
提要:本系列文章主要參考`MIT 6.828課程`以及兩本書籍`《深入理解Linux內核》` `《深入Linux內核架構》`對Linux內核內容進行總結。 記憶體管理的實現覆蓋了多個領域: 1. 記憶體中的物理記憶體頁的管理 2. 分配大塊記憶體的伙伴系統 3. 分配較小記憶體的slab、slub、slob分 ...
提要:本系列文章主要參考MIT 6.828課程以及兩本書籍《深入理解Linux內核》 《深入Linux內核架構》對Linux內核內容進行總結。
記憶體管理的實現覆蓋了多個領域:
- 記憶體中的物理記憶體頁的管理
- 分配大塊記憶體的伙伴系統
- 分配較小記憶體的slab、slub、slob分配器
- 分配非連續記憶體塊的vmalloc分配器
- 進程的地址空間
記憶體管理實際分配的是物理記憶體頁,因此,瞭解物理記憶體分佈是十分必要的。
物理記憶體佈局
在初始化階段,內核必須建立一個物理地址映射來指定哪些物理地址範圍對內核可用而哪些不可用(或者因為它們映射硬體設備I/O的共用記憶體,或者因為相應的頁框含有BIOS數據)。
內核將下列頁框記為保留:
- 在不可用的物理地址範圍內的頁框
- 含有內核代碼和已初始化的數據結構的頁框。
保留頁框中的頁決不能被動態分配或交換到磁碟上。
例如,MIT 6.828 Lab2 -> Part 1: Physical Page Management -> page_init() 方法的實現中,註釋如下:
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
MIT 6.828中,主機的物理記憶體佈局如下:
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
註釋中的(1)(3)這兩項就是不可用的物理地址範圍內的頁框,而(4)就指的是含有內核代碼和已初始化的數據結構的頁框。一般來說,Linux內核安裝在RAM中從物理地址0x00100000(1MB)開始的地方(詳見https://www.cnblogs.com/yanlishao/p/17557668.html),當然這隻是一個固定的地址。那麼為何內核沒有安裝在RAM的第一MB開始的地方呢?由上圖可以看出,第一個MB中很多記憶體由BIOS和硬體使用,因此不是連續的,會被切分成很多小塊。具體描述如下:
- 頁框0由BIOS使用,存放加電自檢(Power-On Self-Test,POST)期間檢查到的系統硬體配置。因此,很多膝上型電腦的BIOS甚至在系統初始化後還將數據寫到該頁框。
- 物理地址從0x000a0000到0x000ffff的範圍通常留給BIOS常式,並且映射ISA圖形卡上的內部記憶體。這個區域就是所有IBM相容PC上從640KB到1MB之間著名的洞:物理地址存在但被保留,對應的頁框不能由操作系統使用。
- 第一個MB內的其他頁框可能由特定電腦模型保留。例如,IBM Thinkpnd把0xa0頁框映射到0x9f頁框。
但是由於各種硬體和BIOS不同,因此,保留記憶體也有差異,因此新近的電腦中,內核調用BIOS過程建立一組物理地址範圍和其對應的記憶體類型,最後映射成一張[start,end, TYPE]的表,TYPE表示記憶體是否可用。在系統啟動時,找到的記憶體區由內核函數print_memory_map顯示。形如下表:
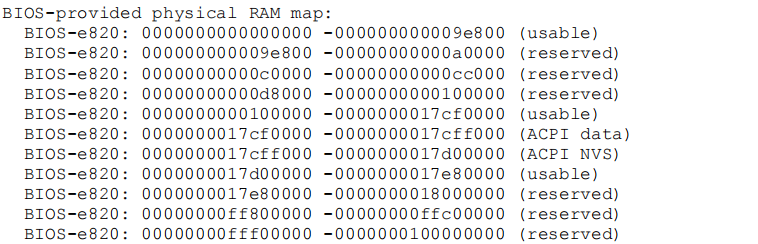
最後,下圖給出物理記憶體最低幾M位元組的佈局:
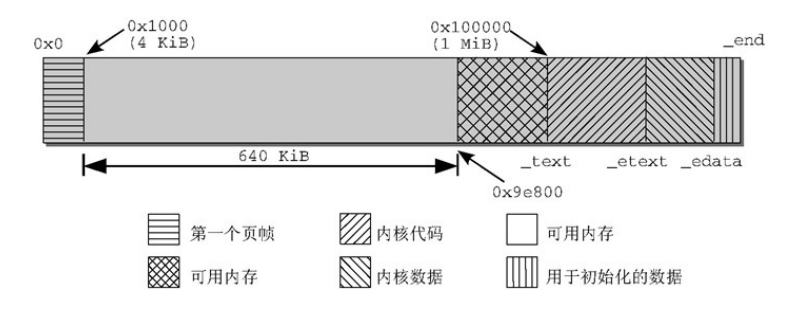
前1MB的記憶體佈局在前面已經介紹過,為了避免把內核裝入一組不連續的頁框里,Linux更願跳過RAM的第一個MB。因此,內核會裝載在物理地址0x00100000開始的地方。
- _text和 _etext是代碼段的起始和結束地址,包含了編譯後的內核代碼。
- 數據段位於 _etext和 _edata之間,保存了大部分內核變數。
- 初始化數據在內核啟動過程結束後不再需要(例如,包含初始化為0的所有靜態全局變數的BSS段)保存在最後一段,從_edata到_end。在內核初始化完成後,其中的大部分數據都可以從記憶體刪除,給應用程式留出更多空間。這一段記憶體區劃分為更小的子區間,以控制哪些可以刪除,哪些不能刪除,但這對於我們現在的討論沒多大意義。
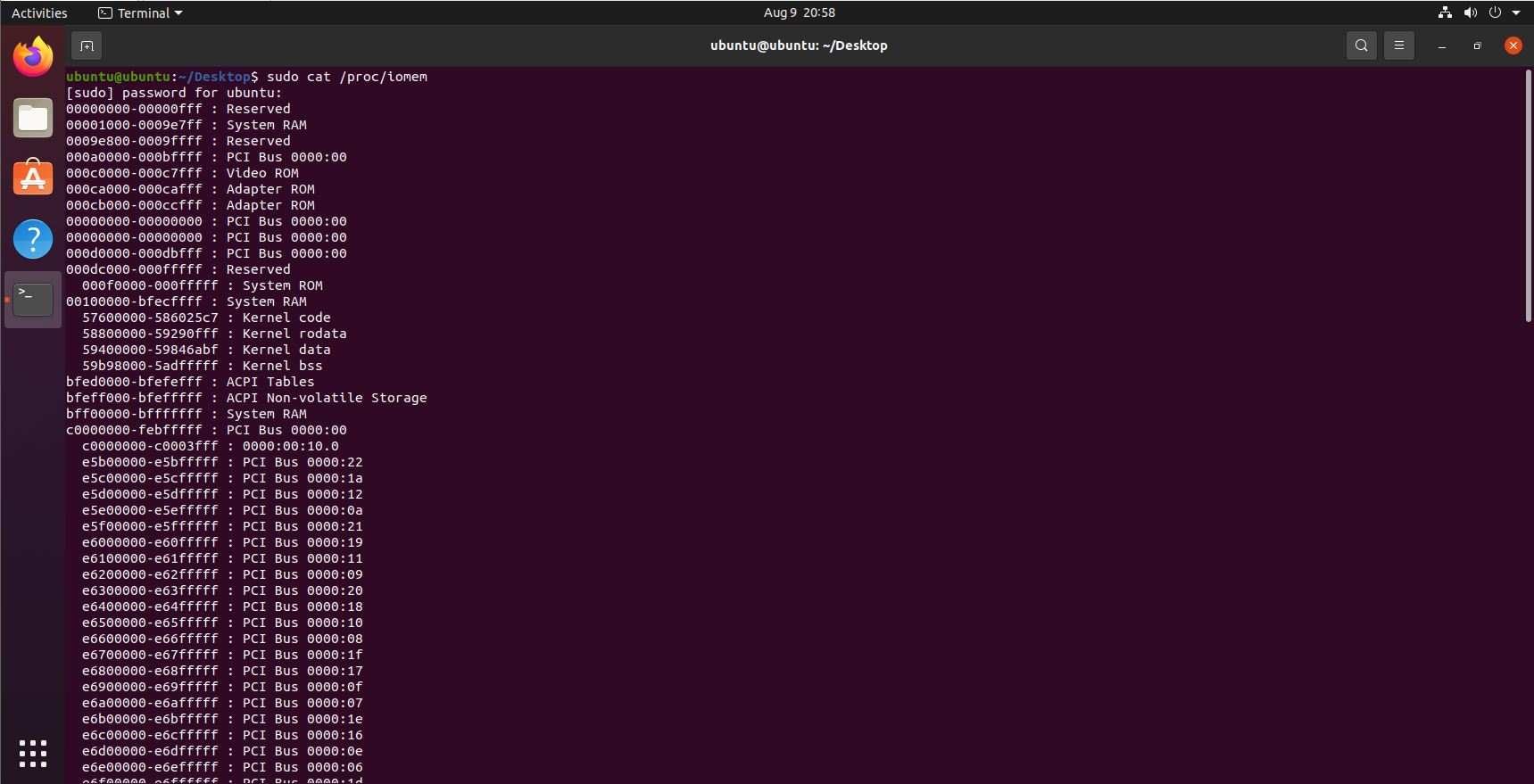
在運行內核時,可以通過/proc/iomem獲得內核的相關信息:
共用存儲型多處理機模型
本部分引用知乎大佬的文章,原鏈接
進行記憶體管理,一個很重要的因素就是CPU對記憶體的訪問方式,所以難免要對此部分進行介紹。
共用存儲型多處理機有兩種模型:
- 均勻存儲器存取(Uniform-Memory-Access,簡稱UMA)模型 (一致存儲器訪問結構)
- 非均勻存儲器存取(Nonuniform-Memory-Access,簡稱NUMA)模型 (非一致存儲器訪問結構)
UMA模型
UMA模型將多個處理機與一個集中的存儲器和I/O匯流排相連,物理存儲器被所有處理機均勻共用,所有處理機對所有的存儲單元都具有相同的存取時間。SMP(對稱型多處理機)系統有時也被稱之為一致存儲器訪問(UMA)結構體系。

UMA模型的最大特點就是共用。在該模型下,所有資源都是共用的,包括CPU、記憶體、I/O等。也正是由於這種特性,導致了UMA模型可伸縮性非常有限,因為記憶體是共用的,CPUs都會通過一條記憶體匯流排連接到記憶體上,這時,當多個CPU同時訪問同一個記憶體塊時就會產生衝突,因此當存儲器和I/O介面達到飽和的時候,增加處理器並不能獲得更高的性能。
NUMA模型
NUMA模型的基本特征是具有多個CPU模塊,每個CPU模塊又由多個CPU core(如4個)組成,並具有本地記憶體、I/O介面等,所以可以支持CPU對本地記憶體的快速訪問。這裡我們把CPU模塊稱為節點,每個節點被分配有本地存儲器,各個節點之間通過匯流排連接起來,這樣可以支持對其他節點中的本地記憶體的訪問,當然這時訪問遠的記憶體就要比訪問本地記憶體慢些。所有節點中的處理器都能夠訪問全部的物理存儲器。

NUMA模型的最大優勢是伸縮性。與UMA不同的是,NUMA具有多條記憶體匯流排,可以通過限制任何一條記憶體匯流排上的CPU數量以及依靠高速互連來連接各個節點,從而緩解UMA的瓶頸。NUMA理論上可以無限擴展的,但由於訪問遠地記憶體的延時遠遠超過訪問本地記憶體,所以當CPU數量增加時,系統性能無法線性增加。
內核處理
內核對一致和非一致記憶體訪問系統使用相同的數據結構,因此針對各種不同形式的記憶體佈局,各個演算法幾乎沒有什麼差別。在UMA系統上,只使用一個NUMA結點來管理整個系統記憶體。而記憶體管理的其他部分則相信它們是在處理一個偽NUMA系統。
根據對NUMA模型的描述,Linux將記憶體進行瞭如下劃分:
- 存儲節點(Node):是每個CPU對應的一個本地記憶體,在內核中表示為
pg_data_t的實例。因為CPU被劃分為多個節點,記憶體被劃分為簇,每個CPU都對應一個本地物理記憶體,即一個CPU Node對應一個記憶體簇bank,即每個記憶體簇被認為是一個存儲節點。在UMA結構下,只存在一個存儲節點。 - 記憶體域(Zone):由於硬體制約,每個物理記憶體節點Node被劃分為多個記憶體域, 用於表示不同範圍的記憶體, 內核可以使用不同的映射方式映射物理記憶體。
- 頁面(Page):各個記憶體域都關聯一個數組,用來組織屬於該記憶體域的物理記憶體頁(頁幀)。頁面是最基本的頁面分配的單位
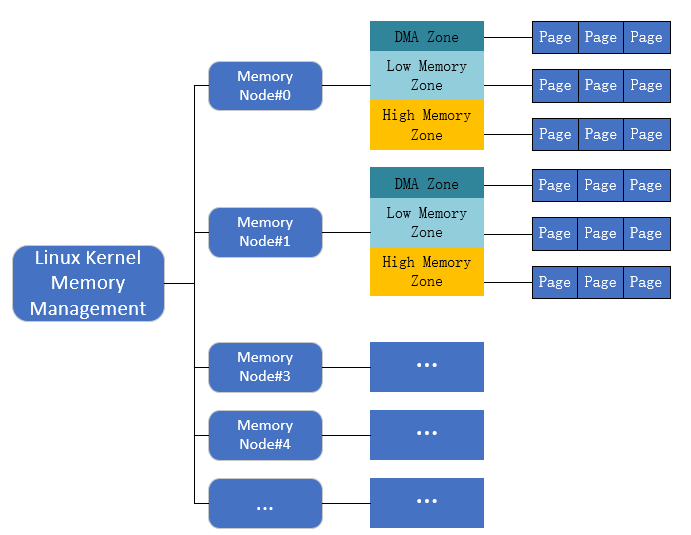
接下來對這3層數據結構進行簡單介紹。
Node — pg_data_t
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
struct bootmem_data *bdata;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* 物理記憶體頁的總數 */
unsigned long node_spanned_pages; /* 物理記憶體頁的總長度,包含洞在內 */
int node_id;
struct pglist_data *pgdat_next;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;
| 屬性名 | 描述 |
|---|---|
| node_zones | 包含了結點中各記憶體域的數據結構 |
| node_zonelists | 指定了備用結點及其記憶體域的列表,以便在當前結點沒有可用空間時,在備用結點分配記憶體(這個欄位將在後面介紹頁分配器時再提到) |
| nr_zones | 結點中管理區的個數 |
| node_mem_map | 指向page實例數組的指針,用於᧿述結點的所有物理記憶體頁。它包含了結點中所有記憶體域的頁。 |
| bdata | 在系統啟動期間,記憶體管理子系統初始化之前,內核也需要使用記憶體(另外,還必須保留部分記憶體用於初始化記憶體管理子系統)。為解決這個問題,內核使用了自舉記憶體分配(boot memory allocator)。bdata指向自舉記憶體分配器數據結構的實例 |
| node_start_pfn | 該NUMA結點第一個頁幀的邏輯編號。系統中 結點的頁幀是依次編號的,每個頁幀的號碼都是全局唯一的(不只是結點內唯一)。node_start_pfn在UMA系統中總是0,因為其中只有一個結點,因此其第一個頁幀編號總是0。 node_present_pages指定了結點中頁幀的數目,而node_spanned_pages則給出了該結點以頁幀為單位計算的長度。二者的值不一定相同,因為結點中可能有一些空洞,並不對應真正的頁幀 |
| node_id | 全局結點ID。系統中的NUMA結點都從0開始編號 |
| pgdat_next | 連接到下一個記憶體結點,系統中所有結點都通過單鏈表連接起來,其末尾通過空指針標記。 |
| kswapd_wait | 交換守護進程(swap daemon)的等待隊列,在將頁幀換出結點時會用到。kswapd指向負責該結點的交換守護進程的task_struct。kswapd_max_order用於頁交換子系統的實現,來定義需要釋放的區域的長度(我們當前不感興趣)。 |
註意:
- 所有結點的描述符存放在一個單向鏈表中,其首結點為pgdat_list。如果採用的是UMA模型,那麼這唯一一個元素還會被放在contig_page_data變數中。
- 結點的記憶體域保存在node_zones[MAX_NR_ZONES]。該數組總是有3個項(這3個項是什麼,看下一小節),即使結點沒有那麼多記憶體域,也是如此。如果不足3個,則其餘的數組項用0填充
如果系統中結點多於一個,內核會維護一個點陣圖,用以ᨀ供各個結點的狀態信息。狀態是用位掩碼指定的,可使用下列值:
enum node_states {
N_POSSIBLE, /* 結點在某個時候可能變為聯機 */
N_ONLINE, /* 結點是聯機的 */
N_NORMAL_MEMORY, /* 結點有普通記憶體域 */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* 結點有普通或高端記憶體域 */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
N_CPU, /* 結點有一個或多個CPU */
NR_NODE_STATES
};
Zone - zone
在之前討論了,由於電腦體繫結構有硬體的制約,這限制了頁框可以使用的方式,尤其是,Linux內核必須處理80x86體繫結構的兩種硬體約束:
- ISA匯流排的直接記憶體存取(DMA)處理器有一個嚴格的限制:它們只能對RAM的前16MB定址。
- 在具有大容量RAM的現代32位電腦中,CPU不能直接訪問所有的物理記憶體,因為線性地址空間太小。
為了應對這兩種限制,Linux2.6把每個記憶體節點的物理記憶體劃分為3個管理區(zone),在80x86UMA體繫結構中的管理區為:
| 名稱 | 描述 |
|---|---|
| ZONE_DMA | 包含低於16MB的記憶體頁框 |
| ZONE_DMA32 | 使用32位地址字可定址、適合DMA的記憶體域。顯然,只有在64位系統上,兩種DMA記憶體域才有差別 |
| ZONE_NORMAL | 包含高於16MB且低於896MB的記憶體頁框 |
| ZONE_HIGHMEM | 包含從896MB開始高於896MB的記憶體頁框 |
這裡我們瞭解了16MB這個界限的來歷,那麼896MB這個界限是怎麼回事呢??
Linux預設按照3:1的比例將地址空間劃分給用戶態和內核態,32位操作系統上內核空間的大小就是1GB(4GB按照3:1劃分),內核空間又分為各個段,如下圖:

直接映射區域從0xC0000000到high_memory地址,high_memory通常為896MB。high_memory由下麵的巨集具體決定,該
//arch/x86/kernel/setup_32.c
static unsigned long __init setup_memory(void)
{
...
#ifdef CONFIG_HIGHMEM
high_memory = (void *) __va(highstart_pfn * PAGE_SIZE -1) + 1;
#else
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE -1) + 1;
#endif
...
}
max_low_pfn指定了物理記憶體數量小於896 MiB的系統上記憶體頁的數目。該值的上界受限於896 MiB可容納的最大頁數(具體的計算在find_max_low_pfn給出),因此high_memory通常為896MB。剩下的128MB通常用作如下用途(如下三種用途的具體介紹有機會會仔細講解):
- 虛擬記憶體中連續、但物理記憶體中不連續的記憶體區,可以在vmalloc區域分配
- 持久映射用於將高端記憶體域中的非持久頁映射到內核中
- 固定映射是與物理地址空間中的固定頁關聯的虛擬地址空間項,但具體關聯的頁幀可以自由選擇。
可以看到直接映射的最大空間長度為896MB,如果物理記憶體超過896MB,則內核無法直接映射全部記憶體。
最後看一下記憶體中表示Zone的數據結構zone,其各個欄位所代表的含義:
struct zone {
/*通常由頁分配器訪問的欄位 */
unsigned long pages_min, pages_low, pages_high;
unsigned long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset pageset[NR_CPUS];
/*
* 不同長度的空閑區域
*/
spinlock_t lock;
struct free_area free_area[MAX_ORDER];
ZONE_PADDING(_pad1_)
/* 通常由頁面收回掃描程式訪問的欄位 */
spinlock_t ru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long pages_scanned; /* 上一次回收以來掃᧿ 過的頁 */
unsigned long flags; /* 記憶體域標誌,見下文 */
/* 記憶體域統計量 */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
int prev_priority;
ZONE_PADDING(_pad2_)
/* 很少使用或大多數情況下只讀的欄位 */
wait_queue_head_t * wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
/* 支持不連續記憶體模型的欄位。 */
struct pglist_data *zone_pgdat;
unsigned long zone_start_pfn;
unsigned long spanned_pages; /* 總長度,包含空洞 */
unsigned long present_pages; /* 記憶體數量(除去空洞) */
/*
* 很少使用的欄位:
*/
char *name;
} ____cacheline_maxaligned_in_smp;
這裡主要介紹記憶體管理的核心欄位,將在後面比較頻繁的出現,對於其他的欄位,我們使用到的時候再進行介紹。
- pages_min、pages_high、pages_low是頁換出時使用的
stake,也就是一些界限。如果記憶體不足,內核可以將頁寫到硬碟。這3個成員會影響交換守護進程的行為。- 如果空閑頁多於pages_high,則記憶體域的狀態是理想的。
- 如果空閑頁的數目低於pages_low,則內核開始將頁換出到硬碟。
- 如果空閑頁的數目低於pages_min,那麼頁回收工作的壓力就比較大,因為記憶體域中急需空閑頁。
- lowmem_reserve數組分別為各種記憶體域指定了若幹頁,
用於一些無論如何都不能失敗的關鍵性記憶體分配。 - pageset是一個數組,
用於實現每個CPU的熱/冷頁幀列表。內核使用這些列表來保存可用於滿足實現的“新鮮”頁。但冷熱頁幀對應的高速緩存狀態不同:- 有些頁幀也很可能仍然在高速緩存中,因此可以快速訪問,故稱之為熱的;
- 未緩存的頁幀與此相對,故稱之為冷的。
- free_area是同名數據結構的數組,用於實現伙伴系統
Page - page
由於我們現在討論的都是對物理記憶體的管理,即頁框的管理,那麼記錄頁框的狀態是無法避免的,因此,操作系統提供了頁描述符用於完成該任務,即struct page結構體。
struct page {
unsigned long flags; /* 原子標誌,有些情況下會非同步更新 */
atomic_t _count; /* 使用計數,見下文。 */
union {
atomic_t _mapcount; /* 記憶體管理子系統中映射的頁表項計數,
* 用於表示頁是否已經映射,還用於限制逆向映射搜索。
*/
unsigned int inuse; /* 用於SLUB分配器:對象的數目 */
};
union {
struct {
unsigned long private; /* 由映射私有,不透明數據:
* 如果設置了PagePrivate,通常用於
buffer_heads;
* 如果設置了PageSwapCache,則用於
swp_entry_t;
* 如果設置了PG_buddy,則用於表示伙伴系統中的
階。
*/
struct address_space *mapping; /* 如果最低位為0,則指向inode
* address_space,或為NULL。
* 如果頁映射為匿名記憶體,最低位置位,
* 而且該指針指向anon_vma對象:
* 參見下文的PAGE_MAPPING_ANON。
*/
};
...
struct kmem_cache *slab; /* 用於SLUB分配器:指向slab的指針 */
struct page *first_page; /* 用於複合頁的尾頁,指向首頁 */
};
union {
pgoff_t index; /* 在映射內的偏移量 */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* 換出頁列表,例如由zone->lru_lock保護的active_list!
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* 內核虛擬地址(如果沒有映射則為NULL,即高端記憶體) */
#endif /* WANT_PAGE_VIRTUAL */
};
這裡我們介紹一些對我們討論的內容比較重要的屬性。
| 屬性名 | 描述 |
|---|---|
| flags | 包含多達32個用來描述頁框狀態的標誌 |
| _count | 頁的引用計數器(這裡兩本參考書有分歧,不做具體描述) |
| _mapcount | 表示在頁表中有多少項指向該頁 |
| lru | 是一個表頭,用於在各種鏈表上維護該頁,以便將頁按不同類別分組,最重要的類別是活動和不活動頁。 |
| private | 指向“私有”數據的指針,虛擬記憶體管理會忽略該數據。根據頁的用途,可以用不同的方式使用該指針 |
| virtual | l用於高端記憶體區域中的頁,換言之,即無法直接映射到內核記憶體中的頁。virtual用於存儲該頁的虛擬地址 |
在本部分的最後,給出一個flags標誌中可選標誌的表,方便後期查看。

總結
本節主要講解了物理記憶體的佈局以及記憶體管理模塊的主要數據結構,下一節我們會描述內核在啟動時是如何初始化這些結構的,為後面講解記憶體分配演算法做準備。


