
一.概述 分散式系統存在網路,時鐘,以及許多不可預測的故障。分散式事務,一致性與共識問題,迄今為止仍沒有得到很好的解決方案。要想完美地解決分散式系統中的問題不太可能,但是實踐中應對特定問題仍有許多可靠的解決方案。本文不會談及諸如BASE, CAP, ACID 等空泛的理論,只基於實踐中遇到的問題提出 ...
一.概述
分散式系統存在網路,時鐘,以及許多不可預測的故障。分散式事務,一致性與共識問題,迄今為止仍沒有得到很好的解決方案。要想完美地解決分散式系統中的問題不太可能,但是實踐中應對特定問題仍有許多可靠的解決方案。本文不會談及諸如BASE, CAP, ACID 等空泛的理論,只基於實踐中遇到的問題提出可行的解決方案。
二.常見問題
1.讀自己的寫
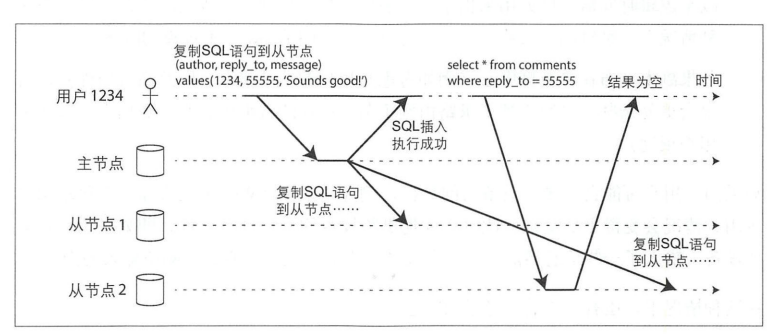
現象: 用戶在發佈頁發佈了帖子,然後訪問自己的主頁查看帖子列表,並沒有馬上看到自己剛剛發佈的帖子,等待1~2s後才看到
分析:後端db採取主從結構,複製任務在負載較高的情況下會有延遲。用戶讀取帖子列表查詢的是從節點,所以無法及時看到剛剛發佈的帖子。一般情況下延遲1~2s是可以接受的,但是為了更好的體驗,可以做一些改進。
解決方案:
- 如果用戶讀取的是自己的主頁,就訪問主節點。如果訪問是他人的主頁,就訪問從節點。只需要在db層路由即可。
- 客戶端還可以記住最近更新時的時間戳,並附帶在讀請求中,據此信息,系統可以確保對該用戶提供讀服務時都應該至少包含了該時間戳的更新。如果不夠新,要麼交由另一個副本來處理,要麼等待直到副本接收到了最近的更新
2.單調讀
現象:用戶查看某個帖子下麵的評論,一會兒看到5條評論,一會兒看到6條評論。
分析:後端db採取主從結構,複製任務在負載較高的情況下會有延遲。用戶讀取評論列表查詢的是從節點,但是兩次讀的是不同的從節點,當某個從節點具有明顯延遲就會出現數據反覆的現象。

解決方案:
- 確保同一個用戶每次都是讀取同一個副本,可以在db層進行路由。這是一種典型的sticky 請求路由。
replica = hash(user_id) % number_of_replica
3.負載傾斜與熱點問題
現象:某個分區的數據明顯比其他分區多,並且訪問頻率高,負載壓力大。
分析:在某些特殊的業務場景下,比如官方或者名人賬號有百萬粉絲,當這些賬號發佈消息事件時,人們會對該消息進行評論,如果評論數據存儲使用事件id進行hash,就會造成某個分區的負載產生傾斜。
解決:
- 在關鍵詞,比如消息事件id,的開頭或者結尾添加一個隨機數。只需一個兩位數的十進位隨機數就可以將關鍵字的寫做操作分佈到100個不同的關鍵字上,從而分片到不同的分區上。這些特殊邏輯只應用在一些特殊賬號上。
4.fencing令牌
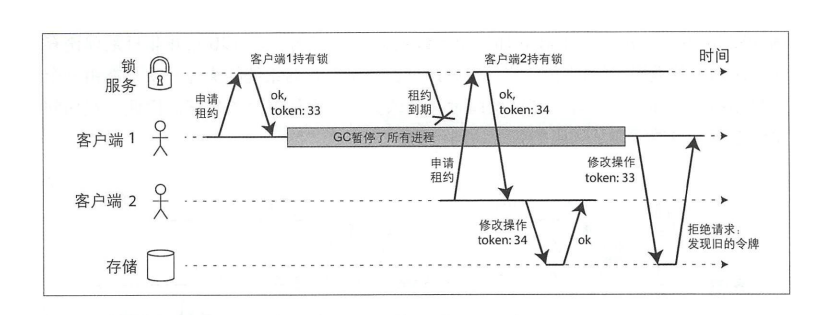
現象:在採用分散式鎖的情況下,資料庫中的事務重覆執行。
分析:在分散式鎖環境中,客戶端A執行事務超時,分散式鎖被釋放。客戶端B執行事務插入數據。客戶端A恢復後繼續執行事務,重覆插入數據。

解決方案:
- 這不是分散式事務的範疇。可以採用fencing令牌來解決。我們假設每次鎖服務授予鎖或租約時,同時還會返回一個fencing令牌,該令牌每授予一次就會遞增。然後,要求客戶端每次向存儲系統發生寫請求時,都必須包含所持有的fencing令牌。當使用zookeeper 作為鎖服務時,可以用事務標識zxid,或節點版本cversion來充當fencing令牌,這兩個都可以滿足單調遞增的要求。
5.Lamport時間戳
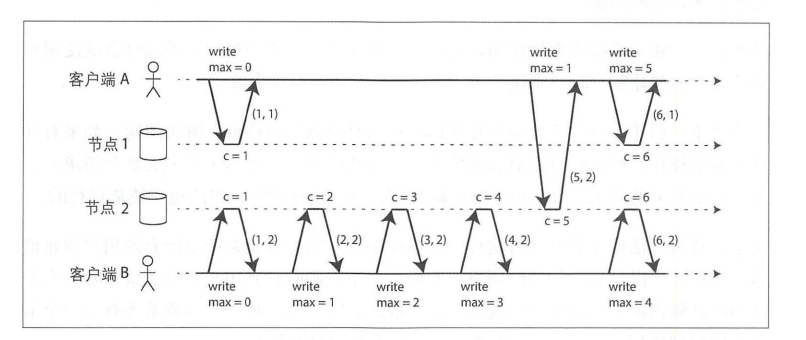
現象:客戶端從兩個分區獲取兩條不同的數據,比如事件a, b;a的序號小於b,但事實上b比a先發生。
分析:常見的有以下幾種非因果序列發生器,產生的序列號與因果關係並不嚴格一致。
- 每個節點單獨產生自己的一組序列號。
- 把牆上時間戳信息(物理時鐘)附加在每個操作上。
- 預先分配好序列號的區間範圍,比如節點A負責區間1~1000的序列號,節點B負責1001~2000。
解決方案:
- 使用Lamport時間戳。Lamport時間戳是一個kv對(計數器,節點ID)。核心流程:每個節點以及每個客戶端都跟蹤迄今為止所見到的最大計數器,併在每個請求中附帶該最大計數器值。當節點收到請求(或者回覆)時,如果發現請求內嵌的最大計數器大於節點自身的計數器,則它立即把自己的計數器修改為該最大值。
6.端到端的重覆消除問題
現象:消息重覆是非常普遍的,比如
- 生產者發送消息到消費者,消費者消費成功後宕機,但是卻沒有更新消費位置,消費者重啟後就會重新消費。
- 常見的rpc調用,調用方因為網路問題沒有收到被調用方的響應,選擇重試。
- 2PC 分散式事務中,因為網路問題,也可能出現重覆事務的問題。
- 用戶在頁面重覆提交POST請求。
分析:端到端的重覆問題是非常普遍的,在TCP 網路中也需要處理重覆數據包的問題。有以下兩種解決辦法:
- 最有效的辦法之一是使操作滿足冪等性,即無論執行一次還是多次,確保具有相同的結果。比如以下語句無論執行多少次效果都是一致的。
update table set v = v2 where v = v1
- 可以為操作生成一個唯一的標識符如(UUID),服務端對此UUID 進行去重校驗。

- 在典型的電商下單介面中採用了以上兩種方法的結合:使用唯一標識符來進行去重,如果寫入異常返回之前的訂單。
create table order(
# ...
dedup_key varchar(60) not null comment 'key to pretend order duplication',
client_id,
# ...
unique uniq_dedup_key(dedup_key, client_id)
);
@Transactional
Order createOrder(Integer userId, String prodCode, Decimal amount, String dedupKey) {
try {
String orderId = createOrder(userId, prodCode, amount, deupKey); // insert a new order
Order order = getOrderById(orderId); // read order from db
order.setDuplicated(false); // 標記是否有重覆下單
return order;
} catch(UniqueKeyViolationException e) {
// if duplicated order has existed, return previous order
Order order = getOrderByDedupKey(dedupKey, clientId);
order.setDuplicated(true);
return order;
} catch (Exception e) {
// hanlde other errors and rollback transaction ...
}
}7.唯一性約束
現象:在集群高併發的環境下,用戶A創建用戶marquezzzz,用戶B同時創建了用戶marquezzzz,兩者的用戶名相同,這違背了唯一性約束。
分析:創建用戶名的邏輯是,先去db中查詢是否有對應的用戶名(步驟1),如果沒有就創建,如果存在就更新用戶的其他信息(步驟2)。用戶A執行了步驟1, 用戶B執行了步驟1和2,然後用戶A執行了步驟2,這樣生成了兩個同名的用戶。
解決方案:
- 串列化請求,將創建用戶的請求串列化,比如發送到隊列中,這樣可以確保全局唯一性。
- 在db層進行唯一性約束,比如使用唯一索引,考慮到龐大的數據量,性能會下降。如果做了分表,唯一索引的方法也不太可行。
- 使用分散式鎖,比如redis, zookeeper,redis偽代碼如下:
boolean r = redisClient.setnx("userName", currentThread, 10s); // 使用 setnx 原子命令
if (!r) {
return false;
}
// 步驟1 查找db確保沒有重名
// 步驟2 插入用戶
redisClient.delete("userName");8.時鐘問題
現象:在許多app中,客戶端會上報事件,但是事件的發生時間不准確
分析:app客戶端時鐘可能不准確,或者用戶手動調整過系統時鐘。
解決方案:
為了調整不正確的設備時鐘,一種方法是記錄三個時間戳:
- 根據設備的時鐘,記錄事件發生的時間, device_event_time
- 根據設備的時鐘,記錄將事件發生到伺服器的時間, device_send_time
- 根據伺服器時鐘,記錄伺服器收到事件的時間, server_receive_time
事件真實發生時間 = device_event_time + (server_receive_time - device_send_time)
三.參考
《數據密集型應用系統設計》
https://cloud.tencent.com/developer/article/1121727

