
在大數據處理中,[實時數據分析](https://www.dtstack.com/dtengine/easylake?src=szsm)是一個重要的需求。隨著數據量的不斷增長,對於實時分析的挑戰也在不斷加大,傳統的批處理方式已經不能滿足[實時數據處理](https://www.dtstack.com ...
在大數據處理中,實時數據分析是一個重要的需求。隨著數據量的不斷增長,對於實時分析的挑戰也在不斷加大,傳統的批處理方式已經不能滿足實時數據處理的需求,需要一種更加高效的技術來解決這個問題。Apache Hudi(Hadoop Upserts Deletes and Incremental Processing)就是這樣一種技術,提供了高效的實時數據倉庫管理功能。
本文將介紹袋鼠雲基於 Hudi 構建數據湖的整體方案架構及其在實時數據倉庫處理方面的特點,並且為大家展示一個使用 Apache Hudi 的簡單示例,便於新手上路。
Apache Hudi 介紹
Apache Hudi 是一個開源的數據湖存儲系統,可以在 Hadoop 生態系統中提供實時數據倉庫處理功能。Hudi 最早由 Uber 開發,後來成為 Apache 頂級項目。
Hudi 主要特性
· 支持快速插入和更新操作,以便在數據倉庫中實時處理數據;
· 提供增量查詢功能,可有效提高數據分析效率;
· 支持時間點查詢,以便查看數據在某一時刻的狀態;
· 與 Apache Spark、Hive 等大數據分析工具相容。
Hudi 架構
Apache Hudi 的架構包括以下幾個主要組件:
· Hudi 數據存儲:Hudi 數據存儲是 Hudi 的核心組件,負責存儲數據,數據存儲有兩種類型:Copy-On-Write(COW)和 Merge-On-Read(MOR);
· Copy-On-Write:COW 存儲類型會在對數據進行更新時,創建一個新的數據文件副本,將更新的數據寫入副本中,之後,新的數據文件副本會替換原始數據文件;
· Merge-On-Read:MOR 存儲類型會在查詢時,將更新的數據與原始數據進行合併,這種方式可以減少數據存儲的寫入延遲,但會增加查詢的計算量;
· Hudi 索引:Hudi 索引用於維護數據記錄的位置信息,索引有兩種類型:內置索引(如 Bloom 過濾器)和外部索引(如 HBase 索引);
· Hudi 查詢引擎:Hudi 查詢引擎負責處理查詢請求,Hudi 支持多種查詢引擎,如 Spark SQL、Hive、Presto 等。
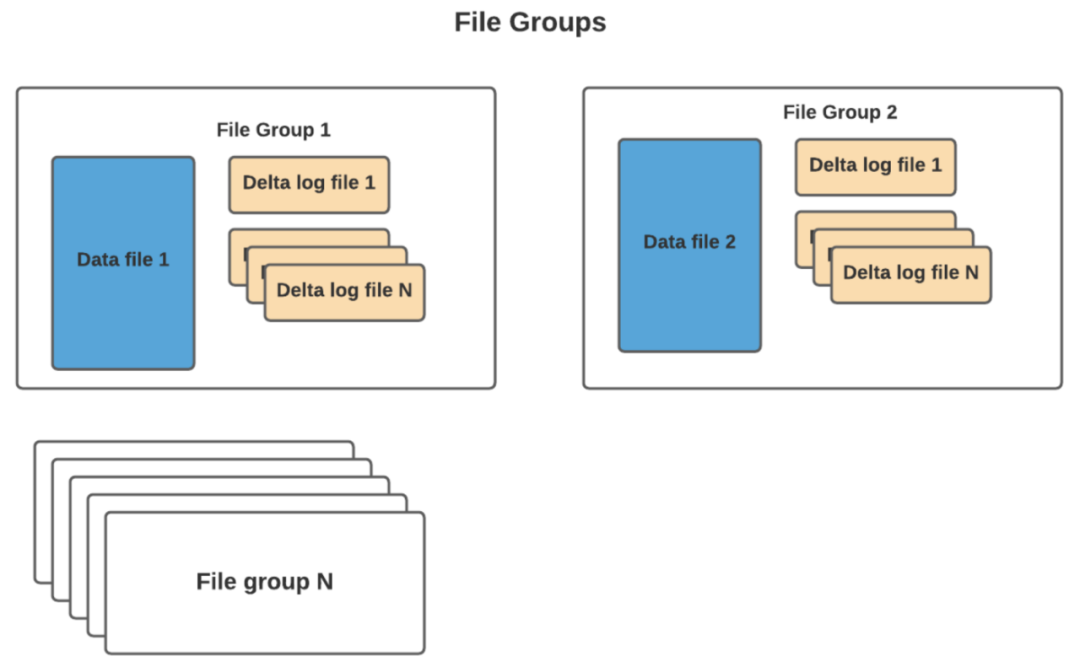
Hudi 的使用場景
Apache Hudi 可以幫助企業和組織實現實時數據處理和分析。實時數據處理需要快速地處理和查詢數據,同時還需要保證數據的一致性和可靠性。
Apache Hudi 的增量數據處理、ACID 事務性保證、寫時合併等技術特性可以幫助企業更好地實現實時數據處理和分析,基於 Hudi 的特性可以在一定程度上在實時數倉的構建過程中承擔上下游數據鏈路的對接(類似 Kafka 的角色)。既能實現增量的數據處理,也能為批流一體的處理提供存儲基礎。
Hudi 的優勢和劣勢
● 優勢
· 高效處理大規模數據集;
· 支持實時數據更新和查詢;
· 實現了增量寫入機制,提高了數據訪問效率;
· Hudi 可以與流處理管道集成;
· Hudi 提供了時間旅行功能,允許回溯數據的歷史版本。
● 劣勢
· 在讀寫數據時需要付出額外的代價;
· 操作比較複雜,需要使用專業的編程語言和工具。
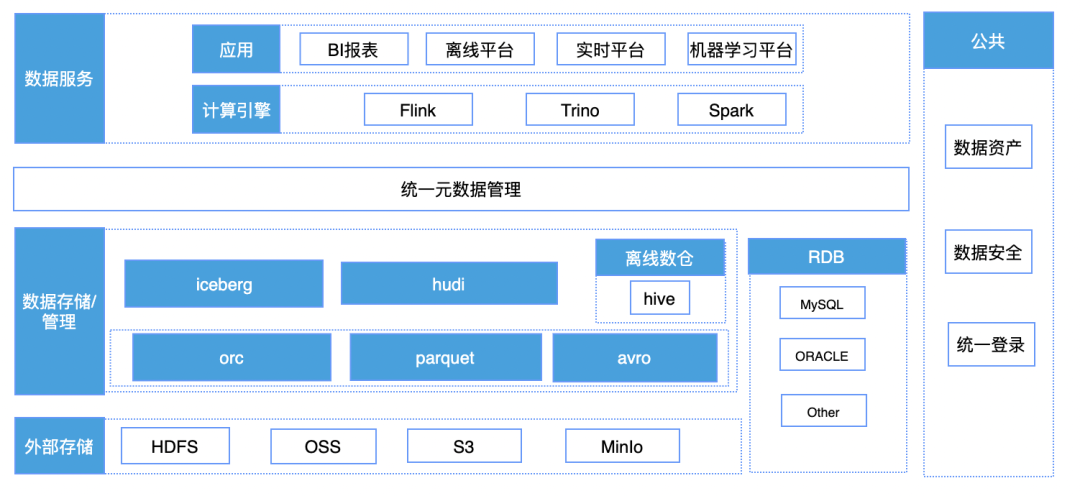
Hudi 在袋鼠雲數據湖平臺上的實踐
Hudi 在袋鼠雲數據湖的技術架構
· 元數據的接入,讓用戶可以快速的對錶進行管理;
· 數據快速接入,包括對符合條件的原有表數據進行轉換,快速搭建數據湖能力;
· 湖表的管理,監控小文件定期進行合併,提升表的查詢性能,內在豐富的表操作功能,包括 time travel ,孤兒文件清理,過期快照清理等;
· 索引構建,提供多種索引包括 bloom filter,zorder 等,提升計算引擎的查詢性能。
Hudi 使用示例
在介紹了 Hudi 的基本信息和袋鼠雲數據湖平臺的結構之後,我們來看一個使用示例,替換 Flink 在記憶體中的 join 過程。
在 Flink 中對多流 join 往往是比較頭疼的場景,需要考慮 state ttl 時間設置,設置太小數據經常關聯不上,設置太大記憶體又需要很高才能保留,我們通過 Hudi 的方式來換個思路實現。
● 構建 catalog
public String createCatalog(){
String createCatalog = "CREATE CATALOG hudi_catalog WITH (\n" +
" 'type' = 'hudi',\n" +
" 'mode' = 'hms',\n" +
" 'default-database' = 'default',\n" +
" 'hive.conf.dir' = '/hive_conf_dir',\n" +
" 'table.external' = 'true'\n" +
")";
return createCatalog;
}
● 創建 hudi 表
public String createHudiTable(){
String createTable = "CREATE TABLE if not exists hudi_catalog.flink_db.test_hudi_flink_join_2 (\n" +
" id int ,\n" +
" name VARCHAR(10),\n" +
" age int ,\n" +
" address VARCHAR(10),\n" +
" dt VARCHAR(10),\n" +
" primary key(id) not enforced\n" +
")\n" +
"PARTITIONED BY (dt)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'changelog.enabled' = 'true',\n" +
" 'index.type' = 'BUCKET',\n" +
" 'hoodie.bucket.index.num.buckets' = '2',\n" +
String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), FlinkOptions.NO_PRE_COMBINE) +
" 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "'\n" +
");";
return createTable;
}
● 更新 hudi 表的 flink_db.test_hudi_flink_join_2 的 id, name, age, dt 列
01 從 kafka 中讀取 topic1
public String createKafkaTable1(){
String kafkaSource1 = "CREATE TABLE source1\n" +
"(\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT,\n" +
" dt String,\n" +
" PROCTIME AS PROCTIME()\n" +
") WITH (\n" +
" 'connector' = 'kafka'\n" +
" ,'topic' = 'join_topic1'\n" +
" ,'properties.bootstrap.servers' = 'localhost:9092'\n" +
" ,'scan.startup.mode' = 'earliest-offset'\n" +
" ,'format' = 'json'\n" +
" ,'json.timestamp-format.standard' = 'SQL'\n" +
" )";
return kafkaSource1;
}
02 從 kafka 中讀取 topic2
public String createKafkaTable2(){
String kafkaSource2 = "CREATE TABLE source2\n" +
"(\n" +
" id INT,\n" +
" name STRING,\n" +
" address string,\n" +
" dt String,\n" +
" PROCTIME AS PROCTIME()\n" +
") WITH (\n" +
" 'connector' = 'kafka'\n" +
" ,'topic' = 'join_topic2'\n" +
" ,'properties.bootstrap.servers' = 'localhost:9092'\n" +
" ,'scan.startup.mode' = 'earliest-offset'\n" +
" ,'format' = 'json'\n" +
" ,'json.timestamp-format.standard' = 'SQL'\n" +
" )";
return kafkaSource2;
}
● 執行插入邏輯1
String insertSQL = "insert into hudi_catalog.flink_db.test_hudi_flink_join_2(id,name,age,dt) " +
"select id, name,age,dt from source1";
● 通過 spark 查詢數據
20230323090605515 20230323090605515_1_186 45 1 c990a618-896c-4627-8243-baace65c7ad6-0_0-21-26_20230331101342388.parquet 45 xc 45 NULL 1
20230323090605515 20230323090605515_1_179 30 1 c990a618-896c-4627-8243-baace65c7ad6-0_0-21-26_20230331101342388.parquet 30 xc 30 NULL 1
● 執行插入邏輯2
String insertSQL = "insert into hudi_catalog.flink_db.test_hudi_flink_join_2(id,name,address,dt) " +
"select id, name, address,dt from source2";
● 運行成功
運行成功後在 spark 中查詢對應的表數據:
20230323090605515 20230323090605515_1_186 45 1 c990a618-896c-4627-8243-baace65c7ad6-0_0-21-26_20230331101342388.parquet 45 xc 45 xc:address45 1
20230323090605515 20230323090605515_1_179 30 1 c990a618-896c-4627-8243-baace65c7ad6-0_0-21-26_20230331101342388.parquet 30 xc 30 xc:address30 1
可以發現在第二次數據運行之後,表數據的對應欄位 address 已經更新,達到了類似在 Flink 中直接執行 join 的效果。
`insert into hudi_catalog.flink_db.test_hudi_flink_join_2
select a.id, a.name, a.age,b.address a.dt from source1 a left join source2 b on a.id = b.id `
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


