
1.3 Apache Hadoop的重要組成 Hadoop=HDFS(分散式文件系統)+MapReduce(分散式計算框架)+Yarn(資源協調框架)+Common模塊 Hadoop HDFS:(Hadoop Distribute File System )一個高可靠、高吞吐量的分散式文件系統 比如 ...
目錄
1.3 Apache Hadoop的重要組成
Hadoop=HDFS(分散式文件系統)+MapReduce(分散式計算框架)+Yarn(資源協調框架)+Common模塊
- Hadoop HDFS:(Hadoop Distribute File System )一個高可靠、高吞吐量的分散式文件系統
比如:100T數據存儲, “分而治之” 。分:拆分-->數據切割,100T數據拆分為10G一個數據塊由一個電腦節點存儲這個數據塊。
數據切割、製作副本、分散儲存
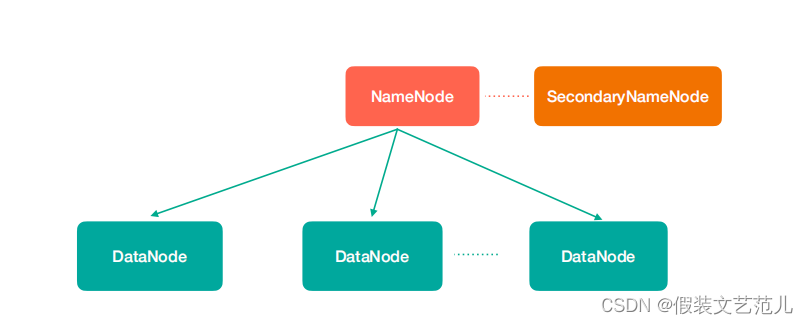
圖中涉及到幾個角色
NameNode(nn):存儲文件的元數據,比如文件名、文件目錄結構、文件屬性(生成時間、副 本數、文件許可權),以及每個文件的塊列表和塊所在的DataNode等。
SecondaryNameNode(2nn):輔助NameNode更好的工作,用來監控HDFS狀態的輔助後臺程式,每隔一段時間獲取HDFS元數據快照。
DataNode(dn):在本地文件系統存儲文件塊數據,以及塊數據的校驗
註意:NN,2NN,DN這些既是角色名稱,進程名稱,代指電腦節點名稱!!
-
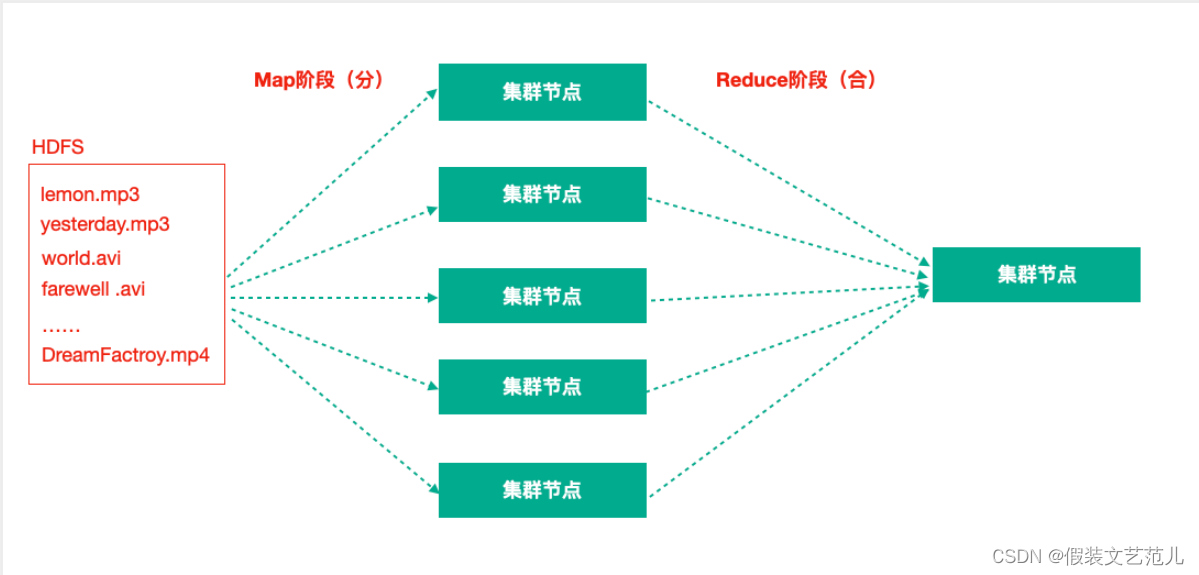
Hadoop MapReduce:一個分散式的離線並行計算框架
拆解任務、分散處理、彙整結果
MapReduce計算 = Map階段 + Reduce階段Map階段就是“分”的階段,並行處理輸入數據
Reduce階段就是“合”的階段,對Map階段結果進行彙總
-
Hadoop YARN:作業調度與集群資源管理的框架
計算資源協調
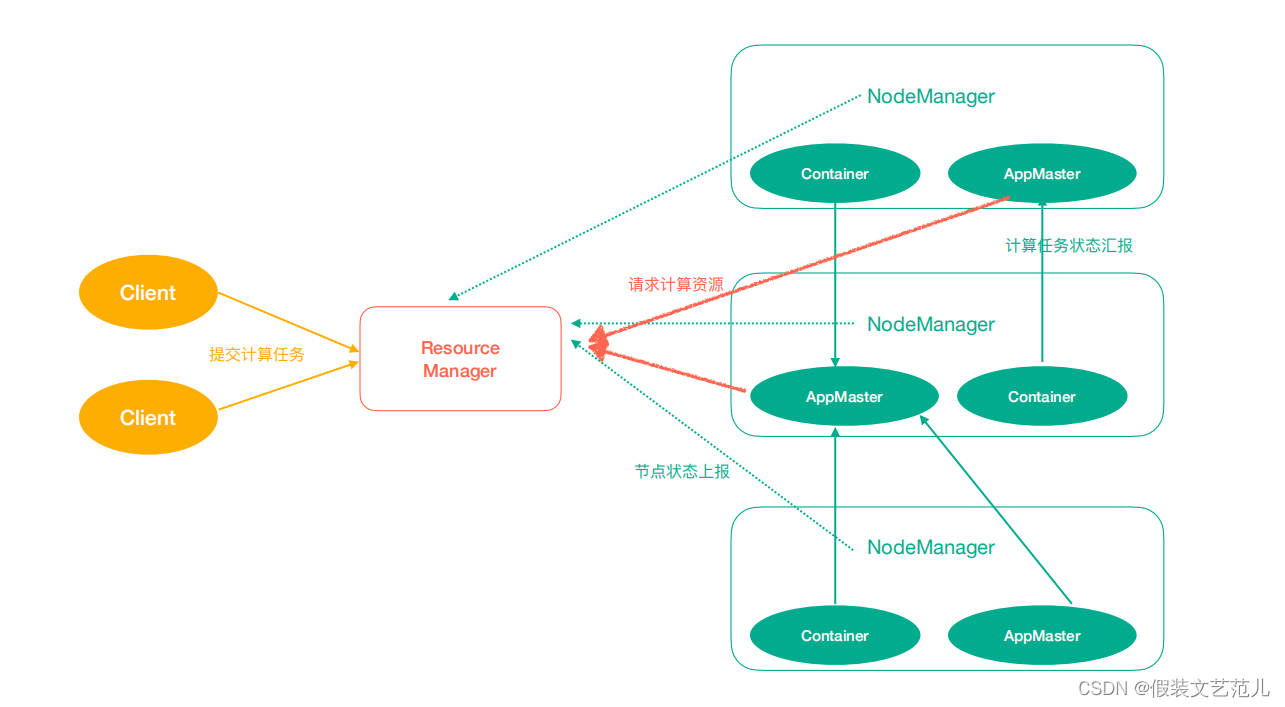
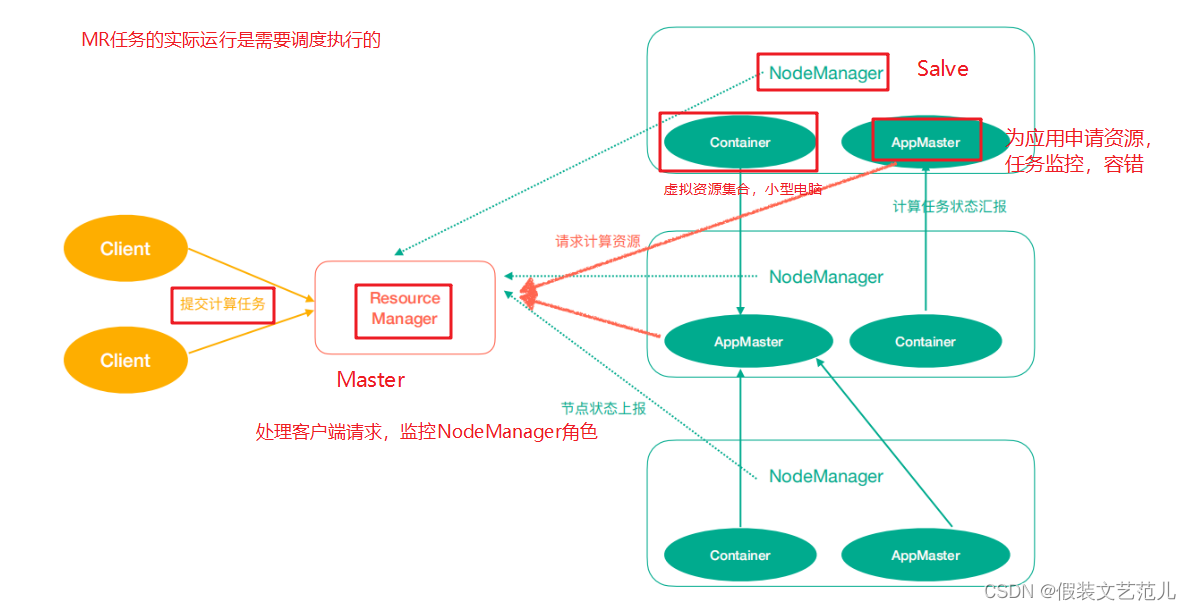
Yarn中有如下幾個主要角色,同樣,既是角色名、也是進程名,也指代所在電腦節點名稱。
ResourceManager(rm):處理客戶端請求、啟動/監控ApplicationMaster、監控NodeManager、資源分配與調度;
NodeManager(nm):單個節點上的資源管理、處理來自ResourceManager的命令、處理來自ApplicationMaster的命令;
ApplicationMaster(am):數據切分、為應用程式申請資源,並分配給內部任務、任務監控與容錯。
Container:對任務運行環境的抽象,封裝了CPU、記憶體等多維資源以及環境變數、啟動命令等任務運行相關的信息。
ResourceManager是老大,NodeManager是小弟,ApplicationMaster是計算任務專員。
- Hadoop Common:支持其他模塊的工具模塊(Configuration、RPC、序列化機制、日誌操作)

