發現報錯:RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error想在linux上跑跑mmclassification中的resnet網路,但是報錯,查閱... ...
發現報錯:
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error
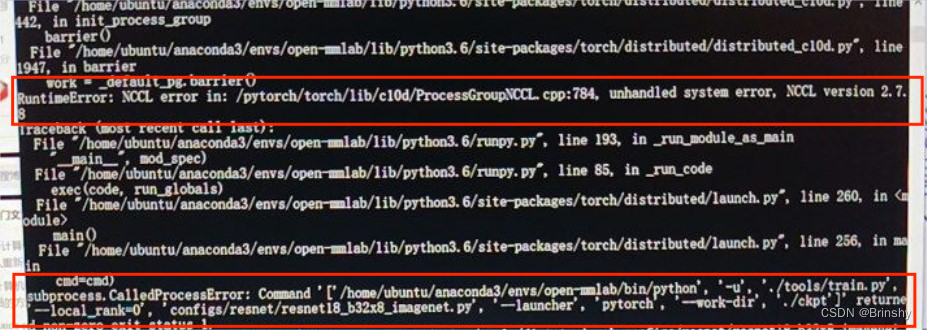
想在linux上跑跑mmclassification中的resnet網路,但是報錯,查閱資料後發現,第二個錯誤是由於第一個錯誤產生的。那麼現在就要解決第一個報錯。
第一個報錯查閱了一堆資料後,發現是GPU使用數量的原因,但我電腦只有一個GPU,修改了配置文件後,依舊這樣報錯。有的博主是由於文件中有中文字元,我仔細檢查後沒有發現。
最後才發現,之前用的訓練命令如下:
sh ./tools/dist_train.sh configs/resnet/resnet18_b32x8_imagenet.py 1 --work-dir ./ckpt對上述命令闡述如下:
dist_train.sh – 訓練 sh 腳本
configs/resnet/resnet18_b32x8_imagenet.py – 訓練依賴的配置
1 – GPU 個數
--work-dir ./ckp – 模型存放的路徑
但是這個命令只適用於多個GPU的時候,單個GPU得用以下命令:
python ./tools/dist_train.sh configs/resnet/resnet18_b32x8_imagenet.py --work-dir ./ckpt最終問題解決,開始煉丹。