
在併發編程中我們為啥一般選用創建多個線程去處理任務而不是創建多個進程呢?這是因為線程之間切換的開銷小,適用於一些要求同時進行並且又要共用某些變數的併發操作。而進程則具有獨立的虛擬地址空間,每個進程都有自己獨立的代碼和數據空間,程式之間的切換會有較大的開銷。 ...
by emanjusaka from https://www.emanjusaka.top/archives/7 彼岸花開可奈何
本文歡迎分享與聚合,全文轉載請留下原文地址。
前言
在併發編程中我們為啥一般選用創建多個線程去處理任務而不是創建多個進程呢?這是因為線程之間切換的開銷小,適用於一些要求同時進行並且又要共用某些變數的併發操作。而進程則具有獨立的虛擬地址空間,每個進程都有自己獨立的代碼和數據空間,程式之間的切換會有較大的開銷。下麵介紹幾種創建線程的方法,在這之前我們還是要先瞭解一下什麼是進程什麼是線程。
一、什麼是進程和線程
線程是進程中的一個實體,它本身是不會獨立存在的。進程是系統進行資源分配和調度的基本單位,線程則是進程的一個執行路徑,一個進程中至少有一個線程,進程中的多個線程共用進程的資源。
進程和線程的關係圖如下:
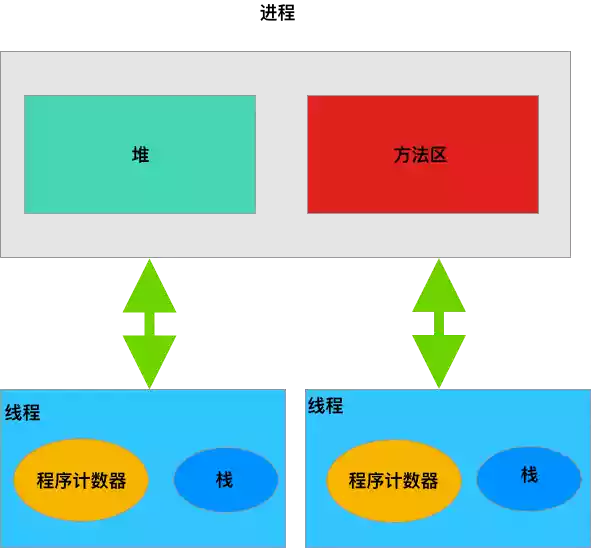
從上面的圖中,我們可以知道一個進程中有多個線程,多個線程共用進程的堆和方法區資源,但是每個線程都有自己的程式計數器和棧區域。堆是一個進程中最大的一塊記憶體,堆是被進程中的所有線程共用的,是進程創建時分配的,堆裡面主要存放使用new操作創建的對象實例。方法區則用來存放 JVM 載入的類、常量及靜態變數等信息,也是線程共用的。
二、線程的創建
Java 中有幾種線程創建的方式:
-
實現 Runnable 介面的 run 方法
-
繼承 Thread 類並重寫 run 的方法
-
使用 FutureTask 方式
-
使用線程池創建
2.1、實現 Runnable 介面的 run 方法
public static void main(String[] args) {
RunableTask task = new RunableTask();
new Thread(task).start();
new Thread(task).start();
}
public static class RunableTask implements Runnable {
@Override
public void run() {
System.out.println("I am a child thread");
}
}
// 輸出
I am a child thread
I am a child thread
這段代碼創建了一個RunableTask類,該類實現了Runnable介面,並重寫了run()方法。在run()方法中,它列印了一條消息:"I am a child thread"。
接下來是main()方法,它是Java程式的入口點。在main()方法中,首先創建了一個RunableTask對象,然後通過調用Thread類的構造函數將該對象作為參數傳遞給Thread類的構造函數,創建了兩個新的線程對象。這兩個線程對象分別使用start()方法啟動,從而使得每個線程都能夠併發地執行。
當程式運行時,會創建兩個子線程,它們將併發地執行RunableTask對象的run()方法。由於兩個線程是同時運行的,因此它們可能會交替執行run()方法中的代碼。在這種情況下,由於線程調度的不確定性,可能會出現以下情況之一:
- 第一個線程先執行
run()方法,列印出"I am a child thread"。 - 第二個線程先執行
run()方法,列印出"I am a child thread"。
需要註意的是,由於線程的執行順序是不確定的,所以每次運行程式時,輸出的結果可能會有所不同。
2.2、繼承 Thread 類方式的實現
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
//繼承Thread類並重寫run方法
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("I am a child thread");
}
}
創建一個名為MyThread的類,該類繼承了Thread類,並重寫了run()方法。
2.3、用 FutureTask 的方式
public static void main(String[] args) throws InterruptedException {
// 創建非同步任務
FutureTask<String> futureTask = new FutureTask<>(new CallerTask());
//啟動線程
new Thread(futureTask).start();
try {
//等待任務執行完畢,並返回結果
String result = futureTask.get();
System.out.println(result);
} catch (ExecutionException e) {
e.printStackTrace();
}
}
//創建任務類,類似Runable
public static class CallerTask implements Callable<String> {
@Override
public String call() throws Exception {
return "hello emanjusaka";
}
}
上面使用了FutureTask和Callable介面來實現非同步任務的執行。首先,在main()方法中創建了一個FutureTask對象,並將一個匿名內部類CallerTask的實例作為參數傳遞給它。這個匿名內部類實現了Callable介面,並重寫了call()方法。在call()方法中,它返回了一個字元串"hello emanjusaka"。接下來,通過調用FutureTask對象的start()方法啟動了一個新的線程,該線程會執行CallerTask對象的call()方法。由於start()方法是非同步執行的,主線程會繼續執行後續的代碼。然後,使用futureTask.get()方法來等待非同步任務的執行結果。這個方法會阻塞當前線程,直到非同步任務執行完畢並返回結果。如果任務執行過程中發生了異常,可以通過捕獲ExecutionException來處理異常情況。
需要註意的是,由於非同步任務的執行是併發進行的,因此輸出的結果可能會有所不同。另外,由於FutureTask和Callable介面提供了更靈活和強大的功能,因此在需要處理返回結果或處理異常的情況下,它們比繼承Thread類並重寫run()方法的方式更加方便和可靠。
2.4、使用線程池
-
Executors
package top.emanjusaka; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Main { public static void main(String[] args) { // 創建一個固定大小的線程池,大小為5 ExecutorService executor = Executors.newFixedThreadPool(5); // 提交10個任務到線程池中執行 for (int i = 0; i < 10; i++) { Runnable worker = new WorkerThread("" + i); executor.execute(worker); } // 關閉線程池 executor.shutdown(); while (!executor.isTerminated()) { } System.out.println("所有任務已完成"); } } class WorkerThread implements Runnable { private String command; public WorkerThread(String s) { this.command = s; } @Override public void run() { System.out.println(Thread.currentThread().getName() + " 開始處理任務: " + command); processCommand(); System.out.println(Thread.currentThread().getName() + " 完成任務: " + command); } private void processCommand() { try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } } // 輸出 pool-1-thread-1 開始處理任務: 0 pool-1-thread-2 開始處理任務: 1 pool-1-thread-3 開始處理任務: 2 pool-1-thread-4 開始處理任務: 3 pool-1-thread-5 開始處理任務: 4 pool-1-thread-2 完成任務: 1 pool-1-thread-4 完成任務: 3 pool-1-thread-2 開始處理任務: 5 pool-1-thread-4 開始處理任務: 6 pool-1-thread-1 完成任務: 0 pool-1-thread-3 完成任務: 2 pool-1-thread-5 完成任務: 4 pool-1-thread-3 開始處理任務: 8 pool-1-thread-1 開始處理任務: 7 pool-1-thread-5 開始處理任務: 9 pool-1-thread-2 完成任務: 5 pool-1-thread-4 完成任務: 6 pool-1-thread-1 完成任務: 7 pool-1-thread-3 完成任務: 8 pool-1-thread-5 完成任務: 9 所有任務已完成
上面的例子中我們首先創建了一個大小為5的線程池。然後,我們提交了10個任務到線程池中執行。每個任務都是一個實現了Runnable介面的WorkerThread對象。最後,我們關閉線程池並等待所有任務完成。
阿裡巴巴開發規範建議使用ThreadPoolExecutor來創建線程池,而不是直接使用Executors。這樣做的原因是,Executors創建的線程池可能會存在資源耗盡的風險,而ThreadPoolExecutor則可以更好地控制線程池的運行規則,規避資源耗盡的風險 。
-
ThreadPoolExecutor
package top.emanjusaka; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; public class Main { public static void main(String[] args) { // 創建一個固定大小的線程池,大小為5 ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); for (int i = 0; i < 10; i++) { Runnable worker = new WorkerThread("" + i); executor.execute(worker); } // 關閉線程池 executor.shutdown(); try { executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("所有任務已完成"); } } class WorkerThread implements Runnable { private String command; public WorkerThread(String s) { this.command = s; } @Override public void run() { System.out.println(Thread.currentThread().getName() + " 開始處理任務:" + command); processCommand(); System.out.println(Thread.currentThread().getName() + " 完成任務:" + command); } private void processCommand() { try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } } // 輸出 pool-1-thread-1 開始處理任務:0 pool-1-thread-3 開始處理任務:2 pool-1-thread-2 開始處理任務:1 pool-1-thread-4 開始處理任務:3 pool-1-thread-5 開始處理任務:4 pool-1-thread-2 完成任務:1 pool-1-thread-3 完成任務:2 pool-1-thread-5 完成任務:4 pool-1-thread-3 開始處理任務:5 pool-1-thread-4 完成任務:3 pool-1-thread-1 完成任務:0 pool-1-thread-4 開始處理任務:8 pool-1-thread-2 開始處理任務:7 pool-1-thread-5 開始處理任務:6 pool-1-thread-1 開始處理任務:9 pool-1-thread-4 完成任務:8 pool-1-thread-3 完成任務:5 pool-1-thread-2 完成任務:7 pool-1-thread-1 完成任務:9 pool-1-thread-5 完成任務:6 所有任務已完成
在這個例子中,我們首先創建了一個大小為5的線程池,其中核心線程數為5,最大線程數為10,空閑線程存活時間為200毫秒,工作隊列為LinkedBlockingQueue。然後,我們提交了10個任務到線程池中執行。最後,我們關閉線程池並等待所有任務完成。
ThreadPoolExecutor的構造函數有以下參數:
- corePoolSize:核心線程數,即線程池中始終保持活躍的線程數。
- maximumPoolSize:最大線程數,即線程池中允許的最大線程數。當工作隊列滿了之後,線程池會創建新的線程來處理任務,直到達到最大線程數。
- keepAliveTime:空閑線程存活時間,即當線程池中的線程數量超過核心線程數時,多餘的空閑線程在等待新任務的最長時間。超過這個時間後,空閑線程將被銷毀。
- unit:keepAliveTime的時間單位,例如TimeUnit.SECONDS表示秒,TimeUnit.MILLISECONDS表示毫秒。
- workQueue:工作隊列,用於存放待處理的任務。常用的有ArrayBlockingQueue、LinkedBlockingQueue和SynchronousQueue等。
- threadFactory:線程工廠,用於創建新的線程。可以自定義線程的名稱、優先順序等屬性。
- handler:拒絕策略,當工作隊列滿了且線程池已滿時,線程池如何處理新提交的任務。常用的有AbortPolicy(拋出異常)、DiscardPolicy(丟棄任務)和DiscardOldestPolicy(丟棄隊列中最舊的任務)。
- executorListeners:監聽器,用於監聽線程池的狀態變化。常用的有ThreadPoolExecutor.AbortPolicy、ThreadPoolExecutor.CallerRunsPolicy和ThreadPoolExecutor.DiscardPolicy。
三、總結
使用繼承方式的好處是方便傳參,你可以在子類裡面添加成員變數,通過set方法設置參數或者通過構造函數進行傳遞,而如果使用Runnable方式,則只能使用主線程裡面被聲明為final的變數。不好的地方是Java不支持多繼承,如果繼承了Thread類,那麼子類不能再繼承其他類,而Runable則沒有這個限制。前兩種方式都沒辦法拿到任務的返回結果,但是Futuretask方式可以。
使用Callable和Future創建線程。這種方式可以將線程作為任務提交給線程池執行,而且可以獲取到線程的執行結果。但是需要註意的是,如果線程拋出了異常,那麼在主線程中是無法獲取到的。使用線程池。線程池是一種管理線程的機制,可以有效地控制線程的數量和復用線程,避免了頻繁地創建和銷毀線程帶來的性能開銷。
參考資料
- 《Java併發編程之美》
本文原創,才疏學淺,如有紕漏,歡迎指正。尊貴的朋友,如果本文對您有所幫助,歡迎點贊,並期待您的反饋,以便於不斷優化。
原文地址: https://www.emanjusaka.top/archives/7
微信公眾號:emanjusaka的編程棧


