
本文分享自華為雲社區《【手把手帶你玩轉HetuEngine】(三)HetuEngine資源規劃》,作者: HetuEngine九級代言 。 HetuEngine支持在服務層角色實例和計算實例兩個維度進行資源規劃,並且支持在高併發場景下通過啟動多個計算實例進行負載分擔和均衡,從而滿足各種業務場景下的資 ...
本文分享自華為雲社區《【手把手帶你玩轉HetuEngine】(三)HetuEngine資源規劃》,作者: HetuEngine九級代言 。
HetuEngine支持在服務層角色實例和計算實例兩個維度進行資源規劃,並且支持在高併發場景下通過啟動多個計算實例進行負載分擔和均衡,從而滿足各種業務場景下的資源規劃需求。
一、HetuEngine角色實例資源規劃
HetuEngine能夠通過服務層對計算實例進行服務化管理,服務層的角色實例包括HSBroker、HSConsole、HSFabric、QAS。
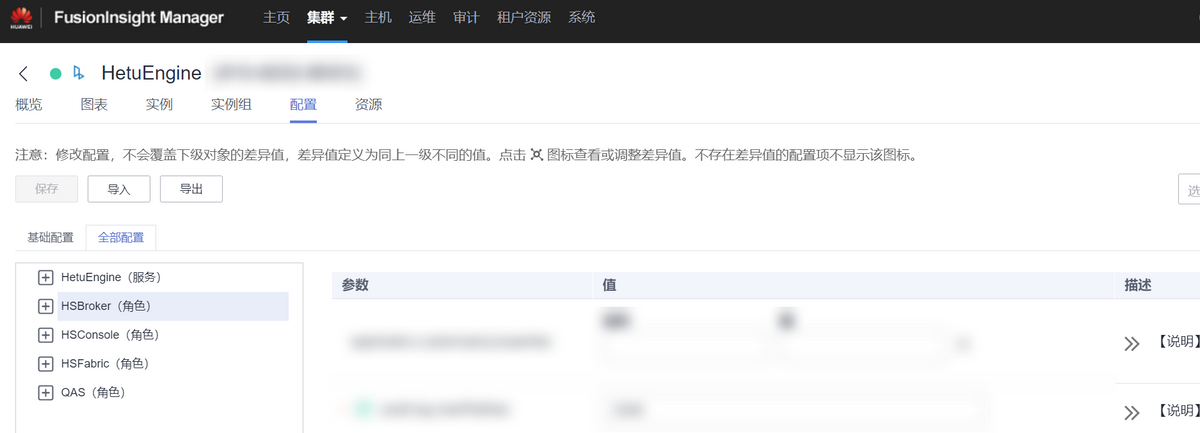
可以通過HetuEngine服務層配置對實例參數進行調整,如下圖所示。
計算實例資源規劃
HetuEngine的計算實例是一個運行在Yarn容器內的基於記憶體的計算引擎,它一般包含1~2個Coordinator和N個worker,其中Coordinator是管理節點,提供SQL接收、SQL解析、生成執行計劃、執行計劃優化、分派任務和資源調度等能力,如果需要計算實例支持高可用,必須部署兩個Coordinator。Worker是工作節點,提供數據源數據並行拉取,分散式SQL計算等能力。從8.2.1版本開始,HetuEngine支持單租戶多計算實例的形態。
Yarn的租戶隊列、HetuEngine計算實例、計算實例的Coordinator 和 Worker 之間的關係如下圖所示:
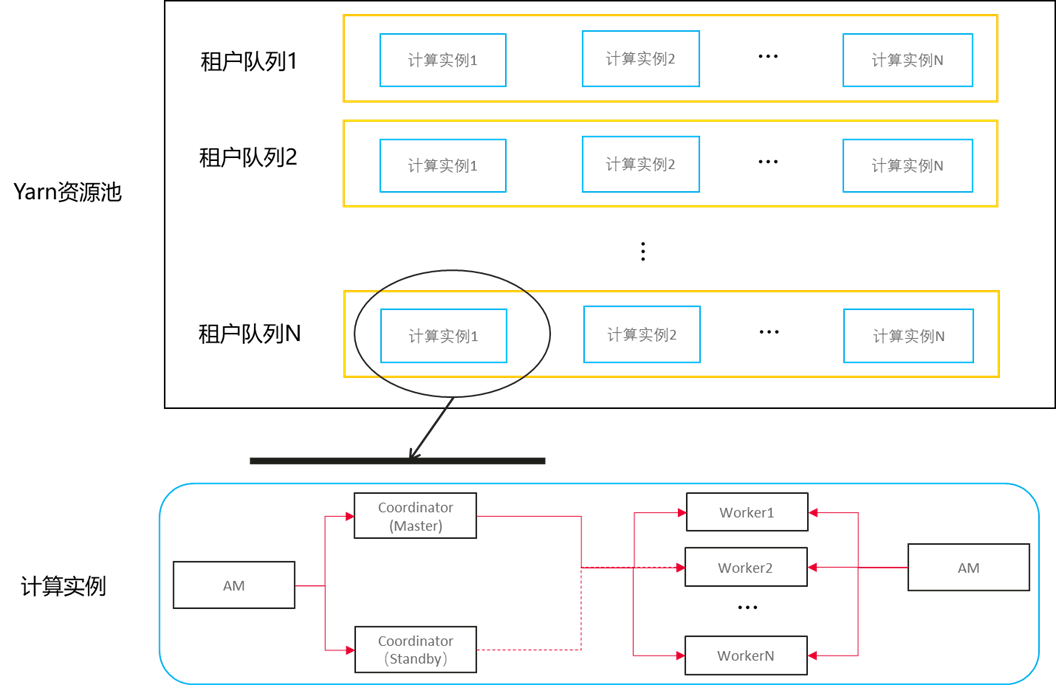
Yarn資源池分配示意圖(AM為Yarn的應用管理器)
HetuEngine支持在HSConsole界面對計算實例進行管理,並且能夠對每個計算實例進行差異化配置,如下圖所示

並且支持在創建計算實例的時候添加計算實例級別的自定義參數配置:

HetuEngine計算實例選型與記憶體配置建議
HetuEngine的計算實例作為SQL查詢引擎,是一個純記憶體的計算引擎。因此,從性能的角度考慮,需要給計算實例儘可能多的記憶體資源。
由於HetuEngine的計算實例是onYarn模式,Coordinator和Worker都是運行在Yarn的NodeManager節點上的。
coordinator & worker資源配置推薦
Coordinator建議部署的節點為2個,Worker按實際資源情況部署。
• Coordaintor和Worker的記憶體值配置要求為:
1. 要求yarn.scheduler.maximum-allocation-mb > coordaintor/worker容器記憶體 > JVM記憶體。
2. 建議yarn.scheduler.maximum-allocation-mb記憶體為節點物理記憶體的90%,coordaintor/worker容器記憶體比yarn.scheduler.maximum-allocation-mb,JVM記憶體 為coordaintor/worker容器記憶體比大小的80%。
3. 建議一個節點啟動一個conatiner的形式部署,避免產生記憶體碎片從未造成資源浪費。
4. coordaintor和worker+AM所用到的記憶體資源不能超出該租戶的可使用最大記憶體資源。
• Coordaintor和Worker的CPU值配置要求為:
1. yarn.scheduler.maximum-allocation-vcores 大於coordaintor和worker的vcore。
2. 建議coordaintor和worker的vcore的值比yarn.scheduler.maximum-allocation-vcores的值少2~10個。
3. coordaintor和worker+AM所用到的core資源不能超出該租戶的可使用最大core資源。
隊列資源規劃配置示例
計算實例規模估算
根據業務數據量大致估算計算實例worker的大小和數量
Yarn參數、計算實例記憶體配置
-
Yarn參數調整
調整yarn上container最大核數和最大記憶體相關參數以滿足計算實例估算規模大小要求,在yarn服務級別進行修改
-
計算實例記憶體調整
HetuEngine的配置(建議CN和Worker配置保持一致):具體修改點如下圖所示,在HSConsole頁面,選擇計算實例,點擊"配置",即可在彈出視窗按下圖修改:
3. 高併發下多實例配置推薦
單HetuEngine計算實例的併發建議低於50,高併發場景下建議啟動多個計算實例進行負載分擔避免性能明顯下降。HetuEngine支持兩種方式啟動多計算實例,一是單租戶單實例的模式,二是單租戶多實例的模式。
方式1: 單租戶單實例的部署模式。
可將資源分成多個資源池,每個租戶獨占一個資源池,每個租戶啟動一個計算實例的方式進行部署。例如將資源分成default、online、offline 3個資源池,分別給default、online、offline三個租戶使用,每個租戶啟動一個計算實例,不同的業務將提交到不同的資源隊列:
方式2:單租戶多實例的部署模式。
320版本後,HetuEngine支持通過配置在單個租戶內啟動多個計算實例,如下圖所示,不同的業務都提交到同一租戶中的隊列,HetuEngine能夠自動實現單租戶內的各個計算實例均衡負載。
二、HetuEngine數據源對接
HetuEngine能夠支持跨源(多種數據源,如Hive,HBase,GaussDB(DWS),Elasticsearch,ClickHouse等),跨域(多個地域或數據中心)的快速聯合查詢,尤其適用於Hadoop集群(FusionInsight MRS)的Hive、Hudi數據的互動式快速查詢場景。本章將對HetuEngine的數據源對接能力與操作實踐進行介紹。
數據源對接概述
當前HetuEngine數據源對接支持以下幾種能力:
1.支持對接Hive、HBase、GaussDB(DWS),Elasticsearch,ClickHouse、Hudi、IoTDB等多種數據源,並支持對接跨域HetuEngine
2.支持多種數據源的快速聯合查詢並提供可視化的數據源配置、管理頁面,用戶可通過HSConsole界面快速添加數據源,併進行差異化配置
3.數據源動態生效,無需重啟計算實例
4.支持數據源下推
多數據源對接
當前版本HetuEngine支持對接的數據源如表1所示
可視化數據源管理界面
HetuEngine能夠支持多種數據源的快速聯合查詢並提供可視化的數據源配置、管理頁面,用戶可通過HSConsole界面快速添加數據源,併進行差異化配置。操作示例如下圖所示
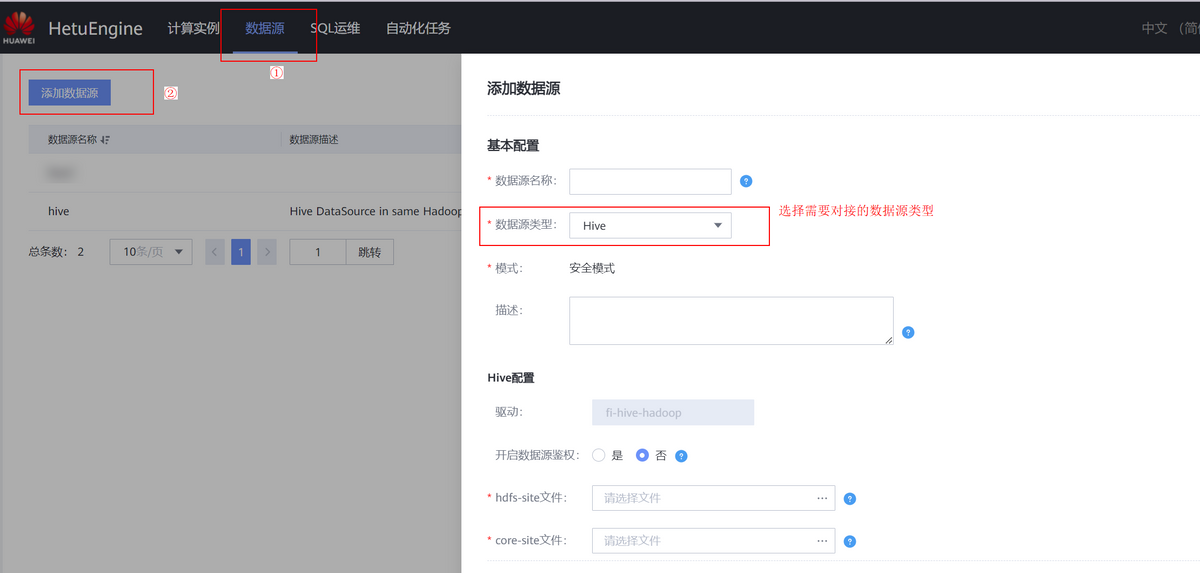
可以通過最下方“自定義配置”添加相應數據源的自定義配置
數據源動態生效
在HSConsole界面或者使用HSConsole Rest API對數據源的添加、配置、刪除等操作支持動態生效,無須重啟計算實例。
數據源動態生效時間預設為60秒。如需修改動態生效時間,在計算實例自定義配置添加如下參數,例如:
catalog.scanner-interval =120s
數據源計算下推
HetuEngine支持查詢下推(pushdown),它能把查詢,或者部分查詢,下推到連接的數據源。這意味著特殊的謂詞,聚合函數或者其它一些操作,可以被傳遞到底層資料庫或者文件系統進行處理。查詢下推能帶來以下好處:
-
提升整體的查詢性能。
-
減少HetuEngine和數據源之間的網路流量。
-
減少遠端數據源的負載。
HetuEngine對查詢下推的具體支持情況,依賴於具體的Connector,以及Connector相關的底層數據源或存儲系統。


