
回顧大數據的發展歷程,一句話概括就是海量數據的高效處理。在當今快節奏、不斷變化的市場環境下,優秀的開發效率已經成為企業數字化轉型的必備條件。 數棧離線開發BatchWorks 是一款專註離線數據ELT開發的產品,採用先進的大數據生態底層技術,具備高性能且功能豐富的大數據處理能力,對大數據離線計算、數 ...
回顧大數據的發展歷程,一句話概括就是海量數據的高效處理。在當今快節奏、不斷變化的市場環境下,優秀的開發效率已經成為企業數字化轉型的必備條件。
數棧離線開發BatchWorks 是一款專註離線數據ELT開發的產品,採用先進的大數據生態底層技術,具備高性能且功能豐富的大數據處理能力,對大數據離線計算、數據倉庫建設提供有效支撐,是企業建設數據中台、數據倉庫,加速數字化轉型的基礎設施。
BatchWorks 經過6年多的打磨已經服務於包括金融、教育、政企、零售等多個行業在內的300+客戶,在開發效率提升方面發揮了巨大的價值。本文將從多個項目實施過程中遇到的6個典型場景來介紹一下離線開發BatchWorks 在開發效率提升上的一些解決方案,與大家共同探討。
場景一:大批量數據快速遷移
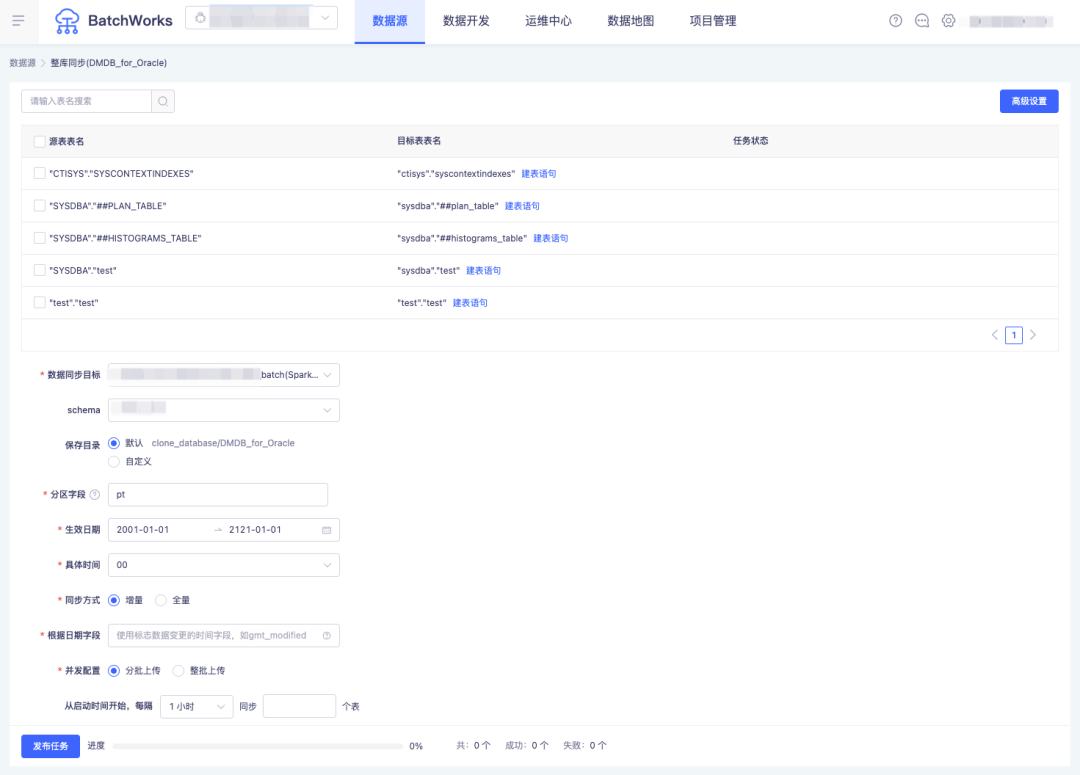
問:客戶數倉計劃從 Oracle 遷移到 Hadoop,初始化需要完成幾萬張表的數據同步,如何快速進行大批量 hive 表的創建並做數據抽取?
答:BatchWorks 支持連接數據源進行關係型資料庫到包括 Hive 在內的多目標資料庫之間的整庫同步,可一次性完成大批量表的自動創建和同步任務的生成,支持按日期增量和全量兩種數據同步方式。考慮到同一時間點啟動大量數據同步任務會造成資料庫壓力過大,還可支持任務併發數的配置。
場景二:SQL 邏輯的復用和批量管理
問:一條業務線上有20+產品,每個產品的數據分析由一個 SQL 任務完成,所有產品的任務邏輯完全一致且需要保持變更同步,而實際業務在快速變化,數據開發每次調整業務邏輯都需要每個 SQL 任務分別手動變更,經常出現調整錯漏的情況,如何解決?
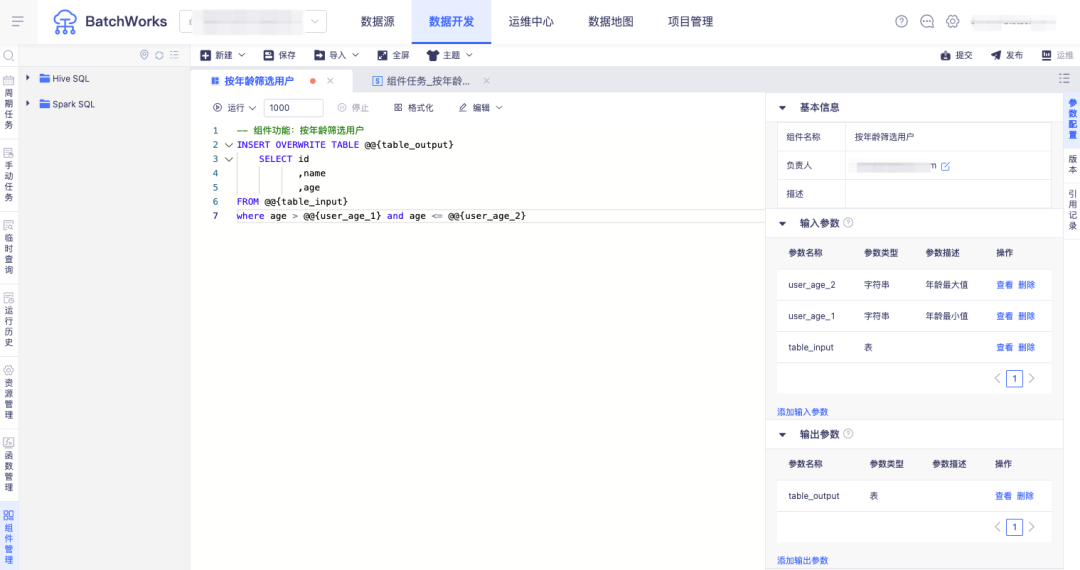
答:增加“組件”功能,用戶可把在大量任務中通用的業務 SQL 邏輯抽象出來作為組件進行維護,不同的產品只需引用組件並配置輸入輸出表和字元參數,即可快速完成任務配置。當業務變更時只要調整組件的邏輯就能實現所有引用此組件任務的同步變更。
一個簡單例子:業務方需要對不同產品的用戶群體做年齡分層,可創建組件做年齡篩選,配置以下輸入輸出參數:
• 輸入參數:數據來源表
• 輸出參數:年齡層中的最大最小值(字元串)、數據輸出表
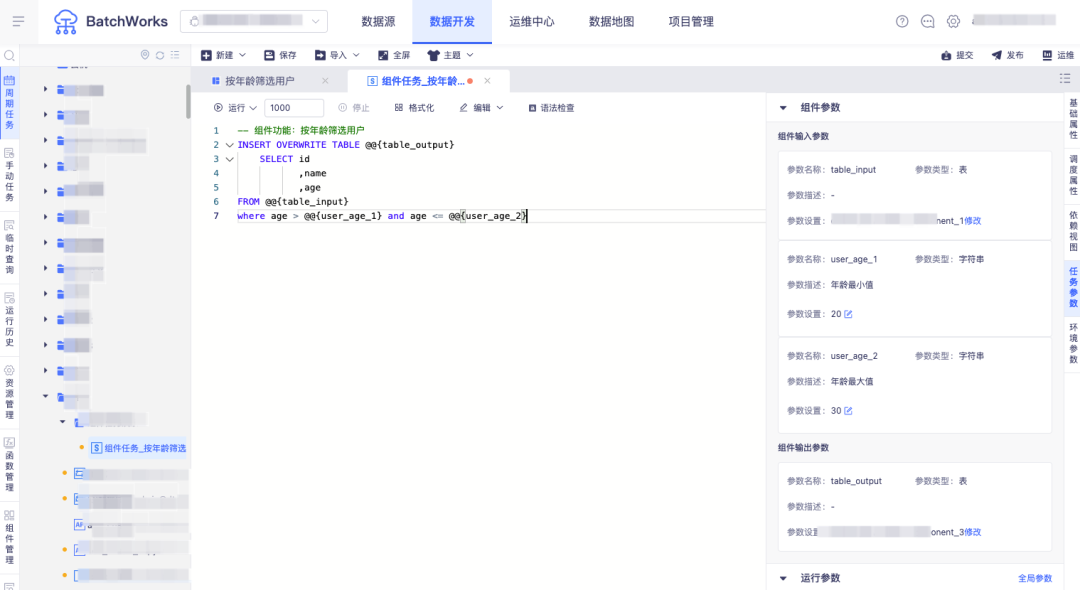
實現從產品1中篩選出年齡為20-30的用戶數據,在創建任務時選擇上述組件配置年齡輸入參數和數據來源表,並指定寫入的結果表:
場景三:計算結果跨任務復用
問:任務存在上下游依賴時,下游任務可能需要直接使用上游部分任務的計算結果,同時用戶不希望建太多臨時表,或產生一些額外的重覆計算,如何解決?
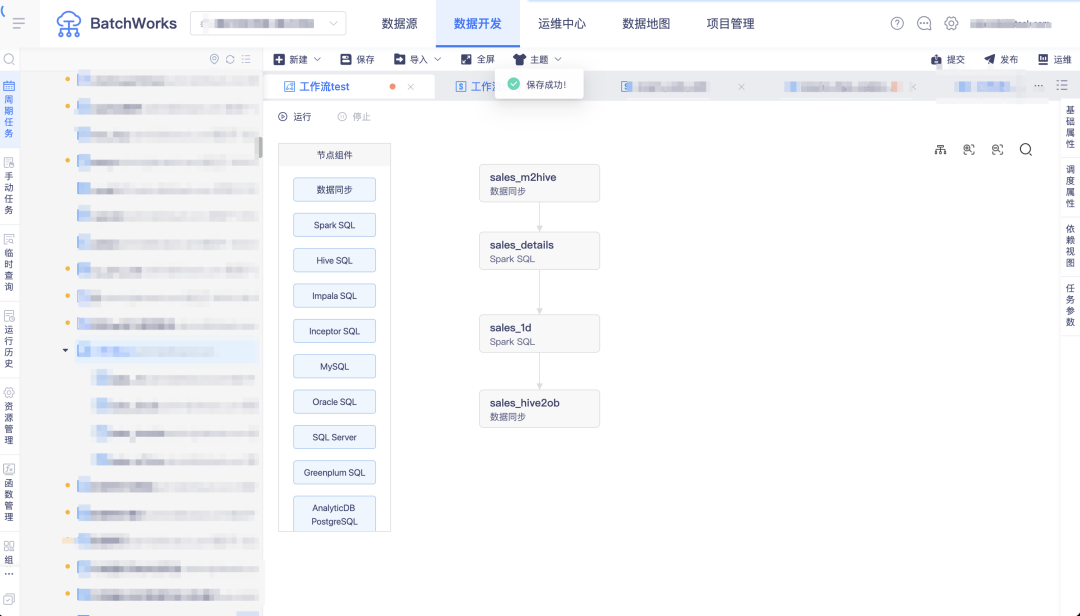
答:BatchWorks 支持了任務上下游參數傳遞功能,上游任務的計算結果可進行周期性存儲,直接被下游計算引用。
一個簡單例子:從業務庫完成銷售明細表數據採集清洗,按天彙總後將銷售金額最高的門店數據輸出 sales_1d 任務,從 sales_details 中通過輸入參數獲取日期數據,然後將當天最高銷售數據對應的門店通過輸出參數輸出傳遞至下游的同步任務,同步任務篩選此門店數據同步至 oceanbase。
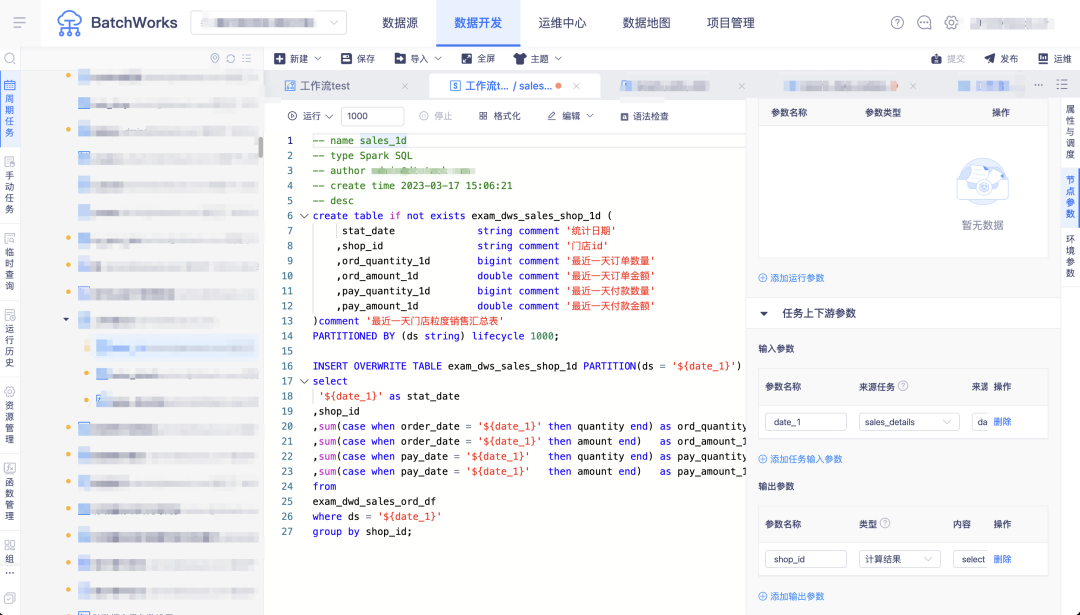
場景四:任務依賴自動解析
問:當任務較多且依賴關係複雜時,依賴關係的配置會占用一定的工作量,尤其在對任務做了修改後,依賴關係可能會有更新不及時/漏更新的情況,發現問題時往往已經到了下游環節,如何解決?
答:BatchWorks 支持了上游任務依賴自動解析推薦/自動依賴功能,選擇此功能進行依賴任務配置時,平臺將對當前任務進行 SQL 解析,得到來源表和結果表,並尋找來源表的產出任務,用戶可從這些推薦任務里選擇全部或部分任務添加到上游依賴,也可直接選擇自動依賴,當 SQL 調整時自動進行上游依賴的更新。
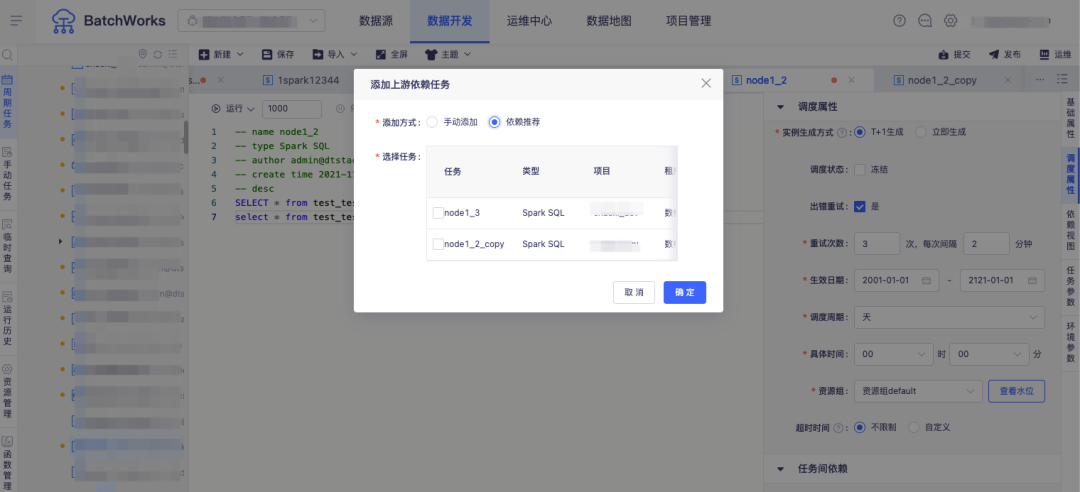
場景五:任務異常快速排查
問:離線實例的運行流程涉及實例上游依賴檢查、到達計劃時間檢查、資源檢查、質量校驗等多個環節,運行過程出現異常時僅通過日誌難以直觀地進行問題溯源,問題處理不及時直接影響下游業務,如何解決?
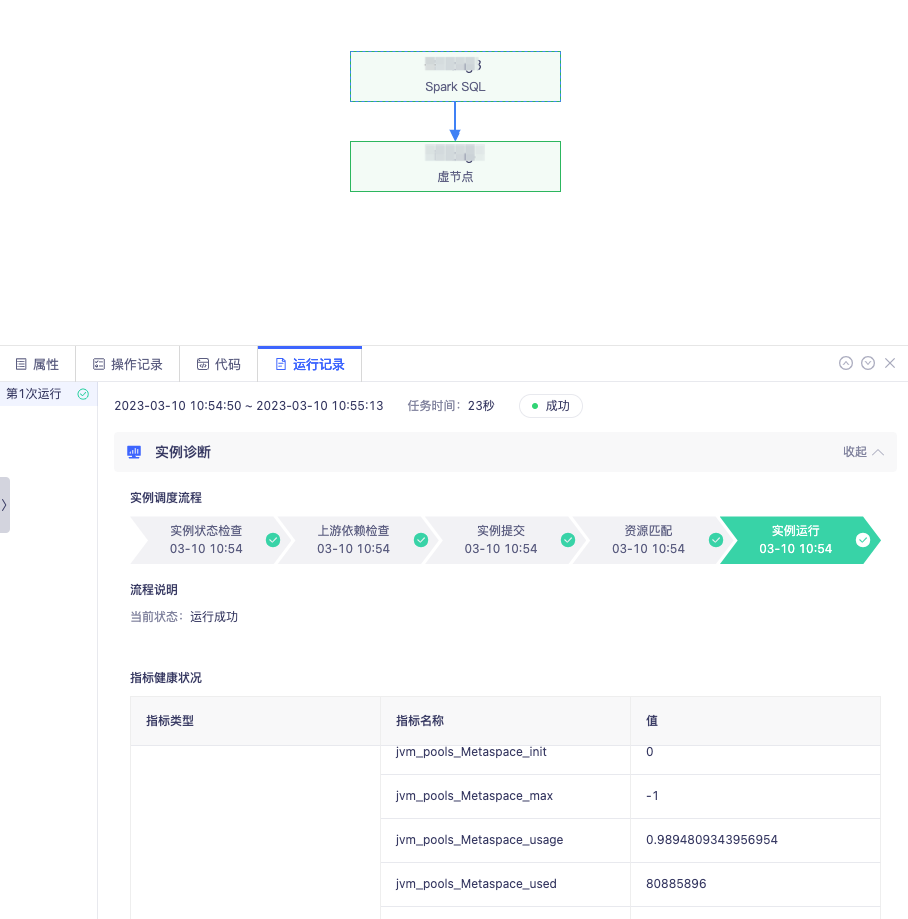
答:BatchWorks 支持實例診斷功能對實例的運行過程進行分析,將實例調度流程及每個流程當前的狀態、節點時間全部展示,用戶可直觀地看到當前實例的運行階段和異常原因。
比如在進行上游依賴異常檢查時,BatchWorks 將構建以當前實例為末位節點的異常依賴樹,尋找直接導致其未運行的根源任務組,快速直達阻塞點。此外針對 SparkSQL,可監控其指標健康狀況並給出調參建議,針對 HiveSQL 可觀測運行過程中資源使用變化情況,從而可進一步進行任務調優。

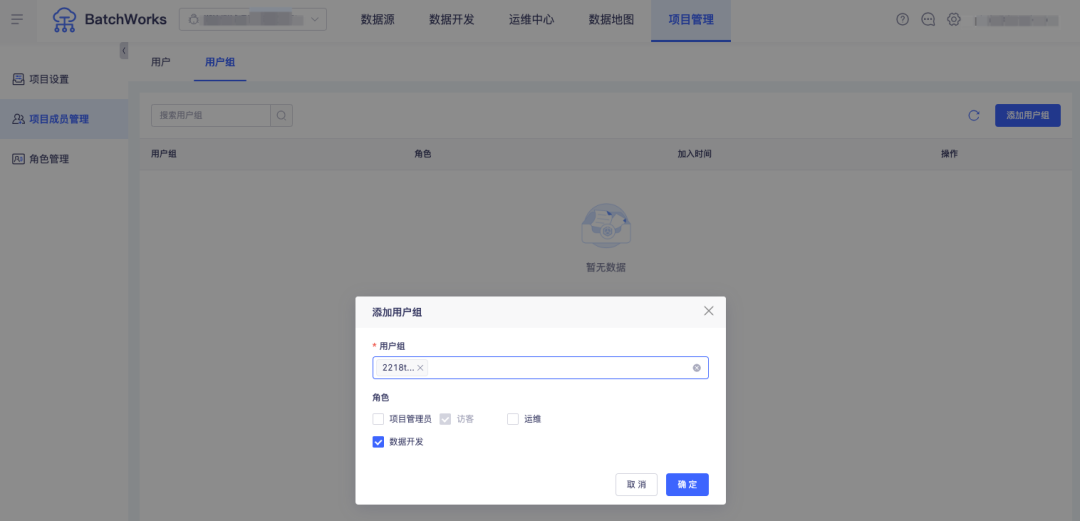
場景六:以用戶組為單位的用戶管理
問:某公司的數據開發團隊不定期會有一些人員調整,因業務量大、開發項目比較多,人員調整後開發平臺上的維護十分繁瑣。例如有新員工入職,需要將其添加到相關的多個開發項目中並賦予不同的角色,任務告警值班時需要添加進對應的告警規則中等等,增加管理員的用戶管理成本且容易缺漏,如何解決?
答:BatchWorks 的用戶中心支持以用戶組為單位的用戶管理,每個用戶可被添加進一個或多個用戶組。項目添加用戶、告警圈選用戶時均可以用戶組的方式進行配置。後續增刪用戶時僅需在用戶中心的用戶組內進行操作,即可完成人員->項目/角色等的快速調整。
《數據治理行業實踐白皮書》下載地址:https://fs80.cn/380a4b
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack

