
本篇文章適用於學習過其他面向對象語言(Java、Php),但沒有學過Go語言的初學者。文章主要從Go與Java功能上的對比來闡述Go語言的基礎語法、面向對象編程、併發與錯誤四個方面。 ...
一、MMDB簡介
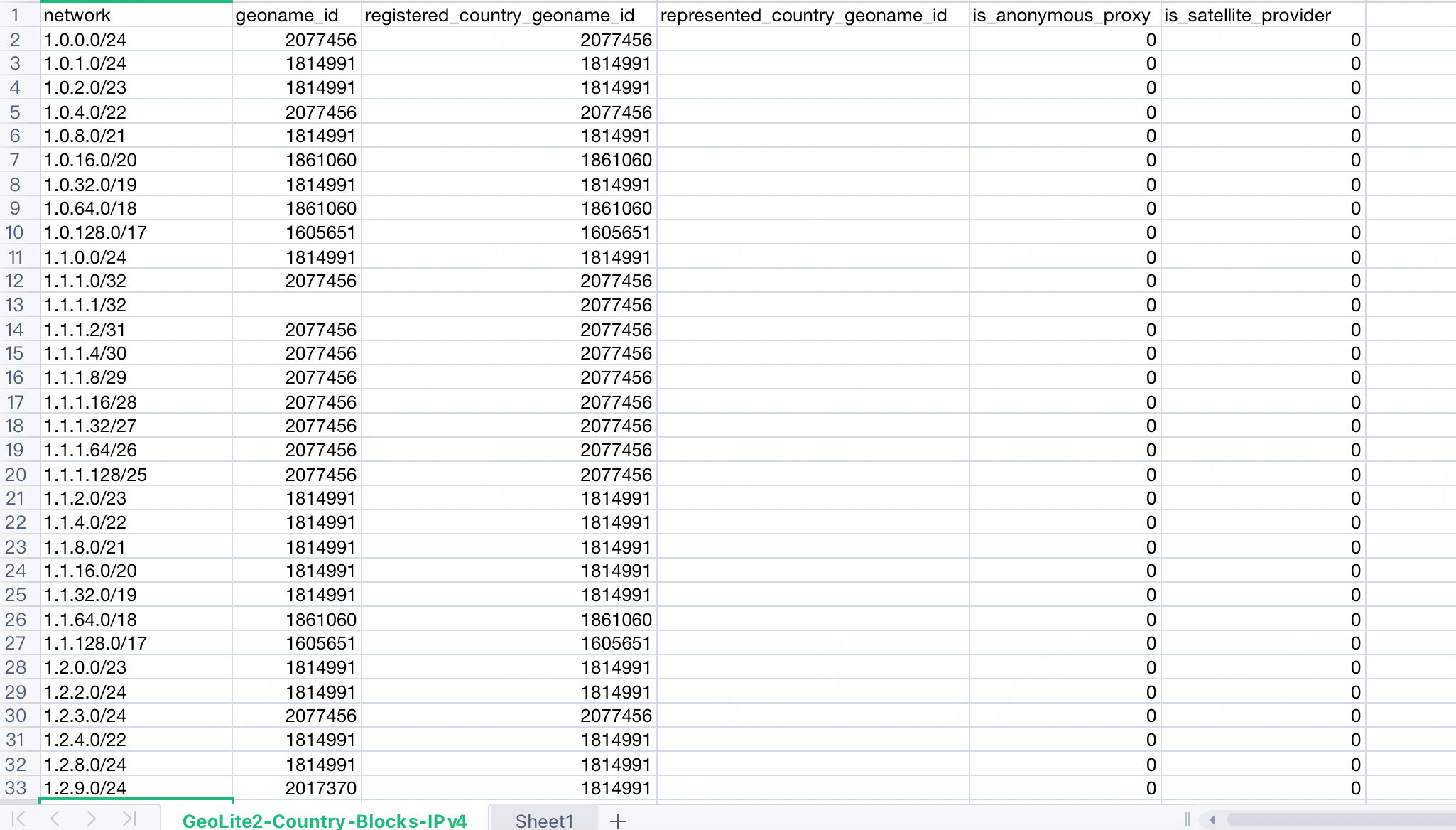
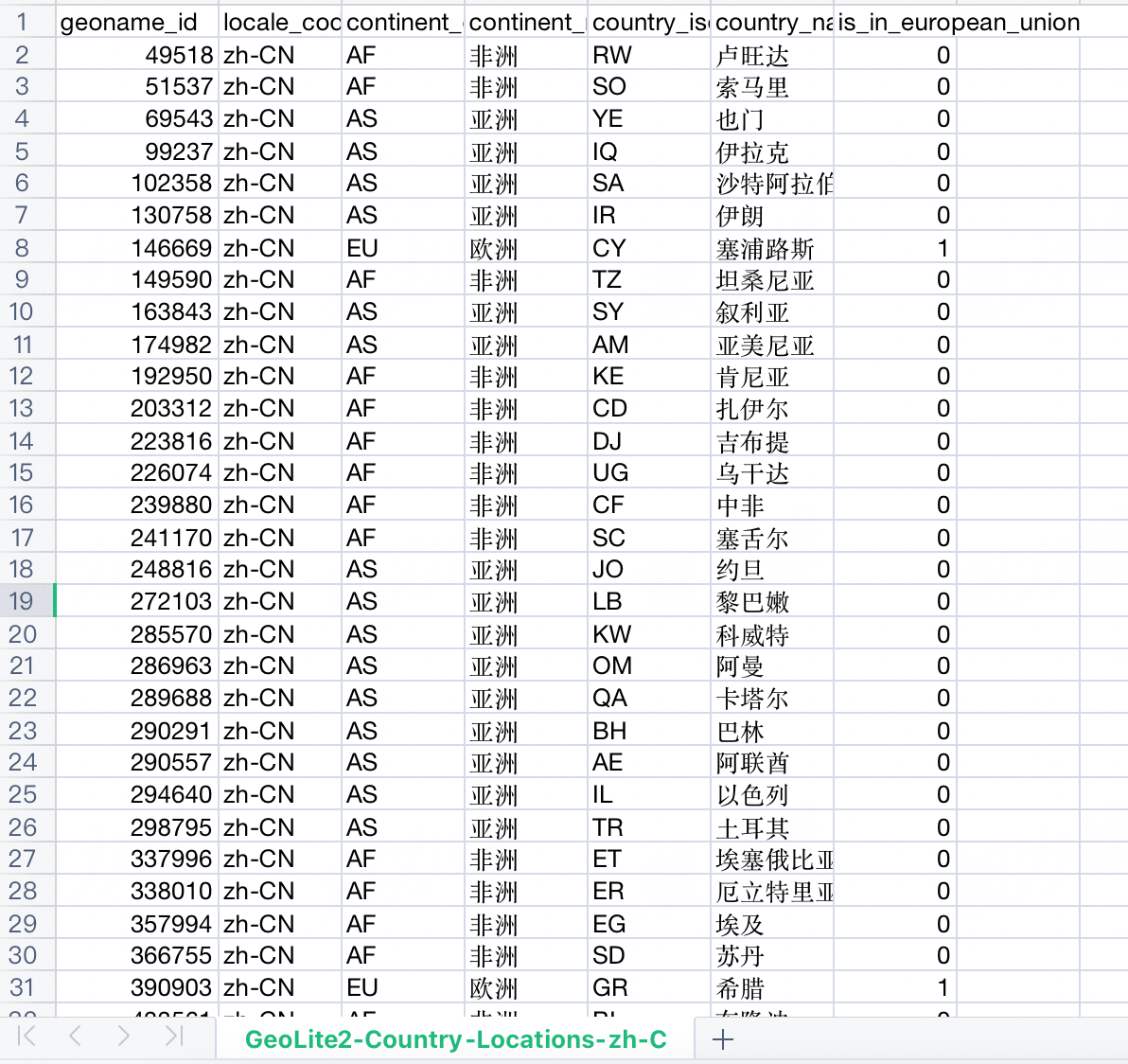
MMDB(MaxMind Database) 是MaxMind推出的一個數據存儲和檢索的資料庫格式,用於旗下針對IP檢索和存儲的Geo產品。 IP格式由二進位比特數組組成,很容易想到每個比特對應二叉樹一個節點,可以說二叉樹檢索特別適合於IP格式。 MMDB的構造過程正是把一顆數據位於葉子節點的二叉樹進行序列化。 序列化後是位元組數組,和其他檢索格式都是反序列化為結構化的記憶體形式不同,MMDB檢索時把整個mmdb文件載入為一個位元組數組即可。 檢索過程在位元組數組上操作,由於每個節點大小固定,通過簡單記憶體計算即可完成節點定位,不需要額外生成其他中間結構,可以說非常簡潔和高效。Maxmind的GeoIP產品用於檢索以下網段的geo信息,其中最左一列是網段,第二列是geoname_id。根據網段找到geoname_id,再根據geoname_id找到下圖的數據。
二、構造過程
構造過程是生成一顆二叉檢索樹的過程。 假設只存儲一個網段“110”的數據,則可以得到二叉樹為: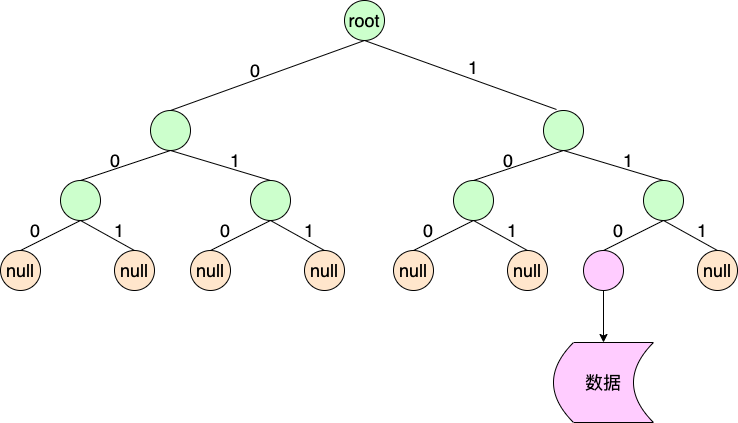
只有葉子節點會存儲指向數據的引用。
三、MMDB總體格式
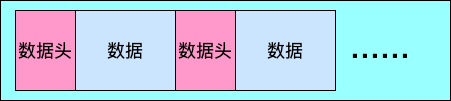
二叉樹經過序列化會得到一個位元組數組,數據格式如下圖: 
四、節點序列說明
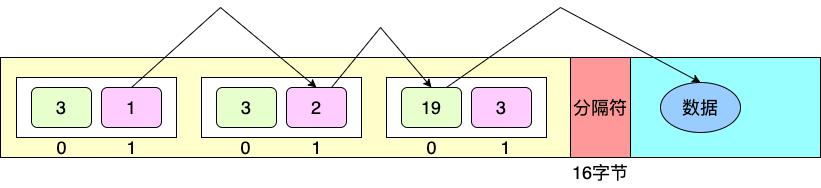
節點序列等於一個節點數組,每個節點由兩個記錄組成,分別對應二叉樹的左孩子和右孩子。
在IP檢索中,比特0對應第一個記錄,比特1對應第二個記錄。

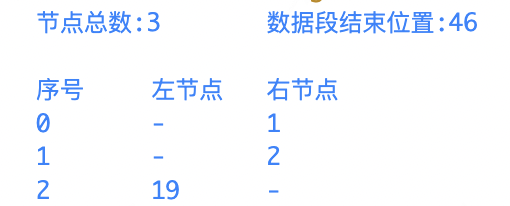
如上圖所示,包含3個節點,第一個節點的兩個記錄為3和1,第二個節點為3和2,第三個節點為19和3。
當記錄數等於節點數3時,表示沒找到數據。當記錄數大於節點數3時,則為數據節點的記錄值。
數據偏移量的計算公式:數據偏移量 = 記錄值 - 節點個數 - 16(分隔符的長度)。第三個節點記錄19表示數據偏移量為0,19-3(節點數)-16。
五、檢索演算法
在一個總節點數為3的mmdb資料庫上,網段“110”的檢索過程
六、數據段說明
七、實驗例子
1、構造一個網段為“192.2.10.0/3”,對應二進位網路“110”的節點,數據為{"iso":156,"country_name":"China"},生成的節點序列為:

可以看到“110”網段根據二叉樹檢索演算法得到數據段的偏移量19,則數據段偏移量為19-3(節點數)-16=0。
2、再加入一個網段為“64.2.10.0/3”,對應二進位網路“010”的節點,數據為{"iso":826,"country_name":"England"},生成的節點序列為:


八、總結
1、生成過程使用二叉樹。
2、存儲和檢索都是序列化位元組數組格式。
3、MMDB是記憶體資料庫 。
參考鏈接
MaxMind DB File Format Specification
Enriching MMDB files with your own data using go
Building your own MMDB database for fun and profit

