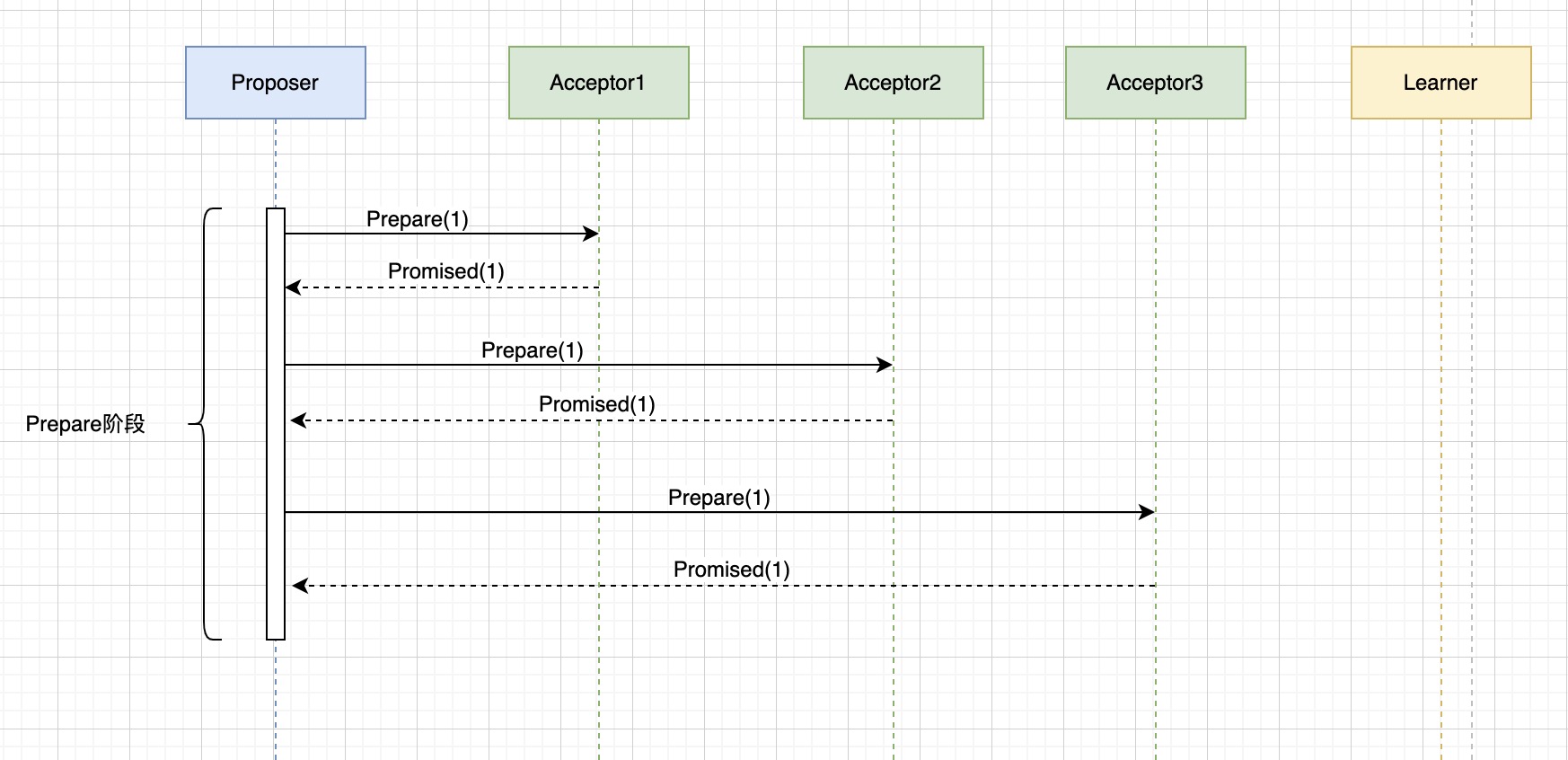
假設分散式環境中有兩個Proposer和三個Acceptor,ProposerB成功發送prepare請求,在發送Accept請求時出現故障宕機,只成功給Acceptor1發送了accept請求並得到響應。當前各個Acceptor的狀態分別為:
Acceptor1,同意了ProposerB發送的提案編號2的Accept請求,當前提案值為:orange;
Acceptor2,接受了ProposerB發送的提案編號2的Prepare請求;
Acceptor3,接受了ProposerB發送的提案編號2的Prepare請求;
此時ProposerA發起Prepare請求示意圖如下:

流程說明:
- a、ProposerA發起prepare(1)的請求,由於該編號小於提案編號2,所以請求被拒絕;
- b、ProposerA發起prepare(3)的請求,該編號大於編號2,則被接受,Accetpor1返回Promised(3,2,'orange'),表示接受編號3的提案請求,並將之前接受過的最大編號提案和提案值返回。
- c、Acceptor2和Acceptor3均返回Promised(3),表示接受編號3的提案請求。
(2). Accept階段
如果Proposer接收到了超過半數節點的Prepare請求的響應數據,則發送accept廣播消息給Acceptor。如果Proposer在限定時間內沒有接收到超過半數的Prepare請求響應數據,則會等待指定時間後再重新發起Prepare請求。
Proposer發送的accept廣播請求包含什麼內容:
- a、accept請求包含相應的提案號;
- b、accept請求包含對應的提案值。如果Proposer接收到的prepare響應數據中包含Acceptor之前已同意的提案號和提案值,則選擇最大提案號對應的提案值作為當前accept請求的提案值,這種設計的目的是為了能夠更快的達成共識。而如果prepare返回數據中的提案值均為空,則自己生成一個提案值。
Acceptor接收到accept消息後的處理流程如下:
- a、判斷accept消息中的提案編號是否小於之前已同意的最大提案編號,如果小於則拋棄,否則同意該請求,並更新自己存儲的提案編號和提案值。
- b、Acceptor同意該提案後發送響應accepted消息給Proposer,並同時發送accepted消息給Learner。Learner判斷各個Acceptor的提案結果,如果提案結果已超過半數同意,則將結果同步給集群中的所有Proposer、Acceptor和所有Learner節點,並結束當前提案。
當Acceptor之前沒有接受過Prepare請求時的響應流程圖:

當Acceptor之前已存在接受過的Prepare和Accept請求時的響應流程圖:

該示例中prepare請求返回數據中已經包含有之前的提案值(1,'apple')和(2,'banana'),Proposer選擇之前最大提案編號的提案值作為當前的提案值。
2、關於提案編號和提案值
- 提案編號
在Paxos演算法中並不自己生成提案編號,提案編號是由外部定義並傳入到Paxos演算法中的。
我們可以根據使用場景按照自身業務需求,自定義提案編號的生成邏輯。提案編號只要符合是“不斷增加的數值型數值”的條件即可。
比如:
在只有一個Proposer的環境中,可以使用自增ID或時間戳作為提案編號;
在兩個Proposer的環境中,一個Proposer可以使用1、3、5、7...作為其編號,另一個Proposer可以使用2、4、6、8...作為其提案編號;
在多Proposer的環境中,可以為每個節點預分配固定ServerId(ServerId可為1、2、3、4...),使用自增序號 + '.' + ServerId或timestamp + '.' + ServerId的格式作為提案編號,比如:1.1、1.2、2.3、3.1、3.2或1693702932000.1、1693702932000.2、1693702932000.3;
每個Proposer在發起Prepare請求後如果沒有得到超半數響應時,會更新自己的提案號,再重新發起新一輪的Prepare請求。
- 提案值
提案值的定義也完全是根據自身的業務需求定義的。在實際應用場景中,提案值可以是具體的數值、字元串或是cmd命令或運算函數等任何形式,比如在分散式資料庫的設計中,我們可以將數據的寫入操作、修改操作和刪除操作等作為提案值。
3、最終值的選擇
Acceptor每次同意新的提案值都會將消息同步給Learner,Learner根據各個Acceptor的反饋判斷當前是否已超過半數同意,如果達成共識則發送廣播消息給所有Acceptor和Proposer並結束提案。
在實際業務場景中,Learner可能由多個節點組成,每個Learner都需要“學習”到最新的投票結果。關於Learner的實現,Lamport在其論文中給出了下麵兩種實現方式:
(1)、選擇一個Learner作為主節點用於接收投票結果(即accepted消息),其他Learner節點作為備份節點,Learner主節點接收到數據後再同步給其他Learner節點。該方案缺點:會出現單點問題,如果這個主節點掛掉,則不能獲取到投票結果。
(2)、Acceptor同意提案後,將投票結果同步給所有的Learner節點,每個Learner節點再將結果廣播給其他的Learner節點,這樣可以避免單點問題。不過由於這種方案涉及很多次的消息傳遞,所以效率要低於上述的方案。
三、活鎖問題
1、什麼是活鎖?
“活鎖”指的是任務由於某些條件沒有被滿足,導致一直重覆嘗試,失敗,然後再次嘗試的過程。 活鎖和死鎖的區別在於,處於活鎖的實體是在不斷的改變狀態,而處於死鎖的實體表現為等待(阻塞);活鎖有可能自行解開,而死鎖不能。
2、為什麼Basic-Paxos可能會出現活鎖?
由於Proposer每次發起prepare請求都會更新編號,那麼就有可能出現這種情況,即每個Proposer在被拒絕時,增大自己的編號重新發起提案,然後每個Proposer在新的編號下不能達成共識,又重新增大編號再次發起提案,一直這樣迴圈往複,就成了活鎖。活鎖現象就是指多個Proposer之間形成僵持,在某個時間段內迴圈發起preapre請求,進入Accept階段但不能達成共識,然後再迴圈這一過程的現象。
活鎖現象示例圖:

3、活鎖如何解決?
活鎖會導致多個Proposer在某個時間段內一直不斷地發起投票,但不能達成共識,造成較長時間不能獲取到共識結果。活鎖有可能自行解開,但該過程的持續時間可長可短並不確定,這與具體的業務場景實現邏輯、網路狀況、提案重新發起時間間隔等多方面因素有關。
解決活鎖問題,有以下常見的方法:
(1)、當Proposer接收到響應,發現支持它的Acceptor小於半數時,不立即更新編號發起重試,而是隨機延遲一小段時間,來錯開彼此的衝突。
(2)、可以設置一個Proposer的Leader,集群全部由它來進行提案,等同於下文的Multi-Paxos演算法。
四、Multi-Paxos
上文闡述了Paxos演算法的基礎運算流程,但我們發現存在兩個問題:
(1)、集群內所有Proposer都可以發起提案所以Basic Paxos演算法有可能導致活鎖現象的發生;
(2)、每次發起提案都需要經過反覆的Prepare和Accept流程,需要經過很多次的網路交互,影響程式的執行效率。
考慮到以上兩個問題,能不能在保障分散式一致性的前提下可以避免活鎖情況的發生,以及儘可能減少達成共識過程中的網路交互,基於這種目的隨即產生了Multi-Paxos演算法。
首先我們可以設想一下:在多個Proposer的環境中最理想的達成共識的交互過程是什麼樣子的?
就是這樣一種情況:集群中的某個Proposer發送一次廣播prepare請求並獲得超半數響應,然後再發送一次廣播accept請求,並獲得超過半數的同意後即達成共識。但現實中多個Proposer很可能會互相交錯的發送消息,彼此之間產生衝突,而且在不穩定的網路環境中消息發送可能會延遲或丟失,這種情況下就需要再次發起提案,影響了執行效率。Multi-Paxos演算法就是為瞭解決這個問題而出現。
Multi-Paxos演算法是為了在保障集群所有節點平等的前提下,依然有主次之分,減少不必要的網路交互流程。
Multi-Paxos演算法是通過選舉出一個Proposer主節點來規避上述問題,集群中的各個Proposer通過心跳包的形式定期監測集群中的Proposer主節點是否存在。當發現集群中主節點不存在時,便會向集群中的Acceptors發出申請表示自己想成為集群Proposer主節點。而當該請求得到了集群中的大多數節點的同意後隨即該Proposer成為主節點。
集群中存在Proposer主節點時,集群內的提案只有主節點可以提出,其他Proposer不再發起提案,則避免了活鎖問題。由於集群中只有一個節點可以發起提案,不存在衝突的可能,所以不必再發送prepare請求,而只需要發送accept請求即可,因此減少了協商網路交互次數。
五、Paxos應用場景示例
上文對Paxos演算法的處理流程就行了闡述,為了加深理解,下麵以一個分散式資料庫的使用案例來闡述Paxos演算法在實際業務場景中的使用。
場景描述:分散式資料庫中假設包含3個節點,客戶端訪問時通過輪詢或隨機訪問的方式請求到其中的某個節點,我們要通過Paxos演算法保證分散式資料庫的3個節點中數據的一致性。
實際的分散式數據一致性流程更為複雜,我這裡為了方便闡述將這個過程進行一些簡化。

分散式資料庫中的每個節點都存儲三份數據,一是事務日誌數據,二是DB數據,三是事務日誌執行位置。
事務日誌表存儲著資料庫的操作日誌記錄,包括:寫入Put、修改Update和刪除Delete等相關的操作日誌,有些文章資料將事務日誌表稱為狀態機其實是一個意思。
DB數據表存儲具體的業務數據。
事務日誌執行位置用於記錄當前節點執行到了哪一條操作記錄;
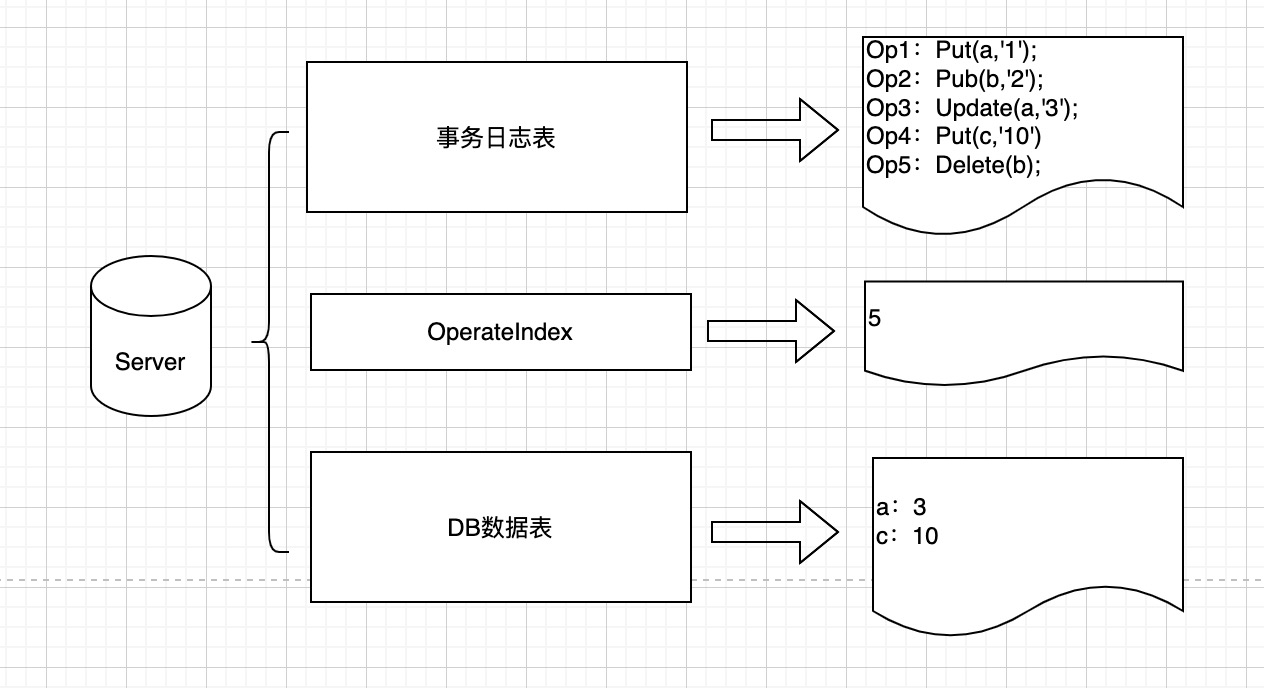 整體設計思想:我們只要通過Paxos演算法保證各個節點事務日誌表數據一致就可以保證節點數據的一致性。
整體設計思想:我們只要通過Paxos演算法保證各個節點事務日誌表數據一致就可以保證節點數據的一致性。
假設,當前各個節點的事務日誌表和數據表均為空,現在客戶端1對資料庫發起寫入操作請求:{'Op1','Put(a,'1')'},這裡的Op1代表操作的ID(為了簡單起見,直接使用自增ID表示,該數值對應Paxos演算法中的提案編號),Put(a,'1')代表操作內容,對應Paxos中的提案值,假設該請求被隨機分配到了Server1處理。

流程說明:
1、Server1接受到Put(a,'1')請求,並不是直接寫入數據表,而是首先通過Paxos演算法判斷集群節點是否達成寫入共識;
2、當前三個節點的OperateIndex均為0,事務日誌表和數據表均為空,Server1的Proposer首先向三個節點發起Prepare(OperateIndex + 1),即Prepare(1)請求。
3、接收到過半數的Prepare請求反饋後,發送Accept(1,'Put(a,'1')')請求,並得到Accepted請求反饋,則此時三個節點達成共識,當前三個節點的事務日誌表均為:{'Op1','Put(a,'1')'},數據表均為空。
4、達成共識後,Server1執行寫入操作並更新當前節點的OperateIndex,此時Server1的OperateIndex為1,其他節點仍為0,Server1的數據表為:a = 1,另外兩個節點為空,三個節點的事務日誌表相同,當前寫入流程結束。
假設,此時Server2節點接收到Put(b,'1')的請求,處理流程如下:
1、Server2接收到Put(b,'1')請求,由於當前Server2的OperateIndex仍為0,則首先發起Prepare(1)的請求,
2、由於當前三個節點的Acceptor的提案編號均為1,所以會拒絕Server2的Prepare(1)請求.
3、Server2未能得到超過半數的prepare響應,則會查看當前事務日誌表發現已存在Op1操作,則從當前節點的事務日誌表中取出相應操作並執行,然後將當前節點OperateIndex修改為1;
4、Server2隨即再次發起Prepare(OperateIndex+1),即Prepare(2)的請求。
5、此時三個節點達成共識,並更新各自的事務日誌表。
6、Server2執行寫入操作,此時Server1節點狀態為OperateIndex:1,數據表:a=1;Server2節點狀態為OperateIndex:2, 數據表:a=1和b=1;Server3的節點狀態為OperateIndex:0,數據表為空;三個節點的事務日誌表相同,均為:
{'Op1','Put(a,'1')'};{'Op2','Put(b,'1')'}。當前流程執行結束。
假設,此時Server3接收到Get(a)請求,處理流程如下:
1、Server3接收到Get(a)請求,並不是直接查詢數據表然後返回,而是要將當前節點的OperateIndex和事務日誌表中的記錄進行比對,如果發現有遺漏操作,則按照事務日誌表的順序執行遺漏操作後再返回。
由於Get請求並不涉及對數據的寫入和修改,所以理論上不需要再次發起Paxos協商。
2、此時Server1節點的狀態為OperateIndex:1,數據表:a=1;Server2的節點狀態為OperateIndex:2, 數據表:a=1和b=1;Server3的節點狀態為OperateIndex:2,數據表為a=1和b=1;三個節點的事務日誌表相同,均為:
{'Op1','Put(a,'1')'};{'Op2','Put(b,'1')'}。當前流程執行結束。
執行流程示意圖如下:

隨著數據的不斷寫入,事務日誌表的數據量不斷增加,可以通過快照的方式,將某個時間點之前的數據備份到磁碟(註意此處備份的是數據表數據,不是事務日誌數據,這樣宕機恢復時直接從快照點開始恢復,可以提高恢復效率,如果備份事務日誌數據,宕機恢復時需要從第一條日誌開始恢復,導致恢復時間會比較長),然後將事務日誌表快照前的數據清除即可。
六、對一些問題的解釋
1、投票過程為什麼要遵循選擇最大提案號的原則?
Paxos投票雖然叫作“投票”,但其實與我們現實中的“投票”有很大的區別,因為它的運算過程中並不關心提案內容本身,而完全依據哪個提案號大就選擇哪個的原則,因為只有這樣才能達成共識。
2、為什麼Proposer每次發起prepare都要變更提案號?
這個問題其實很容易理解,也是為了達成共識。假設ProposerA、ProposerB、ProposerC分別同時發起了prepare(1)、prepare(2)、prepare(3)的提案,而此時ProposerC出現故障宕機,如果ProposerA、ProposerB在後續的每一輪投票中都不變更提案號,那永遠都不可能達成共識。
3、為什麼Paxos演算法可以避免腦裂問題?
Paxos演算法可以避免分散式集群出現腦裂問題,首先我們需要知道什麼是分散式集群的腦裂問題。
腦裂是指集群出現了多個Master主節點,由於分散式集群的節點可能歸屬於不同的網路分區,如果網路分區之間出現網路故障,則會造成不同分區之間的節點不能互相通信。而此時採用傳統的方案很容易在不同分區分別選出相應的主節點。這就造成了一個集群中出現了多個Master節點即為腦裂。
而Paxos演算法是必須達到半數同意才能達成共識,這就意味著如果分區內的節點數量少於一半,則不可能選出主節點,從而避免了腦裂狀況的發生。
七、開發、運維超實用工具推薦
接下來向大家推薦一款對日常開發和運維,極具有實用價值的好幫手XL-LightHouse。
一鍵部署,一行代碼接入,無需大數據相關研發運維經驗就可以輕鬆實現海量數據實時統計,使用XL-LightHouse後:
- 再也不需要用Flink、Spark、ClickHouse或者基於Redis這種臃腫笨重的方案跑數了;
- 再也不需要疲於應付對個人價值提升沒有多大益處的數據統計需求了,能夠幫助您從瑣碎反覆的數據統計需求中抽身出來,從而專註於對個人提升、對企業發展更有價值的事情;
- 輕鬆幫您實現任意細粒度的監控指標,是您監控服務運行狀況,排查各類業務數據波動、指標異常類問題的好幫手;
- 培養數據思維,輔助您將所從事的工作建立數據指標體系,量化工作產出,做專業嚴謹的職場人,創造更大的個人價值;
XL-LightHouse簡介
- XL-LightHouse是針對互聯網領域繁雜的流式數據統計需求而開發的一套集成了數據寫入、數據運算、數據存儲和數據可視化等一系列功能,支持超大數據量,支持超高併發的【通用型流式大數據統計平臺】。
- XL-LightHouse目前已涵蓋了常見的流式數據統計場景,包括count、sum、max、min、avg、distinct、topN/lastN等多種運算,支持多維度計算,支持分鐘級、小時級、天級多個時間粒度的統計,支持自定義統計周期的配置。
- XL-LightHouse內置豐富的轉化類函數、支持表達式解析,可以滿足各種複雜的條件篩選和邏輯判斷。
- XL-LightHouse是一套功能完備的流式大數據統計領域的數據治理解決方案,它提供了比較友好和完善的可視化查詢功能,並對外提供API查詢介面,此外還包括數據指標管理、許可權管理、統計限流等多種功能。
- XL-LightHouse支持時序性數據的存儲和查詢。
** Git地址 **
https://github.com/xl-xueling/xl-lighthouse.git
https://gitee.com/xl-xueling/xl-lighthouse.git
如本文有所疏漏或您有任何疑問,歡迎訪問dtstep.com與我本人溝通交流!


