
摘要:本文章將從使用者角度介紹HStore概念以及使用。 本文分享自華為雲社區《GaussDB(DWS)HStore表講解》,作者:大威天龍:- 。 HStore表簡介 面對實時入庫和實時查詢要求越來越高的趨勢,已有的列存儲無法支持併發更新入庫,行存查詢性能無法做到實時返回且空間壓縮表現不佳。Gau ...
摘要:本文章將從使用者角度介紹HStore概念以及使用。
本文分享自華為雲社區《GaussDB(DWS)HStore表講解》,作者:大威天龍:- 。
HStore表簡介
面對實時入庫和實時查詢要求越來越高的趨勢,已有的列存儲無法支持併發更新入庫,行存查詢性能無法做到實時返回且空間壓縮表現不佳。GaussDB(DWS)基於列存儲格式設計和實現了全新的HStore表,同時提供高效的併發插入、更新入庫,以及高性能實時查詢。本文章將從使用者角度介紹HStore概念以及使用。
HStore表的背景
為什麼要有HStore表呢?在具體講解HStore表之前,我們先來回顧一下GaussDB(DWS)中幾種已有的表類型:
行存表(row-store)
最基礎的表類型,顧名思義,數據按行存儲,在實際的物理塊中,數據的將按下列圖示的方式存儲:
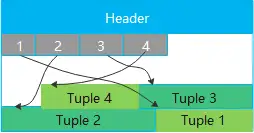
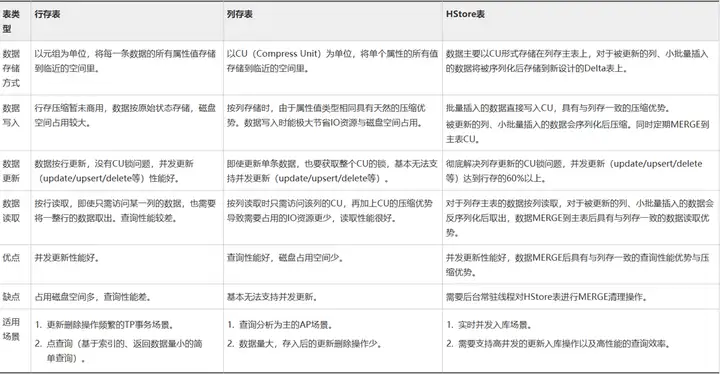
優勢很明顯,點查場景下,直接就能索引到行存某行元組的位置,點查性能好。資料庫中的系統表就是行存表,對於用戶的一些對點查性能要求高或者頻繁更新的小表,都推薦用行存表。
列存表(column-store)
AP場景下,常常需要對某列進行批量查詢來做分析業務,這時候採用行存的話就會把所有列都讀出來產生冗餘IO, 同時AP場景下的表數據量往往很大,行存表壓縮暫未商用,使用行存表也會導致占用空間過大。
GaussDB(DWS)中的列存表就是針對這種場景實現的,列存表數據的實際存儲示意圖如下:
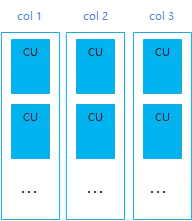
列存表將每列的數據批量存儲成一個CU(Compress Unit), 能帶來了很好的空間壓縮與批量查詢性能提升,對於一些涉及多表關聯的分析類複雜查詢、數據不經常更新的表,推薦使用列存表。
列存帶Delta表
對於列存表,如果業務是頻繁的小批量插入,那麼將產生大量的小CU(單個CU里只有幾百條甚至幾條數據), 每個列的CU都是有壓縮代價的,小CU過多將嚴重影響列存表的查詢性能。
列存的Delta表就是針對這種場景實現的,讓小批量插入的數據先存儲到行存delta表,滿6w後由後臺autovacuum非同步merge到主表CU。
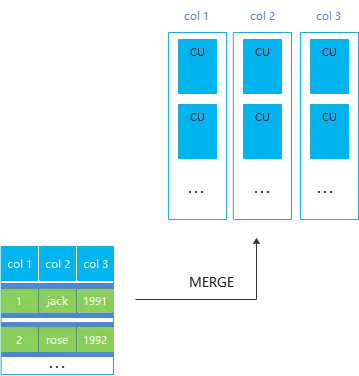
需要註意的是列存帶Delta表只解決小批量入庫產生的小CU問題,不解決同一個CU上的併發更新問題
HStore表
前面提到,雖然列存老Delta表解決了小批量入庫產生的小CU問題,但是沒有解決同一個CU上的併發更新產生的鎖衝突問題。
而實時入庫的場景下,需要將insert+upsert+update操作實時併發入庫,數據來源於上游的其他資料庫或者應用,同時要求入庫後的數據要能及時查詢,且對於查詢的效率要求很高。
目前的列存表由於鎖衝突的原因無法支持併發upsert/update入庫,導致這些有需要的局點只能使用行存表,但是行存表因為格式的天然劣勢,在AP查詢場景下一方面性能較慢,另一方面由於壓縮差導致占用了大量的磁碟空間,對用戶產生額外成本。
GaussDB(DWS)中的HStore表, 在使用列存儲格式儘量降低磁碟占用的同時,支持高併發的更新操作入庫以及高性能的查詢效率。面向對於實時入庫和實時查詢有較強訴求的場景,同時擁有處理傳統TP場景的事務能力。
HStore表的示意圖如下:
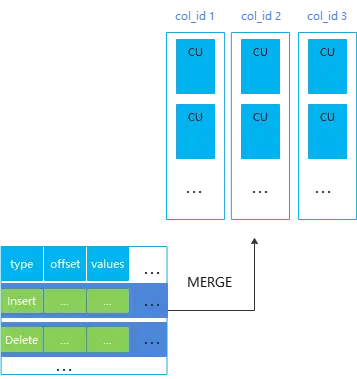
GaussDB(DWS) 中幾種表類型的對比
HStore的Delta表
HStore表的實現主要依靠一張新設計的delta表以及記憶體併發控制機制,這裡簡單講一下delta表的實現以及簡單的觀察delta表。
HStore的Delta表主要用於存放入庫產生的Insert/Delete/Update操作,小批量Insert的數據會先進入Delta形成一條類型是I(Insert)的記錄;刪除會往Delta表插入一條類型是D(Delete)的記錄;更新操作(Upsert與Update)會拆分成Delete + Insert,會插入一條類型X(表示由更新產生的刪除)的記錄以及一條類型I的記錄;
(類型是U(Update)的記錄由輕量化Update產生,不過當前輕量化更新預設關閉,所以不用管。)
可以看到,入庫時的Upsert/Update/Delete都會轉換成相應類型的記錄插入的HStore的Delta表中,再結合記憶體併發控制機制,就能保證同一個CU上更新於刪除操作不會阻塞。同時,由於小批量的插入只會在Delta表上形成一條記錄,相比與列存老Delta的直接存儲數據,能減少IO占用,提高MERGE效率。
HStore的Delta表 與 列存老Delta表的對比

HStore的視圖與函數
當前HStore表提供了視圖,可以用來觀察Delta表的給類型元組數量以及Delta的膨脹情況。
select * from pgxc_get_hstore_delta_info('tableName');
同時也提供了函數可以對Delta表做輕量清理以及全量清理。
-- 輕量Merge滿6萬的I記錄以及CU上的刪除信息,持有四級鎖不阻塞業務增刪改查,但空間不會還給操作系統。 select hstore_light_merge('tableName'); -- 全量Merge所有記錄,然後truncate清空Delta表返還空間給系統,不過持有八級鎖會阻塞業務。 select hstore_full_merge('tableName');
這裡做一個簡單的觀察實驗:
1.往HStore表上批量插入一百條數據,能看到生成了一條類型是I的記錄(n_i_tup 為1)
gaussdb=# create table data(a int primary key, b int); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "data_pkey" for table "data" CREATE TABLE gaussdb=# insert into data values(generate_series(1,100),1); INSERT 0 100 gaussdb=# create table hs(a int primary key, b int)with(orientation=column, enable_hstore=on); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "hs_pkey" for table "hs" CREATE TABLE gaussdb=# insert into hs select * from data; INSERT 0 100 gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --觀察hstore表的delta表上的各類型數據 node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size -----------+---------------------+----------+----------+----------+----------+----------+----------+----------- dn_1 | non partition table | 1 | 1 | 0 | 0 | 0 | 0 | 8192 (1 row)
2.執行hstore_full_merge後能觀察到Delta表上沒有元組(live_tup為0),並且Delta表的空間大小data_size是0.
gaussdb=# select hstore_full_merge('hs'); hstore_full_merge ------------------- 1 (1 row) gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --觀察hstore表的delta表上的各類型數據 node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size -----------+---------------------+----------+----------+----------+----------+----------+----------+----------- dn_1 | non partition table | 0 | 0 | 0 | 0 | 0 | 0 | 0 (1 row)
3.執行刪除,能觀察到Delta表上有一條類型是D的記錄(n_d_tup為1)。
gaussdb=# delete hs where a = 1; DELETE 1 gaussdb=# select * from pgxc_get_hstore_delta_info('hs'); --觀察hstore表的delta表上的各類型數據 node_name | part_name | live_tup | n_i_type | n_d_type | n_x_type | n_u_type | n_m_type | data_size -----------+---------------------+----------+----------+----------+----------+----------+----------+----------- dn_1 | non partition table | 1 | 0 | 1 | 0 | 0 | 0 | 8192 (1 row)
其它的操作這裡不再一一嘗試,感興趣的讀者可以自己下來試一下。
HStore表的簡單使用實驗
準備工作
當需要使用HStore表時,需要同步修改以下幾個清理相關的參數預設值,否則會導致HStore表性能嚴重劣化。推薦的參數修改配置是:autovacuum_max_workers_hstore=3,autovacuum_max_workers=6,autovacuum=true。
併發更新實驗
在列存表上插入一批數據後,開啟兩個會話,
1.會話1刪除某一條數據,然後不結束事務:
gaussdb=# create table col(a int , b int)with(orientation=column); CREATE TABLE gaussdb=# insert into col select * from data; INSERT 0 100 gaussdb=# begin; BEGIN gaussdb=# delete col where a = 1; DELETE 1
2.會話2刪除另一條數據,能看到會話2等待會話1,
gaussdb=# begin; BEGIN gaussdb=# delete col where a = 2;
會話1提交後會話2才能繼續執行,這就復現了列存的CU鎖問題:
3. 使用HStore表重覆上面實驗,能觀察到會話2直接執行成功,不會鎖等待。
gaussdb=# begin; BEGIN gaussdb=# delete hs where a = 2; DELETE 1
壓縮效率實驗
1.構建一張有三百萬數據的數據表data
gaussdb=# create table data( a int, b bigint, c varchar(10), d varchar(10)); CREATE TABLE gaussdb=# insert into data values(generate_series(1,100),1,'asdfasdf','gergqer'); INSERT 0 100 gaussdb=# insert into data select * from data; INSERT 0 100 gaussdb=# insert into data select * from data; INSERT 0 200 ---迴圈插入,直到數據量達到三百萬 gaussdb=# insert into data select * from data; INSERT 0 1638400 gaussdb=# select count(*) from data; count --------- 3276800 (1 row)
2.批量導入到行存表,觀察大小為223MB
gaussdb=# create table row (like data including all); CREATE TABLE gaussdb=# insert into row select * from data; INSERT 0 3276800 gaussdb=# select pg_size_pretty(pg_relation_size('row')); pg_size_pretty ---------------- 223 MB (1 row)
3.批量導入到列存表,觀察大小為3.5MB
gaussdb=# create table hs(a int, b bigint, c varchar(10),d varchar(10))with(orientation= column, enable_hstore=on); CREATE TABLE gaussdb=# insert into hs select * from data; INSERT 0 3276800 gaussdb=# select pg_size_pretty(pg_relation_size('hs')); pg_size_pretty ---------------- 3568 KB (1 row)
4.總結
這個表結構比較簡單,數據也都是重覆數據,所以HStore表的壓縮效果很好,一般情況下HStore表相比行存能有3-5倍的壓縮。
批量查詢性能實驗
還是使用上面建的表,這裡簡單驗證一下批量查詢
1.查詢行存表的第四列,耗時在4s左右
gaussdb=# explain analyze select d from data; explain analye QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------- id | operation | A-time | A-rows | E-rows | Peak Memory | E-memory | A-width | E-width | E-costs ----+------------------------------+----------------------+---------+---------+--------------+----------+---------+---------+---------- 1 | -> Streaming (type: GATHER) | 4337.881 | 3276800 | 3276800 | 32KB | | | 8 | 61891.00 2 | -> Seq Scan on data | [1571.995, 1571.995] | 3276800 | 3276800 | [32KB, 32KB] | 1MB | | 8 | 61266.00
2.查詢HStore表的第四列,耗時300毫秒左右
gaussdb=# explain analyze select d from hs; QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------------------- id | operation | A-time | A-rows | E-rows | Peak Memory | E-memory | A-width | E-width | E-costs ----+----------------------------------------+--------------------+---------+---------+----------------+----------+---------+---------+---------- 1 | -> Row Adapter | 335.280 | 3276800 | 3276800 | 24KB | | | 8 | 15561.80 2 | -> Vector Streaming (type: GATHER) | 111.492 | 3276800 | 3276800 | 96KB | | | 8 | 15561.80 3 | -> CStore Scan on hs | [111.116, 111.116] | 3276800 | 3276800 | [254KB, 254KB] | 1MB | | 8 | 14936.80
3.總結
這裡只驗證了批量查詢場景,該場景下列存以及HStore表相比行存都有很好的查詢性能。但在索引點查詢場景下,列存是比不上行存的,這裡不再做詳細對比。
HStore表註意事項
1.參數設置
HStore依賴後臺常駐線程對HStore表進行MERGE清理操作,才能保證查詢性能與壓縮效率,所以使用HStore表務必設置相關GUC,推薦的配置如下:
autovacuum_max_workers_hstore=3 autovacuum_max_workers=6 autovacuum=true
2.併發同一行:
當前HStore併發更新同一行仍然是不支持的,其中同一行上併發update/delete操作會先等鎖然後報錯,同一行上的併發upsert操作會先等鎖然後繼續執行。由於等待開銷也是會影響業務的入庫性能,甚至可能產生死鎖,所以需要在入庫時保證不會併發更新到同一行或者同一個key。
3.索引相關
索引會占用額外的空間,同時帶來的點查性能提升有限,所以HStore表只建議在需要做Upsert或者有點查(這裡指唯一性與接近唯一的點查)的訴求下創建一個主鍵或者btree索引。
4.MERGE相關
由於HStore表依賴後臺autovacuum來將操作MERGE到主表,所以入庫速度不能超過MERGE速度,否則會導致delta表的膨脹,可以通過控制入庫的併發來控制入庫速度。同時由於Delta表本身的空間復用受oldestXmin的影響,如果有老事務存在可能會導致Delta空間復用不及時而產生膨脹。
5.UPSERT性能
HStore表雖然相比普通列存,併發upsert入庫性能得到了很大提升,但相比行存還是有差距,大概只有行存的1/3。所以在不追求壓縮率以及批量查詢性能、只追求單點查詢性能的場景下,還是推薦行存表入庫。


