
本篇文章我們將進一步探討下Guava Cache 實現層面的一些邏輯與設計策略,讓我們可以對Guava Cache整體有個更加明朗的認識,促進實際使用中對其的理解。 ...

大家好,又見面了。
本文是筆者作為掘金技術社區簽約作者的身份輸出的緩存專欄系列內容,將會通過系列專題,講清楚緩存的方方面面。如果感興趣,歡迎關註以獲取後續更新。
通過《重新認識下JVM級別的本地緩存框架Guava Cache——優秀從何而來》一文,我們知道了Guava Cache作為JVM級別的本地緩存組件的諸多暖心特性,也一步步地學習了在項目中集成並使用Guava Cache進行緩存相關操作。Guava Cache作為一款優秀的本地緩存組件,其內部很多實現機制與設計策略,同樣值得開發人員深入的掌握與借鑒。
作為系列專欄,本篇文章我們將進一步探討下Guava Cache 實現層面的一些邏輯與設計策略,讓我們可以對Guava Cache整體有個更加明朗的認識。

數據回源與回填策略
前面我們介紹過,Guava Cache提供的是一種穿透型緩存模式,當緩存中沒有獲取到對應記錄的時候,支持自動去源端獲取數據並回填到緩存中。這裡回源獲取數據的策略有兩種,即CacheLoader方式與Callable方式,兩種方式適用於不同的場景,實際使用中可以按需選擇。
下麵一起看下這兩種方式。
CacheLoader
CacheLoader適用於數據載入方式比較固定且統一的場景,在緩存容器創建的時候就需要指定此具體的載入邏輯。常見的使用方式如下:
public LoadingCache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.build(new CacheLoader<String, User>() {
@Override
public User load(String key) throws Exception {
System.out.println(key + "用戶緩存不存在,嘗試CacheLoader回源查找並回填...");
return userDao.getUser(key);
}
});
}
上述代碼中,在使用CacheBuilder創建緩存容器的時候,如果在build()方法中傳入一個CacheLoader實現類的方式,則最終創建出來的是一個LoadingCache具體類型的Cache容器:
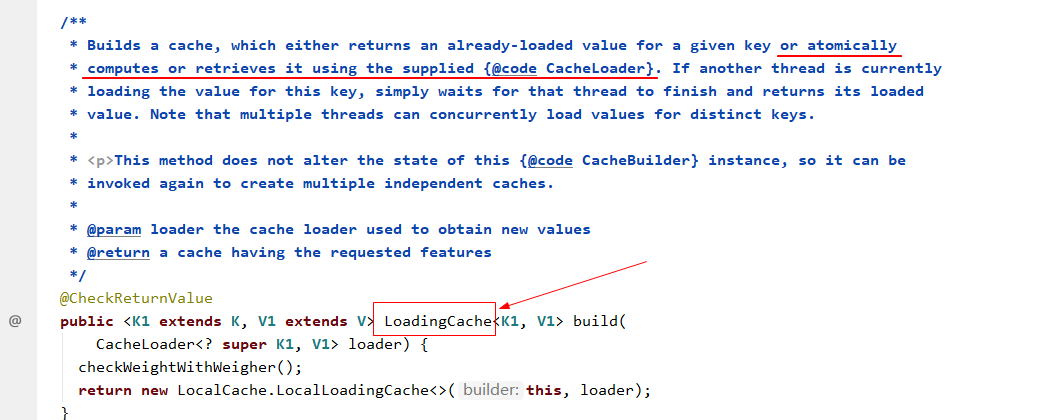
預設情況下,我們需要繼承CacheLoader類並實現其load抽象方法即可。
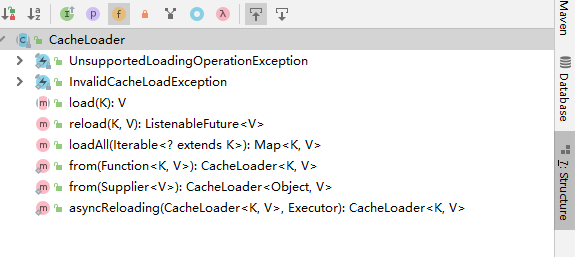
當然,CacheLoader類中還有一些其它的方法,我們也可以選擇性的進行覆寫來實現自己的自定義訴求。比如我們需要設定refreshAfterWrite來支持定時刷新的時候,就推薦覆寫reload方法,提供一個非同步數據載入能力,避免數據刷新操作對業務請求造成阻塞。
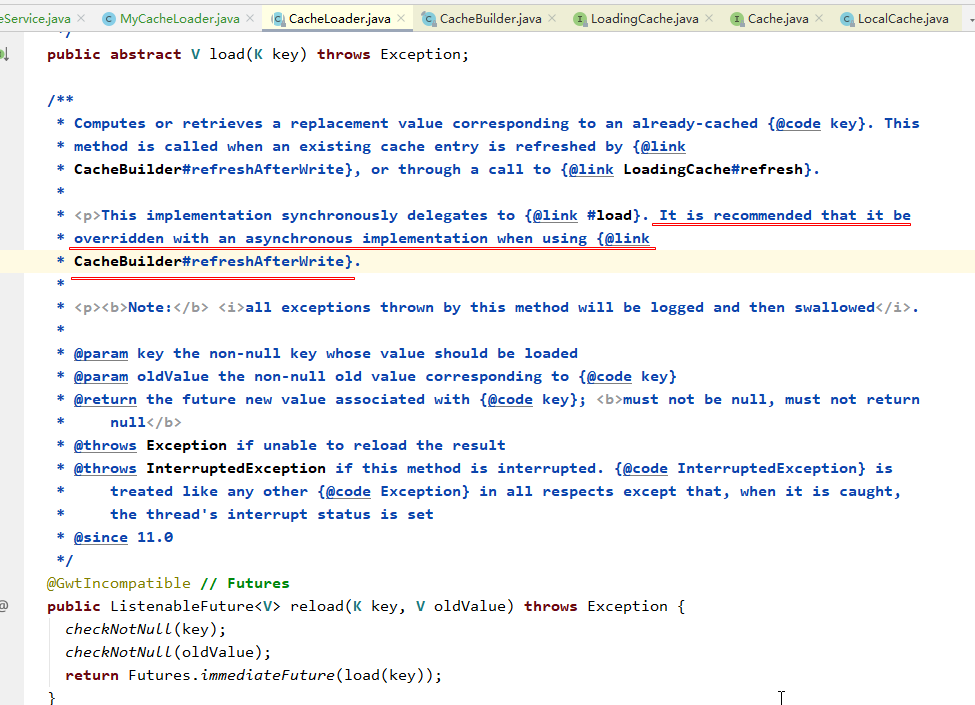
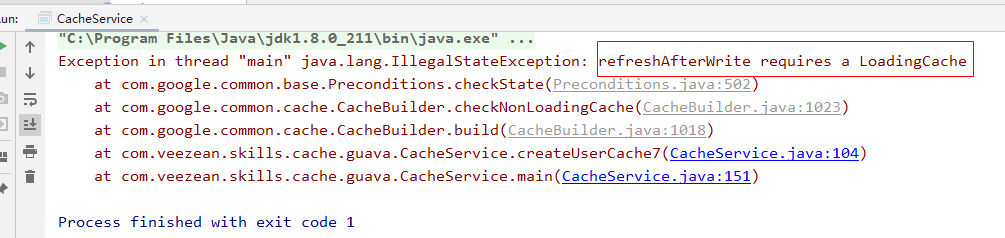
另外,有一點需要註意下,如果創建緩存的時候使用refreshAfterWrite指定了需要定時更新緩存數據內容,則必須在創建的時候指定CacheLoader實例,否則執行的時候會報錯。因為在執行refresh操作的時候,必須調用CacheLoader對象的reload方法去執行數據的回源操作。
Callable
與CacheLoader不同,Callable的方式在每次數據獲取請求中進行指定,可以在不同的調用場景中,分別指定並使用不同的數據獲取策略,更加的靈活。
public static void main(String[] args) {
try {
GuavaCacheService cacheService = new GuavaCacheService();
Cache<String, User> cache = cacheService.createCache();
String userId = "123";
// 獲取userId, 獲取不到的時候執行Callable進行回源
User user = cache.get(userId, () -> cacheService.queryUserFromDb(userId));
System.out.println("get對應用戶信息:" + user);
} catch (Exception e) {
e.printStackTrace();
}
}
通過提供Callable實現函數並作為參數傳遞的方式,可以根據業務的需要,在不同業務調用場景下,指定使用不同的Callable回源策略。
不回源查詢
前面介紹了基於CacheLoader方式自動回源,或者基於Callable方式顯式回源的兩種策略。但是實際使用緩存的時候,並非是緩存中獲取不到數據時就一定需要去執行回源操作。
比如下麵這個場景:
用戶論壇中維護了個黑名單列表,每次用戶登錄的時候,需要先判斷下是否在黑名單中,如果在則禁止登錄。
因為論壇中黑名單用戶占整體用戶量的比重是極少的,也就是幾乎絕大部分登錄的時候去查詢緩存都是無法命中黑名單緩存的。這種時候如果每次查詢緩存中沒有的情況下都去執行回源操作,那幾乎等同於每次請求都需要去訪問一次DB了,這顯然是不合理的。
所以,為了支持這種場景的訪問,Guava cache也提供了一種不會觸發回源操作的訪問方式。如下:
| 介面 | 功能說明 |
|---|---|
| getIfPresent | 從記憶體中查詢,如果存在則返回對應值,不存在則返回null |
| getAllPresent | 批量從記憶體中查詢,如果存在則返回存在的鍵值對,不存在的key則不出現在結果集里 |
上述兩種介面,執行的時候僅會從當前記憶體中已有的緩存數據裡面進行查詢,不會觸發回源的操作。
public static void main(String[] args) {
try {
GuavaCacheService cacheService = new GuavaCacheService();
Cache<String, User> cache = cacheService.createCache();
cache.put("123", new User("123", "123"));
cache.put("124", new User("124", "124"));
System.out.println(cache.getIfPresent("125"));
ImmutableMap<String, User> allPresentUsers =
cache.getAllPresent(Stream.of("123", "124", "125").collect(Collectors.toList()));
System.out.println(allPresentUsers);
} catch (Exception e) {
e.printStackTrace();
}
}
執行後,輸入結果如下:
null
{123=User(userName=123, userId=123), 124=User(userName=124, userId=124)}
Guava Cache的數據清理與載入刷新機制
在前面的CacheBuilder類中有提供了幾種expire與refresh的方法,即expireAfterAccess、expireAfterWrite以及refreshAfterWrite。
這裡我們對幾個方法進行一些探討。
數據過期
對於數據有過期時效訴求的場景,我們可以通過幾種方式設定緩存的過期時間:
-
expireAfterAccess
-
expireAfterWrite
現在我們思考一個問題:數據過期之後,會立即被刪除嗎?在前面的文章中,我們自己構建本地緩存框架的時候,有介紹過緩存數據刪除的幾種機制:
| 刪除機制 | 具體說明 |
|---|---|
| 主動刪除 | 搞個定時線程不停的去掃描並清理所有已經過期的數據。 |
| 惰性刪除 | 在數據訪問的時候進行判斷,如果過期則刪除此數據。 |
| 兩者結合 | 採用惰性刪除為主,低頻定時主動刪除為兜底,兼顧處理性能與記憶體占用。 |
在Guava Cache中,為了最大限度的保證併發性,採用的是惰性刪除的策略,而沒有設計獨立清理線程。所以這裡我們就可以回答前面的問題,也即過期的數據,並非是立即被刪除的,而是在get等操作訪問緩存記錄時觸發過期數據的刪除操作。
在get執行邏輯中進行數據過期清理以及重新回源載入的執行判斷流程,可以簡化為下圖中的關鍵環節:
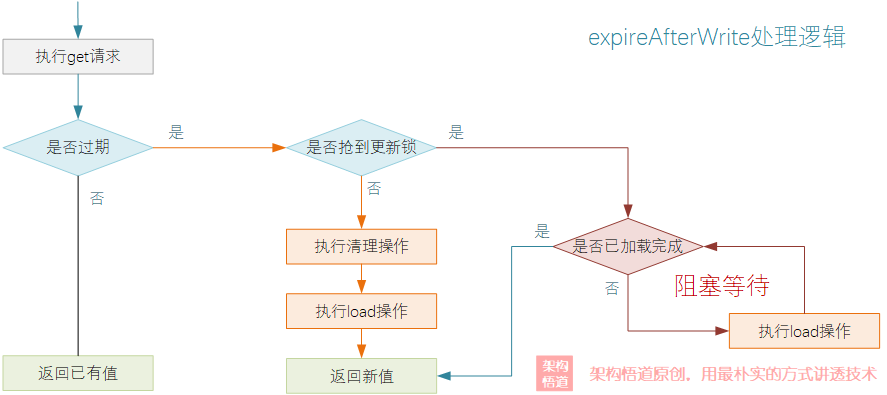
在執行get請求的時候,會先判斷下當前查詢的數據是否過期,如果已經過期,則會觸發對當前操作的Segment的過期數據清理操作。
數據刷新
除了上述的2個過期時間設定方法,Guava Cache還提供了個refreshAfterWrite方法,用於設定定時自動refresh操作。項目中可能會有這麼個情況:
為了提升性能,將最近訪問系統的用戶信息緩存起來,設定有效期30分鐘。如果用戶的角色出現變更,或者用戶昵稱、個性簽名之類的發生更改,則需要最長等待30分鐘緩存失效重新載入後才能夠生效。
這種情況下,我們就可以在設定了過期時間的基礎上,再設定一個每隔1分鐘重新refresh的邏輯。這樣既可以保證數據在緩存中的留存時長,又可以儘可能的縮短緩存變更生效的時間。這種情況,便該refreshAfterWrite登場了。
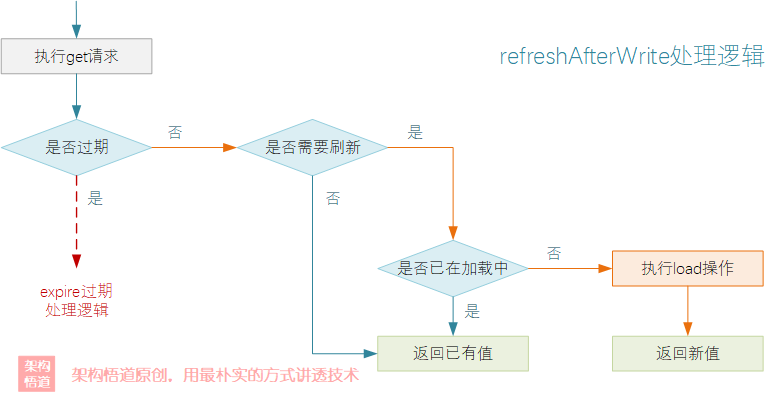
與expire清理邏輯相同,refresh操作依舊是採用一種被動觸發的方式來實現。當get操作執行的時候會判斷下如果創建時間已經超過了設定的刷新間隔,則會重新去執行一次數據的載入邏輯(前提是數據並沒有過期)。
鑒於緩存讀多寫少的特點,Guava Cache在數據refresh操作執行的時候,採用了一種非阻塞式的載入邏輯,儘可能的保證併發場景下對讀取線程的性能影響。
看下麵的代碼,模擬了兩個併發請求同時請求一個需要刷新的數據的場景:
public static void main(String[] args) {
try {
LoadingCache<String, User> cache =
CacheBuilder.newBuilder().refreshAfterWrite(1L, TimeUnit.SECONDS).build(new MyCacheLoader());
cache.put("123", new User("123", "ertyu"));
Thread.sleep(1100L);
Runnable task = () -> {
try {
System.out.println(Thread.currentThread().getId() + "線程開始執行查詢操作");
User user = cache.get("123");
System.out.println(Thread.currentThread().getId() + "線程查詢結果:" + user);
} catch (Exception e) {
e.printStackTrace();
}
};
CompletableFuture.allOf(
CompletableFuture.runAsync(task), CompletableFuture.runAsync(task)
).thenRunAsync(task).join();
} catch (Exception e) {
e.printStackTrace();
}
}
執行後,結果如下:
14線程開始執行查詢操作
13線程開始執行查詢操作
13線程查詢結果:User(userName=ertyu, userId=123)
14線程執行CacheLoader.reload(),oldValue=User(userName=ertyu, userId=123)
14線程執行CacheLoader.load()...
14線程執行CacheLoader.load()結束...
14線程查詢結果:User(userName=97qx6, userId=123)
15線程開始執行查詢操作
15線程查詢結果:User(userName=97qx6, userId=123)
從執行結果可以看出,兩個併發同時請求的線程只有1個執行了load數據操作,且兩個線程所獲取到的結果是不一樣的。具體而言,可以概括為如下幾點:
-
同一時刻僅允許一個線程執行數據重新載入操作,並阻塞等待重新載入完成之後該線程的查詢請求才會返回對應的新值作為結果。
-
當一個線程正在阻塞執行
refresh數據刷新操作的時候,其它線程此時來執行get請求的時候,會判斷下數據需要refresh操作,但是因為沒有獲取到refresh執行鎖,這些其它線程的請求不會被阻塞等待refresh完成,而是立刻返回當前refresh前的舊值。 -
當執行refresh的線程操作完成後,此時另一個線程再去執行get請求的時候,會判斷無需refresh,直接返回當前記憶體中的當前值即可。
上述的過程,按照時間軸的維度來看,可以囊括成如下的執行過程:
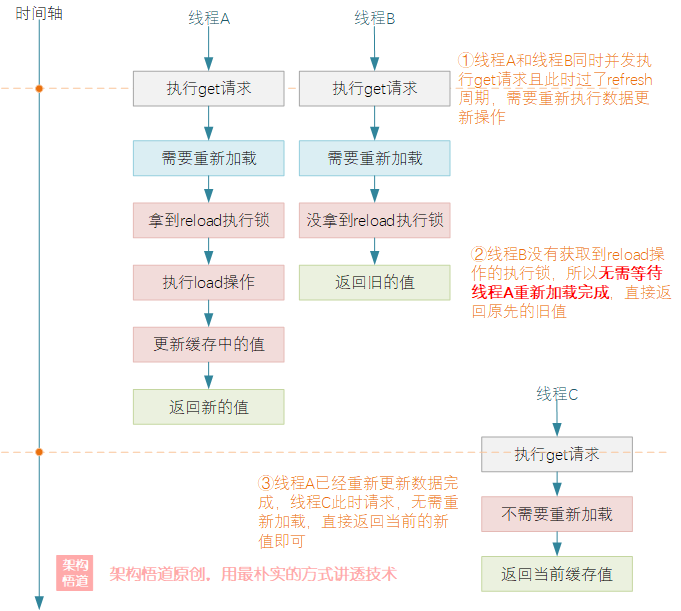
數據expire與refresh關係
expire與refresh在某些實現邏輯上有一定的相似度,很多的文章中介紹的時候甚至很直白的說refresh比expire更好,因為其不會阻塞業務端的請求。個人認為這種看法有點片面,從單純的字面含義上也可以看出這兩種機制不是互斥的、而是一種相互補充的存在,並不存在誰比誰更好這一說,關鍵要看具體是應用場景。
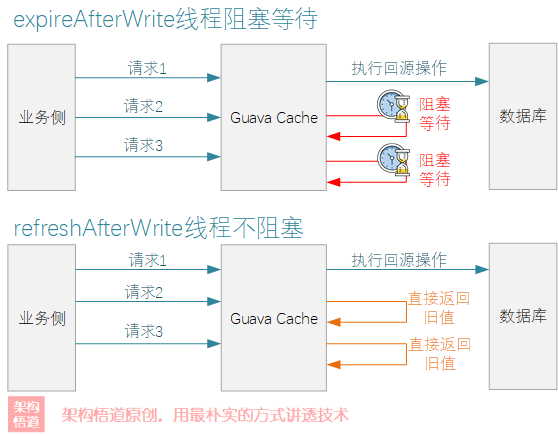
expire操作就是採用的一種嚴苛的更新鎖定機制,當一個線程執行數據重新載入的時候,其餘的線程則阻塞等待。refresh操作執行過程中不會阻塞其餘線程的get查詢操作,會直接返回舊值。這樣的設計各有利弊:
| 操作 | 優勢 | 弊端 |
|---|---|---|
| expire | 有效防止緩存擊穿問題,且阻塞等待的方式可以保證業務層面獲取到的緩存數據的強一致性。 | 高併發場景下,如果回源的耗時較長,會導致多個讀線程被阻塞等待,影響整體的併發效率。 |
| refresh | 可以最大限度的保證查詢操作的執行效率,避免過多的線程被阻塞等待。 | 多個線程併發請求同一個key對應的緩存值拿到的結果可能不一致,在對於一致性要求特別嚴苛的業務場景下可能會引發問題。 |
Guava Cache中的expire與fefresh兩種機制,給人的另一個困惑點在於:兩者都是被動觸發的數據載入邏輯,不管是expire還是refresh,只要超過指定的時間間隔,其實都是依舊存在與記憶體中,等有新的請求查詢的時候,都會執行自動的最新數據載入操作。那這兩個實際使用而言,僅僅只需要依據是否需要阻塞載入這個維度來抉擇?
並非如此。
expire存在的意義更多的是一種數據生命周期終結的意味,超過了expire有效期的數據,雖然依舊會存在於記憶體中,但是在一些觸發了cleanUp操作的情況下,是會被釋放掉以減少記憶體占用的。而refresh則僅僅只是執行數據更新,框架無法判斷是否需要從記憶體釋放掉,會始終占據記憶體。
所以在具體使用時,需要根據場景綜合判斷:
-
數據需要永久存儲,且不會變更,這種情況下
expire和refresh都並不需要設定 -
數據極少變更,或者對變更的感知訴求不強,且併發請求同一個key的競爭壓力不大,直接使用
expire即可 -
數據無需過期,但是可能會被修改,需要及時感知並更新緩存數據,直接使用
refresh -
數據需要過期(避免不再使用的數據始終留在記憶體中)、也需要在有效期內儘可能保證數據的更新一致性,則採用
expire與refresh兩者結合。
對於expire與refresh結合使用的場景,兩者的時間間隔設置,需要註意:
expire時間設定要大於refresh時間,否則的話refresh將永遠沒有機會執行
Guava Cache併發能力支持
採用分段鎖降低鎖爭奪
前面我們提過Guava Cache支持多線程環境下的安全訪問。我們知道鎖的粒度越大,多線程請求的時候對鎖的競爭壓力越大,對性能的影響越大。而如果將鎖的粒度拆分小一些,這樣同時請求到同一把鎖的概率就會降低,這樣線程間爭奪鎖的競爭壓力就會降低。
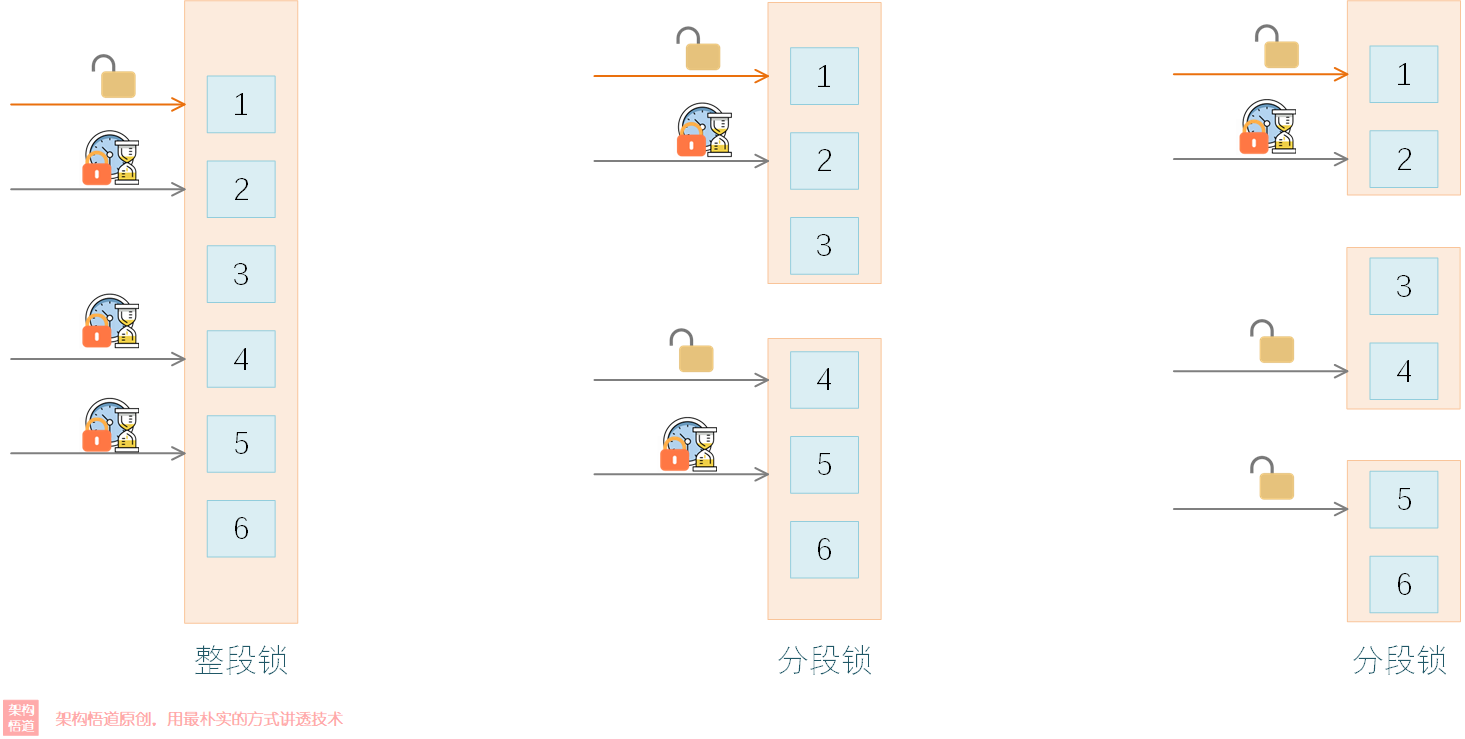
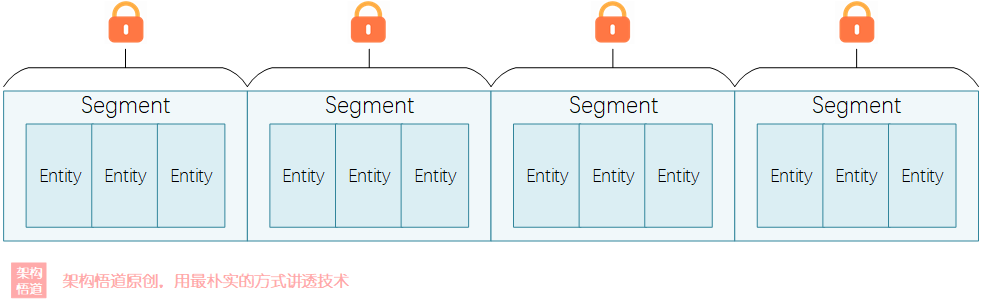
Guava Cache中採用的也就是這種分段鎖策略來降低鎖的粒度,可以在創建緩存容器的時候使用concurrencyLevel來指定允許的最大併發線程數,使得線程安全的前提下儘可能的減少鎖爭奪。而concurrencyLevel值與分段Segment的數量之間也存在一定的關係,這個關係相對來說會比較複雜、且受是否限制總容量等因素的影響,源碼中這部分的計算邏輯可以看下:
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
根據上述的控制邏輯代碼,可以將segmentCount的取值約束概括為下麵幾點:
-
segmentCount 是 2 的整數倍
-
segmentCount 最大可能為
(concurrencyLevel -1)*2 -
如果有按照權重設置容量,則segmentCount不得超過總權重值的
1/20
從源碼中可以比較清晰的看出這一點,Guava Cache在put寫操作的時候,會首先計算出key對應的hash值,然後根據hash值來確定數據應該寫入到哪個Segment中,進而對該Segment加鎖執行寫入操作。
@Override
public V put(K key, V value) {
// ... 省略部分邏輯
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
@Nullable
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
// ... 省略具體邏輯
} finally {
unlock();
postWriteCleanup();
}
}
根據上述源碼也可以得出一個結論,concurrencyLevel只是一個理想狀態下的最大同時併發數,也取決於同一時間的操作請求是否會平均的分散在各個不同的Segment中。極端情況下,如果多個線程操作的目標對象都在同一個分片中時,那麼只有1個線程可以持鎖執行,其餘線程都會阻塞等待。
實際使用中,比較推薦的是將concurrencyLevel設置為CPU核數的2倍,以獲得較優的併發性能。當然,concurrencyLevel也不是可以隨意設置的,從其源碼設置裡面可以看出,允許的最大值為65536。
static final int MAX_SEGMENTS = 1 << 16; // 65536
LocalCache(CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// ... 省略其餘邏輯
}
佛系搶鎖策略
在put等寫操作場景下,Guava Cache採用的是上述分段鎖的策略,通過優化鎖的粒度,來提升併發的性能。但是加鎖畢竟還是對性能有一定的影響的,為了追求更加極致的性能表現,在get等讀操作自身並沒有發現加鎖操作 —— 但是Guava Cache的get等處理邏輯也並非是純粹的只讀操作,它還兼具觸發數據淘汰清理操作的刪除邏輯,所以只在判斷需要執行清理的時候才會嘗試去佛系搶鎖。
那麼它是如何減少搶鎖的幾率的呢?從源碼中可以看出,並非是每次請求都會去觸發cleanUp操作,而是會嘗試積攢一定次數之後再去嘗試清理:
static final int DRAIN_THRESHOLD = 0x3F;
void postReadCleanup() {
if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {
cleanUp();
}
}
在高併發場景下,如果查詢請求量巨大的情況下,即使按照上述的情況限制每次達到一定請求數量之後才去執行清理操作,依舊可能會出現多個get操作線程同時去搶鎖執行清理操作的情況,這樣豈不是依舊會阻塞這些讀取請求的處理嗎?
繼續看下源碼:
void cleanUp() {
long now = map.ticker.read();
runLockedCleanup(now);
runUnlockedCleanup();
}
void runLockedCleanup(long now) {
// 嘗試請求鎖,請求到就處理,請求不到就放棄
if (tryLock()) {
try {
// ... 省略部分邏輯
readCount.set(0);
} finally {
unlock();
}
}
}
可以看到源碼中採用的是tryLock方法來嘗試去搶鎖,如果搶到鎖就繼續後續的操作,如果沒搶到鎖就不做任何清理操作,直接返回 —— 這也是為什麼前面將其形容為“佛系搶鎖”的緣由。這樣的小細節中也可以看出Google碼農們還是有點內功修為的。
承前啟後 —— Caffeine Cache
技術的更新迭代始終沒有停歇的時候,Guava工具包作為Google家族的優秀成員,在很多方面提供了非常優秀的能力支持。隨著JAVA8的普及,Google也基於語言的新特性,對Guava Cache部分進行了重新實現,形成了後來的Caffeine Cache,併在SpringBoot2.x中取代了Guava Cache。
下一篇文章中,我們將一起再聊一聊令人上癮的Caffeine Cache。
小結回顧
好啦,關於Guava Cache中的典型實現機制與核心設計策略,就介紹到這裡了。至此,我們完成了Guava Cache從簡單會用到深度剖析的全過程,不知道小伙伴們是否對Guava Cache有了全新的認識了呢?關於Guava Cache,你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長。


