
“數據湖”、“湖倉一體”及“流批一體”等概念,是近年來大數據領域熱度最高的辭彙,在各大互聯網公司掀起了一波波的熱潮,各家公司紛紛推出了自己的技術方案,其中作為全鏈路數字化技術與服務提供商的袋鼠雲,在探索數據湖架構的早期,就調研並選用了Iceberg作為基礎框架,在落地過程中深度使用了Iceberg並 ...
“數據湖”、“湖倉一體”及“流批一體”等概念,是近年來大數據領域熱度最高的辭彙,在各大互聯網公司掀起了一波波的熱潮,各家公司紛紛推出了自己的技術方案,其中作為全鏈路數字化技術與服務提供商的袋鼠雲,在探索數據湖架構的早期,就調研並選用了Iceberg作為基礎框架,在落地過程中深度使用了Iceberg併進行了部分改造,在這個過程中,我們積累出了一些經驗和探索實踐,希望通過本篇文章與大家分享,也歡迎大家一起共同討論。
一、為什麼選擇Iceberg
Iceberg作為Apache基金會下的一個頂級項目,是業界公認的開源數據湖實現方案之一,考慮到任何概念的提出本質上是源於底層軟硬體技術或架構上取得了新的突破,我們首先站在技術演進的角度對Iceberg的出現契機和應用場景進行分析。
01 大數據存儲技術現狀
2006年Hadoop框架橫空出世,改變了企業對數據的存儲、處理和分析的認知,加速了大數據的發展,形成了完善的生態圈。工程師們將龐雜的歷史數據存在分散式文件系統HDFS中,通過Hive、Spark等進行加速計算處理。至今為止,HDFS已然成為廣泛應用的大數據基礎組件。
在這個大數據技術發展過程中,也面臨著一些問題。在Hive中,將表綁定為HDFS上的一個目錄,通過HiveMetaStore記錄其綁定的存儲位置,計算引擎查詢數據時請求主節點獲取文件並讀取,這天然缺少事務保證:某個用戶寫入的文件其他用戶立即可見,沒有隔離性;即便先寫入到隱藏文件中,待事務提交後再全部改名可見,因為一批文件的改名不是原子操作,這隻能保證分區級別的原子性。隨著對象存儲的廣泛應用,通過主節點去獲取全部文件有比較大的性能損耗,因為對象存儲的“List”性能較差。
經過以上分析,我們發現Hive中這種設計的缺陷在於缺乏對錶數據文件的管理維護:對於表中不同時刻包含的數據文件,都要即時訪問HDFS主節點獲取,這樣子就造成了比較大的資源浪費。
而數據湖卻能很好的解決這一問題,數據湖是一個集中各種形式和來源數據的存儲區域,存儲內容雖然種類繁多卻管理有序,對數據文件的組織維護能夠高效地幫助我們對接各類底層存儲和上層計算。
02 數據湖技術選型——Iceberg
我們知道問題的關鍵在於“對錶數據文件的管理維護”,基於此就可以開展技術選型了。在2020年末,技術團隊做了眾多技術方案的調研,包括包括Delta Lake、Hudi、Iceberg,我們最終選用了Iceberg。
而選擇Iceberg的原因,正是基於袋鼠雲的技術棧的具體情況做了充足考慮:袋鼠雲中的離線計算、實時計算、智能標簽等應用,在計算層需要依托Spark、Flink、Trino等多種引擎為客戶解決不同的業務訴求,在底層則可能需要對接客戶自建雲、公有雲等混合存儲。這就要求所選擇的技術方案必須能滿足對接多種類型的需求。
Iceberg具備介面開放、易於拓展的優點,十分符合我們的選型要求。在存儲層HDFS上增加一個中間層Iceberg以跟蹤數據文件,不必改變其他層的架構設計,就可以享受到Iceberg對數據文件管理帶來的極速體驗與美妙特性。下圖展示了袋鼠雲基於Iceberg框架的數據湖架構設計:
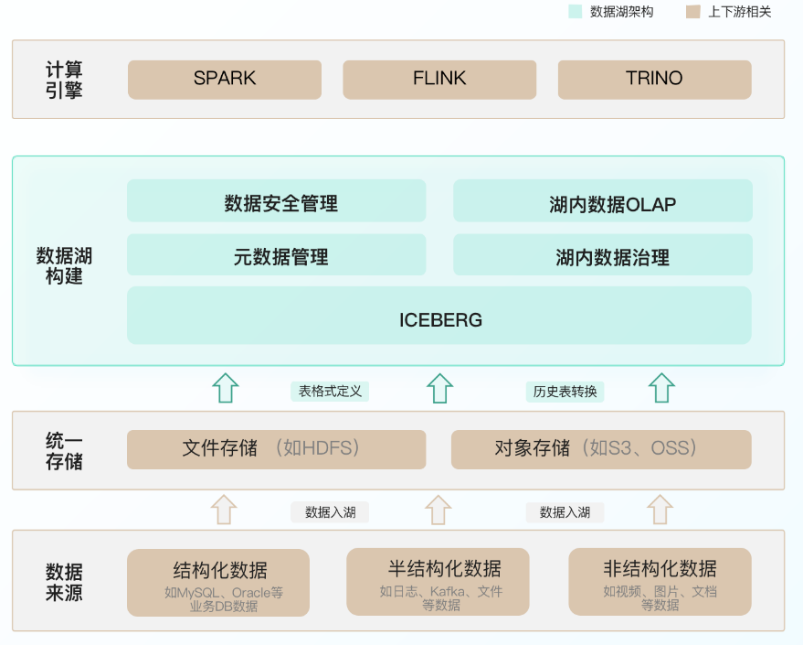
基於前述關鍵點,我們介紹下Iceberg的設計,參考下圖所示:
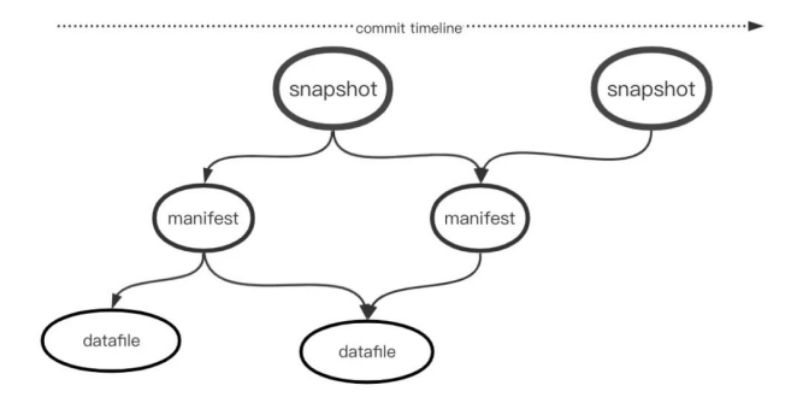
Iceberg在數據文件的基礎上增加了文件清單和文件快照等索引,通過這些索引我們就能跟蹤到每張表在當前時刻有哪些數據文件,這就解決了前文提到的Hive中的設計缺陷:某個用戶寫入的臨時文件不會被其他用戶讀取到,因為這些文件沒有被快照記錄;每個事務修改跟蹤的數據文件時,需要向鎖服務進行申請,成功獲取到鎖許可之後可以更新快照內容,一次快照修改可以增加多個文件,這樣就保證原子性;預先記錄好目錄下的每個數據文件可以避免對HDFS主節點的多次訪問,對雲存儲友好。
二、Iceberg在袋鼠雲中的應用實踐
01 行級更新
在Hive中想要對歷史數據進行訂正,需要用增量數據合併歷史數據後替換歷史數據,這種方式的代價是比較大的,即便是很少的更新也需要對全表或者整個分區進行掃描。
利用Iceberg這種合併和覆寫可以被推遲,如下圖所示:
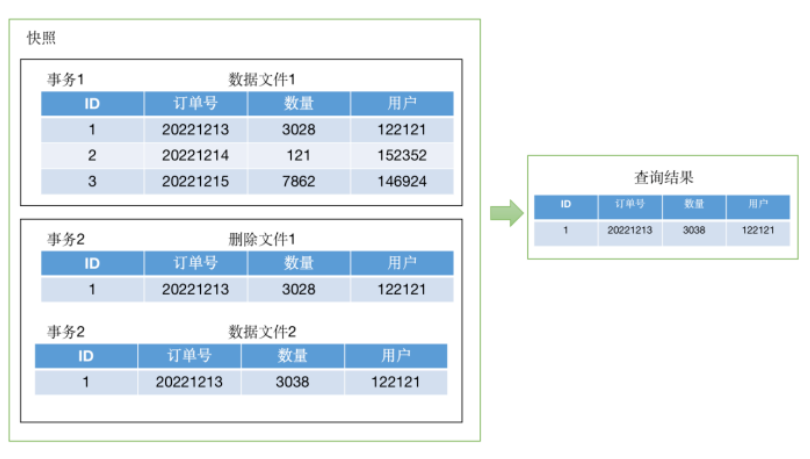
在Iceberg中,可以寫入一份標記刪除的數據文件並再寫入更新後的數據文件,這樣的好處是訂正歷史數據時用戶在數棧平臺的操作等待時間會很短,在查詢的時候再對這個標記刪除文件中的數據進行更新,準確查找到更新之後的數據。而實際對數據文件內容合併的耗時操作推遲在用戶休息的時候,保證了後續操作的性能。
02 查詢加速
在HDFS上,數據文件通常採用Parquet、ORC等存儲格式,這些存儲格式中記錄了諸如列最大值/最小值/空值等詳細的元數據信息,因此在進行查詢的過程中,Iceberg充分利用了存儲格式提供的元數據信息進行文件過濾。
用戶在數棧平臺寫入數據時,在文件清單中彙總了每個文件中保存數據每一列的最大值/最小值/空值信息。在查詢數據時,對查詢條件和彙總信息進行交集判斷,對於沒有交集的文件就不需要再去讀取了,這樣就能夠極大的減少需要讀取的文件數量。
考慮到數據文件的分佈是在寫入時決定的,在寫入數據順序不規律的情況下,文件中的最大值/最小值範圍跨度會很大,這樣並集判斷過濾的效果就沒有那麼明顯了,這時候在數棧平臺上按照一定規則對數據進行重排列,使得具有相似特征的數據落入到同一個數據文件里,這樣提取出來的最大值/最小值信息就會在更接近的範圍里,查詢過濾性能會有更大提升。
03 自動治理
在Iceberg的寫入過程中,為了支持快速寫入和數據跟蹤等功能,其代價是會在每次操作引入不同數量的小文件,這些小文件會隨著時間的前進而不斷拖延系統的效率,必須要通過合併操作進行刪除才能繼續保證系統的高效。
Iceberg本身提供了文件合併、快照清理等工具,但這需要用戶手動去啟動任務才能觸發,對於使用者來說是額外心智負擔。
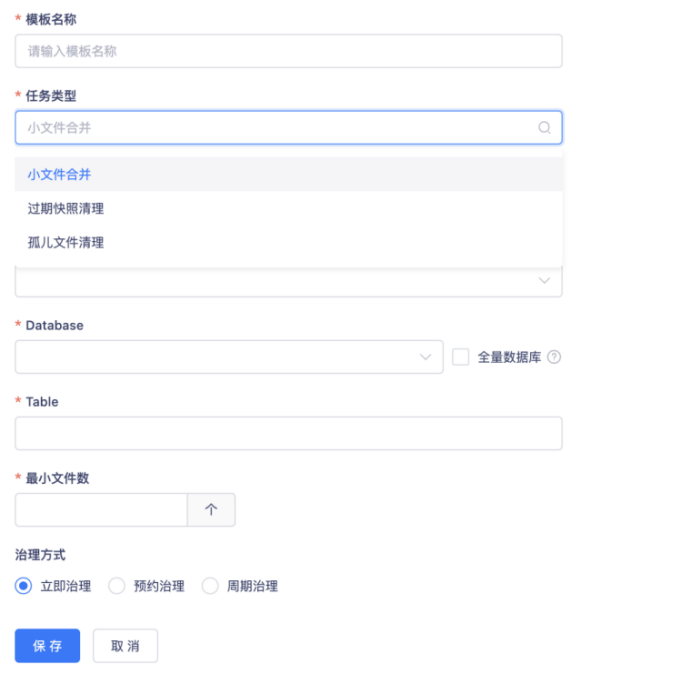
如上圖所示,袋鼠雲在產品設計上為用戶屏蔽了這種運維上的複雜度,用戶只需要對錶進行基本參數的設置就可以享受新框架優化後帶來的快速和便捷,而更複雜的文件治理任務的啟動和資源配置都交由後臺程式監控完成。
三、袋鼠雲基於Iceberg的改造
除了對Iceberg本身提供的能力進行應用,袋鼠雲還根據生產場景的要求對Iceberg做了一定的改造。
01 列更新
在袋鼠雲標簽引擎中經常有需要根據原子指標生成派生指標的場景,在後臺程式中就是為一張大寬表增加新的欄位並且填入數據。在過去,我們依賴OverWrite操作在HDFS上重寫新的表數據,然而這種操作都需要將全部欄位數據進行寫入,非常消耗存儲和時間的(想象一下一張表有幾百個欄位,每次都需要重新寫入)。
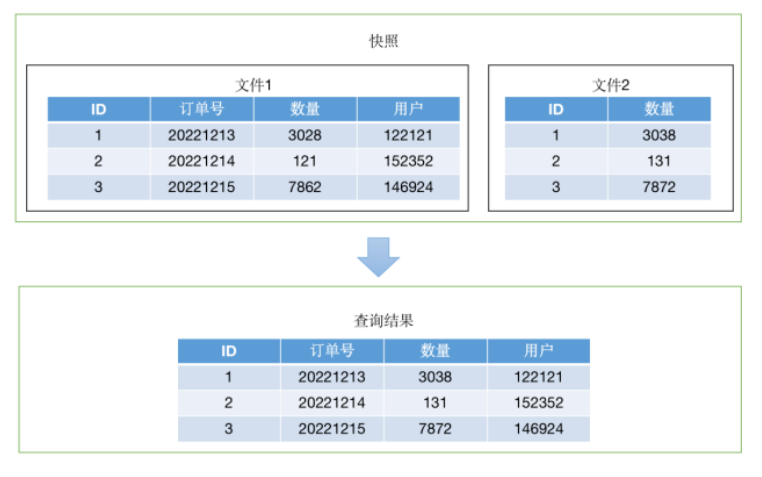
基於Iceberg袋鼠雲設計了一種優化方案,如上圖所示:保留原來的數據文件,列更新時將新的欄位數據和表的主鍵欄位數據一起寫入到新的數據文件。這樣,在寫入過程中需要寫入的數據量就大大減少了,而在讀取過程中,再將新欄位和原有的欄位做一次合併,這樣就能夠保證數據的準確性。同時我們還會在查詢時只讀取包含查詢欄位的文件以提高查詢性能。
當然,在多次添加新欄位之後,每次查詢中包含的合併操作就多了,性能就會隨之下降,這就需要結合前述的文件合併功能,定時進行數據合併,這樣更新累計的副作用就可以消除了。
02 批流一體
批流一體在存儲上要解決的很重要的問題是:離線數倉依賴HDFS存儲,HDFS能夠提供大規模的存儲,成本低廉,然而其實時性比較差;實時數倉依賴Kafka存儲,Kafka能夠存儲的數據量有限,但是能夠提供非常好的實時性。兩條技術鏈路帶來了理解和使用上的困難,能否提供統一的存儲是批流一體架構落地的關鍵。
在袋鼠雲中,我們提出了一種基於Iceberg的屏蔽能力,構建的針對這兩種組件的統一存儲方案:底層存儲混合使用Iceberg和Kafka,但對使用者只暴露一張完整的數據表,在Iceberg中記錄Kafka的切換位點(偏移量),讀取時根據當前數據的時間信息選擇讀取Kafka或者Iceberg數據源。如下圖所示:
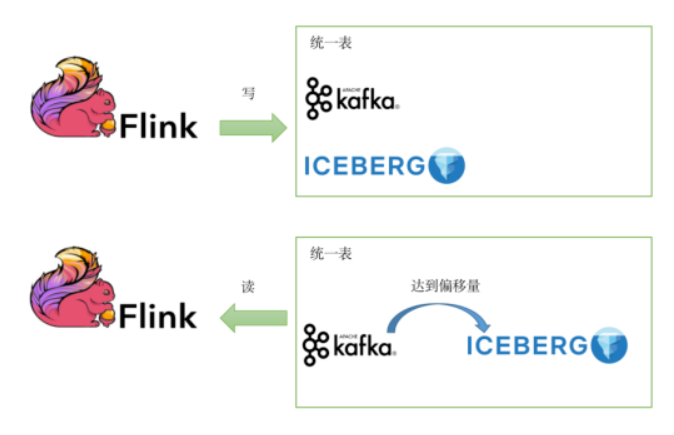
具體步驟有:
1)在創建表時,設置Iceberg存儲和Kafka存儲相關的元數據信息。
2)寫入數據時,向兩種存儲介質一起寫入。在Iceberg每次生成新快照時,將最後一條數據對應的Kafka偏移量寫入快照信息里。用戶可以選擇性開始Kafka事務保證。
3)讀取數據時,在最近一段時間內的數據都通過Kafka進行消費,在讀取完Kafka的數據後根據偏移量切換到對Iceberg記錄的HDFS文件進行訪問,讀取歷史數據。
這樣就能符合了袋鼠雲用戶使用不同處理速度去處理不同階段數據的需求。
四、寫在最後
以上就是袋鼠雲基於Iceberg在數據湖的一些探索和實踐,目前這種框架已應用於我們的數據湖產品DataLake——提供面向湖倉一體的數據湖管理分析服務。基於統一的元數據抽象構建一致性的數據訪問,提供海量數據的存儲管理和實時分析處理能力,可以幫助企業快速構建湖倉一體化平臺,完成數字化基礎建設。
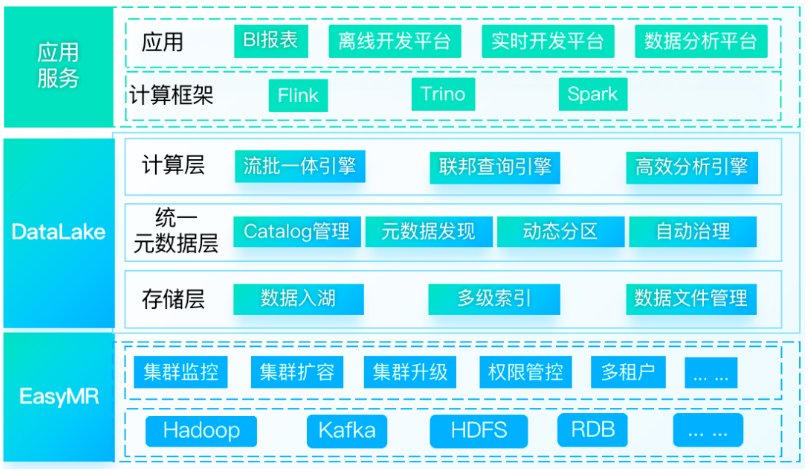
未來我們還會對數據湖和湖倉一體架構做更多的探索和應用,敬請期待。
歡迎大家瞭解或咨詢更多有關數據湖產品的信息
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


