
一、貝葉斯定理 貝葉斯定理是關於隨機事件A和B的條件概率,生活中,我們可能很容易知道P(A|B),但是我需要求解P(B|A),學習了貝葉斯定理,就可以解決這類問題,計算公式如下: P(A)是A的先驗概率 P(B)是B的先驗概率 P(A|B)是A的後驗概率(已經知道B發生過了) P(B|A)是B的後驗 ...
一、貝葉斯定理
貝葉斯定理是關於隨機事件A和B的條件概率,生活中,我們可能很容易知道P(A|B),但是我需要求解P(B|A),學習了貝葉斯定理,就可以解決這類問題,計算公式如下:
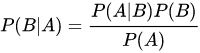
- P(A)是A的先驗概率
- P(B)是B的先驗概率
- P(A|B)是A的後驗概率(已經知道B發生過了)
- P(B|A)是B的後驗概率(已經知道A發生過了)
二、朴素貝葉斯分類
朴素貝葉斯的思想是,對於給出的待分類項,求解在此項出現的條件下,各個類別出現的概率,哪個最大,那麼就是那個分類。
是一個待分類的數據,有m個特征
是類別,計算每個類別出現的先驗概率
- 在各個類別下,每個特征屬性的條件概率計算
- 計算每個分類器的概率
- 概率最大的分類器就是樣本
的分類
三、java樣例代碼開發步驟
首先,需要在pom.xml文件中添加以下依賴項:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>3.2.0</version> </dependency>
然後,在Java代碼中,可以執行以下步驟來實現朴素貝葉斯演算法:
1、創建一個SparkSession對象,如下所示:
import org.apache.spark.sql.SparkSession; SparkSession spark = SparkSession.builder() .appName("NaiveBayesExample") .master("local[*]") .getOrCreate();
2、載入訓練數據和測試數據:
import org.apache.spark.ml.feature.LabeledPoint; import org.apache.spark.ml.linalg.Vectors; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.types.DataTypes; import static org.apache.spark.sql.functions.*; //讀取訓練數據 Dataset<Row> trainingData = spark.read() .option("header", true) .option("inferSchema", true) .csv("path/to/training_data.csv"); //將訓練數據轉換為LabeledPoint格式 Dataset<LabeledPoint> trainingLP = trainingData .select(col("label"), col("features")) .map(row -> new LabeledPoint( row.getDouble(0), Vectors.dense((double[])row.get(1))), Encoders.bean(LabeledPoint.class)); //讀取測試數據 Dataset<Row> testData = spark.read() .option("header", true) .option("inferSchema", true) .csv("path/to/test_data.csv"); //將測試數據轉換為LabeledPoint格式 Dataset<LabeledPoint> testLP = testData .select(col("label"), col("features")) .map(row -> new LabeledPoint( row.getDouble(0), Vectors.dense((double[])row.get(1))), Encoders.bean(LabeledPoint.class));
請確保訓練數據和測試數據均包含"label"和"features"兩列,其中"label"是標簽列,"features"是特征列。
import org.apache.spark.ml.classification.NaiveBayes; import org.apache.spark.ml.classification.NaiveBayesModel; NaiveBayes nb = new NaiveBayes() .setSmoothing(1.0) //設置平滑參數 .setModelType("multinomial"); //設置模型類型 NaiveBayesModel model = nb.fit(trainingLP); //擬合模型
在這裡,我們創建了一個NaiveBayes對象,並設置了平滑參數和模型類型。然後,我們使用fit()方法將模型擬合到訓練數據上。
Dataset<Row> predictions = model.transform(testLP); //查看前10條預測結果 predictions.show(10);
在這裡,我們使用transform()方法對測試數據進行預測,並將結果存儲在一個DataFrame中。可以通過調用show()方法查看前10條預測結果。
5、關閉SparkSession:
spark.close();
以下是完整代碼的示例。請註意,需要替換數據文件的路徑以匹配您的實際文件路徑:
import org.apache.spark.ml.classification.NaiveBayes; import org.apache.spark.ml.classification.NaiveBayesModel; import org.apache.spark.ml.feature.LabeledPoint; import org.apache.spark.ml.linalg.Vectors; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.Encoders; import static org.apache.spark.sql.functions.*; public class NaiveBayesExample { public static void main(String[] args) { //創建SparkSession對象 SparkSession spark = SparkSession.builder() .appName("NaiveBayesExample") .master("local[*]") .getOrCreate(); try{ //讀取很抱歉,我剛纔的回答被意外截斷了。以下是完整的Java代碼示例: ```java import org.apache.spark.ml.classification.NaiveBayes; import org.apache.spark.ml.classification.NaiveBayesModel; import org.apache.spark.ml.feature.LabeledPoint; import org.apache.spark.ml.linalg.Vectors; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.Encoders; import static org.apache.spark.sql.functions.*; public class NaiveBayesExample { public static void main(String[] args) { //創建SparkSession對象 SparkSession spark = SparkSession.builder() .appName("NaiveBayesExample") .master("local[*]") .getOrCreate(); try{ //讀取訓練數據 Dataset<Row> trainingData = spark.read() .option("header", true) .option("inferSchema", true) .csv("path/to/training_data.csv"); //將訓練數據轉換為LabeledPoint格式 Dataset<LabeledPoint> trainingLP = trainingData .select(col("label"), col("features")) .map(row -> new LabeledPoint( row.getDouble(0), Vectors.dense((double[])row.get(1))), Encoders.bean(LabeledPoint.class)); //讀取測試數據 Dataset<Row> testData = spark.read() .option("header", true) .option("inferSchema", true) .csv("path/to/test_data.csv"); //將測試數據轉換為LabeledPoint格式 Dataset<LabeledPoint> testLP = testData .select(col("label"), col("features")) .map(row -> new LabeledPoint( row.getDouble(0), Vectors.dense((double[])row.get(1))), Encoders.bean(LabeledPoint.class)); //創建朴素貝葉斯分類器 NaiveBayes nb = new NaiveBayes() .setSmoothing(1.0) .setModelType("multinomial"); //擬合模型 NaiveBayesModel model = nb.fit(trainingLP); //進行預測 Dataset<Row> predictions = model.transform(testLP); //查看前10條預測結果 predictions.show(10); } finally { //關閉SparkSession spark.close(); } } }
請註意替換代碼中的數據文件路徑,以匹配實際路徑。另外,如果在集群上運行此代碼,則需要更改master地址以指向正確的集群地址。


