
[TOC] ## 類型的基本歸類 **整形家族:** ```c char unsigned char signed char short unsigned short [int] signed short [int] int unsigned int signed int long unsigned ...
目錄
類型的基本歸類
整形家族:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
補充:
char是signed char還是unsigned char,C語言標準並沒有規定,取決於編譯器。
int 是signe int,short是signed short。
浮點數家族:
float
double
構造類型:
> 數組類型
> 結構體類型 struct
> 枚舉類型 enum
> 聯合類型 union
空類型:
void 表示空類型(無類型),通常應用於函數的返回類型、函數的參數、指針類型。
整形在記憶體中的存儲
一個變數的創建是要在記憶體中開闢空間的。空間的大小是根據不同的類型而決定的。
int a = 20;
int b = -10;
該段代碼為 a 分配四個位元組的空間。
那如何存儲?
原碼、反碼、補碼
電腦中的整數有三種2進位表示方法,即原碼、反碼和補碼。
三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”,而數值位正數的原、反、補碼都相同。
負整數的三種表示方法各不相同。
原碼:直接將數值按照正負數的形式翻譯成二進位就可以得到原碼。
反碼:將原碼的符號位不變,其他位依次按位取反就可以得到反碼。
補碼:反碼+1就得到補碼。
對於整形來說:數據存放記憶體中其實存放的是補碼。
在電腦系統中,數值一律用補碼來表示和存儲。原因在於,使用補碼,可以將符號位和數值域統一處理;同時,加法和減法也可以統一處理(CPU只有加法器)此外,補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬體電路。
在記憶體中的存儲:
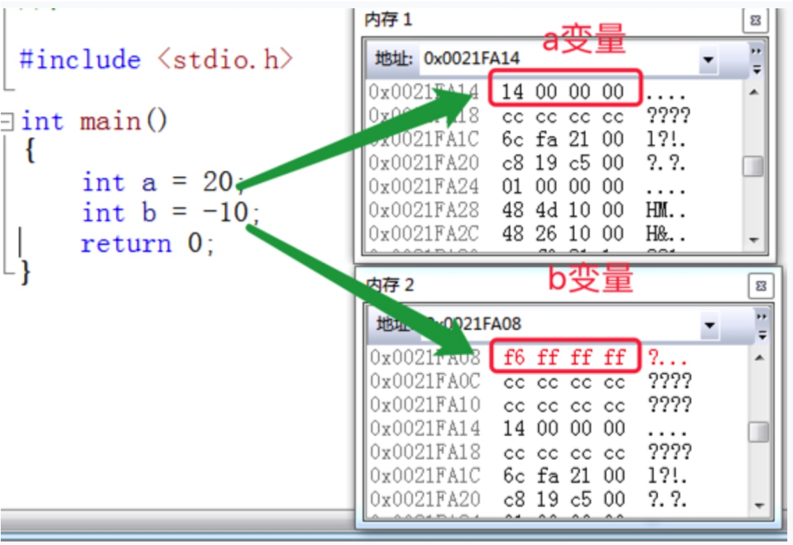
可以看到對於a和b分別存儲的是補碼。但是我們發現順序有點不對勁。
這是又為什麼?
大小端介紹
什麼大端小端:
大端(存儲)模式,是指數據的低位保存在記憶體的高地址中,而數據的高位,保存在記憶體的低地址中;
小端(存儲)模式,是指數據的低位保存在記憶體的低地址中,而數據的高位,,保存在記憶體的高地址中。
為什麼有大端和小端:
為什麼會有大小端模式之分呢?這是因為在電腦系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為8 bit。但是在C語言中除了8 bit的char之外,還有16 bit的short型,32 bit的long型(要看具體的編譯器),另外,對於位數大於8位的處理器,例如16位或者32位的處理器,由於寄存器寬度大於一個位元組,那麼必然存在著一個如何將多個位元組安排的問題。因此就導致了大端存儲模式和小端存儲模式。
例如:一個 16bit 的 short 型 x ,在記憶體中的地址為 0x0010 , x 的值為 0x1122 ,那麼 0x11 為高位元組, 0x22 為低位元組。對於大端模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,剛好相反。我們常用的 X86 結構是小端模式,而 KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬體來選擇是大端模式還是小端模式。
百度2015年系統工程師筆試題:
請簡述大端位元組序和小端位元組序的概念,設計一個小程式來判斷當前機器的位元組序。
//代碼1
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char *)&i);
}
int main()
{
int ret = check_sys();
if(ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
//代碼2
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
練習
下麵程式輸出什麼?(答案在後面)
1.
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
2.
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
}
3.
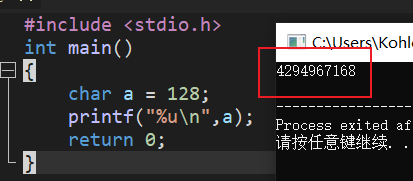
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
}
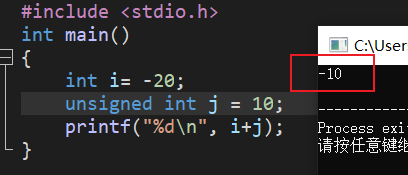
4.
int i= -20;
unsigned int j = 10;
printf("%d\n", i+j);
//按照補碼的形式進行運算,最後格式化成為有符號整數
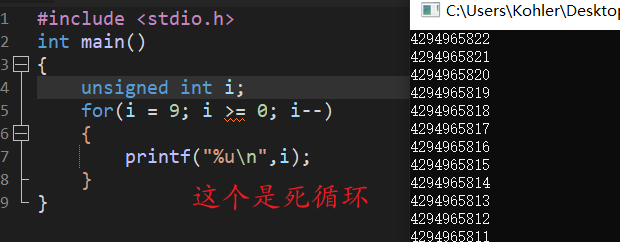
5.
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
6.
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
7.
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}



浮點型在記憶體中的存儲
常見的浮點數:3.14159 ,1E10
浮點數家族包括: float、double、long double 類型。
浮點數表示的範圍:float.h中定義
浮點數存儲的例子
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
return 0;
}
輸出的結果:

浮點數存儲規則
num 和 *pFloat 在記憶體中明明是同一個數,為什麼浮點數和整數的解讀結果會差別這麼大?
要理解這個結果,一定要搞懂浮點數在電腦內部的表示方法。
詳細解讀:
根據國際標準IEEE(電氣和電子工程協會) 754,任意一個二進位浮點數V可以表示成下麵的形式:
(-1)^S * M * 2^E
(-1)^S表示符號位,當S=0,V為正數;當S=1,V為負數。
M表示有效數字,大於等於1,小於2。
2^E表示指數位。
歡迎關註公眾號:“愚生淺末”。
舉例來說:
十進位的5.0,寫成二進位是 101.0 ,相當於 1.01×2^2 。
那麼,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十進位的-5.0,寫成二進位是 -101.0 ,相當於 -1.01×2^2 。那麼,S=1,M=1.01,E=2。
IEEE 754規定:
對於32位的浮點數,最高的1位是符號位S,接著的8位是指數E,剩下的23位為有效數字M。

對於64位的浮點數,最高的1位是符號位S,接著的11位是指數E,剩下的52位為有效數字M。
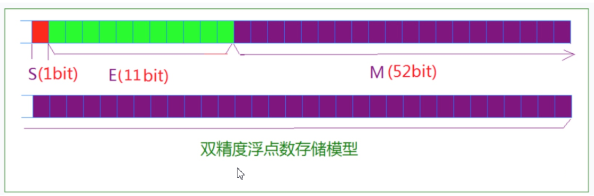
IEEE 754對有效數字M和指數E,還有一些特別規定。
前面說過, 1≤M<2 ,也就是說,M可以寫成 1.xxxxxx 的形式,其中xxxxxx表示小數部分。IEEE 754規定,在電腦內部保存M時,預設這個數的第一位總是1,因此可以被捨去,只保存後面的xxxxxx部分。比如保存1.01的時候,只保存01,等到讀取的時候,再把第一位的1加上去。這樣做的目的,是節省1位有效數字。以32位浮點數為例,留給M只有23位,將第一位的1捨去以後,等於可以保存24位有效數字。
至於指數E,情況就比較複雜。
首先,E為一個無符號整數(unsigned int)這意味著,如果E為8位,它的取值範圍為0255;如果E為11位,它的取值範圍為02047。但是,我們知道,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入記憶體時E的真實值必須再加上一個中間數,對於8位的E,這個中間數是127;對於11位的E,這個中間數是1023。比如,2^10的E是10,所以保存成32位浮點數時,必須保存成10+127=137,即
10001001。
然後,指數E從記憶體中取出還可以再分成三種情況:
E不全為0或不全為1
這時,浮點數就採用下麵的規則表示,即指數E的計算值減去127(或1023),得到真實值,再將有效數字M前加上第一位的1。
比如:
0.5(1/2)的二進位形式為0.1,由於規定正數部分必須為1,即將小數點右移1位,則為
1.0*2^(-1),其階碼為-1+127=126,表示為01111110,而尾數1.0去掉整數部分為0,補齊0到23位00000000000000000000000,則其二進位表示形式為:
0 01111110 00000000000000000000000
E全為0
這時,浮點數的指數E等於1-127(或者1-1023)即為真實值,有效數字M不再加上第一位的1,而是還原為0.xxxxxx的小數。這樣做是為了表示±0,以及接近於0的很小的數字。
E全為1
這時,如果有效數字M全為0,表示±無窮大(正負取決於符號位s);
好了,關於浮點數的表示規則,就說到這裡。
解釋前面的題目:
下麵,讓我們回到一開始的問題:為什麼 0x00000009 還原成浮點數,就成了 0.000000 ?
首先,將 0x00000009 拆分,得到第一位符號位s=0,後面8位的指數 E=00000000 ,
最後23位的有效數字M=000 0000 0000 0000 0000 1001。
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由於指數E全為0,所以符合上一節的第二種情況。因此,浮點數V就寫成:
V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146)
顯然,V是一個很小的接近於0的正數,所以用十進位小數表示就是0.000000。
再看例題的第二部分。
請問浮點數9.0,如何用二進位表示?還原成十進位又是多少?
首先,浮點數9.0等於二進位的1001.0,即1.001×2^3。
那麼,第一位的符號位s=0,有效數字M等於001後面再加20個0,湊滿23位,指數E等於3+127=130,
即10000010。
所以,寫成二進位形式,應該是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
這個32位的二進位數,還原成十進位,正是 1091567616 。
歡迎關註公眾號:“愚生淺末”。



