
一、概述 String類的一個最大特性是不可修改性,而導致其不可修改的原因是在String內部定義了一個常量數組,因此每次對字元串的操作實際上都會另外分配分配一個新的常量數組空間。 二、創建字元串對象的方式 2.1 四種方式 方式一:直接賦值(常用) // 直接賦值方式創建對象是在方法區的常量池 S ...
一、概述
String類的一個最大特性是不可修改性,而導致其不可修改的原因是在String內部定義了一個常量數組,因此每次對字元串的操作實際上都會另外分配分配一個新的常量數組空間。
二、創建字元串對象的方式
2.1 四種方式
方式一:直接賦值(常用)
// 直接賦值方式創建對象是在方法區的常量池
String str1 = "hello word";
方式二:通過構造方法產生對象
// 通過構造方法創建字元串對象是在堆記憶體
String str2 = new String("hello word");
方式三:通過字元數組產生對象
char[] data = new char[]{‘a’ , ‘b’ ,‘c’};
String str3 = new String(data);
方式四:通過String的靜態方法valueOf(任意數據類型) = >轉為字元串(常用)
String str4 = String.valueOf(10);
2.2 實例化方式的比較
1). 編寫代碼比較
public class TestString {
public static void main(String[] args) {
String str1 = "Lance";
String str2 = new String("Lance");
String str3 = str2; // 引用傳遞,str3直接指向st2的堆記憶體地址
String str4 = "Lance";
/**
* ==:
* 基本數據類型:比較的是基本數據類型的值是否相同
* 引用數據類型:比較的是引用數據類型的地址值是否相同
* 所以在這裡的話:String類對象==比較,比較的是地址,而不是內容
*/
System.out.println(str1 == str2); // false
System.out.println(str1 == str3); // false
System.out.println(str3 == str2); // true
System.out.println(str1 == str4); // true
}
}
2). 記憶體圖分析

可能這裡還是不夠明顯,構造方法實例化方式的記憶體圖:String str = new String("Hello");
首先:

當我們再一次的new一個String對象時:

3). 字元串常量池
在字元串中,如果採用直接賦值的方式(String str = "Lance")進行對象的實例化,則會將匿名對象“Lance”放入對象池,每當下一次對不同的對象進行直接賦值的時候會直接利用池中原有的匿名對象,
這樣,所有直接賦值的String對象,如果利用相同的“Lance”,則String對象==返回true;
比如:對象手工入池
public class TestString {
public static void main(String args[]) {
// 對匿名對象"hello"進行手工入池操作
String str = new String("Lance").intern();
String str1 = "Lance";
System.out.println(str == str1); // true
}
}
4). 總結:兩種實例化方式的區別
- 直接賦值
(String str = "hello"):只開闢一塊堆記憶體空間,並且會自動入池,不會產生垃圾。 - 構造方法
(String str= new String("hello");):會開闢兩塊堆記憶體空間,其中一塊堆記憶體會變成垃圾被系統回收,而且不能夠自動入池,需要通過intern()方法進行手工入池。
在開發的過程中不會採用構造方法進行字元串的實例化。
5). 避免空指向
首先瞭解:==和equals()比較字元串的區別
==在對字元串比較的時候,對比的是記憶體地址,而equals比較的是字元串內容,在開發的過程中,equals()通過接受參數,可以避免空指向。
舉例:
String str = null;
if (str.equals("hello")) {// 此時會出現空指向異常
// ...
}
if ("hello".equals(str)) {// 此時equals會處理null值,可以避免空指向異常
//...
}
6). String類對象一旦聲明則不可以改變;而改變的只是地址,原來的字元串還是存在的,並且產生垃圾

三、源碼分析
3.1 成員變數
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** String的屬性值 */
private final char value[];
/** The offset is the first index of the storage that is used. */
/** 數組被使用的開始位置 **/
private final int offset;
/** The count is the number of characters in the String. */
/** String中元素的個數 **/
private final int count;
/** Cache the hash code for the string */
/** String類型的hash值 **/
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
/**
* Class String is special cased within the Serialization Stream Protocol.
*
* A String instance is written into an ObjectOutputStream according to
* <a href="{@docRoot}/../platform/serialization/spec/output.html">
* Object Serialization Specification, Section 6.2, "Stream Elements"</a>
*/
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
}
final修飾類名:String作為不可重寫類它保證了線程安全。Serializable實現介面:String預設支持序列化。Comparable<String>實現介面:String支持與同類型對象的比較與排序。CharSequence實現介面:String支持字元標準介面,具備以下行為:length/charAt/subSequence/toString,在jdk8之後,CharSequence介面預設實現了chars()/codePoints()方法,返回String對象的輸入流。
成員變數可以知道String類的值是final類型的,不能被改變的,所以只要一個值改變就會生成一個新的String類型對象,存儲String數據也不一定從數組的第0個元素開始的,而是從offset所指的元素開始。
另外,JDK9與JDK8的類聲明比較也有差異,下麵是JDK9的類描述源碼部分:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
@Stable
private final byte[] value;
private final byte coder;
@Native static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true;
}
}
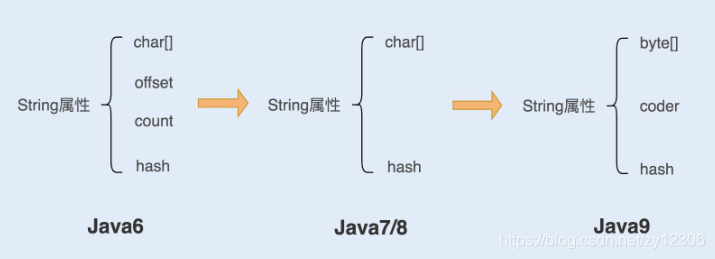
- 在
JDK8中String底層最終使用字元數組char[]來存儲字元值;但在JDK9之後,JDK維護者將其改為了byte[]數組作為底層存儲(究其原因是JDK開發人員調研了成千上萬的應用程式的heap dump信息,然後得出結論:大部分的String都是以Latin-1字元編碼來表示的,只需要一個位元組存儲就夠了,兩個位元組完全是浪費)。 - 在
JDK9之後,String類多了一個成員變數coder,它代表編碼的格式,目前String支持兩種編碼格式LATIN1和UTF16。LATIN1需要用一個位元組來存儲。而UTF16需要使用2個位元組或者4個位元組來存儲。
而實際上,JDK對String類的存儲優化由來已久了:
3.2 構造方法
| 構造方法 | 描述 |
|---|---|
| String() | 初始化一個新創建的String對象,使其表示一個空字元序列。 |
| String(byte[] bytes) | 通過使用平臺的預設字元集解碼指定的byte數組,構造一個新的String。 |
| String(byte[] bytes, Charset charset) | 通過使用指定的charset解碼指定的byte數組,構造一個新的String。 |
| String(byte[] bytes, int offset, int length) | 通過使用平臺的預設字元集解碼指定的byte子數組,構造一個新的String。 |
| String(byte[] bytes, int offset, int length, Charset charset) | 通過使用指定的charset解碼指定的byte子數組,構造一個新的String。 |
| String(byte[] bytes, int offset, int length, String charsetName) | 通過使用指定的字元集解碼指定的byte子數組,構造一個新的String。 |
| String(byte[] bytes, String charsetName) | 通過使用指定的charset解碼指定的byte數組,構造一個新的String。 |
| String(char[] value) | 分配一個新的String,使其表示字元數組參數中當前包含的字元序列。 |
| String(char[] value, int offset, int count) | 分配一個新的String,它包含取自字元數組參數一個子數組的字元。 |
| String(int[] codePoints, int offset, int count) | 分配一個新的String,它包含Unicode代碼點數組參數一個子數組的字元。 |
| String(String original) | 初始化一個新創建的String對象,使其表示一個與參數相同的字元序列;換句話說,新創建的字元串是該參數字元串的副本。 |
| String(StringBuffer buffer) | 分配一個新的字元串,它包含字元串緩衝區參數中當前包含的字元序列。 |
| String(StringBuilder builder) | 分配一個新的字元串,它包含字元串生成器參數中當前包含的字元序列。 |
3.3 常用方法

3.3.1 判斷功能
1). 常用方法
boolean equals(Object obj):比較字元串的內容是否相同
boolean equalsIgnoreCase(String str): 比較字元串的內容是否相同,忽略大小寫
boolean startsWith(String str): 判斷字元串對象是否以指定的str開頭
boolean endsWith(String str): 判斷字元串對象是否以指定的str結尾
2).代碼測試
public class TestString {
public static void main(String[] args) {
// 創建字元串對象
String s1 = "hello";
String s2 = "hello";
String s3 = "Hello";
// boolean equals(Object obj):比較字元串的內容是否相同
System.out.println(s1.equals(s2));
System.out.println(s1.equals(s3));
System.out.println("-----------");
// boolean equalsIgnoreCase(String str):比較字元串的內容是否相同,忽略大小寫
System.out.println(s1.equalsIgnoreCase(s2));
System.out.println(s1.equalsIgnoreCase(s3));
System.out.println("-----------");
// boolean startsWith(String str):判斷字元串對象是否以指定的str開頭
System.out.println(s1.startsWith("he"));
System.out.println(s1.startsWith("ll"));
}
}
結果:
true
false
-----------
true
true
-----------
true
false
3.3.2 獲取功能
1)常用方法
int length(): 獲取字元串的長度,其實也就是字元個數
char charAt(int index): 獲取指定索引處的字元
int indexOf(String str): 獲取str在字元串對象中第一次出現的索引
String substring(int start): 從start開始截取字元串
String substring(int start, int end): 從start開始,到end結束截取字元串。包括start,不包括end
2)代碼測試
public class TestString {
public static void main(String[] args) {
// 創建字元串對象
String s = "helloworld";
// int length():獲取字元串的長度,其實也就是字元個數
System.out.println(s.length());
System.out.println("--------");
// char charAt(int index):獲取指定索引處的字元
System.out.println(s.charAt(0));
System.out.println(s.charAt(1));
System.out.println("--------");
// int indexOf(String str):獲取str在字元串對象中第一次出現的索引
System.out.println(s.indexOf("l"));
System.out.println(s.indexOf("owo"));
System.out.println(s.indexOf("ak"));
System.out.println("--------");
// String substring(int start):從start開始截取字元串
System.out.println(s.substring(0));
System.out.println(s.substring(5));
System.out.println("--------");
// String substring(int start,int end):從start開始,到end結束截取字元串
System.out.println(s.substring(0, s.length()));
System.out.println(s.substring(3, 8));
}
}
結果:
10
--------
h
e
--------
2
4
-1
--------
helloworld
world
--------
helloworld
lowor
3.3.3 轉換功能
1)常用方法
char[] toCharArray():把字元串轉換為字元數組
String toLowerCase():把字元串轉換為小寫字元串
String toUpperCase():把字元串轉換為大寫字元串
2)核心代碼
public class TestString {
public static void main(String[] args) {
// 創建字元串對象
String s = "abcde";
// char[] toCharArray():把字元串轉換為字元數組
char[] chs = s.toCharArray();
for (int x = 0; x < chs.length; x++) {
System.out.println(chs[x]);
}
System.out.println("-----------");
// String toLowerCase():把字元串轉換為小寫字元串
System.out.println("HelloWorld".toLowerCase());
// String toUpperCase():把字元串轉換為大寫字元串
System.out.println("HelloWorld".toUpperCase());
}
}
結果:
a
b
c
d
e
-----------
helloworld
HELLOWORLD
註意:
字元串的遍歷有兩種方式:一是length()加上charAt()。二是把字元串轉換為字元數組,然後遍曆數組。
3.3.4 其他常用方法
1)常用方法
String trim():去除字元串兩端空格
String[] split(String str):按照指定符號分割字元串
2)核心代碼
public class TestString {
public static void main(String[] args) {
// 創建字元串對象
String s1 = "helloworld";
String s2 = " helloworld ";
String s3 = " hello world ";
System.out.println("---" + s1 + "---");
System.out.println("---" + s1.trim() + "---");
System.out.println("---" + s2 + "---");
System.out.println("---" + s2.trim() + "---");
System.out.println("---" + s3 + "---");
System.out.println("---" + s3.trim() + "---");
System.out.println("-------------------");
// String[] split(String str)
// 創建字元串對象
String s4 = "aa,bb,cc";
String[] strArray = s4.split(",");
for (int x = 0; x < strArray.length; x++) {
System.out.println(strArray[x]);
}
}
}
結果:
---helloworld---
---helloworld---
--- helloworld ---
---helloworld---
--- hello world ---
---hello world---
-------------------
aa
bb
cc
四、String的不可變性(immutable)
當我們去閱讀源代碼的時候,會發現有這樣的一句話:
Strings are constant; their values cannot be changed after they are created.
意思就是說:String是個常量,從一齣生就註定不可變。
我想大家應該就知道為什麼String不可變了,String類被final修飾,官方註釋說明創建後不能被改變,但是為什麼String要使用final修飾呢?
4.1 案例
瞭解一個經典的面試題:
public class Apple {
public static void main(String[] args) {
String a = "abc";
String b = "abc";
String c = new String("abc");
System.out.println(a == b); // true
System.out.println(a.equals(b)); // true
System.out.println(a == c); // false
System.out.println(a.equals(c)); // true
}
}
記憶體圖:

4.2 分析
因為String太過常用,JAVA類庫的設計者在實現時做了個小小的變化,即採用了享元模式,每當生成一個新內容的字元串時,他們都被添加到一個共用池中,當第二次再次生成同樣內容的字元串實例時,就共用此對象,而不是創建一個新對象,但是這樣的做法僅僅適合於通過=符號進行的初始化。
需要說明一點的是,在object中,equals()是用來比較記憶體地址的,但是String重寫了equals()方法,用來比較內容的,即使是不同地址,只要內容一致,也會返回true,這也就是為什麼a.equals(c)返回true的原因了。
4.3 優點
可以實現多個變數引用堆記憶體中的同一個字元串實例,避免創建的開銷。
我們的程式中大量使用了String字元串,有可能是出於安全性考慮。
大家都知道HashMap中key為String類型,如果可變將變的多麼可怕。
當我們在傳參的時候,使用不可變類不需要去考慮誰可能會修改其內部的值,如果使用可變類的話,可能需要每次記得重新拷貝出裡面的值,性能會有一定的損失。
五、字元串常量池
5.1 字元串常量池概述
1). 常量池表(Constant_Pool table)
Class文件中存儲所有常量(包括字元串)的table。
這是Class文件中的內容,還不是運行時的內容,不要理解它是個池子,其實就是Class文件中的位元組碼指令。
2). 運行時常量池(Runtime Constant Pool)
JVM記憶體中方法區的一部分,這是運行時的內容。
這部分內容(絕大部分)是隨著JVM運行時候,從常量池轉化而來,每個Class對應一個運行時常量池。
上一句中說絕大部分是因為:除了Class中常量池內容,還可能包括動態生成並加入這裡的內容。
3). 字元串常量池(String Pool)
這部分也在方法區中,但與Runtime Constant Pool不是一個概念,String Pool是JVM實例全局共用的,全局只有一個JVM規範要求進入這裡的String實例叫“被駐留的interned string”,各個JVM可以有不同的實現,HotSpot是設置了一個哈希表StringTable來引用堆中的字元串實例,被引用就是被駐留。
5.2 亨元模式
其實字元串常量池這個問題涉及到一個設計模式,叫“享元模式”,顧名思義 - - - > 共用元素模式
也就是說:一個系統中如果有多處用到了相同的一個元素,那麼我們應該只存儲一份此元素,而讓所有地方都引用這一個元素
Java中String部分就是根據享元模式設計的,而那個存儲元素的地方就叫做“字元串常量池 - String Pool”
5.3 詳細分析
舉例:
int x = 10;
String y = "hello";
- 首先,
10和"hello"會在經過javac(或者其他編譯器)編譯過後變為Class文件中constant_pool table的內容 - 當我們的程式運行時,也就是說
JVM運行時,每個Classconstant_pool table中的內容會被載入到JVM記憶體中的方法區中各自Class的<span>Runtime Constant Pool</span>。 - 一個沒有被
String Pool包含的Runtime Constant Pool中的字元串(這裡是"hello")會被加入到String Pool中(HosSpot使用hashtable引用方式),步驟如下:
一是:在Java Heap中根據"hello"字面量create一個字元串對象
二是:將字面量"hello"與字元串對象的引用在hashtable中關聯起來,鍵 - 值 形式是:"hello" = 對象的引用地址。
另外來說,當一個新的字元串出現在Runtime Constant Pool中時怎麼判斷需不需要在Java Heap中創建新對象呢?
策略是這樣:會先去根據equals來比較Runtime Constant Pool中的這個字元串是否和String Pool中某一個是相等的(也就是找是否已經存在),如果有那麼就不創建,直接使用其引用;反之,如上3
如此,就實現了享元模式,提高的記憶體利用效率。
六、總結
string對象在記憶體對中被創建後,就無法修改。如果需要一個可修改的字元串,應該使用StringBuffer或者StringBuilder。如果只需要創建一個字元串,可以使用引號的方式,如果在堆中創建一個新的對象,可以選擇構造函數。
七、拓展
7.1 new String()會創建幾個對象
String s = new String("hello");
會創建2個對象
首先,出現了字面量"hello",那麼去String Pool中查找是否有相同字元串存在,因為程式就這一行代碼所以肯定沒有,那麼就在Java Heap中用字面量"hello"首先創建1個String對象。
接著,new String("hello"),關鍵字new又在Java Heap中創建了1個對象,然後調用接收String參數的構造器進行了初始化。最終s的引用是這個String對象。
7.2 String真的不可變嗎?
前面我們介紹了,String類是用final關鍵字修飾的,所以我們認為其是不可變對象。但是真的不可變嗎?
每個字元串都是由許多單個字元組成的,我們知道其源碼是由char[] value字元數組構成。
value被final修飾,只能保證引用不被改變,但是value所指向的堆中的數組,才是真實的數據,只要能夠操作堆中的數組,依舊能改變數據。而且value是基本類型構成,那麼一定是可變的,即使被聲明為private,我們也可以通過反射來改變。
String str = "vae";
// 列印原字元串
System.out.println(str);//vae
// 獲取String類中的value欄位
Field fieldStr = String.class.getDeclaredField("value");
// 因為value是private聲明的,這裡修改其訪問許可權
fieldStr.setAccessible(true);
// 獲取str對象上的value屬性的值
char[] value = (char[]) fieldStr.get(str);
// 將第一個字元修改為V(小寫改大寫)
value[0] = 'V';
// 列印修改之後的字元串
System.out.println(str);//Vae
通過前後兩次列印的結果,我們可以看到String被改變了,但是在代碼里,幾乎不會使用反射的機制去操作String字元串,所以,我們會認為String類型是不可變的。
那麼,String類為什麼要這樣設計成不可變呢?我們可以從性能以及安全方面來考慮:
- 安全
引發安全問題,譬如資料庫的用戶名、密碼都是以字元串的形式傳入來獲得資料庫的連接,或者在socket編程中,主機名和埠都是以字元串的形式傳入。因為字元串是不可變的,所以它的值是不可改變的,如果改變字元串指向的對象的值,就會造成安全漏洞。
保證線程安全,在併發場景下,多個線程同時讀寫資源時,會引競態條件,由於String是不可變的,不會引發線程的問題而保證了線程。
HashCode,當String被創建出來的時候,hashcode也會隨之被緩存,hashcode的計算與value有關,若String可變,那麼hashcode也會隨之變化,針對於Map、Set等容器,他們的鍵值需要保證唯一性和一致性,因此,String的不可變性使其比其他對象更適合當容器的鍵值。
- 性能
當字元串是不可變時,字元串常量池才有意義。字元串常量池的出現,可以減少創建相同字面量的字元串,讓不同的引用指向池中同一個字元串,為運行時節約很多的堆記憶體。若字元串可變,字元串常量池失去意義,基於常量池的String.intern()方法也失效,每次創建新的String將在堆內開闢出新的空間,占據更多的記憶體。


