
[toc] # 一、爬取目標 本次爬取的目標是,愛奇藝電視劇類目下的10個榜單:[電視劇風雲榜-愛奇藝風雲榜](https://www.iqiyi.com/ranks1/2/0) 
可以看到,這10個榜單包含了:
熱播榜、飆升榜、必看榜、古裝榜、言情榜、都市榜、搞笑榜、年代榜、懸疑榜、奇幻榜。
我們以熱播榜為例,打開Chrome瀏覽器,按F12進入開發者模式,選擇網路 -> XHR這個選項,重新刷新一下頁面,並且逐次下拉頁面到最底部,展現出全部100部電視劇:
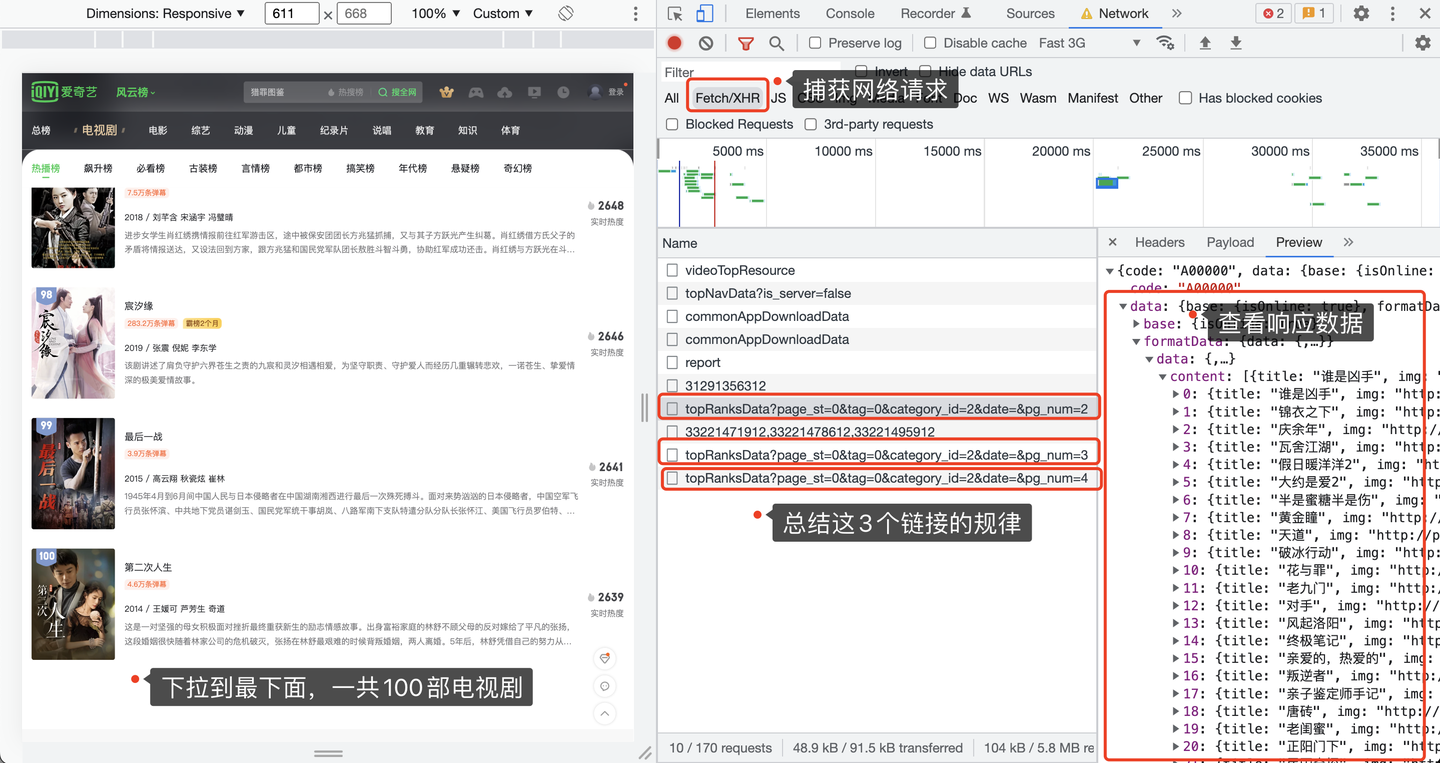
查看捕獲到的請求鏈接地址,每翻一次頁,出現一條鏈接地址,並且該地址的響應數據就是20條電視劇的數據。
所以,這個地址就是我們要請求的地址了。
二、講解代碼
首先,導入需要用到的爬蟲庫:
import requests # 發送請求
import pandas as pd # 存入excel文件
from time import sleep # 隨機等待,防止反爬
import random # 設置隨機
從請求地址的Request Header處,拷貝過來一個請求頭,放到代碼里:
headers = {
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'origin': 'https://www.iqiyi.com',
'referer': 'https://www.iqiyi.com/',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?1',
'sec-ch-ua-platform': '"Android"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Mobile Safari/537.36'
}
愛奇藝的這個榜單頁面,反爬不那麼厲害,請求頭中連cookie都不用加!
由於我想自動爬取這10個榜單,每個榜單對應一個tag標簽,從哪裡獲取呢?經過分析,是從另外一個請求地址返回的:
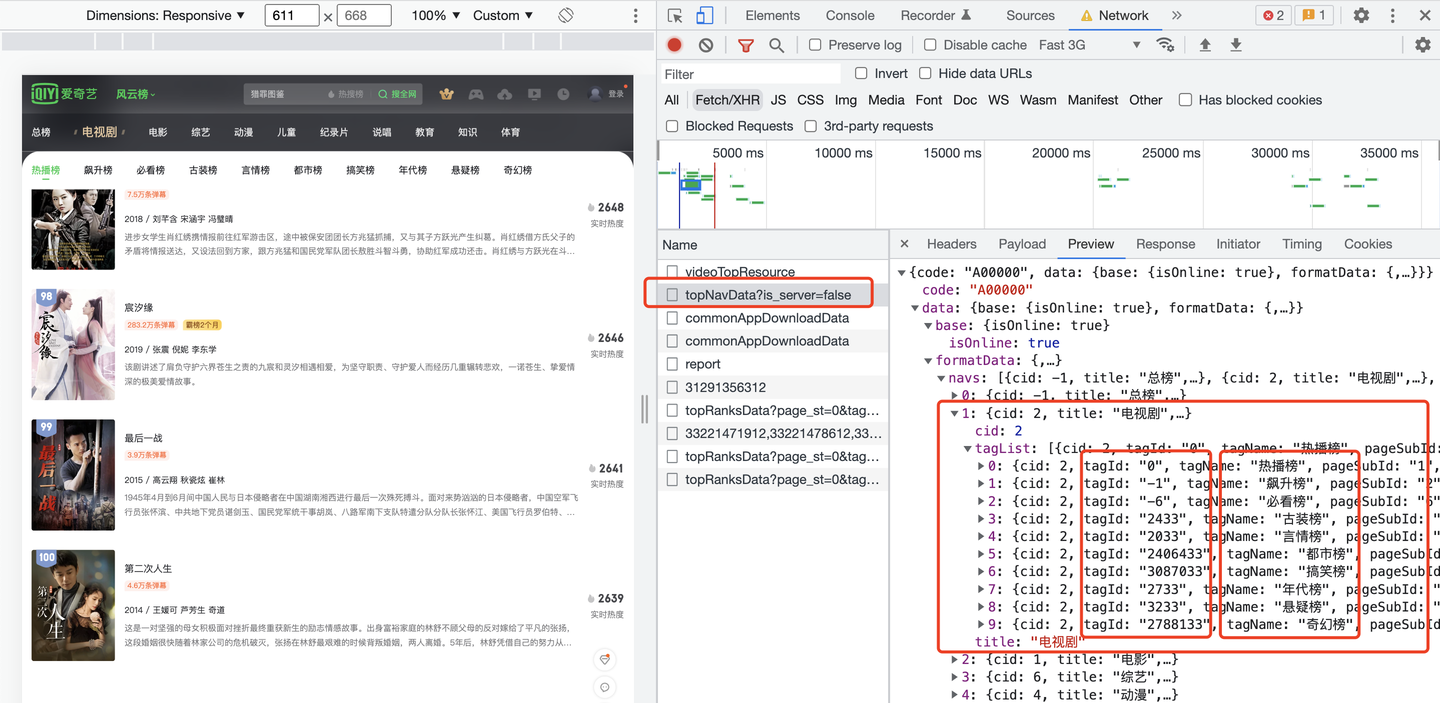
發現了嗎?每個榜單名稱是一個tagName,對應一個tagId。拿到tagId,帶入到榜單數據的請求地址中:
for page in range(1, 5):
url = 'https://pcw-api.iqiyi.com/strategy/pcw/data/topRanksData?page_st={}&tag={}&category_id=2&date=&pg_num={}'.format(v_tag_id, v_tag_id, page)
r = requests.get(url, headers=headers)
這樣,就完成了向頁面發送請求的過程。
順便說一下這個for迴圈,一共翻4頁,每頁25條數據,對應一共100部電視劇。
用json格式接收返回的數據:
json_data = r.json()
然後開始解析json數據:
content_list = json_data['data']['formatData']['data']['content']
for content in content_list:
# 排名
order_list.append(order)
# 標題
title_list.append(content['title'])
print(order, ' ', content['title'])
# 描述
try:
desc_list.append(content['desc'])
except:
desc_list.append('')
# 標簽
tags_list.append(content['tags'])
tag_info = content['tags'].split(' / ')
# 上映年份
year = tag_info[0]
year_list.append(year)
# 主演
actor = tag_info[-1]
actor_list.append(actor)
# 彈幕
try:
danmu_list.append(content['danmu'].replace('條彈幕', ''))
except:
danmu_list.append('')
# 霸榜
try:
babang_list.append(content['babang'])
except:
babang_list.append('')
# 實時熱度
if v_tag_name == '飆升榜':
index_list.append(content['index'] + '%')
else:
index_list.append(content['index'])
order += 1
最後,依然採用我最順手的方法,拼裝成DataFrame的格式,保存到excel文件:
df = pd.DataFrame({
'排名': order_list,
'標題': title_list,
'描述': desc_list,
'標簽': tags_list,
'上映年份': year_list,
'主演': actor_list,
'彈幕': danmu_list,
'霸榜': babang_list,
'實時熱度': index_list,
})
if v_tag_name == '飆升榜': # 如果是飆升榜,把excel標題中的'實時熱度'改為'飆升幅度'
df.rename(columns={'實時熱度': '飆升幅度'}, inplace=True)
df.to_excel('愛奇藝電視劇_{}.xlsx'.format(v_tag_name), index=False)
這裡,需要註意一個小邏輯,飆升榜的'實時熱度'需要rename為'飆升幅度',因為飆升榜跟其他榜單不一樣!

三、查看結果
共爬取到10個榜單文件:
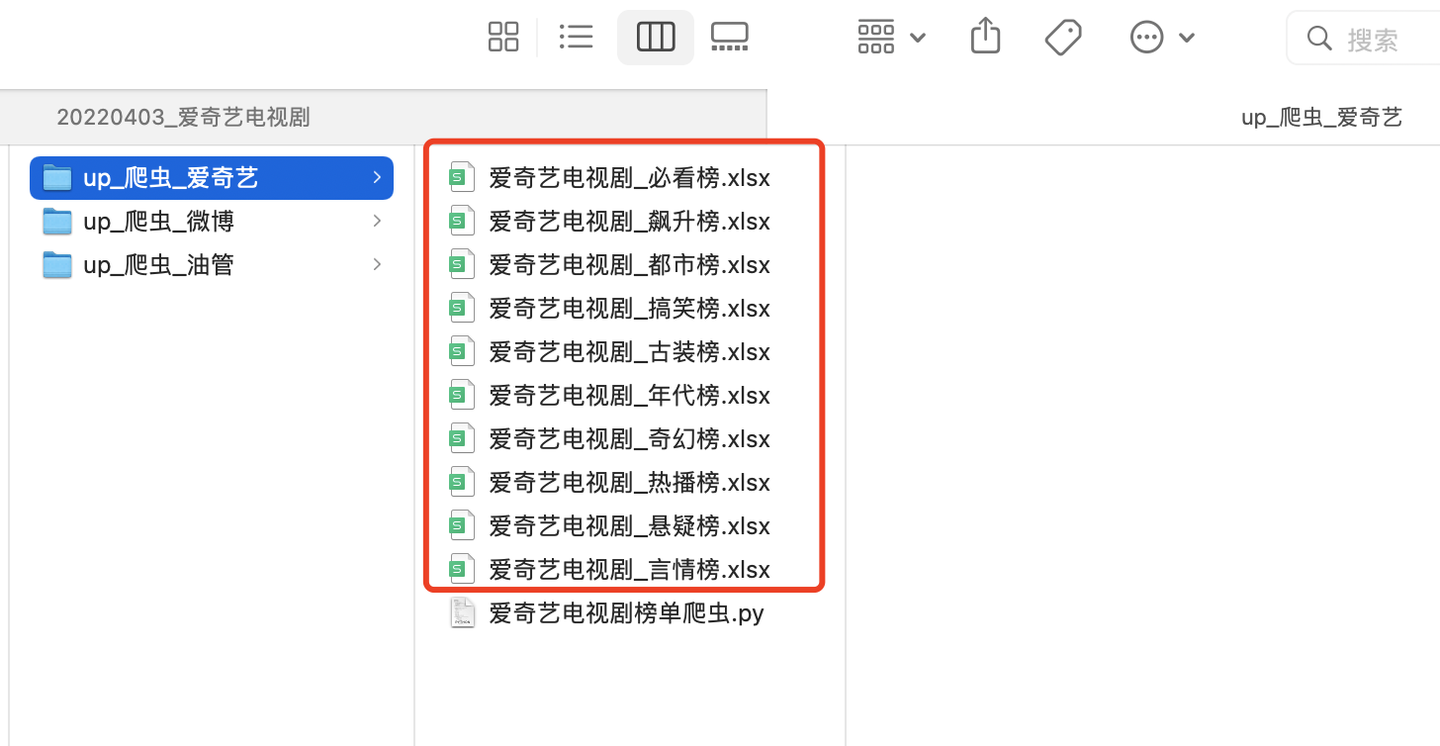
隨便打開一個文件,比如,熱播榜:
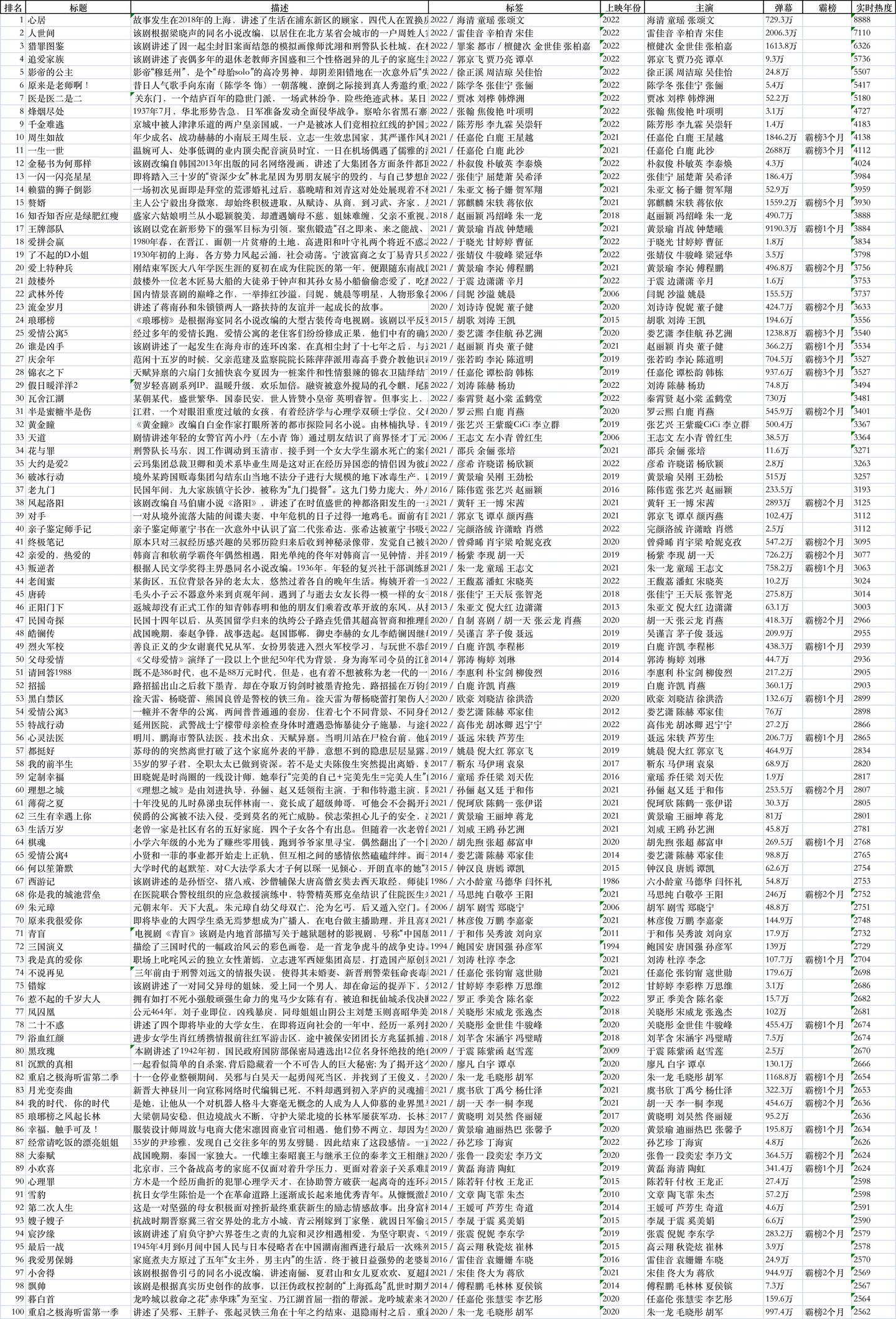
比如,都市榜:
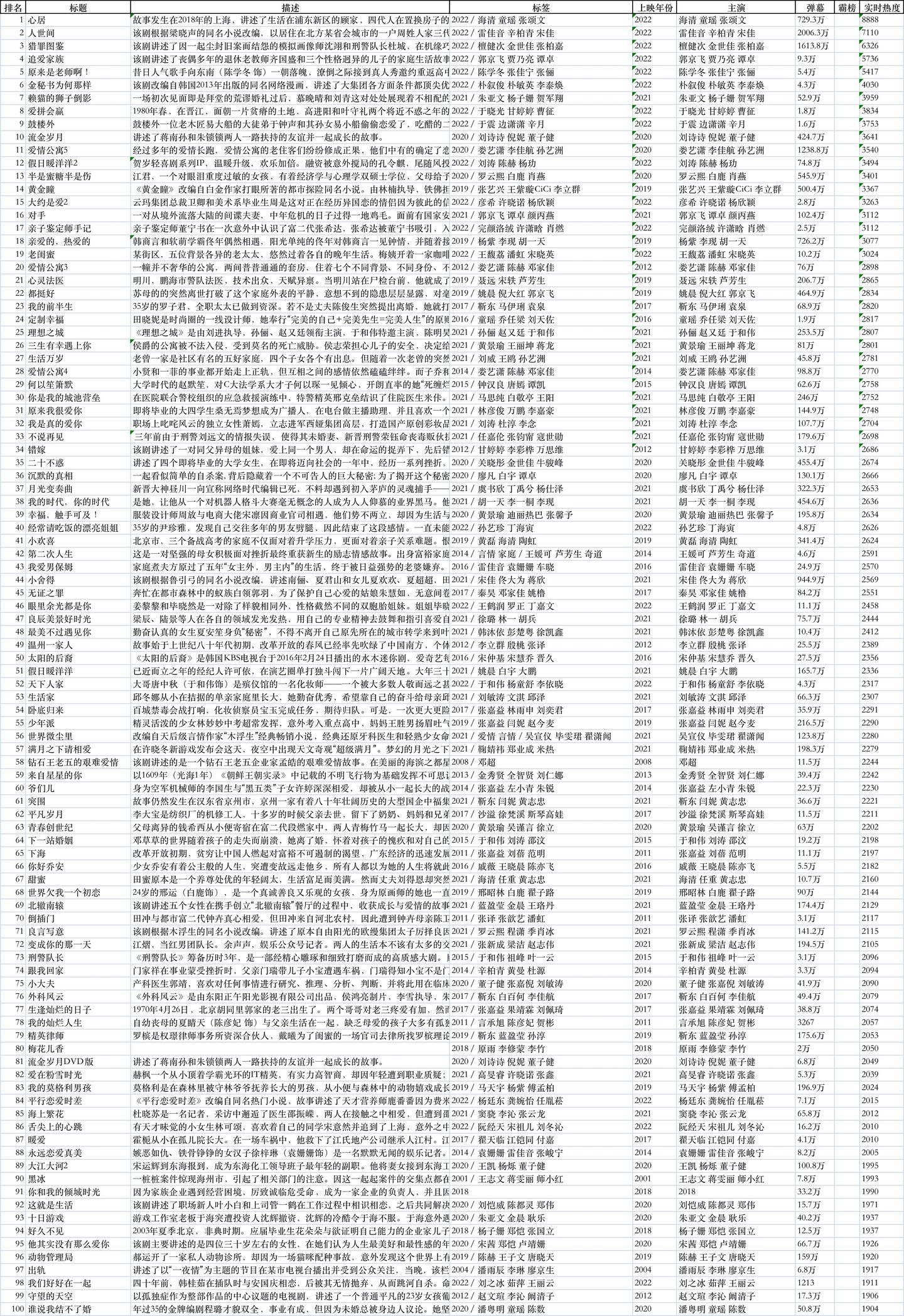
除了搞笑榜有40+條數據,其他榜單都是100條數據,對應100部電視劇。
四、視頻演示
代碼演示視頻:https://www.bilibili.com/video/BV1fT4y1e7wd/
五、附完整源碼
完整源碼:【python爬蟲實戰】用python爬取《愛奇藝風雲榜》電視劇十大榜單!2023.6發佈
我是 @馬哥python說 ,持續分享python源碼乾貨中!

