
使用Apache PDFBox實現拆分、合併PDF 問題背景 如何拆分PDF? 如何合併PDF? 如何拆分併合並PDF實現去除PDF的某些頁? Apache PDFBox介紹 Apache PDFBox 1.8.10官方文檔 Apache PDFBox 庫是一個開源的 Java 工具,用於處理 PD ...
目錄
使用Apache PDFBox實現拆分、合併PDF
問題背景
- 如何拆分PDF?
- 如何合併PDF?
- 如何拆分並合併PDF實現去除PDF的某些頁?
Apache PDFBox介紹
Apache PDFBox 庫是一個開源的 Java 工具,用於處理 PDF 文件。該項目允許創建新的PDF文檔,操作 現有文檔以及從文檔中提取內容的能力。 PDFBox還包括幾個命令行實用程式。PDFBox 發佈 在 Apache 許可證下,版本 2.0。
也就是說,我們可以使用PDFBox實現拆分、合併PDF。
在maven項目中添加依賴:
<!--PDF操作-->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>1.8.10</version>
</dependency>
拆分PDF
我們需實現WPS這種按照範圍拆分的拆分規則:

- 參考樣例
以下是wiki教程中找到的樣例,可以實現按照每頁拆分成pdf。
public static void main(String[] args) throws IOException {
//Loading an existing PDF document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
//Instantiating Splitter class
Splitter splitter = new Splitter();
//splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
//Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
//Saving each page as an individual document
int i = 1;
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
pd.save("C:/PdfBox_Examples/sample"+ i++ +".pdf");
}
System.out.println("Multiple PDF’s created");
document.close();
}
org.apache.pdfbox.util.Splitter類
Splitter 類有三個拆分相關的參數
private int splitAtPage = 1;
private int startPage = -2147483648;
private int endPage = 2147483647;
分別代表拆分的頁數範圍,開始拆分的頁數,結束拆分的頁數。
也就是說,我們可以通過實現設置splitter的相關參數(如splitter.setStartPage(12)等)來實現按照範圍拆分的功能。
- 匹配拆分規則
建立SplitterDTO
/**
* Splitter類的配置
*/
@Data
class SplitterDTO {
private int splitAtPage;
private int startPage;
private int endPage;
}
使用正則表達式校驗按照範圍拆分的拆分規則,將其參數保存在List<SplitterDTO>中:
// m-n 例如 3-5,拆分第三到第五頁的pdf
private static final String ruleOne = "^[1-9]\\d*-[1-9]\\d*$";
// m 例如 7,拆分第七頁的pdf
private static final String ruleTwo = "^[1-9]\\d*$";
/**
* 正則校驗匹配 拆分規則
* @param splitRule 拆分規則
* @return
*/
private List<SplitterDTO> matchByRegex(String splitRule) {
List<SplitterDTO> result = new ArrayList<>();
String[] splits = splitRule.split(",");
for (String split : splits) {
SplitterDTO dto = new SplitterDTO();
if (split.matches(ruleOne)) {
String[] nums = split.split("-");
dto.setStartPage(Integer.parseInt(nums[0]));
dto.setEndPage(Integer.parseInt(nums[1]));
// 拆分的長度
dto.setSplitAtPage(dto.getEndPage() - dto.getStartPage() + 1);
result.add(dto);
} else if (split.matches(ruleTwo)) {
dto.setStartPage(Integer.parseInt(split));
dto.setEndPage(Integer.parseInt(split));
dto.setSplitAtPage(1);
result.add(dto);
} else {
System.out.println("錯誤的規則:" + split);
}
}
return result;
}
- 根據拆分規則拆分PDF
根據拆分規則開始拆分PDF並保存為pdf。
/**
* 拆分pdf
* @param sourcePdf 源pdf(路徑+文件名+文件尾碼)
* @param splitPath 拆分後的文件路徑
* @param splitFileName 拆分後的文件名(不含尾碼)
* @param splitterDTOS 拆分規則
* @return finalPdfs 最終拆分成的pdf
*/
private List<String> spitPdf(String sourcePdf, String splitPath, String splitFileName, List<SplitterDTO> splitterDTOS) throws IOException, COSVisitorException {
List<String> finalPdfs = new ArrayList<>();
int j = 1;
String splitPdf = splitPath + "\\" + splitFileName + "_";
for (SplitterDTO splitterDTO : splitterDTOS) {
// Loading an existing PDF document
File file = new File(sourcePdf);
PDDocument document = PDDocument.load(file);
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(splitterDTO.getStartPage());
splitter.setSplitAtPage(splitterDTO.getSplitAtPage());
splitter.setEndPage(splitterDTO.getEndPage());
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
String pdfName = splitPdf+ j++ +".pdf";
pd.save(pdfName);
finalPdfs.add(pdfName);
}
// System.out.println("Multiple PDF’s created");
document.close();
}
return finalPdfs;
}
- 拆分測試
public static void main(String[] args) throws Exception {
// 拆分規則:如拆分成1-4,5,以及8三個pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\測試用pdf.pdf";
// 拆分後pdf所放的文件夾
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分後的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
}
控制台輸出結果:
pdf文件拆分成功------------
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_1.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_2.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_3.pdf
對應文件夾生成三個pdf文件:
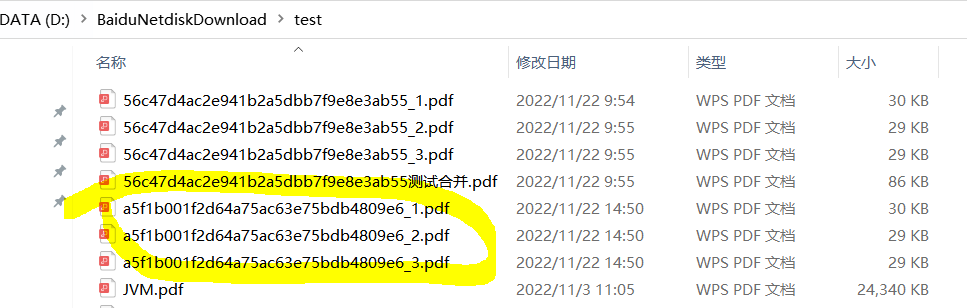
合併PDF
- 代碼
/**
* 合併PDF
* @param inputStreams 需合併的pdf文件流
* @param bothPath 合併後的pdf文件路徑
* @param destinationFileName 合併後的pdf文件名
*/
public static void MergePdf(List<InputStream> inputStreams, String bothPath, String destinationFileName) throws Exception {
// org.apache.pdfbox.util.PDFMergerUtility:pdf合併工具類
PDFMergerUtility mergePdf = new PDFMergerUtility();
File file = new File(bothPath);
if (!file.exists()) {
file.mkdirs();
}
mergePdf.addSources(inputStreams);
// 設置合併生成pdf文件名稱
mergePdf.setDestinationFileName(bothPath + File.separator + destinationFileName);
// 合併PDF
mergePdf.mergeDocuments();
for (InputStream in : inputStreams) {
if (in != null) {
in.close();
}
}
}
- 合併測試
public static void main(String[] args) throws Exception {
/**
* 合併
*/
// 合併pdf生成的文件名
String destinationFileName = DateUtils.format(new Date());
// 需要合併的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
inputStreams.add(new FileInputStream(new File("D:\\ToPDF\\pdf\\水印沖鴨.pdf")));
inputStreams.add(new FileInputStream(new File("D:\\ToPDF\\pdf\\testtest.pdf")));
// 合併後pdf存放路徑
String bothPath = "D:\\ToPDF\\pdf";
MergePdf(inputStreams, bothPath, destinationFileName+"測試合併.pdf");
System.out.println("pdf文件合併成功");
}
控制台輸出結果:
pdf文件合併成功
對應文件夾生成合併的pdf文件:
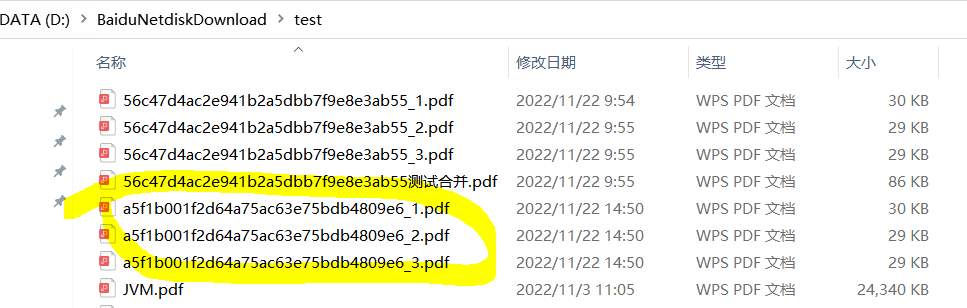
拆分 + 合併
- 測試代碼
public static void main(String[] args) throws Exception {
// 拆分規則:如拆分成1-4,5,以及8三個pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\測試用pdf.pdf";
// 拆分後pdf所放的文件夾
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分後的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
/**
* 2、合併
*/
// 合併pdf生成的文件名
String destinationFileName = splitFileName;
// 需要合併的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
for (String pdf : pdfList) {
inputStreams.add(new FileInputStream(new File(pdf)));
}
// 合併後pdf存放路徑
String bothPath = "D:\\BaiduNetdiskDownload\\test";
MergePdf(inputStreams, bothPath, destinationFileName + "測試合併.pdf");
System.out.println("pdf文件合併成功-----------");
}
- 測試結果
控制台輸出結果:
pdf文件拆分成功------------
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_1.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_2.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_3.pdf
pdf文件合併成功-----------
對應文件夾生成拆分後以及合併的pdf文件:
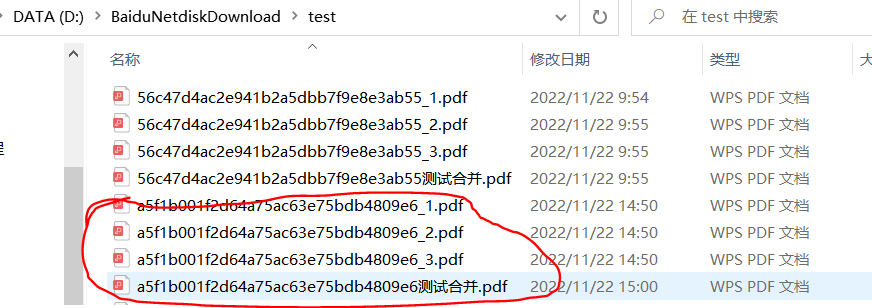
完整代碼
package com.example.demo.utils;
import lombok.Data;
import org.apache.pdfbox.exceptions.COSVisitorException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFMergerUtility;
import org.apache.pdfbox.util.Splitter;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
/**
* @Author 似有風中泣
* @Description 操作PDF類
* @Data 2022/6/27 16:18
* @Version 1.0
*/
public class PdfUtils {
// m-n 例如 3-5,拆分第三到第五頁的pdf
private static final String ruleOne = "^[1-9]\\d*-[1-9]\\d*$";
// m 例如 7,拆分第七頁的pdf
private static final String ruleTwo = "^[1-9]\\d*$";
public static void main(String[] args) throws Exception {
// 拆分規則:如拆分成1-4,5,以及8三個pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\測試用pdf.pdf";
// 拆分後pdf所放的文件夾
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分後的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
/**
* 2、合併
*/
// 合併pdf生成的文件名
String destinationFileName = splitFileName;
// 需要合併的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
for (String pdf : pdfList) {
inputStreams.add(new FileInputStream(new File(pdf)));
}
// 合併後pdf存放路徑
String bothPath = "D:\\BaiduNetdiskDownload\\test";
MergePdf(inputStreams, bothPath, destinationFileName + "測試合併.pdf");
System.out.println("pdf文件合併成功-----------");
}
/**
* 正則校驗匹配 拆分規則
* @param splitRule 拆分規則
* @return
*/
private List<SplitterDTO> matchByRegex(String splitRule) {
List<SplitterDTO> result = new ArrayList<>();
String[] splits = splitRule.split(",");
for (String split : splits) {
SplitterDTO dto = new SplitterDTO();
if (split.matches(ruleOne)) {
String[] nums = split.split("-");
dto.setStartPage(Integer.parseInt(nums[0]));
dto.setEndPage(Integer.parseInt(nums[1]));
// 拆分的長度
dto.setSplitAtPage(dto.getEndPage() - dto.getStartPage() + 1);
result.add(dto);
} else if (split.matches(ruleTwo)) {
dto.setStartPage(Integer.parseInt(split));
dto.setEndPage(Integer.parseInt(split));
dto.setSplitAtPage(1);
result.add(dto);
} else {
System.out.println("錯誤的規則:" + split);
}
}
return result;
}
/**
* 拆分pdf
* @param sourcePdf 源pdf(路徑+文件名+文件尾碼)
* @param splitPath 拆分後的文件路徑
* @param splitFileName 拆分後的文件名(不含尾碼)
* @param splitterDTOS 拆分規則
* @return finalPdfs 最終拆分成的pdf
*/
private List<String> spitPdf(String sourcePdf, String splitPath, String splitFileName, List<SplitterDTO> splitterDTOS) throws IOException, COSVisitorException {
List<String> finalPdfs = new ArrayList<>();
int j = 1;
String splitPdf = splitPath + "\\" + splitFileName + "_";
for (SplitterDTO splitterDTO : splitterDTOS) {
// Loading an existing PDF document
File file = new File(sourcePdf);
PDDocument document = PDDocument.load(file);
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(splitterDTO.getStartPage());
splitter.setSplitAtPage(splitterDTO.getSplitAtPage());
splitter.setEndPage(splitterDTO.getEndPage());
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
String pdfName = splitPdf+ j++ +".pdf";
pd.save(pdfName);
finalPdfs.add(pdfName);
}
// System.out.println("Multiple PDF’s created");
document.close();
}
return finalPdfs;
}
/**
* 合併PDF
* @param inputStreams 需合併的pdf文件流
* @param bothPath 合併後的pdf文件路徑
* @param destinationFileName 合併後的pdf文件名
*/
public static void MergePdf(List<InputStream> inputStreams, String bothPath, String destinationFileName) throws Exception {
// pdf合併工具類
PDFMergerUtility mergePdf = new PDFMergerUtility();
File file = new File(bothPath);
if (!file.exists()) {
file.mkdirs();
}
mergePdf.addSources(inputStreams);
// 設置合併生成pdf文件名稱
mergePdf.setDestinationFileName(bothPath + File.separator + destinationFileName);
// 合併PDF
mergePdf.mergeDocuments();
for (InputStream in : inputStreams) {
if (in != null) {
in.close();
}
}
}
}
/**
* Splitter類的配置
*/
@Data
class SplitterDTO {
private int splitAtPage;
private int startPage;
private int endPage;
}
參考:
https://iowiki.com/pdfbox/pdfbox_splitting_a_pdf_document.html
https://github.com/apache/pdfbox
https://javadoc.io/doc/org.apache.pdfbox/pdfbox/1.8.10/index.html


