
對於緩存容器而言,容量限制與數據淘汰是兩個基礎且核心的關鍵點,也是實際使用的時候使用頻率最高的特性。本篇在上一文基礎上深入解讀下Guava Cache中的容量限制與數據淘汰策略的實現與使用約束。 ...

大家好,又見面了。
本文是筆者作為掘金技術社區簽約作者的身份輸出的緩存專欄系列內容,將會通過系列專題,講清楚緩存的方方面面。如果感興趣,歡迎關註以獲取後續更新。
通過《重新認識下JVM級別的本地緩存框架Guava Cache——優秀從何而來》一文,我們知道了Guava Cache作為JVM級別的本地緩存組件的諸多暖心特性,也一步步地學習了在項目中集成並使用Guava Cache進行緩存相關操作。Guava Cache作為一款優秀的本地緩存組件,其內部很多實現機制與設計策略,同樣值得開發人員深入的掌握與借鑒。
作為系列專欄,本篇文章我們將在上一文的基礎上,繼續探討下Guava Cache對於緩存容量限制與數據清理相關的使用與設計機制,進而讓我們在項目中使用起來可以更加的游刃有餘,解鎖更多使用技巧。

容量限制時的Size與Weight區別
弄清Size與Weight
Guava Cache提供了對緩存總量的限制,並且支持從兩個維度進行限制,這裡我們首先要釐清size與weight兩個概念的區別與聯繫。

- 限制緩存條數size
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder().maximumSize(10000L).build();
}
- 限制緩存權重weight
public Cache<String, String> createUserCache() {
return CacheBuilder.newBuilder()
.maximumWeight(50000)
.weigher((key, value) -> (int) Math.ceil(value.length() / 1000))
.build();
}
一般而言,我們限制容器的容量的初衷,是為了防止記憶體占用過大導致記憶體溢出,所以本質上是限制記憶體的占用量。從實現層面,往往會根據總記憶體占用量與預估每條記錄位元組數進行估算,將其轉換為對緩存記錄條數的限制。這種做法相對簡單易懂,但是對於單條緩存記錄占用位元組數差異較大的情況下,會導致基於條數控制的結果不夠精準。
比如:
需要限制緩存最大占用
500M總量,緩存記錄可能大小範圍是1k~100k,按照每條50k進行估算,設定緩存容器最大容量為限制最大容量1w條。如果存儲的都是1k大小的記錄,則記憶體總占用量才10M(記憶體沒有被有效利用起來);若都存儲的是100k大小的記錄,又會導致記憶體占用為1000M,遠大於預期的記憶體占用量(容易造成記憶體溢出)。
為瞭解決這個問題,Guava Cache中提供了一種相對精準的控制策略,即基於權重的總量控制,根據一定的規則,計算出每條value記錄所占的權重值,然後以權重值進行總量的計算。
還是上面的例子,我們按照權重進行設定,假定1k對應基礎權重1,則100k可轉換為權重100。這樣一來:
限制緩存最大占用
500M,1k對應權重1,Nk代表權重N,則我們可以限制總權重為50w。這樣假如存儲的都是1k的記錄,則最多可以緩存5w條記錄;而如果都是100k大小的記錄,則最多僅可以緩存5000條記錄。根據存儲數據的大小不同,最大存儲的記錄條數也不相同,但是最終占用的總體量可以實現基本吻合。
所以,基於weight權重的控制方式,比較適用於這種對容器體量控制精度有嚴格訴求的場景,可以在創建容器的時候指定每條記錄的權重計算策略(比如基於字元串長度或者基於bytes數組長度進行計算權重)。
使用約束說明
在實際使用中,這幾個參數之間有一定的使用約束,需要特別註意一下:
-
如果沒有指定weight實現邏輯,則使用
maximumSize來限制最大容量,按照容器中緩存記錄的條數進行限制;這種情況下,即使設定了maximumWeight也不會生效。 -
如果指定了weight實現邏輯,則必須使用
maximumWeight來限制最大容量,按照容器中每條緩存記錄的weight值累加後的總weight值進行限制。
看下麵的一個反面示例,指定了weighter和maximumSize,卻沒有指定 maximumWeight屬性:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.weigher((key, value) -> 2)
.maximumSize(2)
.build();
cache.put("key1", "value1");
cache.put("key2", "value2");
System.out.println(cache.size());
} catch (Exception e) {
e.printStackTrace();
}
}
執行的時候,會報錯,提示weighter和maximumSize不可以混合使用:
java.lang.IllegalStateException: maximum size can not be combined with weigher
at com.google.common.base.Preconditions.checkState(Preconditions.java:502)
at com.google.common.cache.CacheBuilder.maximumSize(CacheBuilder.java:484)
at com.veezean.skills.cache.guava.CacheService.main(CacheService.java:205)
Guava Cache淘汰策略
為了簡單描述,我們將數據從緩存容器中移除的操作統稱數據淘汰。按照觸發形態不同,我們可以將數據的清理與淘汰策略分為被動淘汰與主動淘汰兩種。
被動淘汰
- 基於數據量(size或者weight)
當容器內的緩存數量接近(註意是接近、而非達到)設定的最大閾值的時候,會觸發guava cache的數據清理機制,會基於LRU或FIFO刪除一些不常用的key-value鍵值對。這種方式需要在創建容器的時候指定其maximumSize或者maximumWeight,然後才會基於size或者weight進行判斷並執行上述的清理操作。
看下麵的實驗代碼:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.removalListener(notification -> {
System.out.println("---監聽到緩存移除事件:" + notification);
})
.build();
System.out.println("put放入key1");
cache.put("key1", "value1");
System.out.println("put放入key2");
cache.put("key2", "value1");
System.out.println("put放入key3");
cache.put("key3", "value1");
System.out.println("put操作後,當前緩存記錄數:" + cache.size());
System.out.println("查詢key1對應值:" + cache.getIfPresent("key1"));
} catch (Exception e) {
e.printStackTrace();
}
}
上面代碼中,沒有設置數據的過期時間,理論上數據是長期有效、不會被過期刪除。為了便於測試,我們設定緩存最大容量為2條記錄,然後往緩存容器中插入3條記錄,觀察下輸出結果如下:
put放入key1
put放入key2
put放入key3
---監聽到緩存移除事件:key1=value1
put操作後,當前緩存記錄數:2
查詢key1對應值:null
從輸出結果可以看到,即使數據並沒有過期,但在插入第3條記錄的時候,緩存容器還是自動將最初寫入的key1記錄給移除了,挪出了空間用於新的數據的插入。這個就是因為觸發了Guava Cache的被動淘汰機制,以確保緩存容器中的數據量始終是在可控範圍內。
- 基於過期時間
Guava Cache支持根據創建時間或者根據訪問時間來設定數據過期處理,實際使用的時候可以根據具體需要來選擇對應的方式。
| 過期策略 | 具體說明 |
|---|---|
| 創建過期 | 基於緩存記錄的插入時間判斷。比如設定10分鐘過期,則記錄加入緩存之後,不管有沒有訪問,10分鐘時間到則 |
| 訪問過期 | 基於最後一次的訪問時間來判斷是否過期。比如設定10分鐘過期,如果緩存記錄被訪問到,則以最後一次訪問時間重新計時;只有連續10分鐘沒有被訪問的時候才會過期,否則將一直存在緩存中不會被過期。 |
看下麵的實驗代碼:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.expireAfterWrite(1L, TimeUnit.SECONDS)
.recordStats()
.build();
cache.put("key1", "value1");
cache.put("key2", "value2");
cache.put("key3", "value3");
System.out.println("put操作後,當前緩存記錄數:" + cache.size());
System.out.println("查詢key1對應值:" + cache.getIfPresent("key1"));
System.out.println("統計信息:" + cache.stats());
System.out.println("-------sleep 等待超過過期時間-------");
Thread.sleep(1100L);
System.out.println("執行key1查詢操作:" + cache.getIfPresent("key1"));
System.out.println("當前緩存記錄數:" + cache.size());
System.out.println("當前統計信息:" + cache.stats());
System.out.println("剩餘數據信息:" + cache.asMap());
} catch (Exception e) {
e.printStackTrace();
}
}
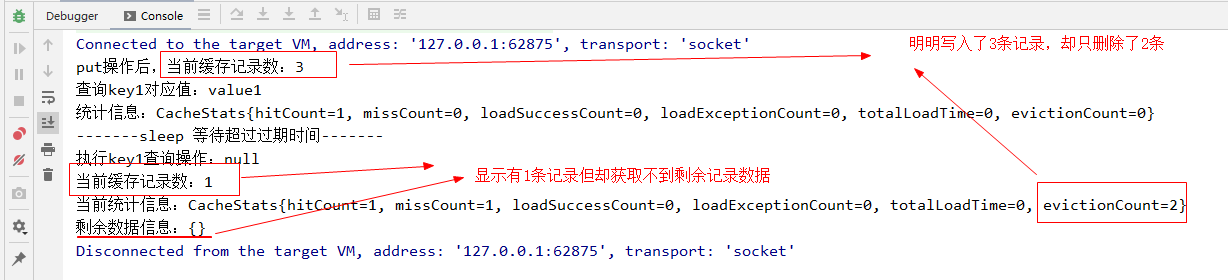
在實驗代碼中,我們設置了緩存記錄1s有效期,然後等待其過期之後查看其緩存中數據情況,代碼執行結果如下:
put操作後,當前緩存記錄數:3
查詢key1對應值:value1
統計信息:CacheStats{hitCount=1, missCount=0, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=0}
-------sleep 等待超過過期時間-------
執行key1查詢操作:null
當前緩存記錄數:1
當前統計信息:CacheStats{hitCount=1, missCount=1, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=2}
剩餘數據信息:{}
從結果中可以看出,超過過期時間之後,再次執行get操作已經獲取不到已過期的記錄,相關記錄也被從緩存容器中移除了。請註意,上述代碼中我們特地是在過期之後執行了一次get請求然後才去查看緩存容器中存留記錄數量與統計信息的,主要是因為Guava Cache的過期數據淘汰是一種被動觸發技能。
當然,細心的小伙伴可能會發現上面的執行結果有一個“問題”,就是前面一起put寫入了3條記錄,等到超過過期時間之後,只移除了2條過期數據,還剩了一條記錄在裡面?但是去獲取剩餘緩存裡面的數據的時候又顯示緩存裡面是空的?
Guava Cache作為一款優秀的本地緩存工具包,是不可能有這麼個大的bug遺留在裡面的,那是什麼原因呢?
這個現象其實與Guava Cache的緩存淘汰實現機制有關係,前面說過Guava Cache的過期數據清理是一種被動觸發技能,我們看下getIfPresent方法對應的實現源碼,可以很明顯的看出每次get請求的時候都會觸發一次cleanUp操作:
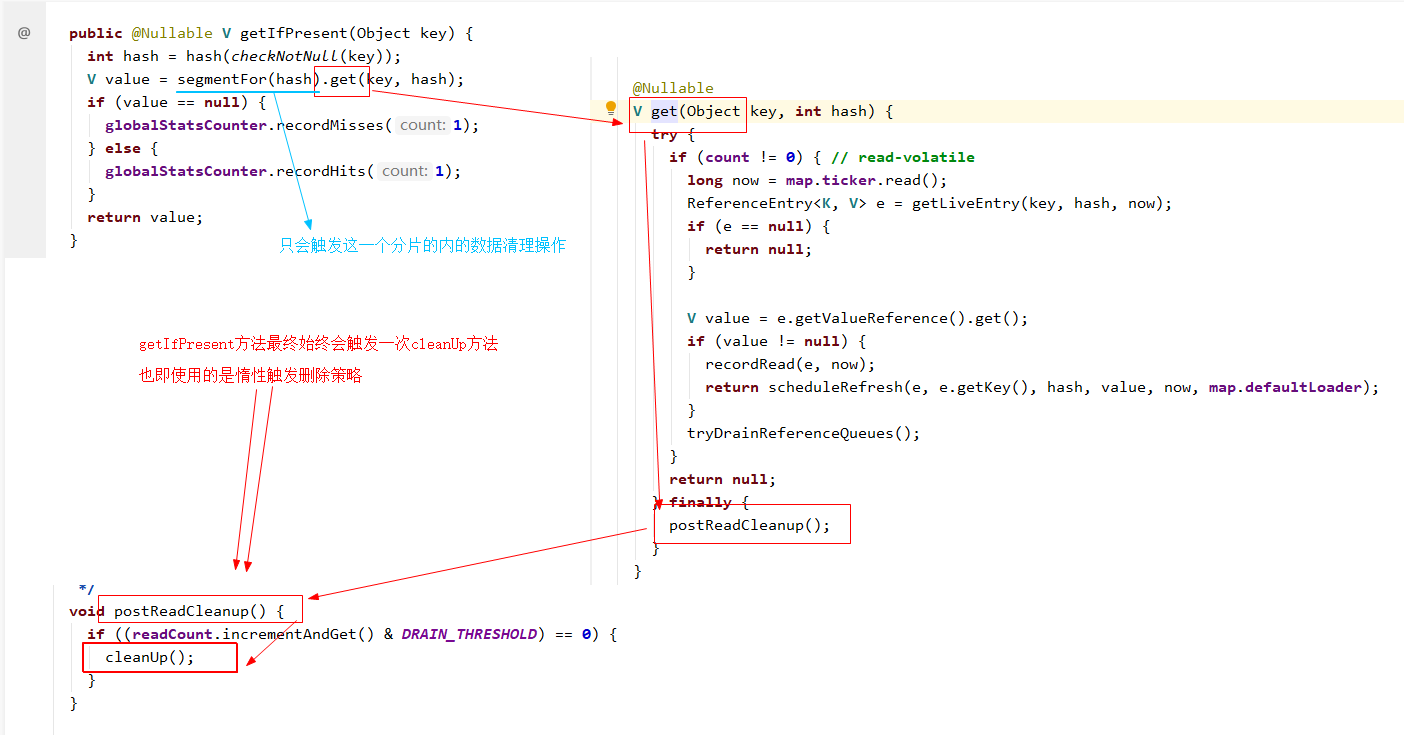
為了實現高效的多線程併發控制,Guava Cache採用了類似ConcurrentHashMap一樣的分段鎖機制,數據被分為了不同分片,每個分片同一時間只允許有一個線程執行寫操作,這樣降低併發鎖爭奪的競爭壓力。而上面代碼中也可以看出,執行清理的時候,僅針對當前查詢的記錄所在的Segment分片執行清理操作,而其餘的分片的過期數據並不會觸發清理邏輯 —— 這個也就是為什麼前面例子中,明明3條數據都過期了,卻只清理掉了其中的2條的原因。
為了驗證上述的原因說明,我們可以在創建緩存容器的時候將concurrencyLevel設置為允許併發數為1,強制所有的數據都存放在同一個分片中:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.expireAfterWrite(1L, TimeUnit.SECONDS)
.concurrencyLevel(1) // 添加這一約束,強制所有數據放在一個分片中
.recordStats()
.build();
// ...省略其餘邏輯,與上一段代碼相同
} catch (Exception e) {
e.printStackTrace();
}
}
重新運行後,從結果可以看出,這一次3條過期記錄全部被清除了。
put操作後,當前緩存記錄數:3
查詢key1對應值:value1
統計信息:CacheStats{hitCount=1, missCount=0, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=0}
-------sleep 等待超過過期時間-------
執行key1查詢操作:null
當前緩存記錄數:0
當前統計信息:CacheStats{hitCount=1, missCount=1, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=3}
剩餘數據信息:{}
在實際的使用中,我們倒也無需過於關註數據過期是否有被從記憶體中真實移除這一點,因為Guava Cache會在保證業務數據準確的情況下,儘可能的兼顧處理性能,在該清理的時候,自會去執行對應的清理操作,所以也無需過於擔心。
- 基於引用
基於引用回收的策略,核心是利用JVM虛擬機的GC機制來達到數據清理的目的。按照JVM的GC原理,當一個對象不再被引用之後,便會執行一系列的標記清除邏輯,並最終將其回收釋放。這種實際使用的較少,此處不多展開。
主動淘汰
上述通過總體容量限制或者通過過期時間約束來執行的緩存數據清理操作,是屬於一種被動觸發的機制。
實際使用的時候也會有很多情況,我們需要從緩存中立即將指定的記錄給刪除掉。比如執行刪除或者更新操作的時候我們就需要刪除已有的歷史緩存記錄,這種情況下我們就需要主動調用 Guava Cache提供的相關刪除操作介面,來達到對應訴求。
| 介面名稱 | 含義描述 |
|---|---|
| invalidate(key) | 刪除指定的記錄 |
| invalidateAll(keys) | 批量刪除給定的記錄 |
| invalidateAll() | 清空整個緩存容器 |
小結回顧
好啦,關於Guava Cache中的容量限制與數據淘汰策略,就介紹到這裡了。關於本章的內容,你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長。


