
提要:本系列文章主要參考`MIT 6.828課程`以及兩本書籍`《深入理解Linux內核》` `《深入Linux內核架構》`對Linux內核內容進行總結。 記憶體管理的實現覆蓋了多個領域: 1. 記憶體中的物理記憶體頁的管理 2. 分配大塊記憶體的伙伴系統 3. 分配較小記憶體的slab、slub、slob分 ...
提要:本系列文章主要參考MIT 6.828課程以及兩本書籍《深入理解Linux內核》 《深入Linux內核架構》對Linux內核內容進行總結。
記憶體管理的實現覆蓋了多個領域:
- 記憶體中的物理記憶體頁的管理
- 分配大塊記憶體的伙伴系統
- 分配較小記憶體的slab、slub、slob分配器
- 分配非連續記憶體塊的vmalloc分配器
- 進程的地址空間
內核初始化後,記憶體管理的工作就交由伙伴系統來承擔,作為眾多記憶體分配器的基礎,我們必須要對其進行一個詳細的解釋。但是由於伙伴系統的複雜性,因此,本節會首先給出一個簡單的例子,然後由淺入深,逐步解析伙伴系統的細節。
伙伴系統簡介
伙伴系統將所有的空閑頁框分為了11個塊鏈表,每個塊鏈表分別包含大小為1,2,4,\(2^3\),\(2^4\),...,\(2^{10}\)個連續的頁框(每個頁框大小為4K),\(2^{n}\)中的n被稱為order(分配階),因此在代碼中這11個塊鏈表的表示就是一個長度為11的數組。考察表示Zone結構的代碼,可以看到一個名為free_area的屬性,該屬性用於保存這11個塊鏈表。
struct zone {
...
/*
* 不同長度的空閑區域
*/
struct free_area free_area[MAX_ORDER];
...
};
結合之前的知識,我們總結一下,Linux記憶體管理的結構形如下圖:
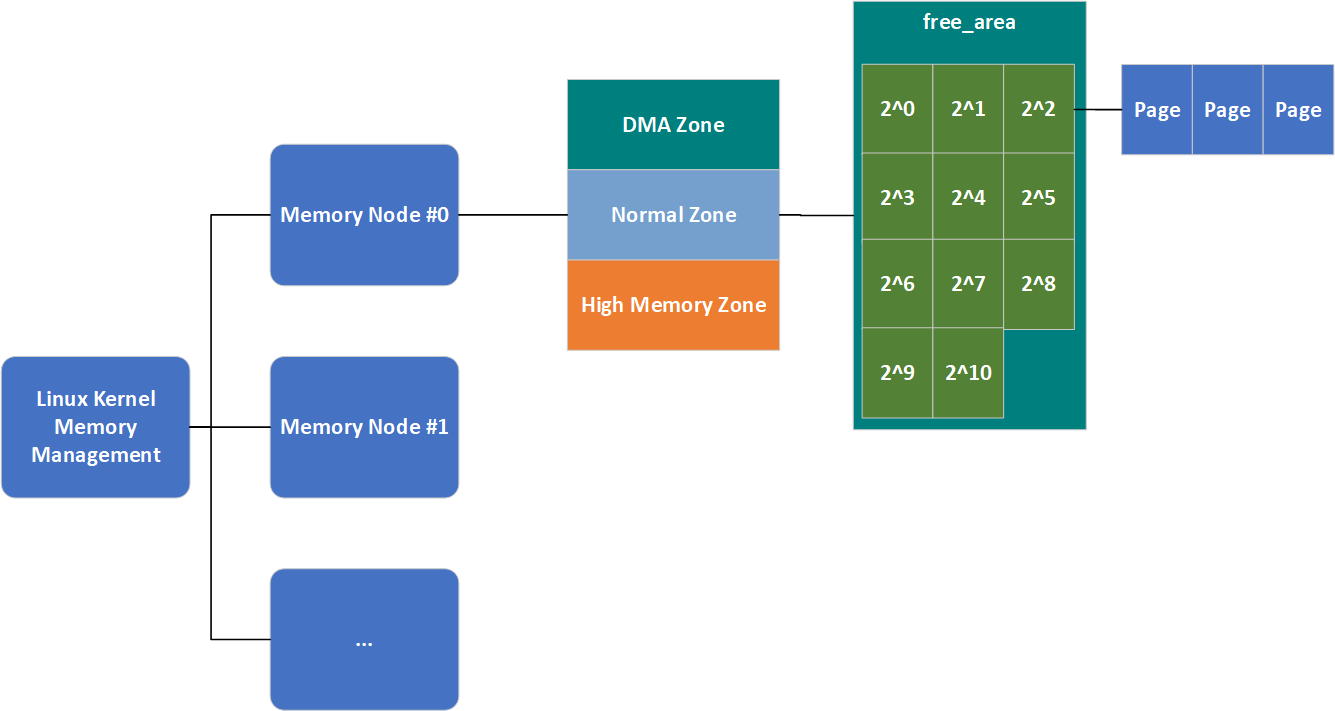
當然,這還不是完整的,我們本節就會將其填充完整。最後借用《深入理解Linux內核》中的一個例子簡單介紹一下該演算法的工作原理進而結束簡介這一小節。
假設要請求一個256個頁框(2^8)的塊(即1MB)。
- 演算法先在256個頁的鏈表中檢查是否有一個空閑塊。
- 如果沒有這樣的塊,演算法會查找下一個更大的頁塊,也就是,在512個頁框的鏈表中找一個空閑塊。
- 如果存在這樣的塊,內核就把256的頁框分成兩等份,一半用作滿足請求,另一半插人到256個頁框的鏈表中。
- 如果在512個頁框的塊鏈表中也沒找到空閑塊,就繼續找更大的塊 一一1024個頁框的塊。
- 如果這樣的塊存在,內核把1024個頁框塊的256個頁框用作請求,然後從剩餘的768個頁框中拿512個插入到512個頁框的鏈表中
- 再把最後的256個插人到256個頁框的鏈表中。
- 如果1024個頁框的鏈表還是空的,演算法就放棄併發出錯信號
以上過程的逆過程就是頁框塊的釋放過程,也是該演算法名字的由來。內核試圖把大小為b的一對空閑伙伴塊合併為一個大小為2b的單獨塊。滿足以下條件的兩個塊稱為伙伴:
- 兩個塊具有相同的大小,記作 b。
- 它們的物理地址是連續的。
- 第一塊的第一個頁框的物理地址是2 x b x \(2^{12}\)的倍數。
註意:該演算法是迭代的,如果它成功合併所釋放的塊,它會試圖合併2b的塊,以再次試圖形成更大的塊。然而伙伴系統的實現並沒有這麼簡單。
避免碎片
伙伴系統作為記憶體管理系統,也難以逃脫一個經典的難題,物理記憶體的碎片問題。尤其是在系統長期運行後,其記憶體可能會變成如下的樣子:
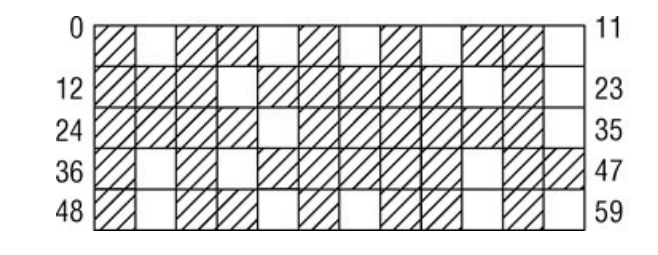
為瞭解決這個問題,Linux提供了兩種避免碎片的方式:
- 可移動頁
- 虛擬可移動記憶體區
可移動頁
物理記憶體被零散的占據,無法尋找到一塊連續的大塊記憶體。內核2.6.24版本,防止碎片的方法最終加入內核。內核採用的方法是反碎片,即試圖從最初開始儘可能防止碎片。因為許多物理記憶體頁不能移動到任意位置,因此無法整理碎片。
可以看到,內核中記憶體碎片難以處理的主要原因是許多頁無法移動到任意位置,那麼如果我們將其單獨管理,在分配大塊記憶體時,嘗試從可以任意移動的記憶體區域內分配,是不是更好呢?
為了達成這一點,Linux首先要瞭解哪些頁是可移動的,因此,操作系統將內核已分配的頁劃分為如下3種類型:
| 類別名稱 | 描述 |
|---|---|
| 不可移動頁 | 在記憶體中有固定位置,不能移動到其他地方。核心內核分配的大多數記憶體屬於該類別 |
| 可回收頁 | 不能直接移動,但可以刪除,其內容可以從某些源重新生成 |
| 可移動頁 | 可以隨意移動。屬於用戶空間應用程式的頁屬於該類別。它們是通過頁表映射的。如果它們複製到新位置,頁表項可以相應地更新,應用程式不會註意到任何事 |
內核中定義了一系列巨集來表示不同的遷移類型:
#define MIGRATE_UNMOVABLE 0 // 不可移動頁
#define MIGRATE_RECLAIMABLE 1 // 可回收頁
#define MIGRATE_MOVABLE 2 // 可移動頁
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* 不能從這裡分配 */
#define MIGRATE_TYPES 5
對於其他兩種類型(瞭解就好):
- MIGRATE_RESERVE:如果向具有特定可移動性的列表請求分配記憶體失敗,這種緊急情況下可從MIGRATE_RESERVE分配記憶體
- MIGRATE_ISOLATE:是一個特殊的虛擬區域,用於跨越NUMA結點移動物理記憶體頁。在大型系統上,它有益於將物理記憶體頁移動到接近於使用該頁最頻繁的CPU。
伙伴系統實現頁的可移動性特性,依賴於數據結構free_area,其代碼如下:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
| 屬性名 | 描述 |
|---|---|
| free_list | 每種遷移類型對應一個空閑頁鏈表 |
| nr_free | 所有列表上空閑頁的數目 |
與zone.free_area一樣,free_area.free_list也是一個鏈表,但這個鏈表終於直接連接struct page了。因此,我們的記憶體管理結構圖就變成瞭如下的樣子:

與NUMA記憶體域無法滿足分配請求時會有一個備用列表一樣,當一個遷移類型列表無法滿足分配請求時,同樣也會有一個備用列表,不過這個列表不用代碼生成,而是寫死的:
/*
* 該數組描述了指定遷移類型的空閑列表耗盡時,其他空閑列表在備用列表中的次序。
*/
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE },/* 從來不用 */
};
該數據結構大體上是自明的:在內核想要分配不可移動頁時,如果對應鏈表為空,則後退到可回收頁鏈表,接下來到可移動頁鏈表,最後到緊急分配鏈表。
在各個遷移鏈表之間,當前的頁面分配狀態可以從/proc/pagetypeinfo獲得:
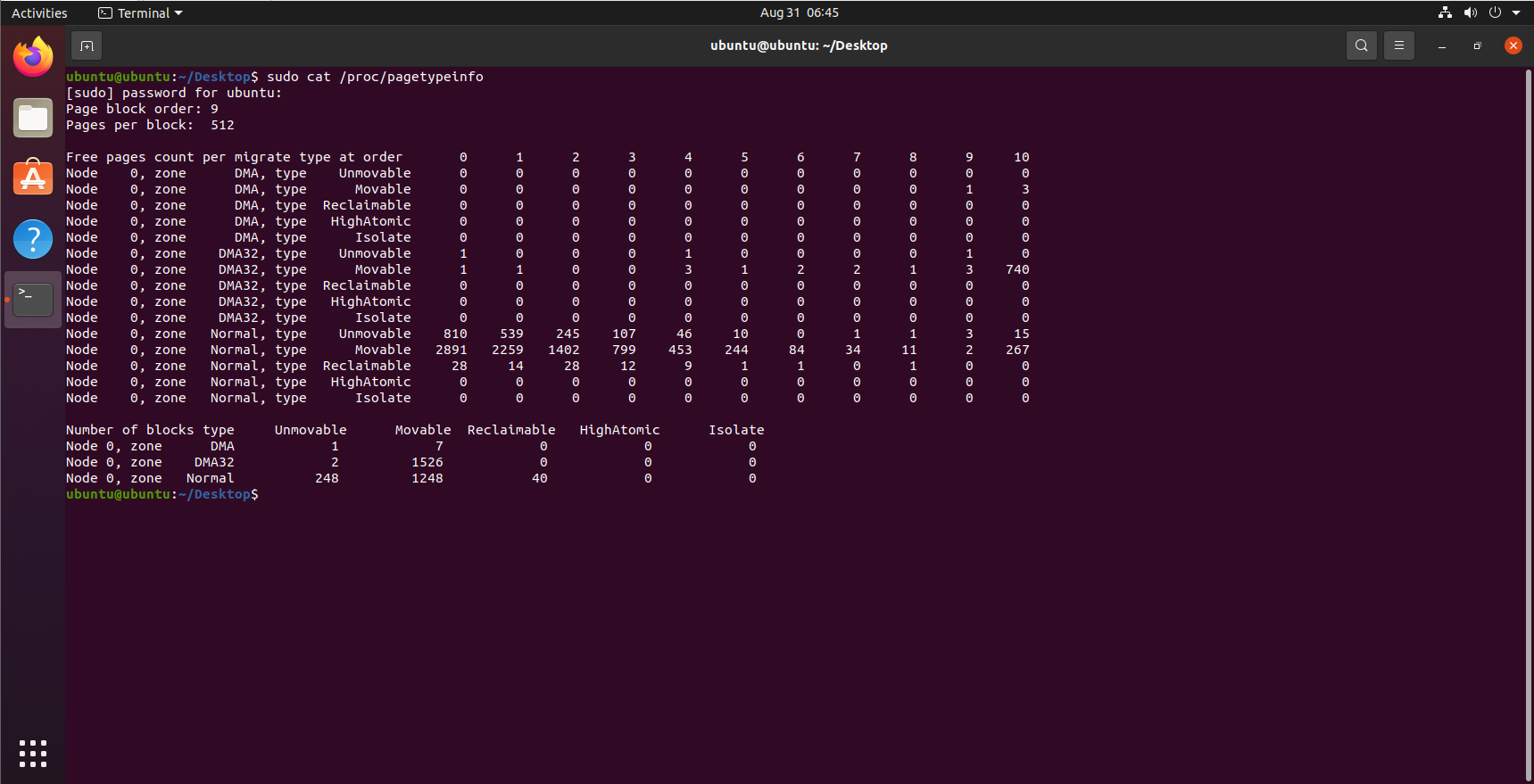
虛擬可移動記憶體域
可移動頁給與記憶體分配一種層級分配的能力(按照備用列表順序分配)。但是可能會導致不可移動頁侵入可移動頁區域。
內核在2.6.23版本將虛擬可移動記憶體域(ZONE_MOVABLE)這一功能加入內核。其基本思想為:可用的物理記憶體劃分為兩個記憶體域,一個用於可移動分配,一個用於不可移動分配。這會自動防止不可移動頁向可移動記憶體域引入碎片。
取決於體繫結構和內核配置,ZONE_MOVABLE記憶體域可能位於高端或普通記憶體域:
enum zone_type {
...
ZONE_NORMAL
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
MAX_NR_ZONES
};
與系統中所有其他的記憶體域相反,ZONE_MOVABLE並不關聯到任何硬體上有意義的記憶體範圍。實際上,該記憶體域中的記憶體取自高端記憶體域或普通記憶體域,因此我們在下文中稱ZONE_MOVABLE是一個虛擬記憶體域。
那麼用於可移動分配和不可移動分配的記憶體域大小如何分配呢?系統提供了兩個參數用來分配這兩個區域的大小:
- kernelcore參數用來指定用於不可移動分配的記憶體數量,即用於既不能回收也不能遷移的記憶體數量。剩餘的記憶體用於可移動分配。
- 還可以使用參數movablecore控制用於可移動記憶體分配的記憶體數量
輔助函數find_zone_movable_pfns_for_nodes用於計算進入ZONE_MOVABLE的記憶體數量。如果kernelcore和movablecore參數都沒有指定,find_zone_movable_pfns_for_nodes會使ZONE_MOVABLE保持為空,該機制處於無效狀態。
但是ZONE_MOVABLE記憶體域的記憶體會按照如下情況分配:
- 用於不可移動分配的記憶體會平均地分佈到所有記憶體結點上。
- 只使用來自最高記憶體域的記憶體。在記憶體較多的32位系統上,這通常會是ZONE_HIGHMEM,但是對於64位系統,將使用ZONE_NORMAL或ZONE_DMA32。
為ZONE_MOVABLE記憶體域分配記憶體後,會保存在如下位置:
- 用於為虛擬記憶體域ZONE_MOVABLE提取記憶體頁的物理記憶體域,保存在全局變數movable_zone中;
- 對每個結點來說,zone_movable_pfn[node_id]表示ZONE_MOVABLE在movable_zone記憶體域中所取得記憶體的起始地址。
伙伴系統頁面分配與回收
就伙伴系統的介面而言,NUMA或UMA體繫結構是沒有差別的,二者的調用語法都是相同的。所有函數的一個共同點是:只能分配2的整數冪個頁。本節我們會按照如下順序介紹伙伴系統頁面的分配與回收:
- 介紹伙伴系統API介面
- 介紹API的核心邏輯
我們會按照分配頁面與回收頁面兩節分別介紹。
分配頁面
分配頁面API
分配頁面的API包含如下4個:
| API | 描述 |
|---|---|
| alloc_pages(mask, order) | 分配\(2^{order}\)頁並返回一個struct page的實例,表示分配的記憶體塊的起始頁 |
| alloc_page(mask) | alloc_pages(mask,0)的改寫,只分配1頁記憶體 |
| get_zeroed_page(mask) | 分配一頁並返回一個page實例,頁對應的記憶體填充0 |
| __get_free_pages(mask, order) | 分配頁面,但返回分配記憶體塊的虛擬地址 |
| get_dma_pages(gfp_mask, order) | 用來獲得適用於DMA的頁 |
在空閑記憶體無法滿足請求以至於分配失敗的情況下,所有上述函數都返回空指針(alloc_pages和alloc_page)或者0(get_zeroed_page、__get_free_pages和__get_free_page)。
可以看到,每個分配頁面的介面都包含一個mask參數,該參數是記憶體修飾符,用來控制記憶體分配的邏輯,例如記憶體在哪個記憶體區分配等,為了控制這一點,內核提供瞭如下巨集:
/* GFP_ZONEMASK中的記憶體域修飾符(參見linux/mmzone.h,低3位) */
#define __GFP_DMA ((__force gfp_t)0x01u)
#define __GFP_HIGHMEM ((__force gfp_t)0x02u)
#define __GFP_DMA32 ((__force gfp_t)0x04u)
...
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 頁是可移動的 */
註意:設置__GFP_MOVABLE不會影響內核的決策,除非它與__GFP_HIGHMEM同時指定。在這種情況下,會使用特殊的虛擬記憶體域ZONE_MOVABLE滿足記憶體分配請求。
這裡給出其他一些掩碼的含義(需要用時現查):

實際上,上面所有用於分配頁面的API,最終都是通過alloc_pages_node方法進行記憶體分配的,其調用關係如下:
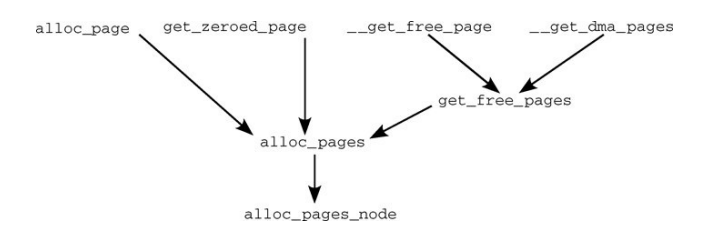
後面我們將主要討論alloc_pages_node方法的具體邏輯。
alloc_pages_node:分配頁面的具體邏輯
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (unlikely(order >= MAX_ORDER))
return NULL;
/* 未知結點即當前結點 */
if(nid< 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order,NODE_DATA(nid)->node_zonelists + gfp_zone(gfp_mask));
}
alloc_pages_node方法很簡單,進行了一些簡單的檢查,並將頁面的分配邏輯交由__alloc_pages方法處理。這裡我們又見到了老朋友zonelist,如果不熟悉請參見該鏈接。gfp_zone方法,負責根據gfp_mask選擇分配記憶體的記憶體域,因此可以通過指針運算,選擇合適的zonelist(記憶體區選擇備用列表)。
分配頁面需要大量的檢查以及選擇合適的記憶體域進行分配,在完成這些工作之後,就可以進行真正的分配物理記憶體。__alloc_pages方法就是按照這個邏輯編寫的。
__alloc_pages會根據現實情況調用get_page_from_freelist方法選擇合適的記憶體域,進行記憶體分配,然而記憶體域是否有空閑空間,也有一定的條件,這個條件由zone_watermark_ok函數判斷。這裡的判斷條件主要和zone的幾個watermark有關,即pages_min、pages_low、pages_high,這三個參數的具體含義可以參考第二章的講解
內核提供瞭如下幾個巨集,用於控制到達各個水印指定的臨界狀態時的行為:
#define ALLOC_NO_WATERMARKS 0x01 /* 完全不檢查水印 */
#define ALLOC_WMARK_MIN 0x02 /* 使用pages_min水印 */
#define ALLOC_WMARK_LOW 0x04 /* 使用pages_low水印 */
#define ALLOC_WMARK_HIGH 0x08 /* 使用pages_high水印 */
#define ALLOC_HARDER 0x10 /* 試圖更努力地分配,即放寬限制 */
#define ALLOC_HIGH 0x20 /* 設置了__GFP_HIGH */
#define ALLOC_CPUSET 0x40 /* 檢查記憶體結點是否對應著指定的CPU集合 */
前幾個標誌表示在判斷頁是否可分配時,需要考慮哪些水印。
- 預設情況下(即沒有因其他因素帶來的壓力而需要更多的記憶體),只有記憶體域包含頁的數目至少為zone->pages_high時,才能分配頁。這對應於ALLOC_WMARK_HIGH標誌。
- 如果要使用較低(zone->pages_low)或最低(zone->pages_min)設置,則必須相應地設置ALLOC_WMARK_MIN或ALLOC_WMARK_LOW
- ALLOC_HARDER通知伙伴系統在急需記憶體時放寬分配規則
- 在分配高端記憶體域的記憶體時,ALLOC_HIGH進一步放寬限制
- ALLOC_CPUSET告知內核,記憶體只能從當前進程允許運行的CPU相關聯的記憶體結點分配,當然該選項只對NUMA系統有意義
zone_watermark_ok方法,使用了ALLOC_HIGH和ALLOC_HARDER標誌,其代碼如下:
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
int classzone_idx, int alloc_flags)
{
/* free_pages可能變為負值,沒有關係 */
long min = mark;
long free_pages = zone_page_state(z, NR_FREE_PAGES) -(1 << order) + 1;
int o;
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (alloc_flags & ALLOC_HARDER)
min -= min / 4;
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return 0;
for(o= 0;o <order;o++){
/* 在下一階,當前階的頁是不可用的 */
free_pages -= z->free_area[o].nr_free << o;
/* 所需高階空閑頁的數目相對較少 */
min >>= 1;
if (free_pages <= min)
return 0;
}
return 1;
}
註意,zone_watermark_ok方法中的mark參數就是zone中的水印,根據設置的ALLOC_WMARK_*標誌的不同,mark選擇對應的pages_*水印,zone_page_state方法用於訪問記憶體域中的統計量,由於提供了標誌NR_FREE_PAGES,這裡獲取的是記憶體域中空閑頁的數目。
可以看到當flag設置了ALLOC_HIGH和ALLOC_HARDER後,min的閾值變小了,這也就是所謂的放寬了限制。當前記憶體域需要滿足如下兩個條件才能進行記憶體分配:
- min+lowmem_reserve中指定的緊急分配值 < 記憶體域中的空閑頁數目
- 對於指定order前的每一個分配階,都要高於當前階的min值(每升高一階,所需空閑頁的最小值折半)
瞭解了記憶體域的可用性條件後,我們將討論,哪個方法負責從備用列表中選擇合適的記憶體域。該方法為get_page_from_freelist,如果查找到對應的記憶體域,將發起實際的分配操作。
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, int alloc_flags)
{
struct zone **z;
struct page *page = NULL;
int classzone_idx = zone_idx(zonelist->zones[0]);
struct zone *zone;
...
/*
* 掃描zonelist,尋找具有足夠空閑空間的記憶體域。
* 請參閱kernel/cpuset.c中cpuset_zone_allowed()的註釋。
*/
z = zonelist->zones;
do {
...
zone = *z;
//cpuset_zone_allowed_softwall是另一個輔助函數,用於檢查給定記憶體域是否屬於該進程允許運行的CPU
if ((alloc_flags & ALLOC_CPUSET) &&!cpuset_zone_allowed_softwall(zone, gfp_mask))
continue;
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
unsigned long mark;
if (alloc_flags & ALLOC_WMARK_MIN)
mark = zone->pages_min;
else if (alloc_flags & ALLOC_WMARK_LOW)
mark = zone->pages_low;
else
mark = zone->pages_high;
if (!zone_watermark_ok(zone, order, mark,classzone_idx, alloc_flags))
continue;
}
page = buffered_rmqueue(*z, order, gfp_mask);
if (page) {
zone_statistics(zonelist, *z);
break;
}
} while (*(++z) != NULL);
return page;
}
可以看到do..while迴圈遍歷了整個備用列表,通過zone_watermark_ok方法查找第一個可用的記憶體域,查找到後進行記憶體分配(buffered_rmqueue方法負責處理分配邏輯)。
__alloc_pages通過調用get_page_from_freelist方法進行實際的分配,但是,分配記憶體的時機是一個很複雜的問題,在現實生活中,記憶體並不總是充足的,為了充分解決這些情況,__alloc_pages方法考慮了諸多情況:
-
記憶體充足時,調用
get_page_from_freelist方法直接分配:struct page * fastcall __alloc_pages(gfp_t gfp_mask, unsigned int order, struct zonelist *zonelist) { const gfp_t wait = gfp_mask & __GFP_WAIT; struct zone **z; struct page *page; struct reclaim_state reclaim_state; struct task_struct *p = current; int do_retry; int alloc_flags; int did_some_progress; might_sleep_if(wait); restart: z = zonelist->zones; /* 適合於gfp_mask的記憶體域列表 */ if (unlikely(*z == NULL)) { /* *如果在沒有記憶體的結點上使用GFP_THISNODE,導致zonelist為空,就會發生這種情況 */ return NULL; } page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, order,zonelist, ALLOC_WMARK_LOW|ALLOC_CPUSET); if (page) goto got_pg; ...可以看到,第一次嘗試分配記憶體時,系統對分配的要求會比較嚴格:
- gft_mask設置了__GFP_HARDWALL:它限制只在分配到當前進程的各個CPU所關聯的結點分配記憶體。
- flag設置了ALLOC_WMARK_LOW和ALLOC_CPUSET(這兩個含義代碼註釋里有,這裡就不解釋了)
-
首次分配失敗後,內核會喚醒負責換出頁的kswapd守護進程,寫回或換出很少使用的頁。在交換守護進程喚醒後,再次嘗試
get_page_from_freelist:... for (z = zonelist->zones; *z; z++) wakeup_kswapd(*z, order); alloc_flags = ALLOC_WMARK_MIN; if ((unlikely(rt_task(p)) && !in_interrupt()) || !wait) alloc_flags |= ALLOC_HARDER; if (gfp_mask & __GFP_HIGH) alloc_flags |= ALLOC_HIGH; if (wait) alloc_flags |= ALLOC_CPUSET; page = get_page_from_freelist(gfp_mask, order, zonelist, alloc_flags); if (page) goto got_pg; ... }此處的策略不僅換出了非常用頁,而且放寬了水印的判斷條件:
- alloc_flags成為了ALLOC_WMARK_MIN
- 對實時進程和指定了__GFP_WAIT標誌因而不能睡眠的調用,會設置ALLOC_HARDER。
-
如果設置了PF_MEMALLOC或進程設置了TIF_MEMDIE標誌(在這兩種情況下,內核不能處於中斷上下文中),內核會忽略所有水印,調用
get_page_from_freelist方法:rebalance: if (((p->flags & PF_MEMALLOC) || unlikely(test_thread_flag(TIF_MEMDIE)))&& !in_interrupt()) { if (!(gfp_mask & __GFP_NOMEMALLOC)) { nofail_alloc: /* 再一次遍歷zonelist,忽略水印 */ page = get_page_from_freelist(gfp_mask, order,zonelist, ALLOC_NO_WATERMARKS); if (page) goto got_pg; if (gfp_mask & __GFP_NOFAIL) { congestion_wait(WRITE, HZ/50); goto nofail_alloc; } } goto nopage; } ...通常只有在分配器自身需要更多記憶體時,才會設置PF_MEMALLOC,而只有線上程剛好被OOM killer機制選中時,才會設置TIF_MEMDIE
這裡的兩個goto語句負責處理此種情況下,記憶體分配失敗的情況:
- 設置了__GFP_NOMEMALLOC。該標誌禁止使用緊急分配鏈表(如果忽略水印,這可能是最佳途徑),因此無法在禁用水印的情況下調用get_page_from_freelist。跳轉到nopage處,通過內核消息將失敗報告給用戶,並將NULL指針返回調用者
- 在忽略水印的情況下,get_page_from_freelist仍然失敗了,這種情況下會放棄搜索,報告錯誤消息。如果設置了__GFP_NOFAIL,內核會進入無限迴圈(跳轉到第4行的標號nofail_alloc),重覆本段內容。
-
如果上述3種情況都沒有成功分配記憶體,內核會進行一些耗時的操作。。前提是分配掩碼中設置了__GFP_WAIT標誌,因為隨後的操作可能使進程睡眠(為了使得kswapd取得一些進展)。
if (!wait) goto nopage; cond_schedule(); ...如果wait標誌沒有被設置,這裡會放棄分配。如果設置了,內核通過cond_reschedᨀ供了重調度的時機。這防止了花費過多時間搜索記憶體,以致於使其他進程處於饑餓狀態。
分頁機制提供了一個目前尚未使用的選項,將很少使用的頁換出到塊介質,以便在物理記憶體中產生更多空間。但該選項非常耗時,還可能導致進程睡眠狀態。try_to_free_pages是相應的輔助函數,用於查找當前不急需的頁,以便換出。
/* 我們現在進入同步回收狀態 */ p->flags |= PF_MEMALLOC; ... did_some_progress = try_to_free_pages(zonelist->zones, order, gfp_mask); ... p->flags &= ~PF_MEMALLOC; cond_resched(); ...該調用被設置/清除PF_MEMALLOC標誌的代碼間隔起來。try_to_free_pages自身可能也需要分配新的記憶體。由於為獲得新記憶體還需要額外分配一點記憶體(相當矛盾的情形),該進程當然應該在記憶體管理方面享有最高優先順序,上述標誌的設置即達到了這一目的。try_to_free_pages會返回增加的空閑頁數目。
接下來,如果try_to_free_pages釋放了一些頁,那麼內核再次調用get_page_from_freelist嘗試分配記憶體:
if (likely(did_some_progress)) { page = get_page_from_freelist(gfp_mask, order,zonelist, alloc_flags); if (page) goto got_pg; } else if ((gfp_mask & __GFP_FS) && !(gfp_mask & __GFP_NORETRY)) { ...如果內核可能執行影響VFS層的調用而又沒有設置GFP_NORETRY,那麼調用OOM killer:
/* OOM killer無助於高階分配,因此失敗 */ if (order > PAGE_ALLOC_COSTLY_ORDER) { clear_zonelist_oom(zonelist); goto nopage; } out_of_memory(zonelist, gfp_mask, order); goto restart; }out_of_memory函數函數選擇一個內核認為犯有分配過多記憶體“罪行”的進程,並殺死該進程。這有很大幾率騰出較多的空閑頁,然後跳轉到標號restart,重試分配記憶體的操作。但殺死一個進程未必立即出現多於\(2^{PAGE_COSTLY_ORDER}\)頁的連續記憶體區(其中PAGE_COSTLY_ORDER_PAGES通常設置為3),因此如果當前要分配如此大的記憶體區,那麼內核會饒恕所選擇的進程,不執行殺死進程的任務,而是承認失敗並跳轉到nopage。
如果設置了__GFP_NORETRY,或內核不允許使用可能影響VFS層的操作,會判斷所需分配的長度,作出不同的決定:
... do_retry = 0; if (!(gfp_mask & __GFP_NORETRY)) { if ((order <= PAGE_ALLOC_COSTLY_ORDER) ||(gfp_mask & __GFP_REPEAT)) do_retry = 1; if (gfp_mask & __GFP_NOFAIL) do_retry = 1; } if (do_retry) { congestion_wait(WRITE, HZ/50); goto rebalance; } nopage: if (!(gfp_mask & __GFP_NOWARN) && printk_ratelimit()) { printk(KERN_WARNING "%s: page allocation failure."" order:%d, mode:0x%x\n"p->comm, order, gfp_mask); dump_stack(); show_mem(); } got_pg: return page; }- 如果分配長度小於\(2^{PAGE_ALLOC_COSTLY_ORDER}\)=8頁,或設置了__GFP_REPEAT標誌,則內核進入無限迴圈。在這兩種情況下,是不能設置GFP_NORETRY的。因為如果調用者不打算重試,那麼進入無限迴圈重試並沒有意義。內核會跳轉回rebalance標號,即 的入口,並一直等待,直至找到適當大小的記憶體塊——根據所要分配的記憶體大小,內核可以假定該無限迴圈不會持續太長時間。內核在跳轉之前會調用congestion_wait,等待塊設備層隊列釋放,這樣內核就有機會換出頁。
- 在所要求的分配階大於3但設置了__GFP_NOFAIL標誌的情況下,內核也會進入上述無限迴圈,因為該標誌無論如何都不允許失敗。
- 如果情況不是這樣,內核只能放棄,並向用戶返回NULL指針,並輸出一條記憶體請求無法滿足的警告消息。
總結
本節主要總結了伙伴系統中__alloc_pages方法的主要流程,由於後續內容過多,這裡會分為多個小結總結。


