
_Java 平臺標準版 HotSpot 虛擬機垃圾收集調整指南_ 描述了 Java HotSpot 虛擬機 (Java HotSpot VM) 中包含的垃圾收集方法,並幫助您確定最適合您需要的方法。 本文檔適用於希望提高應用程式性能的應用程式開發人員和系統管理員,尤其是那些處理大量數據、使用多線程... ...
參考文檔
目錄
- 參考文檔
- 目錄
- 前言
- 1 簡介
- 2 工效學
- 3 代
- 4 確定世代規模
- 5 可用的收集器
- 6 並行收集器
- 7 大多數併發收集器
- 8 併發標記掃描(CMS)收集器
- 9 垃圾優先(G1)垃圾收集器
- 10 垃圾優先垃圾收集器調優
- 11 其他註意事項
前言
_Java *台標準版 HotSpot 虛擬機垃圾收集調整指南_描述了 Java HotSpot 虛擬機 (Java HotSpot VM) 中包含的垃圾收集方法,並幫助您確定最適合您需要的方法。
觀眾
本文檔適用於希望提高應用程式性能的應用程式開發人員和系統管理員,尤其是那些處理大量數據、使用多線程和具有高事務率的應用程式。
文檔輔助功能
有關 Oracle 對可訪問性的承諾的信息,請訪問 Oracle 可訪問性計劃網站:http://www.oracle.com/pls/topic/lookup?ctx=acc&id=docacc 。
獲得 Oracle 支持
購買了支持的 Oracle 客戶可以通過 My Oracle Support 獲得電子支持。 有關信息,請訪問 http://www.oracle.com/pls/topic/lookup?ctx=acc&id=info ,或者如果您有聽力障礙的話,也可以訪問 http://www.oracle.com/pls/topic/lookup?ctx=acc&id=trs 。
相關文件
有關詳細信息,請參閱以下文檔:
- Java虛擬機技術
http://docs.oracle.com/javase/8/docs/technotes/guides/vm/index.html - Java SE HotSpot 一覽
http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136373.html - HotSpot VM 常見問題 (FAQ)
http://www.oracle.com/technetwork/java/hotspotfaq-138619.html - Richard Jones 和 Rafael Lins, 《垃圾收集: 自動動態記憶體管理演算法》, Wiley and Sons (1996), ISBN 0-471-94148-4
慣例
本文檔中使用了以下文本約定:
| 慣例 | 意義 |
|---|---|
| 黑體字 | 粗體字表示與操作相關的圖形用戶界面元素,或在文本或辭彙表中定義的術語。 |
| 斜體 | 斜體表示書名、重點或您為其提供特定值的占位符變數。 |
| 等寬 | 等寬字體表示段落中的命令、URL、示例中的代碼、出現在屏幕上的文本或您輸入的文本。 |
譯者註:由於原文和譯文的格式差異,該慣例可能存在一些差異。
1 簡介
各種各樣的應用程式使用 Java Platform, Standard Edition (Java SE),從桌面上的小程式到大型伺服器上的 Web 服務。 為了支持這種多樣化的部署,Java HotSpot 虛擬機實現 (Java HotSpot VM) 提供了多個垃圾收集器,每個垃圾收集器旨在滿足不同的需求。 這是滿足大型和小型應用程式需求的重要部分。 Java SE 根據運行應用程式的電腦類別選擇最合適的垃圾收集器。 但是,此選擇可能並非對每個應用程式都是最佳選擇。 具有嚴格性能目標或其他要求的用戶、開發人員和管理員可能需要明確選擇垃圾收集器並調整某些參數以達到所需的性能水*。 本文檔提供了有助於完成這些任務的信息。 首先,垃圾收集器的一般特性和基本調優選項在串列停止世界收集器的上下文中進行了描述。 然後介紹了其他收集器的具體特征以及選擇收集器時要考慮的因素。
垃圾收集器 (GC) 是一種記憶體管理工具。 它通過以下操作實現了自動記憶體管理:
- 將對象分配給年輕代並將老化的對象提升到老年代。
- 通過併發(並行)標記階段在老一代中查找活動對象。當 Java 堆總占用率超過預設閾值時,Java HotSpot VM 會觸發標記階段。請參閱 併發標記清除 (CMS) 收集器 和 垃圾優先垃圾收集器 部分。
- 通過並行複製壓縮活動對象來恢復空閑記憶體。 請參閱 並行收集器 和 [垃圾優先垃圾收集器(G1垃圾收集器)](https: //docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc.html#garbage_first_garbage_collection)
垃圾收集器的選擇何時重要?對於某些應用程式,答案是否定的。也就是說,應用程式可以在存在垃圾收集的情況下以適度的頻率和持續時間暫停執行良好。 但是,對於大量應用程式,尤其是那些具有大量數據(數 GB)、許多線程和高事務率的應用程式,情況並非如此。
阿姆達爾定律(給定問題的並行加速受限於問題的順序部分)意味著大多數工作負載無法完美並行化; 某些部分始終是順序的,並且不會從並行性中受益。 Java *台也是如此。 特別是,Oracle 為 Java SE 1.4 之前的 Java *台提供的虛擬機不支持並行垃圾收集,因此垃圾收集對多處理器系統的影響相對於其他並行應用程式而言會增加。
圖 1-1,“比較垃圾收集中花費的時間百分比” 模擬了一個理想的系統,除了垃圾收集 (GC) 之外,該系統可完美擴展。 紅線是應用程式在單處理器系統上僅花費 1% 的時間進行垃圾回收。 這意味著具有 32 個處理器的系統的吞吐量損失超過 20%。 洋紅色線表明,對於 10% 的時間用於垃圾收集的應用程式(在單處理器應用程式中,垃圾收集的時間不算離譜),當擴展到 32 個處理器時,超過 75% 的吞吐量會丟失。
**_圖1-1 比較垃圾收集所花費的時間百分比
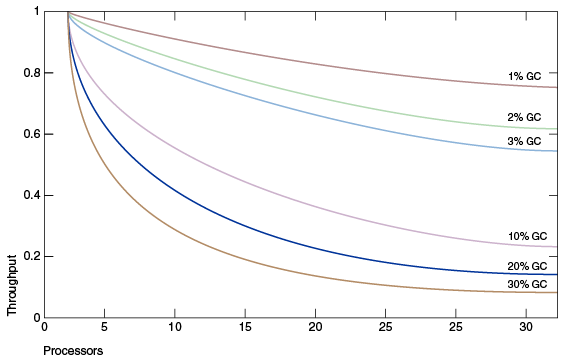
“圖1-1比較垃圾回收時間百分比”的說明
該圖模擬了一個完美可擴展的理想系統,但垃圾收集 (GC) 除外。 它繪製了處理器數量(x 軸)與吞吐量(y 軸)的關係圖。 它包含標記為 1% GC、2% GC、3% GC、10% GC、20% GC 和 30% GC 的六條標繪線。 每條線代表一個應用程式吞吐量的變化,該應用程式在單處理器系統和多處理器系統上花費了指定百分比的時間用於垃圾收集。 該圖在其前面的文本中進行了描述。
這表明在小型系統上開發時可以忽略不計的速度問題可能會成為擴展到大型系統時的主要瓶頸。 然而,在減少這種瓶頸方面的小改進可以產生很大的性能提升。 對於一個足夠大的系統,選擇正確的垃圾收集器併在必要時對其進行調整是值得的。
串列收集器通常足以滿足大多數“小型”應用程式(那些需要最多約 100 兆位元組 (MB) 的堆(在現代處理器上)。其他收集器有額外的開銷或複雜性,這是專門行為的代價。如果應用程式 不需要備用收集器的特殊行為,請使用串列收集器。串列收集器不是最佳選擇的一種情況是大型、重線程應用程式運行在具有大量記憶體和兩個的機器上 或更多處理器。當應用程式在此類伺服器級機器上運行時,預設情況下會選擇並行收集器。請參閱 工效學 部分。
本文檔是在 Solaris 操作系統(SPARC *台版)上使用 Java SE 8 作為參考開發的。 但是,此處介紹的概念和建議適用於所有受支持的*台,包括 Linux、Microsoft Windows、Solaris 操作系統(x64 *台版)和 OS X。此外,提到的命令行選項在所有受支持的*臺上都可用,儘管 某些選項的預設值在每個*臺上可能不同。
2 工效學
工效學 是 Java 虛擬機 (JVM) 和垃圾收集調整(例如基於行為的調整)提高應用程式性能的過程。 JVM 為垃圾收集器、堆大小和運行時編譯器提供依賴於*台的預設選擇。 這些選擇滿足不同類型應用程式的需求,同時需要較少的命令行調整。 此外,基於行為的調整會動態調整堆的大小以滿足應用程式的特定行為。 本節介紹這些預設選擇和基於行為的調整。 在使用後續部分中描述的更詳細的控制項之前,請先使用這些預設值。
垃圾收集器、堆和運行時編譯器預設選擇
稱為伺服器類機器的一類機器被定義為具有以下內容的機器:
- 2 個或更多物理處理器
- 2 GB 或更多的物理記憶體
在伺服器級機器上,預設選擇以下選項:
- 吞吐量垃圾收集器
- 初始堆大小為物理記憶體的 1/64,最高可達 1 GB
- 最大堆大小為物理記憶體的 1/4,最高可達 1 GB
- 伺服器運行時編譯器 有關 64 位系統的初始堆和最大堆大小,請參閱 預設堆大小 在 6 並行收集器 中。
伺服器級機器的定義適用於所有*台,但運行 Windows 操作系統版本的 32 位*台除外。 表 2-1,“預設運行時編譯器”,顯示了為 不同*台的運行時編譯器。
表 2-1 預設運行時編譯器
| *台 | 操作系統 | 預設值Foot1 | 預設是否是伺服器類Footref1 |
|---|---|---|---|
| i586 | Linux | Client | Server |
| i586 | Windows | Client | ClientFoot2 |
| SPARC (64-bit) | Solaris | Server | ServerFoot3 |
| AMD (64-bit) | Linux | Server | ServerFootref3 |
| AMD (64-bit) | Windows | Server | ServerFootref3 |
- [^Footnote1] 客戶端表示使用客戶端運行時編譯器。 伺服器表示使用伺服器運行時編譯器。
- [^Footnote2] 該策略被選擇為即使在伺服器類機器上也使用客戶端運行時編譯器。 做出此選擇是因為以前客戶端應用程式(例如,互動式應用程式)在這種*台和操作系統的組合上運行得更頻繁。
- [^Footnote3] 僅支持伺服器運行時編譯器。
基於行為的調優
對於並行收集器,Java SE 提供了兩個基於實現應用程式特定行為的垃圾收集調優參數:最大暫停時間目標和應用程式吞吐量目標; 請參閱 並行收集器 部分。 (這兩個選項在其他收集器中不可用。)請註意,並非總能滿足這些行為。 該應用程式需要一個足夠大的堆,以至少容納所有實時數據。 此外,最小堆大小可能會妨礙實現這些預期目標。
最長停頓時間目標
暫停時間是垃圾收集器停止應用程式並回收不再使用的空間的持續時間。 最大暫停時間目標的目的是限制最長的暫停時間。 垃圾收集器維護暫停的*均時間和該*均值的變化。 *均值是從執行開始時獲取的,但經過加權,因此最*的暫停次數更多。 如果*均值加上停頓時間的方差大於最大停頓時間目標,則垃圾收集器認為沒有達到目標。 最大暫停時間目標是使用命令行選項 -XX:MaxGCPauseMillis=<nnn> 指定的。 這被解釋為對垃圾收集器的提示,即需要 <nnn> 毫秒或更短的暫停時間。 垃圾收集器將調整 Java 堆大小和其他與垃圾收集相關的參數,以試圖使垃圾收集暫停時間短於 <nnn> 毫秒。 預設情況下沒有最大暫停時間目標。 這些調整可能會導致垃圾收集器更頻繁地發生,從而降低應用程式的整體吞吐量。 垃圾收集器嘗試在吞吐量目標之前滿足任何暫停時間目標。 但是,在某些情況下,無法達到所需的暫停時間目標。
吞吐量目標
吞吐量目標是根據收集垃圾所花費的時間和在垃圾收集之外所花費的時間(稱為 應用程式時間 )來衡量的。 目標由命令行選項 -XX:GCTimeRatio=<nnn> 指定。垃圾收集時間與應用程式時間的比率為 1 / (1 + <nnn> )。 例如,-XX:GCTimeRatio=19 將目標設置為垃圾收集總時間的 1/20 或 5%。
垃圾收集花費的時間是年輕代和老年代收集的總時間。如果未達到吞吐量目標,則會增加各代的大小,以增加應用程式可以在兩次收集之間運行的時間。
Footprint占用空間目標
如果達到了吞吐量和最大暫停時間目標,則垃圾收集器會減小堆的大小,直到無法滿足其中一個目標(總是吞吐量目標)。 然後解決未實現的目標。
調整策略
不要為堆選擇最大值,除非您知道您需要一個大於預設最大堆大小的堆。 選擇一個足以滿足您的應用程式的吞吐量目標。
堆將增長或縮小到支持所選吞吐量目標的大小。 應用程式行為的變化會導致堆增大或縮小。 例如,如果應用程式開始以更高的速率分配,堆將增長以保持相同的吞吐量。
如果堆增長到其最大大小並且未滿足吞吐量目標,則最大堆大小對於吞吐量目標來說太小了。 將最大堆大小設置為接**臺上總物理記憶體但不會導致應用程式交換的值。 再次執行應用程式。 如果仍然沒有達到吞吐量目標,那麼應用程式時間的目標對於*臺上的可用記憶體來說太高了。
如果可以達到吞吐量目標,但停頓時間過長,則選擇最大停頓時間目標。 選擇最大暫停時間目標可能意味著無法滿足您的吞吐量目標,因此請選擇應用程式可接受的折衷值。
當垃圾收集器試圖滿足競爭目標時,堆的大小通常會波動。 即使應用程式已達到穩定狀態也是如此。 實現吞吐量目標(可能需要更大的堆)的壓力與最大暫停時間和最小占用空間(兩者都可能需要較小的堆)的目標競爭。
3 代
Java SE *台的優勢之一是它使開發人員免於記憶體分配和垃圾收集的複雜性。 然而,當垃圾收集成為主要瓶頸時,瞭解這個隱藏實現的某些方面是很有用的。 垃圾收集器對應用程式使用對象的方式做出假設,這些都反映在可調參數中,可以在不犧牲抽象能力的情況下調整這些參數以提高性能。
當運行程式中的任何指針都無法再訪問某個對象時,該對象就被認為是垃圾。 最直接的垃圾收集演算法遍歷每個可到達的對象。 剩下的任何對象都被視為垃圾。 這種方法所花費的時間與活動對象的數量成正比,這對於維護大量活動數據的大型應用程式來說是令人望而卻步的。
虛擬機包含許多不同的垃圾收集演算法,這些演算法使用 generational collection 組合。朴素的垃圾收集檢查堆中的每個活動對象,而分代收集利用大多數應用程式的幾個憑經驗觀察到的屬性來最小化回收未使用(垃圾)對象所需的工作。 這些觀察到的屬性中最重要的是弱_世代假設_,它指出大多數物體只能存活很短的時間。
圖 3-1,“對象生命周期的典型分佈” 中的藍色區域 是對象生命周期的典型分佈。 x 軸是以分配的位元組為單位測量的對象生命周期。 y 軸上的位元組數是具有相應生命周期的對象中的總位元組數。左邊的尖峰表示在分配後不久就可以回收(換句話說,已經“死亡”)的對象。 例如,迭代器對象通常在單個迴圈的持續時間內處於活動狀態。
圖 3-1 對象生命周期的典型分佈
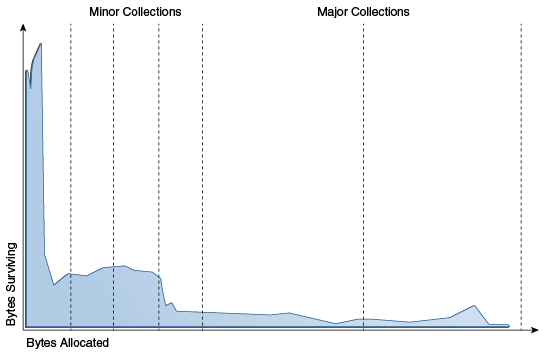
“圖 3-1 對象生命周期的典型分佈”說明
此圖的 x 軸“分配的位元組數”表示以分配的位元組數衡量的對象生命周期。 y 軸“Bytes surviving”是具有相應生命周期的對象的總位元組數。 該圖左側的三分之一標記為“次要收集”。 圖表右側的三分之二標記為“主要收藏”。 繪製線下方的區域為實心且顏色為藍色。 該區域代表對象生命周期的典型分佈。 該區域在左側急劇上升並向右延伸。 該圖在它周圍的文本中有進一步描述。
有些物體確實壽命更長,因此分佈向右延伸。 例如,通常有一些在初始化時分配的對象會一直存在到進程退出。 在這兩個極端之間的是在某些中間計算期間存在的對象,這裡被視為初始峰值右側的塊。 一些應用程式看起來分佈非常不同,但數量驚人的多都具有這種一般形狀。 通過關註大多數對象“早逝”這一事實,可以實現高效收集。
為了針對這種情況進行優化,記憶體在 generations(記憶體池保存不同年齡的對象)中進行管理。 垃圾收集發生在每一代填滿時。 絕大多數對象都分配在專用於年輕對象(年輕一代)的池中,並且大多數對象都死在那裡。 當年輕一代填滿時,它會引發一個 minor collection,其中只有年輕一代被收集; 其他世代的垃圾不回收。 Minor collections 可以優化,假設弱代假設成立並且年輕代中的大多數對象都是垃圾並且可以被回收。 此類收集的成本首先與收集的活動對象數量成正比; 很快就會收集充滿死對象的年輕一代。 通常,在每次小收集期間,年輕一代中的一些幸存對象會被移動到老年代。 最終,tenured generation 將填滿並且必須被收集,導致 major collection,其中收集整個堆。 主要收集通常比次要收集持續的時間長得多,因為涉及的對象數量要多得多。
正如 工效學 部分所述,工效學會動態選擇垃圾收集器以提供良好的性能 在各種應用程式上。 串列垃圾收集器專為具有小數據集的應用程式而設計,其預設參數被選擇為對大多數小應用程式有效。 並行或吞吐量垃圾收集器旨在與具有中型到大型數據集的應用程式一起使用。 工效學選擇的堆大小參數加上自適應大小策略的特性旨在為伺服器應用程式提供良好的性能。 這些選擇在大多數(但不是所有)情況下都適用,這導致了本文檔的中心原則:
註:
如果垃圾收集成為瓶頸,您很可能必須自定義總堆大小以及各個代的大小。 檢查詳細的垃圾收集器輸出,然後探索您的個人性能指標對垃圾收集器參數的敏感性。
圖 3-2,“代的預設排列,並行收集器和 G1 除外” 顯示預設的世代安排(對於除並行收集器和 G1 之外的所有收集器):
圖 3-2 生成的預設排列,並行收集器和 G1 除外
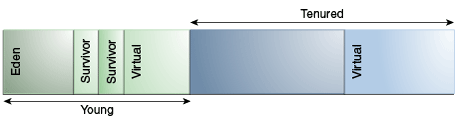
[“圖 3-2 預設分代安排,並行收集器和 G1 除外”的說明](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/img_text/jsgct_dt_001_armgnt_gn. 網頁)
此圖由一排六個矩形組成。 這些矩形標記如下(從左到右):
- Eden
- Survivor
- Spaces
- Virtual
- No label
- Virtual
矩形 1 到 4 標記為“年輕”。 矩形 5 到 6 標記為“Tenured”。
在初始化時,最大地址空間實際上是保留的,但除非需要,否則不會分配給物理記憶體。 為對象記憶體保留的完整地址空間可以分為年輕代和老年代。
新生代由伊甸園和兩個幸存者空間組成。 大多數對象最初是在伊甸園中分配的。 一個幸存者空間在任何時候都是空的,作為伊甸園中任何活物體的歸宿; 另一個幸存者空間是下一次複製收集期間的目的地。 對象以這種方式在幸存者空間之間複製,直到它們足夠老可以被永久使用(複製到永久代)。
性能註意事項
垃圾收集性能有兩個主要衡量標準:
- 吞吐量 是長時間內未花費在垃圾收集上的總時間的百分比。 吞吐量包括花費在分配上的時間(但通常不需要調整分配速度)。
- 暫停 是應用程式由於正在進行垃圾收集而出現無響應的時間。
用戶對垃圾回收有不同的要求。 例如,一些人認為 Web 伺服器的正確指標是吞吐量,因為垃圾收集期間的暫停可能是可以容忍的,或者只是被網路延遲所掩蓋。 然而,在互動式圖形程式中,即使是短暫的停頓也可能對用戶體驗產生負面影響。
一些用戶對其他註意事項很敏感。 Footprint占用空間 是進程的工作集,以頁面和緩存行為單位進行衡量。 在物理記憶體有限或進程較多的系統上,占用空間可能決定可伸縮性。 Promptness(敏捷) 是對象死亡和記憶體變為可用之間的時間,這是分散式系統(包括遠程方法調用 (RMI))的一個重要考慮因素。
通常,為特定代選擇大小是這些考慮因素之間的權衡。 例如,一個非常大的年輕一代可能會最大化吞吐量,但這樣做會以占用空間、及時性和暫停時間為代價。 可以通過以吞吐量為代價使用較小的年輕代來最小化年輕代暫停。 一代的大小不會影響另一代的收集頻率和暫停時間。
沒有一種正確的方法來選擇一代的大小。 最佳選擇取決於應用程式使用記憶體的方式以及用戶要求。 因此,虛擬機對垃圾收集器的選擇並不總是最佳的,並且可能會被 調整代數 部分中描述的命令行選項覆蓋。
測量
吞吐量和占用空間最好使用特定於應用程式的指標來衡量。 例如,可以使用客戶端負載生成器測試 Web 伺服器的吞吐量,而可以使用 pmap 命令在 Solaris 操作系統上測量伺服器的占用空間。 但是,通過檢查虛擬機本身的診斷輸出可以很容易地估計由於垃圾收集而導致的暫停。 命令行選項 -verbose:gc 會導致在每次收集時列印有關堆和垃圾收集的信息。 例如,這是一個大型伺服器應用程式的輸出:
[GC 325407K->83000K(776768K), 0.2300771 secs]
[GC 325816K->83372K(776768K), 0.2454258 secs]
[Full GC 267628K->83769K(776768K), 1.8479984 secs]
輸出顯示兩個次要收集,然後是一個主要收集。箭頭前後的數字(例如,第一行的 325407K->83000K )分別表示垃圾回收前後活動對象的組合大小。 minor collections 後,size 中包含了一些對象,這些對象是垃圾(不再存活)但無法回收。 這些對象要麼包含在 tenured generation 中,要麼從 tenured generation 中引用。
括弧中的下一個數字(例如,來自第一行的 (776768K) )是堆的提交大小:無需從操作系統請求更多記憶體即可用於 Java 對象的空間量。 請註意,此數字僅包括一個幸存者空間。 除了垃圾回收期間,在任何給定時間都只會使用一個幸存者空間來存儲對象。
該行的最後一項(例如,0.2300771 秒)表示執行收集所花費的時間,在本例中大約為四分之一秒。
第三行中主要收集的格式類似。
註:
-verbose:gc產生的輸出格式在未來的版本中可能會發生變化。
命令行選項 -XX:+PrintGCDetails 會導致列印有關收集的附加信息。 此處顯示了使用串列垃圾收集器的 -XX:+PrintGCDetails 輸出示例。
[GC [DefNew: 64575K->959K(64576K), 0.0457646 secs] 196016K->133633K(261184K), 0.0459067 secs]
這表明 minor collection 恢復了大約 98% 的年輕代,DefNew: 64575K->959K(64576K) 並花費了 0.0457646 秒(大約 45 毫秒)。 整個堆的使用率減少到大約 51% (196016K->133633K(261184K)),並且收集有一些額外的開銷(超過年輕代的收集),如最終結果所示 0.0459067 秒 的時間。
註:
-XX:+PrintGCDetails產生的輸出格式在未來的版本中可能會發生變化。 選項-XX:+PrintGCTimeStamps在每個收集的開始添加時間戳。 這對於查看垃圾收集發生的頻率很有用。
111.042: [GC 111.042: [DefNew: 8128K->8128K(8128K), 0.0000505 secs] 111.042: [Tenured: 18154K->2311K(24576K), 0.1290354 secs] 26282K->2311K(32704K), 0.1293306 secs]
收集在應用程式執行後大約 111 秒開始。 次要收集大約在同一時間開始。 此外,還顯示了由 Tenured 劃定的主要館藏的信息。 老年代使用率降低到大約 10% (18154K->2311K(24576K)) 並花費了 0.1290354 秒(大約 130 毫秒)。
4 確定世代規模
許多參數影響生成大小。 圖 4-1,“堆參數” 說明瞭堆中的 Committed 和 Virtual 之間的區別。 在虛擬機初始化時,為堆保留整個空間。 保留空間的大小可以使用 -Xmx 選項指定。 如果“-Xms”參數的值小於“-Xmx”參數的值,那麼並非所有保留的空間都會立即提交給虛擬機。 未提交的空間在此圖中標記為“虛擬”。 堆的不同部分(tenured generation 和 young generation)可以根據需要增長到虛擬空間的極限。
一些參數是堆的一部分與另一部分的比率。 例如,參數 NewRatio 表示老一代與年輕一代的相對大小。
圖 4-1 堆參數
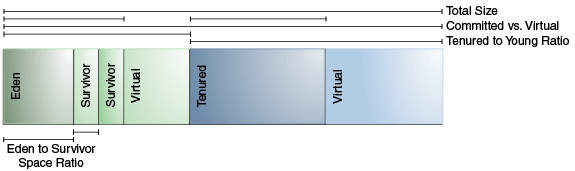
圖4-1堆參數說明
該圖由一排六個矩形組成,標記如下(從左到右):
- Eden
- Survivor
- Survivor
- Virtual
- Tenured
- Virtual
矩形組標記如下:
- 總大小:矩形1到6
- Committed vs. Virtual:Committed 由矩形 1 到 3 和 5 組成; virtual 由矩形 4 和 6 組成
- Tenured to Young ratio:Tenured由矩形1-4組成; 年輕的由矩形 5-6 組成
- Eden to Survivor 空間比例:Eden 為矩形 1; 幸存者空間為矩形 2
總堆
以下關於堆和預設堆大小的增長和收縮的討論不適用於並行收集器。 (請參閱 6 並行收集器 部分在 4 確定世代規模 有關並行收集器的堆大小調整和預設堆大小的詳細信息。)但是,控制總數的參數 堆的大小和世代的大小確實適用於並行收集器。 影響垃圾收集性能的最重要因素是可用記憶體總量。 因為收集發生在各代填滿時,吞吐量與可用記憶體量成反比。
預設情況下,虛擬機會在每次收集時增大或縮小堆,以儘量將每次收集時可用空間與活動對象的比例保持在特定範圍內。 此目標範圍由參數-XX:MinHeapFreeRatio=<minimum> 和-XX:MaxHeapFreeRatio=<maximum> 設置為百分比,並且總大小低於-Xms<min> 及以上為 -Xmx<max>。 64 位 Solaris 操作系統(SPARC *台版)的預設參數顯示在 表 4-1 64 位 Solaris 操作系統的預設參數 :
表 4-1 64 位 Solaris 操作系統的預設參數 ^dc3d9b
| Parameter | Default Value |
|---|---|
| MinHeapFreeRatio | 40 |
| MaxHeapFreeRatio | 70 |
| -Xms | 6656k |
| -Xmx | calculated |
使用這些參數,如果一代中可用空間的百分比低於 40%,則該代將擴展以保持 40% 的可用空間,直至達到該代允許的最大大小。 類似地,如果可用空間超過 70%,則生成將收縮,以便只有 70% 的空間可用,以生成的最小大小為準。
如 表 4-1 64 位 Solaris 操作系統的預設參數 ,預設最大堆大小是由 JVM 計算的值。 Java SE 中用於並行收集器和伺服器 JVM 的計算現在用於所有垃圾收集器。 部分計算是最大堆大小的上限,這對於 32 位*台和 64 位*台是不同的。
請參閱 6 並行收集器 中的 預設堆大小 部分。客戶端 JVM 有類似的計算,這導致最大堆大小小於伺服器 JVM。
以下是有關伺服器應用程式堆大小的一般準則:
- 除非您遇到暫停問題,否則請嘗試為虛擬機分配儘可能多的記憶體。 預設大小通常太小。
- 將
-Xms和-Xmx設置為相同的值,通過從虛擬機中刪除最重要的大小調整決策來提高可預測性。 但是,如果您做出了錯誤的選擇,虛擬機將無法進行補償。 - 通常,隨著處理器數量的增加而增加記憶體,因為分配可以並行化。
年輕一代
在總可用記憶體之後,影響垃圾收集性能的第二大影響因素是專用於年輕代的堆的比例。 年輕一代越大,minor collections 發生的頻率就越低。 然而,對於有限的堆大小,較大的新生代意味著較小的老年代,這將增加主要收集的頻率。 最佳選擇取決於應用程式分配的對象的生命周期分佈。
預設情況下,新生代大小由參數 NewRatio 控制。 例如,設置-XX:NewRatio=3表示年輕代和老年代的比例為1:3。 換句話說,eden 和 survivor 空間的組合大小將是總堆大小的四分之一。
參數 NewSize 和 MaxNewSize 從下方和上方限制了年輕代的大小。 將這些設置為相同的值可以修複年輕代,就像將 -Xms 和 -Xmx 設置為相同的值可以修複總堆大小一樣。 這對於以比 NewRatio 允許的整數倍更細的粒度調整年輕代很有用。
幸存者空間大小
您可以使用參數 SurvivorRatio 來調整幸存者空間的大小,但這通常對性能並不重要。 例如,-XX:SurvivorRatio=6 將伊甸園和幸存者空間之間的比例設置為 1:6。 換句話說,每個幸存者空間將是伊甸園大小的六分之一,因此是年輕代大小的八分之一(不是七分之一,因為有兩個幸存者空間)。
如果幸存者空間太小,複製收集會直接溢出到老年代。 如果幸存者空間太大,它們將毫無用處地空著。 在每次垃圾回收時,虛擬機都會選擇一個閾值,即一個對象在被使用之前可以被覆制的次數。 選擇此閾值是為了讓幸存者保持半滿狀態。 命令行選項 -XX:+PrintTenuringDistribution(並非所有垃圾收集器都可用)可用於顯示此閾值和新一代對象的年齡。 它對於觀察應用程式的生命周期分佈也很有用。
表 4-2,“Survivor 空間大小調整的預設參數值”提供了 64 位 Solaris 的預設值:
表 4-2 幸存者空間大小調整的預設參數值
| Parameter | Server JVM Default Value |
|---|---|
| NewRatio | 2 |
| NewSize | 1310M |
| MaxNewSize | not limited |
| SurvivorRatio | 8 |
新生代的最大大小將根據總堆的最大大小和 NewRatio 參數的值計算得出。 MaxNewSize 參數的“不受限制”預設值意味著計算值不受 MaxNewSize 的限制,除非在命令行上指定了 MaxNewSize 的值。
以下是伺服器應用程式的一般準則:
- 首先決定你能負擔得起的最大堆大小給虛擬機。 然後將你的性能指標與年輕一代的大小進行對比,以找到最佳設置。
- 請註意,最大堆大小應始終小於機器上安裝的記憶體量,以避免過多的頁面錯誤和抖動。
- 如果總堆大小是固定的,那麼增加新生代的大小需要減少老年代的大小。 保持老年代足夠大以容納應用程式在任何給定時間使用的所有實時數據,外加一定量的鬆弛空間(10% 到 20% 或更多)。
- 受制於前面所述的對終身一代的限制:
- 為年輕一代提供充足的記憶體。
- 隨著處理器數量的增加而增加新生代的大小,因為分配可以並行化。
5 可用的收集器
到目前為止的討論都是關於串列收集器的。 Java HotSpot VM 包括三種不同類型的收集器,每種都有不同的性能特征。
- 串列收集器使用單個線程來執行所有垃圾收集工作,這使得它相對高效,因為線程之間沒有通信開銷。 它最適合單處理器機器,因為它不能利用多處理器硬體,儘管它在多處理器上對於具有小數據集(最多大約 100 MB)的應用程式很有用。 在某些硬體和操作系統配置中預設選擇串列收集器,或者可以使用選項
-XX:+UseSerialGC顯式啟用。 - 並行收集器(也稱為 吞吐量收集器 ) 並行執行次要收集,這可以顯著減少垃圾收集開銷。 它適用於在多處理器或多線程硬體上運行的具有中型到大型數據集的應用程式。 並行收集器在某些硬體和操作系統配置上預設選擇,或者可以使用選項
-XX:+UseParallelGC顯式啟用。- 並行壓縮是一種使並行收集器能夠並行執行主要收集的功能。 如果沒有並行壓縮,主要的收集是使用單個線程執行的,這會顯著限制可伸縮性。 如果指定了選項
-XX:+UseParallelGC,則預設啟用並行壓縮。 關閉它的選項是-XX:-UseParallelOldGC。
- 並行壓縮是一種使並行收集器能夠並行執行主要收集的功能。 如果沒有並行壓縮,主要的收集是使用單個線程執行的,這會顯著限制可伸縮性。 如果指定了選項
- 大多數併發收集器 併發執行其大部分工作(例如,當應用程式仍在運行時)以保持垃圾收集暫停時間短。 它專為具有中型到大型數據集的應用程式而設計,在這些應用程式中響應時間比總吞吐量更重要,因為用於最小化暫停的技術會降低應用程式性能。 Java HotSpot VM 提供了兩個主要併發的收集器之間的選擇; 請參閱 大多數併發收集器。 使用選項
-XX:+UseConcMarkSweepGC啟用 CMS 收集器或使用選項-XX:+UseG1GC啟用 G1 收集器。
選擇收集器
除非你的應用程式有相當嚴格的暫停時間要求,否則首先運行你的應用程式並允許 VM 選擇一個收集器。 如有必要,調整堆大小以提高性能。 如果性能仍未達到您的目標,請使用以下指南作為選擇收集器的起點。
- 如果應用程式的數據集較小(最多約 100 MB),則 使用選項
-XX:+UseSerialGC選擇串列收集器。 - 如果應用程式將在單處理器上運行並且沒有暫停時間要求,則讓 VM 選擇收集器,或者使用選項“-XX:+UseSerialGC”選擇串列收集器。
- 如果 (a) 峰值應用程式性能是第一優先順序並且 (b) 沒有暫停時間要求或 1 秒或更長時間的暫停是可以接受的,那麼讓 VM 選擇收集器,或者選擇帶有
-XX:+UseParallelGC。 - 如果響應時間比整體吞吐量更重要,並且垃圾收集暫停必須保持短於大約 1 秒,則選擇帶有
-XX:+UseConcMarkSweepGC或-XX:+UseG1GC的併發收集器。
這些指南僅提供了選擇收集器的起點,因為性能取決於堆的大小、應用程式維護的實時數據量以及可用處理器的數量和速度。 暫停時間對這些因素特別敏感,因此前面提到的 1 秒閾值只是一個*似值:並行收集器在許多數據大小和硬體組合上都會經歷超過 1 秒的暫停時間; 相反,併發收集器可能無法在某些組合上保持短於 1 秒的暫停。
如果推薦的收集器沒有達到預期的性能,首先嘗試調整堆和生成大小以滿足預期的目標。 如果性能仍然不足,則嘗試不同的收集器:使用併發收集器來減少暫停時間並使用並行收集器來增加多處理器硬體上的整體吞吐量。
6 並行收集器
並行收集器(這裡也稱為 吞吐量收集器 )是一種類似於串列收集器的分代收集器; 主要區別在於使用多個線程來加速垃圾收集。 並行收集器通過命令行選項 -XX:+UseParallelGC 啟用。 預設情況下,使用此選項,並行執行次要和主要收集以進一步減少垃圾收集開銷。
在具有 N 硬體線程(其中 N 大於 8)的機器上,並行收集器使用 N 的固定分數作為垃圾收集器線程數。 對於較大的 N 值,分數約為 5/8。 在 N 的值低於 8 時,使用的數字是 N。 在選定的*臺上,該比例降至 5/16。 垃圾收集器線程的具體數量可以通過命令行選項進行調整(稍後介紹)。 在具有一個處理器的主機上,由於並行執行所需的開銷(例如,同步),並行收集器的性能可能不如串列收集器。 然而,當運行具有中型到大型堆的應用程式時,它通常在具有兩個處理器的機器上略勝串列收集器,並且通常在有兩個以上處理器可用時比串列收集器表現更好。
可以使用命令行選項 -XX:ParallelGCThreads=<N> 控制垃圾收集器線程的數量。 如果使用命令行選項顯式調整堆,那麼並行收集器獲得良好性能所需的堆大小與串列收集器所需的堆大小相同。 但是,啟用並行收集器應該可以縮短收集暫停時間。 因為多個垃圾收集器線程正在參與次要收集,所以由於在收集期間從年輕代提升到老年代,可能會產生一些碎片。 minor collection 中涉及的每個垃圾回收線程都會保留一部分老年代用於提升,將可用空間劃分為這些“提升緩衝區”會導致碎片效應。 減少垃圾收集器線程的數量並增加老年代的大小將減少這種碎片效應。
世代
如前所述,並行收集器中代的排列是不同的。 這種安排顯示在 圖 6-1,“並行收集器中的世代安排” :
圖6-1 並行收集器中代的排列
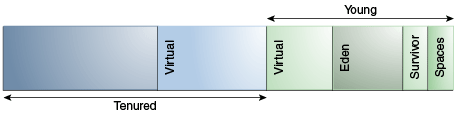
“圖 6-1 並行收集器中世代排列”的說明
此圖顯示了並行收集器中代的排列。 該圖由一排六個矩形組成。 這些矩形標記如下(從左到右):
- No label
- Virtual
- Virtual
- Eden
- Survivor
- Spaces
矩形 1 和 2 標記為“Tenured”。 矩形 3 到 6 標記為“年輕”。 矩形 7 和 8 標記為“Perm”。
並行收集器工效學
伺服器級機器預設選擇並行收集器。 此外,並行收集器使用一種自動調整方法,允許您指定特定行為而不是生成大小和其他低級別調整細節。 您可以指定最大垃圾收集暫停時間、吞吐量和占用空間(堆大小)。
- 最大垃圾收集暫停時間:最大暫停時間目標是使用命令行選項
-XX:MaxGCPauseMillis=<N>指定的。 這被解釋為暗示需要<N>毫秒或更短的暫停時間; 預設情況下,沒有最長暫停時間目標。 如果指定了暫停時間目標,則會調整堆大小和與垃圾收集相關的其他參數,以嘗試使垃圾收集暫停時間短於指定值。 這些調整可能會導致垃圾收集器降低應用程式的整體吞吐量,並且無法始終滿足所需的暫停時間目標。 - 吞吐量:吞吐量目標是根據垃圾收集所花費的時間與垃圾收集之外所花費的時間(稱為應用程式時間)來衡量的。 目標由命令行選項
-XX:GCTimeRatio=<N>指定,它將垃圾收集時間與應用程式時間的比率設置為1 / (1 +<N>).- 例如,
-XX:GCTimeRatio=19將目標設置為垃圾收集總時間的 1/20 或 5%。 預設值為 99,目標是 1% 的時間用於垃圾回收。
- 例如,
- Footprint占用空間:最大堆占用空間使用選項
-Xmx<N>指定。 此外,收集器有一個隱含的目標,即在滿足其他目標的情況下最小化堆的大小。
目標的優先順序
這些目標按以下順序處理:
- 最大停頓時間目標
- 吞吐量目標
- 最小占用空間目標
首先滿足最大暫停時間目標。 只有在滿足它之後,吞吐量目標才會得到解決。 同樣,只有在滿足前兩個目標後,才會考慮footprint占用空間目標。
生成大小調整
收集器保存的*均停頓時間等統計信息在每次收集結束時更新。 然後進行確定是否已達到目標的測試,並對生成的大小進行任何必要的調整。 例外情況是顯式垃圾收集(例如,調用 System.gc())在保留統計信息和調整生成大小方面會被忽略。
增加和縮小一代的大小是通過增量來完成的,增量是一代大小的固定百分比,以便一代逐步增加或減少到其所需的大小。 增長和收縮以不同的速度進行。 預設情況下,一代以 20% 的增量增長,以 5% 的增量收縮。 增長的百分比由年輕一代的命令行選項 -XX:YoungGenerationSizeIncrement=<Y> 和老一代的 -XX:TenuredGenerationSizeIncrement=<T> 控制。 一代收縮的百分比由命令行標誌 -XX:AdaptiveSizeDecrementScaleFactor=<D> 調整。 如果增長增量為 X 百分比,則收縮減量為 X/D 百分比。
如果收集器決定在啟動時增長一代,那麼增量中會添加一個補充百分比。 此補品隨收藏次數遞減,無遠期作用。 補充的目的是提高啟動性能。 收縮的百分比沒有補充。
如果未達到最大暫停時間目標,則一次僅縮小一代的大小。 如果兩代人的停頓時間都在目標之上,那麼停頓時間較大的那一代人的規模首先縮小。
如果未達到吞吐量目標,則兩代的大小都會增加。 每一個都與其各自對總垃圾收集時間的貢獻成比例地增加。 例如,如果新生代的垃圾收集時間是總收集時間的 25%,如果新生代的完整增量為 20%,那麼新生代將增加 5%。
預設堆大小
除非在命令行中指定初始和最大堆大小,否則它們是根據機器上的記憶體量計算的。
客戶端 JVM 預設初始和最大堆大小
預設最大堆大小是物理記憶體的一半,最大物理記憶體大小為 192 兆位元組 (MB),否則為物理記憶體的四分之一,最大物理記憶體大小為 1 千兆位元組 (GB)。
例如,如果您的電腦有 128 MB 的物理記憶體,那麼最大堆大小為 64 MB,大於或等於 1 GB 的物理記憶體導致最大堆大小為 256 MB。
JVM 實際上並不使用最大堆大小,除非您的程式創建了足夠多的對象來需要它。 在 JVM 初始化期間分配的數量要少得多,稱為 初始堆大小 。 此數量至少為 8 MB,否則為物理記憶體的 1/64,直到 1 GB 的物理記憶體大小。
分配給新生代的最大空間量是總堆大小的三分之一。
伺服器 JVM 預設初始和最大堆大小
預設的初始和最大堆大小在伺服器 JVM 上的工作方式與在客戶端 JVM 上的工作方式類似,只是預設值可以更高。 在 32 位 JVM 上,如果有 4 GB 或更多的物理記憶體,預設的最大堆大小可以達到 1 GB。 在 64 位 JVM 上,如果有 128 GB 或更多的物理記憶體,預設的最大堆大小可以達到 32 GB。 您始終可以通過直接指定這些值來設置更高或更低的初始堆和最大堆; 請參閱下一節。
指定初始和最大堆大小
您可以使用標誌“-Xms”(初始堆大小)和“-Xmx”(最大堆大小)指定初始和最大堆大小。 如果您知道您的應用程式需要多少堆才能正常運行,您可以將 -Xms 和 -Xmx 設置為相同的值。 如果不是,JVM 將首先使用初始堆大小,然後增加 Java 堆,直到它在堆使用和性能之間找到*衡。
其他參數和選項會影響這些預設值。 要驗證您的預設值,請使用“-XX:+PrintFlagsFinal”選項併在輸出中查找“MaxHeapSize”。 例如,在 Linux 或 Solaris 上,您可以運行以下命令:
java -XX:+PrintFlagsFinal <GC options> -version | grep MaxHeapSize
過多的 GC 時間和 OutOfMemoryError
如果在垃圾收集 (GC) 上花費了太多時間,並行收集器會拋出一個 OutOfMemoryError:如果超過 98% 的總時間花在了垃圾收集上並且只有不到 2% 的堆被回收,那麼一個 OutOfMemoryError 被拋出。 此功能旨在防止應用程式長時間運行而由於堆太小而進展甚微或根本沒有進展。 如有必要,可以通過向命令行添加選項-XX:-UseGCOverheadLimit 來禁用此功能。
測量
並行收集器的詳細垃圾收集器輸出與串列收集器的輸出基本相同。
7 大多數併發收集器
Java Hotspot VM在JDK 8中有兩個主要是併發的收集器:
併發標記掃描(CMS)收集器:此收集器適用於那些喜歡較短垃圾收集暫停時間並且能夠與垃圾收集共用處理器資源的應用程式。
垃圾第一垃圾收集器:這個伺服器風格的收集器適用於具有大記憶體的多處理器機器。它在實現高吞吐量的同時,高概率地滿足垃圾收集暫停時間目標。
併發開銷
大多數併發收集器將處理器資源(否則應用程式將可用)用於更短的主要收集暫停時間。最明顯的開銷是在收集的併發部分使用一個或多個處理器。在N個處理器的系統上,收集的併發部分將使用可用處理器的K/N,其中1<=K<=上限{N/4}。(請註意,K的精確選擇和邊界可能會發生變化。)除了在併發階段使用處理器之外,還需要額外的開銷來實現併發。因此,雖然併發收集器的垃圾收集暫停時間通常要短得多,但應用程式吞吐量也往往略低於其他收集器。
在具有多個處理核心的機器上,在收集的併發部分,處理器可用於應用程式線程,因此併發垃圾收集器線程不會“暫停”應用程式。這通常會導致更短的暫停,但應用程式可用的處理器資源也會更少,而且應該會出現一些放緩,尤其是在應用程式最大限度地使用所有處理核心的情況下。隨著N的增加,由於併發垃圾收集導致的處理器資源減少會變小,併發收集帶來的好處也會增加。併發標記掃描(CMS)收集器中的併發模式故障一節討論了這種擴展的潛在限制。
因為在併發階段至少有一個處理器用於垃圾收集,所以併發收集器通常不會在單處理器(單核)機器上提供任何好處。然而,CMS(而不是G1)有一個單獨的模式,可以在只有一個或兩個處理器的系統上實現低暫停;有關詳細信息,請參閱 併發標記掃描(CMS)收集器 中的 增量模式 。此功能在Java SE 8中已被棄用,可能會在以後的主要版本中刪除。
其他參考文獻
垃圾優先垃圾回收器:
http://www.oracle.com/technetwork/java/javase/tech/g1-intro-jsp-135488.html
垃圾優先垃圾回收器調優:
http://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
8 併發標記掃描(CMS)收集器
Concurrent Mark Sweep(CMS)收集器是為那些喜歡較短垃圾收集暫停時間的應用程式設計的,並且能夠在應用程式運行時與垃圾收集器共用處理器資源。通常,具有相對較大的長期數據集(大量長期生成)併在具有兩個或多個處理器的機器上運行的應用程式往往會從使用此收集器中受益。但是,對於任何暫停時間要求較低的應用程式,都應該考慮使用此收集器。CMS收集器是通過命令行選項-XX:+UseConcMarkSweepGC啟用的。
與其他可用的收集器類似,CMS收集器是一代式的;因此,既發生了小收集,也發生了大收集。CMS收集器通過使用單獨的垃圾收集器線程在執行應用程式線程的同時跟蹤可訪問對象,試圖減少由於主要收集而導致的暫停時間。在每個主要的收集周期中,CMS收集器在收集開始時暫停所有應用程式線程一小段時間,併在收集中間再次暫停。第二次停頓往往是兩次停頓中較長的一次。在兩次暫停期間都使用多個線程來完成收集工作。收集的其餘部分(包括對活動對象


