
最近在壓測一批介面,發現介面處理速度慢的有點超出預期,感覺很奇怪,後面定位發現是資料庫批量保存這塊很慢。 這個項目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。 我點進去看了下源碼,感覺有點不太對勁: 繼續追蹤了下,從這個代碼來看,確實是 ...
最近在壓測一批介面,發現介面處理速度慢的有點超出預期,感覺很奇怪,後面定位發現是資料庫批量保存這塊很慢。
這個項目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。 我點進去看了下源碼,感覺有點不太對勁:
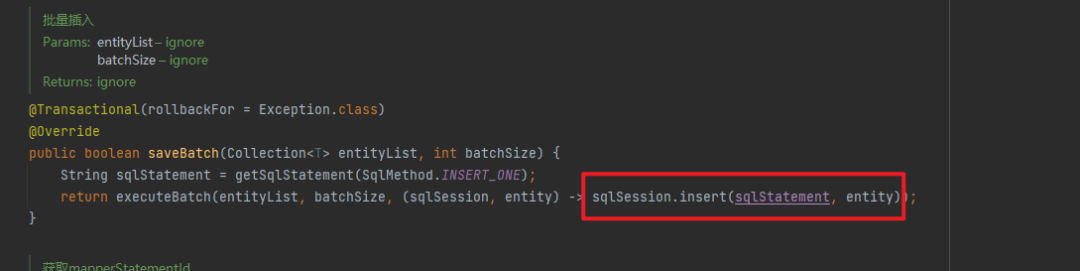
繼續追蹤了下,從這個代碼來看,確實是 for 迴圈一條一條執行了 sqlSession.insert,下麵的 consumer 執行的就是上面的 sqlSession.insert:
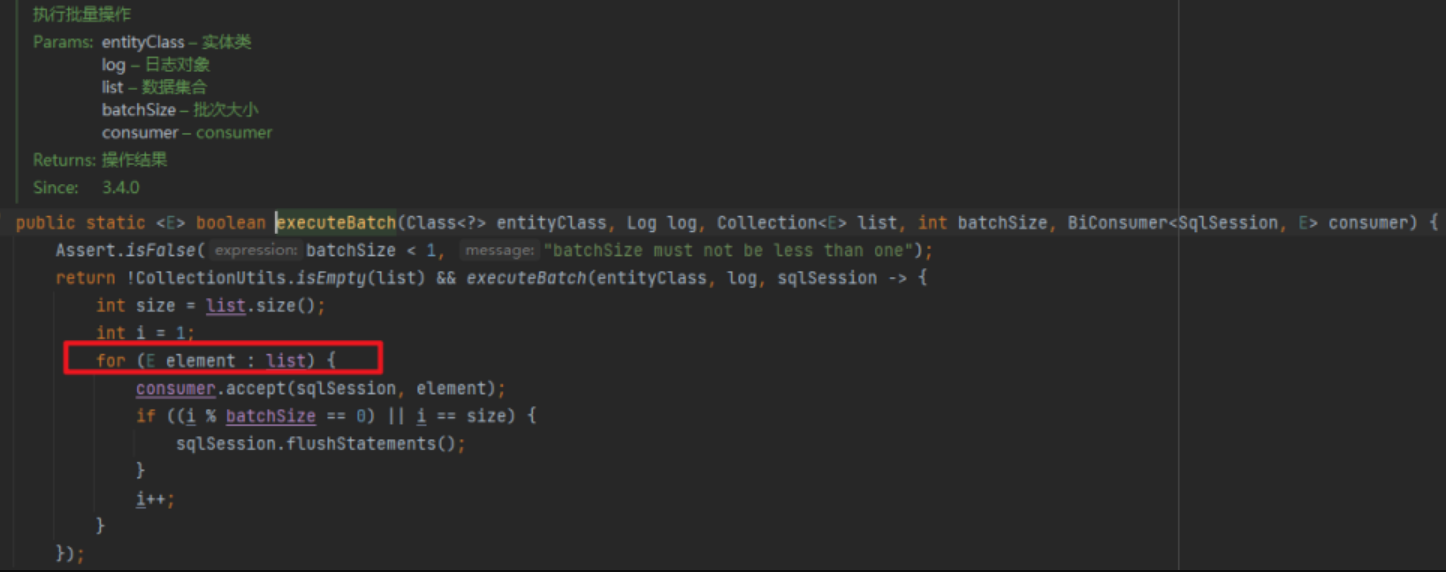
然後累計一定數量後,一批 flush。從這點來看,這個 saveBach 的性能肯定比直接一條一條 insert 快。
我直接進行一個粗略的實驗,簡單創建了一張表來對比一波!
1、1000條數據,一條一條插入
@Test void MybatisPlusSaveOne() { SqlSession sqlSession = sqlSessionFactory.openSession(); try { StopWatch stopWatch = new StopWatch(); stopWatch.start("mybatis plus save one"); for (int i = 0; i < 1000; i++) { OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); //一條一條插入 openTestService.save(openTest); } sqlSession.commit(); stopWatch.stop(); log.info("mybatis plus save one:" + stopWatch.getTotalTimeMillis()); } finally { sqlSession.close(); } }

可以看到,執行一批 1000 條數的批量保存,耗費的時間是 121011 毫秒。
2、1000條數據用 mybatis-plus 自帶的 saveBatch 插入
@Test void MybatisPlusSaveBatch() { SqlSession sqlSession = sqlSessionFactory.openSession(); try { List<OpenTest> openTestList = new ArrayList<>(); for (int i = 0; i < 1000; i++) { OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); openTestList.add(openTest); } StopWatch stopWatch = new StopWatch(); stopWatch.start("mybatis plus save batch"); //批量插入 openTestService.saveBatch(openTestList); sqlSession.commit(); stopWatch.stop(); log.info("mybatis plus save batch:" + stopWatch.getTotalTimeMillis()); } finally { sqlSession.close(); } }

耗費的時間是 59927 毫秒,比一條一條插入快了一倍,從這點來看,效率還是可以的。
然後常見的還有一種利用拼接 SQL 方式來實現批量插入,我們也來對比試試看性能如何。
3、1000 條數據用手動拼接 SQL 方式插入, 搞個手動拼接:

來跑跑下性能如何:
@Test void MapperSaveBatch() { SqlSession sqlSession = sqlSessionFactory.openSession(); try { List<OpenTest> openTestList = new ArrayList<>(); for (int i = 0; i < 1000; i++) { OpenTest openTest = new OpenTest(); openTest.setA("a" + i); openTest.setB("b" + i); openTest.setC("c" + i); openTest.setD("d" + i); openTest.setE("e" + i); openTest.setF("f" + i); openTest.setG("g" + i); openTest.setH("h" + i); openTest.setI("i" + i); openTest.setJ("j" + i); openTest.setK("k" + i); openTestList.add(openTest); } StopWatch stopWatch = new StopWatch(); stopWatch.start("mapper save batch"); //手動拼接批量插入 openTestMapper.saveBatch(openTestList); sqlSession.commit(); stopWatch.stop(); log.info("mapper save batch:" + stopWatch.getTotalTimeMillis()); } finally { sqlSession.close(); } }

耗時只有 2275 毫秒,性能比 mybatis-plus 自帶的 saveBatch 好了 26 倍!
這時,我又突然回想起以前直接用 JDBC 批量保存的介面,那都到這份上了,順帶也跑跑看!
4、1000 條數據用 JDBC executeBatch 插入
@Test void JDBCSaveBatch() throws SQLException { SqlSession sqlSession = sqlSessionFactory.openSession(); Connection connection = sqlSession.getConnection(); connection.setAutoCommit(false); String sql = "insert into open_test(a,b,c,d,e,f,g,h,i,j,k) values(?,?,?,?,?,?,?,?,?,?,?)"; PreparedStatement statement = connection.prepareStatement(sql); try { for (int i = 0; i < 1000; i++) { statement.setString(1,"a" + i); statement.setString(2,"b" + i); statement.setString(3, "c" + i); statement.setString(4,"d" + i); statement.setString(5,"e" + i); statement.setString(6,"f" + i); statement.setString(7,"g" + i); statement.setString(8,"h" + i); statement.setString(9,"i" + i); statement.setString(10,"j" + i); statement.setString(11,"k" + i); statement.addBatch(); } StopWatch stopWatch = new StopWatch(); stopWatch.start("JDBC save batch"); statement.executeBatch(); connection.commit(); stopWatch.stop(); log.info("JDBC save batch:" + stopWatch.getTotalTimeMillis()); } finally { statement.close(); sqlSession.close(); } }

耗時是 55663 毫秒,所以 JDBC executeBatch 的性能跟 mybatis-plus 的 saveBatch 一樣(底層一樣)。
綜上所述,拼接 SQL 的方式實現批量保存效率最佳。
但是我又不太甘心,總感覺應該有什麼別的法子,然後我就繼續跟著 mybatis-plus 的源碼 debug 了一下,跟到了 MySQL 的驅動,突然發現有個 if 裡面的條件有點顯眼:
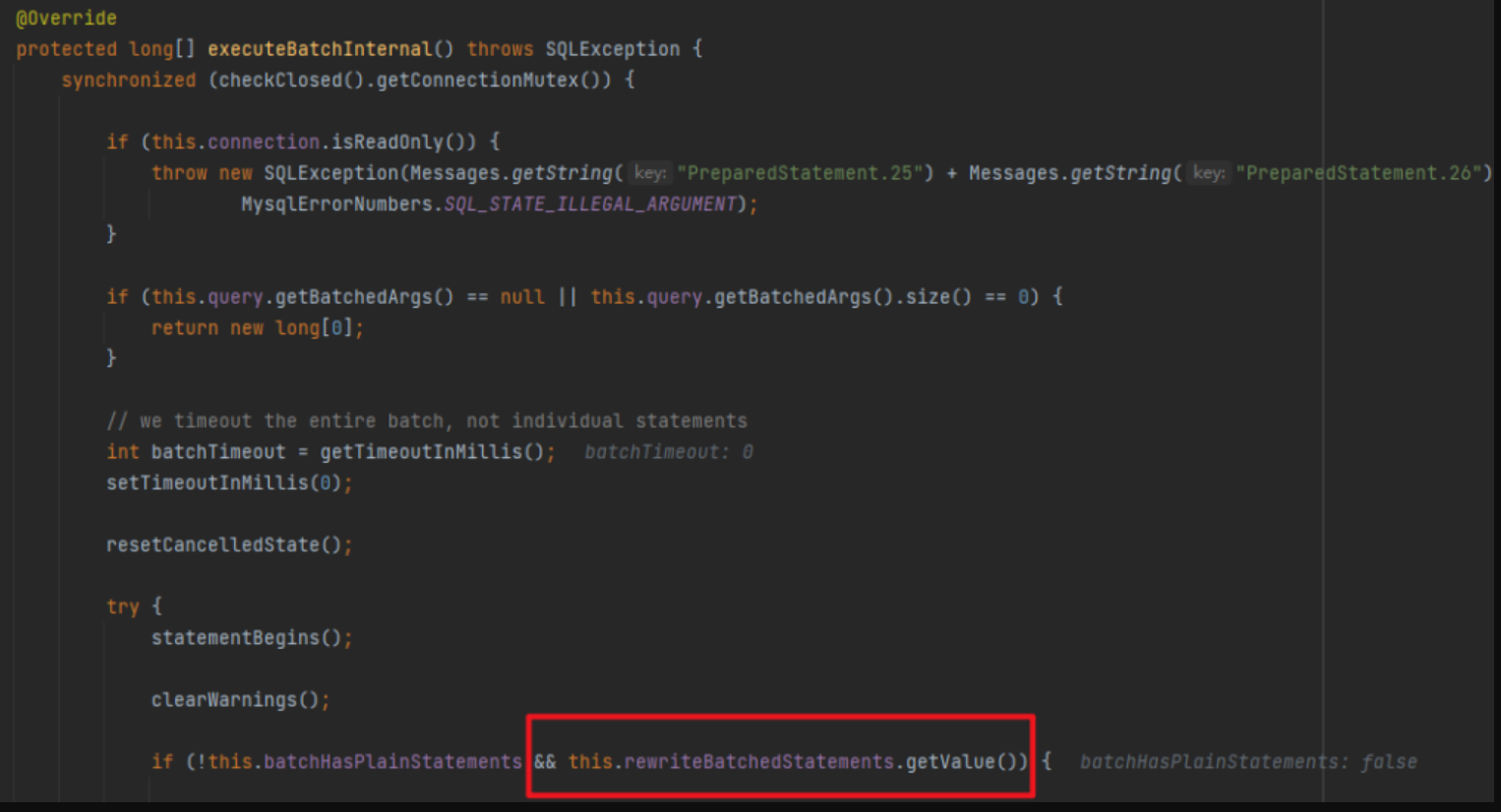
就是這個叫 rewriteBatchedStatements 的玩意,從名字來看是要重寫批操作的 Statement,前面batchHasPlainStatements 已經是 false,取反肯定是 true,所以只要這參數是 true 就會進行一波操作。
我看了下預設是 false。
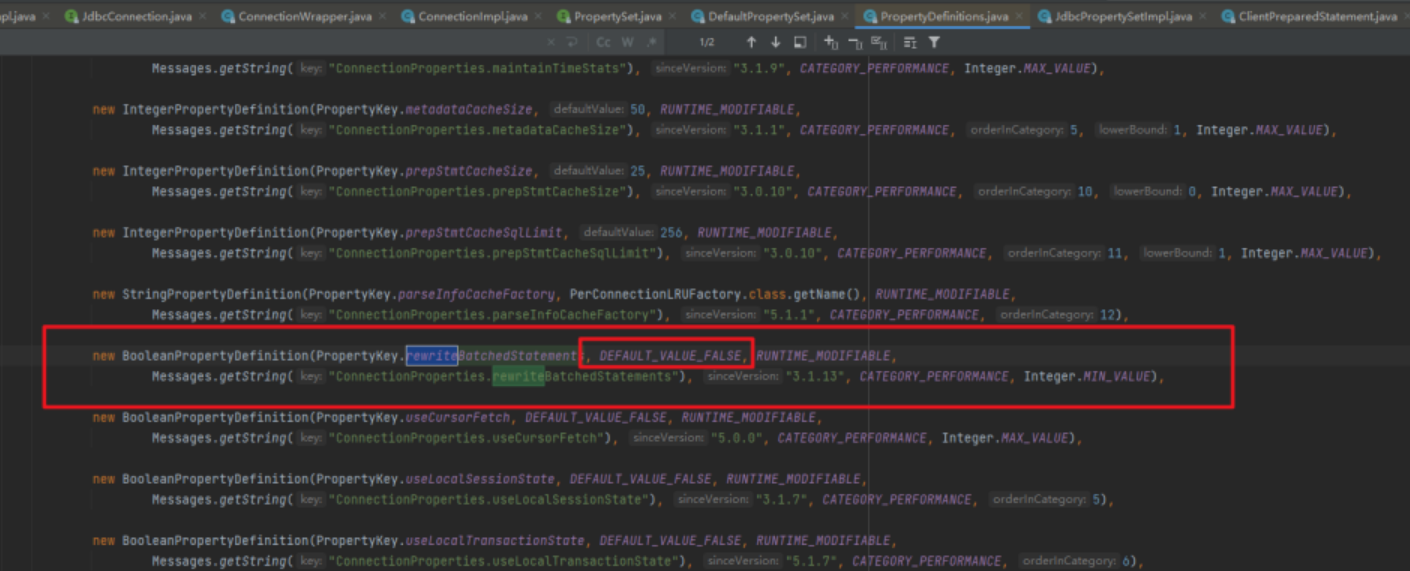
同時我也上網查了下 rewriteBatchedStatements 參數,好家伙,好像有用!

直接將 jdbcurl 加上了這個參數:

然後繼續跑了下 mybatis-plus 自帶的 saveBatch,果然性能大大提高,跟拼接 SQL 差不多!

順帶我也跑了下 JDBC 的 executeBatch ,果然也提高了。

然後我繼續 debug ,來探探 rewriteBatchedStatements 究竟是怎麼 rewrite 的! 如果這個參數是 true,則會執行下麵的方法且直接返回:

看下 executeBatchedInserts 究竟幹了什麼:

看到上面我圈出來的代碼沒,好像已經有點感覺了,繼續往下 debug。
果然!SQL 語句被 rewrite了:
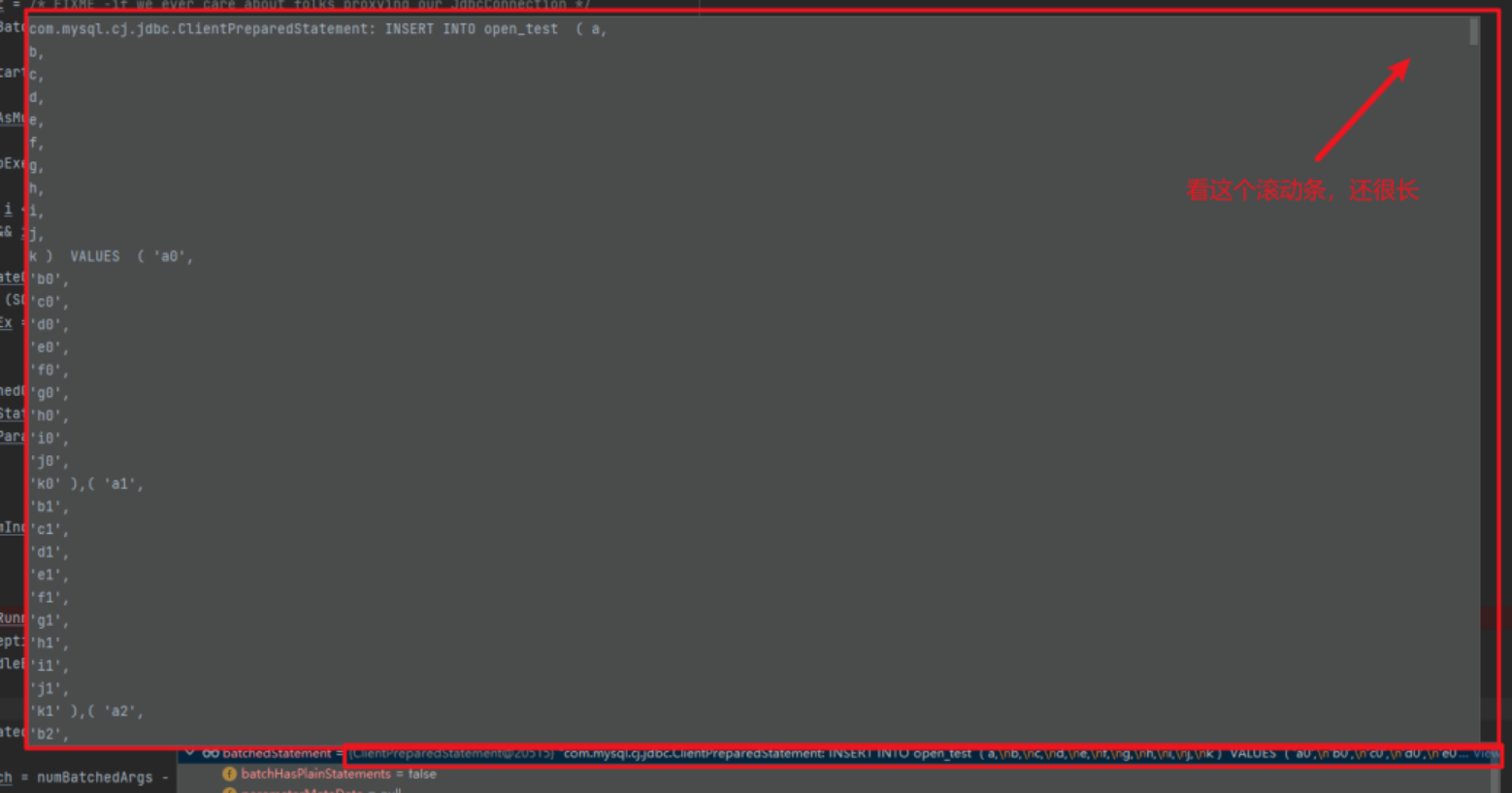
對插入而言,所謂的 rewrite 其實就是將一批插入拼接成 insert into xxx values (a),(b),(c)...這樣一條語句的形式然後執行,這樣一來跟拼接 SQL 的效果是一樣的。
那為什麼預設不給這個參數設置為 true 呢?主要有以下兩點:
如果批量語句中的某些語句失敗,則預設重寫會導致所有語句都失敗。
批量語句的某些語句參數不一樣,則預設重寫會使得查詢緩存未命中。
看起來影響不大,所以我給我的項目設置上了這個參數!
最後
稍微總結下我粗略的對比(雖然粗略,但實驗結果符合原理層面的理解),如果你想更準確地做實驗,可以使用 JMH,並且測試更多組數(如 5000,10000等)的情況。
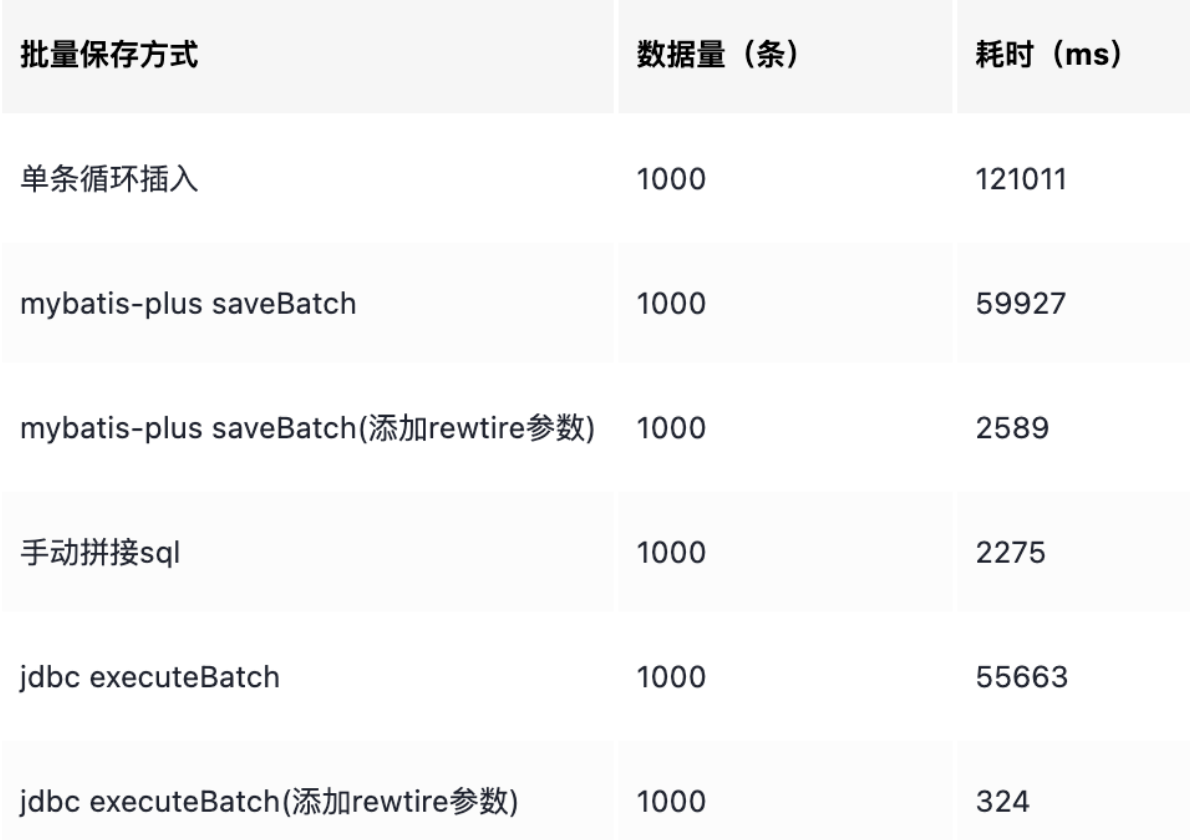
所以如果有使用 JDBC 的 Batch 性能方面的需求,要將 rewriteBatchedStatements 設置為 true,這樣能提高很多性能。
然後如果喜歡手動拼接 SQL 要註意一次拼接的數量,分批處理。


